はじめに
ネットワークに接続されたセンサ機器の普及により、IoT(Internet of Things)が注目を集めています。IoTでは様々なセンサ機器が膨大なデータを生成するため、システムが管理するデータ量は急激に増加しています。このような膨大なデータを管理するためのデータストアとして、RDBと比較して高い性能とスケーラビリティを持つNoSQLが注目を集めています。
「Apache HBase」(以降、HBase)はNoSQLの1つで、センサ機器が生成する時系列データを管理するための有力なデータストアとして注目されています。本連載では、HBaseを用いたシステム設計のノウハウと、1,000万個のスマートメータから収集したデータによる性能検証の結果を紹介します。
今回は、まずNoSQLにおけるHBaseの位置付けを説明し、その後でHBaseの概要とアーキテクチャについて説明します。
NoSQLとは
RDBとNoSQLの違い
Wikipediaによると、NoSQL(Not only SQL)とは、関係データベース管理システム(RDBMS)以外のデータベース管理システムを指すおおまかな分類語です。一般的に、RDBMSにはビッグデータの3つの「V」と呼ばれる課題があると言われています。
1つ目はVolume(データ量)です。これは少数のサーバでは管理できないような大量のデータを指しています。RDBは複数人が同時にデータを更新した際に、データの整合性を担保するためのトランザクション機能を持っています。しかし、あまり多くのサーバにデータを分散すると整合性の維持が難しくなります。また、サーバ台数を増やしてスケールアウトする場合、特に商用製品では追加のライセンスが必要となることが多く、容量単位のコストはあまり安くなりません。そのため、膨大なデータを蓄積するような用途には向いていません。
2つ目はVelocity(速度)です。これは高頻度に発生する大量のデータをリアルタイムに格納/参照するというものです。しかし、RDBにはデータの整合性を維持するためのトランザクションやSQLの解析時間などのオーバーヘッドがあります。そのため高頻度のデータ処理には向いていません。また、処理性能を上げるためにサーバ台数を増やしてスケールアウトしても、複数のサーバにまたがるようなトランザクション処理があると、それほど性能は向上しません。性能を上げるためにサーバスペックをスケールアップすることも可能ですが、コストは高くなりやすいです。
3つ目はVariety(多様性)です。これはログやSNSのテキスト、センサデータ、画像や音声など、様々な構造や大きさのデータを指しています。これらのデータは、表形式のスキーマを事前に定義するRDBとは相性が良くありません。
これらの課題に対処するため、RDBの特徴であるデータの整合性を捨てて処理性能に特化したものや、表形式のデータモデルを捨ててより柔軟なデータモデルを採用したものがNoSQLと言えます(図1)。
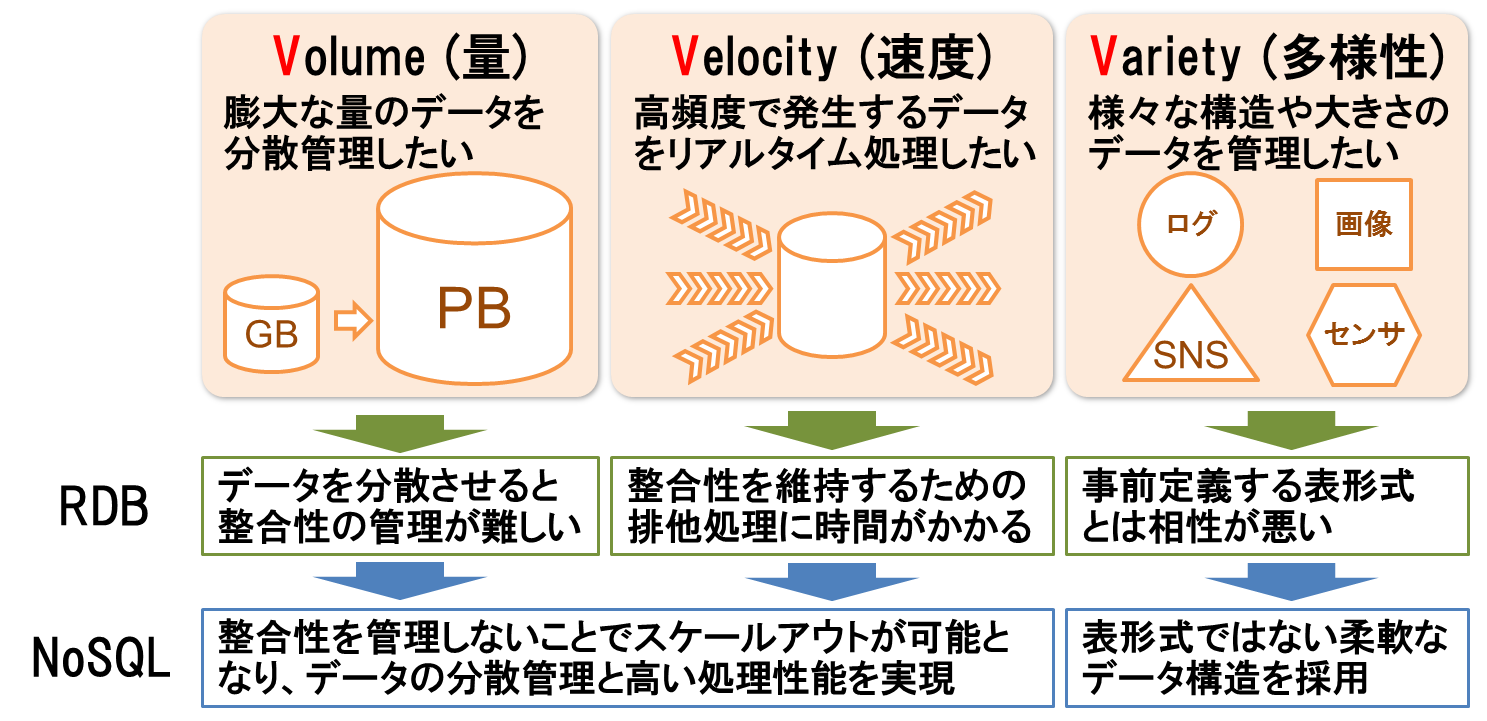
図1:RDBが苦手とするビッグデータの3つの「V」
データモデルによるNoSQLの分類
NoSQLの代表的なデータモデルを図2に示します。
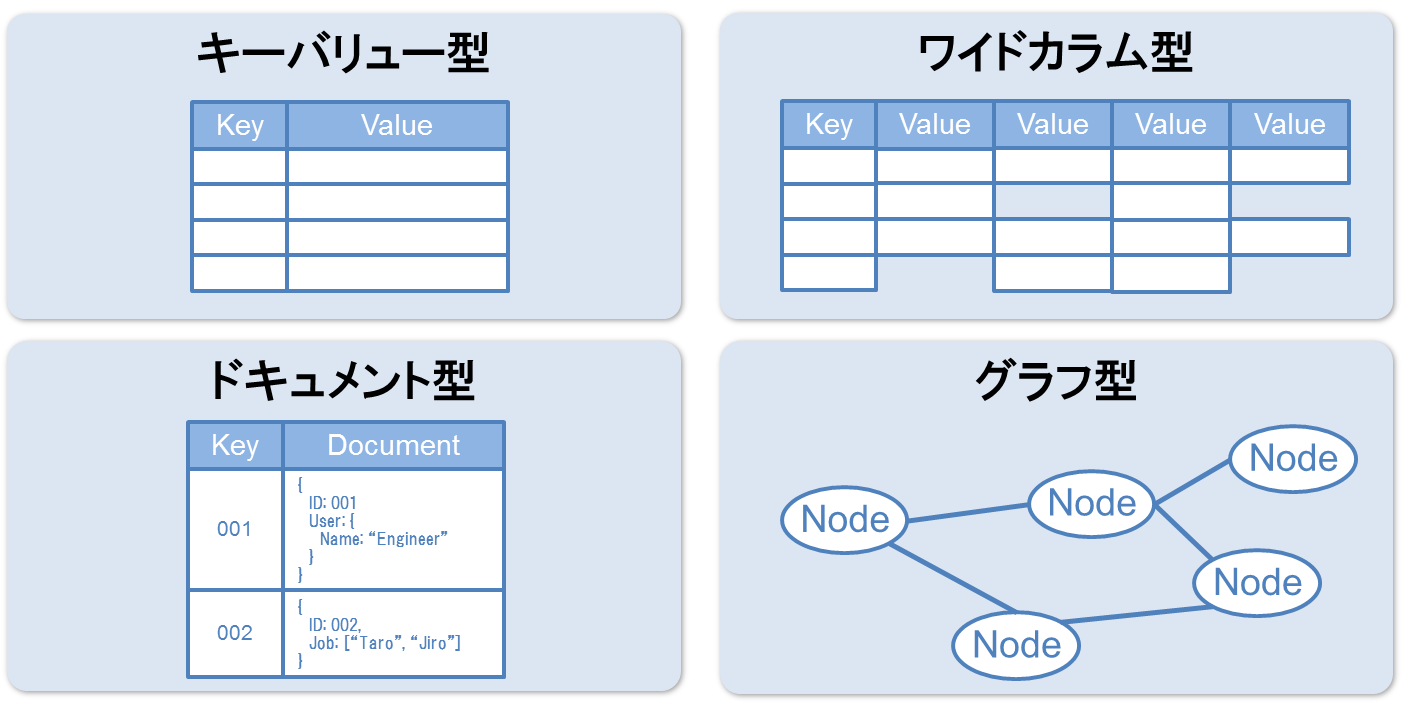
図2:NoSQLの代表的なデータモデル
- キーバリュー型
キーとバリューのペアというシンプルな構造でデータを格納します。これにより大量のデータを簡単に分散管理でき、かつ高速にアクセスできます。またバリューはほとんど型に縛られないため、動画や音声、画像などのメディアデータも容易に扱えます。一方、複数データの結合など複雑な条件での検索は苦手です。 - ワイドカラム型
キーバリュー型を拡張したもので、1つの行キーに対して複数の列を持つことができます。行ごとに異なる数の列を持つことができるため、柔軟なデータ運用が可能です。また列方向の集約が高速であるため集計処理にも適しています。 - ドキュメント型
これもキーバリュー型を拡張したもので、バリュー部分にJSONやXMLなどの半構造化データ(ドキュメント)を格納できます。キーバリュー型よりもデータの検索性に優れています。スキーマレスで柔軟なデータ運用が可能なため、一般的なWebシステムとの相性が良いと言えます。 - グラフ型
データ間の関係をグラフ構造で表現することで、データ間の関連を高速に検索できます。人・物・場所などの相関関係を表現する際にこのグラフ構造を利用します。グラフ型は上記の他のデータモデルとは異なりデータ間の関連性が強いため、これらのデータモデルと比べて複数台のサーバにデータを分散することは難しいです。
この他にも、複数のデータモデルに対応するマルチモデル型のNoSQLもあります。
データモデルと用途によるデータ処理基盤の分類
NoSQLを含むデータ処理基盤をデータモデルと用途で分類すると図3のようになります。リレーショナルモデルでデータを扱う場合、オペレーション用途なら汎用RDB、分析用途ならDWHまたはSQL on Hadoop(表形式のデータを扱うHive/Impalaなど)が適しています。リレーショナルモデル以外でデータを扱う場合はNoSQLやHadoop(MapReduce/Sparkなど。後述)が適しています。
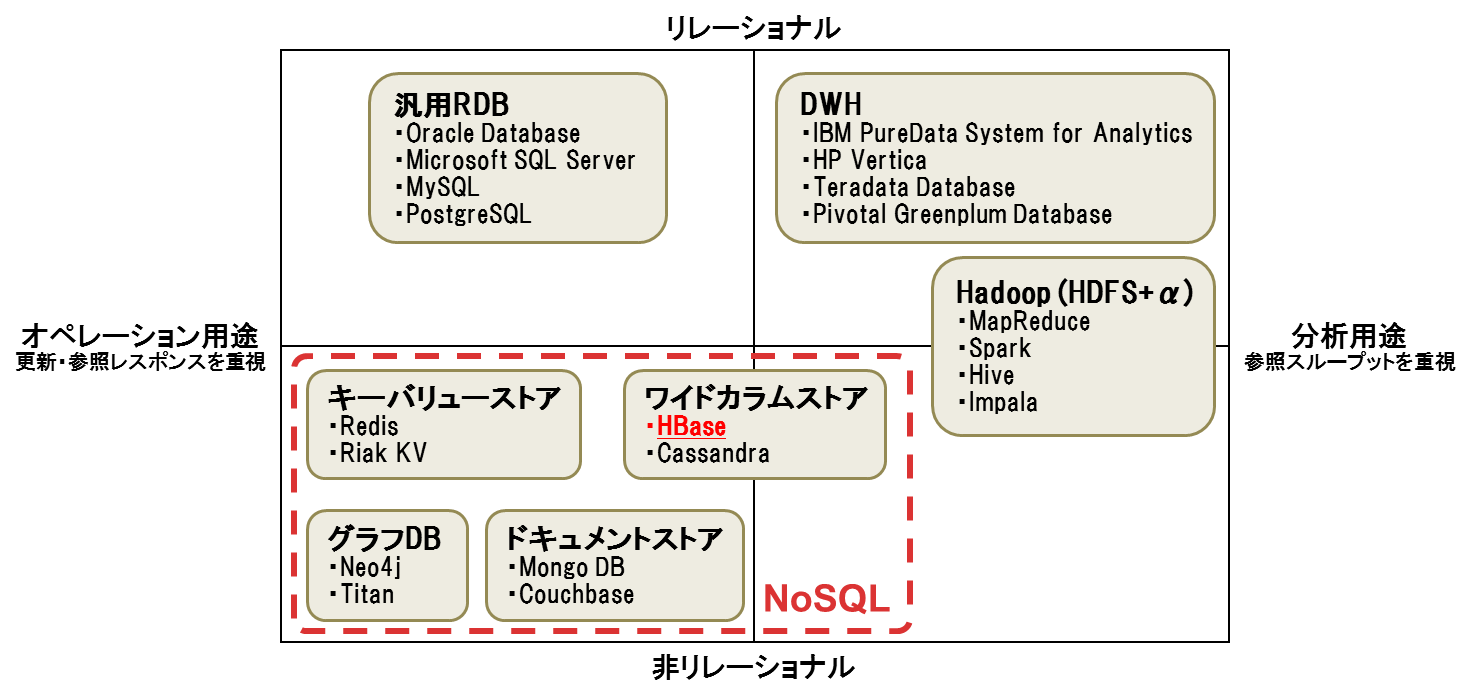
図3:データモデルと用途によるデータ処理基盤の分類
NoSQLの大半は非リレーショナルモデルのオペレーション用途に分類されますが、ワイドカラムストアは列方向の集約が高速であるため分析用途にも適用できます。本連載で扱うHBaseはワイドカラムストアで、分散処理により高頻度の書き込みと高スループットの並列読み出しが可能です。またスケールアウトにより大量のデータを低コストで格納できるため、高頻度に発生する大量のセンサデータを格納し、まとめて読み出して分析するといったケースに適しています。
HBaseの概要
HBaseとHadoop (HDFS)の関係
「Apache Hadoop」(以降、Hadoop)は、デファクトスタンダードになっているビッグデータ向けの処理基盤です。HBaseはHadoopのエコシステムを構成するOSSの1つで、Hadoopの分散ファイルシステムであるHDFS上に構築する分散データベースです。
Hadoopは、以下の3種類のコンポーネントで構成されています。
- MapReduce:バッチ処理の並列分散処理フレームワーク
- YARN(Yet Another Resource Negotiator):クラスタリソース管理ミドルウェア
- HDFS(Hadoop Distributed File System):分散ファイルシステム
Hadoopは複数台のサーバで構成されるクラスタ上にHDFSが分散ファイルシステムを構築し、YARNがクラスタのCPU、メモリなどのリソースを管理します。そして、YARN上でバッチ処理の並列分散処理フレームワークであるMapReduceが動作します。
HBaseはこのHDFS上に構築するデータベースです。HBaseとHadoop(HDFS)の関係を図4に示します。なお、HBaseの構築にYARNとMapReduceは必須ではありませんが、MapReduceを使用するとHBaseのデータ格納/参照を高速に行えるため、YARNとMapReduceも同時にインストールすることを推奨します。
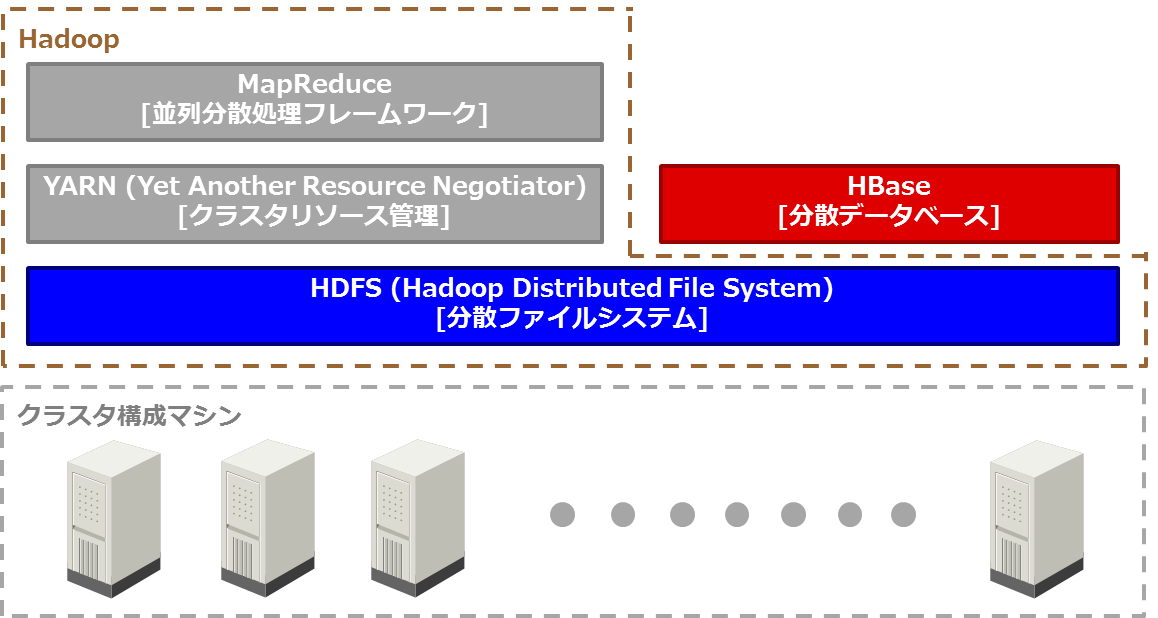
図4:HBaseはHadoop(HDFS)上に構築する
HDFSは大容量のファイルを高いスループットで読み書きできるため、Hiveなどのクエリエンジンと組み合わせてファイルに格納した大量データの参照・分析に使用されます(図3)。しかし、HDFSはあくまでファイルシステムであり、RDBのように大量の小さなデータを読み書きするレスポンス重視のオペレーション用途には向いていません。また、HDFSが扱うファイルは不変であるため、データの更新もできません。ファイルの内容を更新したい場合は、ファイルを一度削除してから更新後のファイルを追加する必要があります。
一方で、分散データベースのHBaseは大量の小さなデータの読み書きを高速に処理できます。したがってHBaseはHDFSを補完する存在とも言えます(スループット重視のHDFSとレスポンス重視のHBase)。
HDFSのしくみ
HDFSは、複数台のマシンのディスク領域をまとめて仮想的な1個のファイルシステムとして扱います。入力ファイルをブロックという単位で分割して複数のノードに分散配置することで書き込み/読み出し時のディスクI/Oを並列化し、高いスループットを実現します。また、1個のブロックを複数のノードに複製することで耐障害性を確保します(図5)。
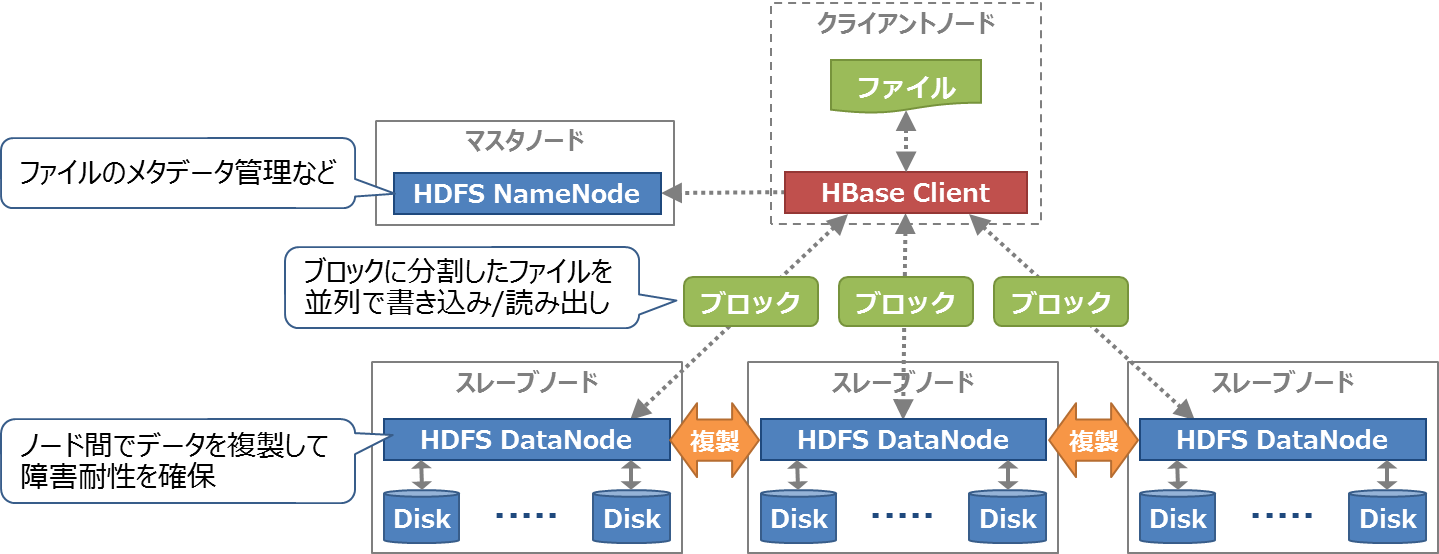
図5:HDFSの動作
HBaseのアーキテクチャ
HBaseのシステム構成
HBaseのシステム構成を図6に、またHBaseとその周辺コンポーネントの説明を表1に示します。HBaseはマスタ・スレーブ型の構成で、クラスタ全体を管理するマスタノードとデータを管理するスレーブノードで構成します。スレーブノードではHBaseのRegionServerがデータの管理とリクエスト処理、およびデータのキャッシュを行い、HDFSがデータの永続化を行います。HBaseとHDFSが同じノードに同居することでデータの管理と保存をスムーズに行えます。また、HDFSに保存されたデータはノード間で複製されるため、スレーブノードに障害が発生してもデータが失われる可能性は低いと言えます。
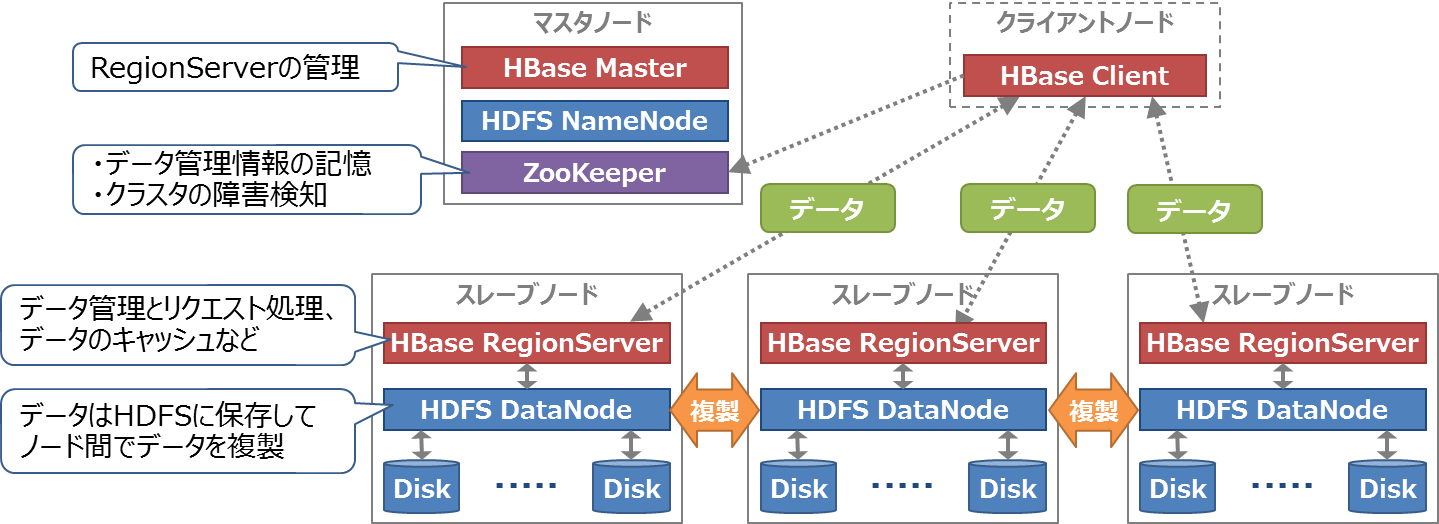
図6:HBaseのシステム構成
表1:HBaseとその周辺コンポーネント
| # | コンポーネント | 説明 |
|---|---|---|
| 1 | HBase Client | HBaseのデータアクセス用クライアント |
| 2 | HBase RegionServer | HBaseのデータを管理するサーバ。HBaseのデータはRegionという単位で分割され、1台のスレーブノードは複数個のRegionを管理する。RegionのデータはファイルとしてHDFSに保存する。また、HBaseクライアントからのリクエストの受付とデータのキャッシュを行う |
| 3 | HBase Master | HBase全体のメタデータ管理、各RegionServerに対するRegionの割り当てと監視、および障害発生時のフェイルオーバなどを行う |
| 4 | ZooKeeper | HBaseクラスタの障害検知やHBaseが保持する全データの管理情報(カタログTableと呼ばれる)がどのRegionServerに保存されているのかを記憶する |
| 5 | HDFS NameNode | HDFSのファイル情報管理とDataNodeの監視を行う |
| 6 | HDFS DataNode | HDFSのファイルを構成するブロックを管理する |
HBaseのデータ管理
HBaseはRegionという単位でデータを分散し、各スレーブノードのRegionServerにRegionを割り当てることでデータの書き込み/読み出しを分散処理します(図7)。そのため、スレーブノードを追加すると処理性能とディスク容量が向上します。各RegionはRegionServerのメモリ上にデータのキャッシュを持ち、データの実体はHDFS上にファイルとして格納します。
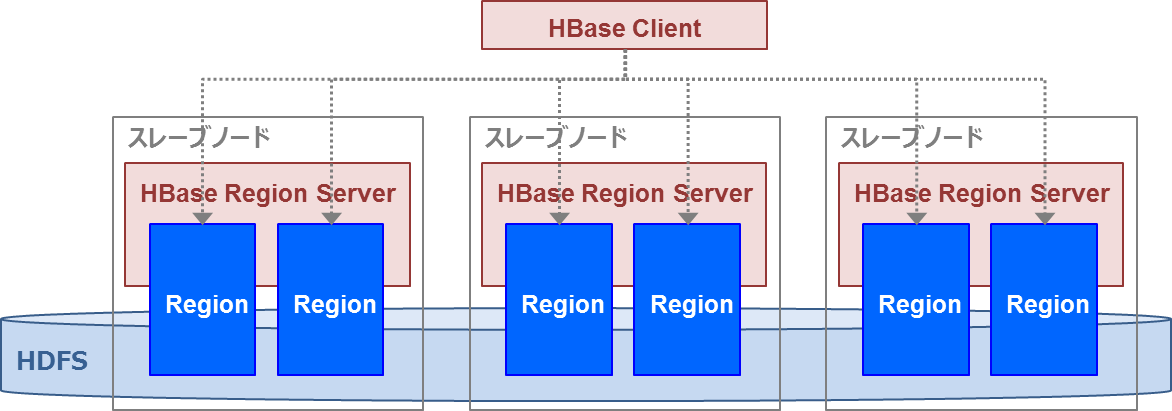
図7:HBaseのデータ管理
HBaseのデータモデル(論理データ構造)
HBaseのデータモデル(論理データ構造)を図8に示します。このデータモデルの最上位の概念であるNamespaceが1個以上のTableをグルーピングしています。Tableはデータを表形式で保持するデータモデルであり、1個のRowKeyと1個以上のColumnQualifier(以降、Qualifier)、およびQualifierをグルーピングするColumnFamilyで構成されます。
RowKeyとQualifierが交差する箇所をCellと呼び、このCellにデータを保持します。Cellに格納されたデータにはTimestampが付加されており、上書き前の過去データも保持されています。Cellには過去データの保持数を指定でき、古いデータを自動削除することも可能です。なお、Tableの各行(Row)はRowKeyでソートされた状態で保持されます。
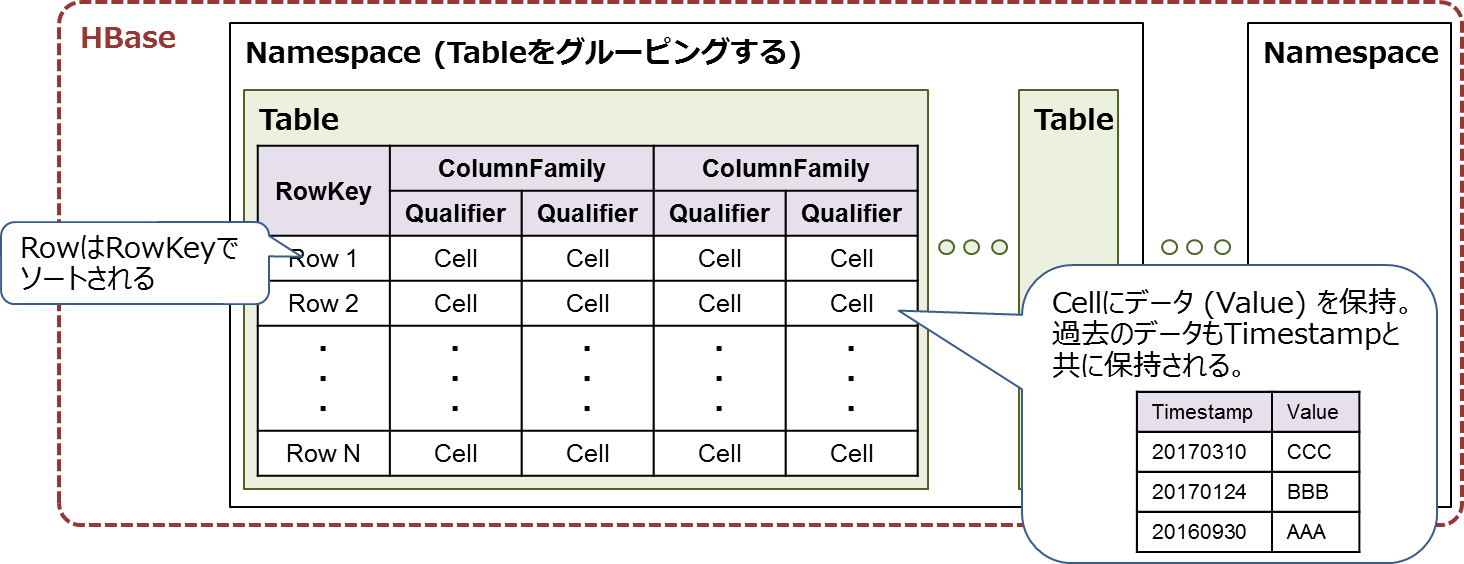
図8:HBaseのデータモデル(論理データ構造)
HBaseの物理データ構造
HBaseのTableの物理データ構造を図9に示します。HBaseのデータモデルは表形式ですが(図8)、データの実体はキーバリュー形式で保持されます。RowKey、Column(ColumnFamilyとQualifierを結合したもの)、Timestampの3つのキーにValueが対応します。 このキーバリューはRowKey、Column、Timestampの順番でソートされた状態で保持されます。HBaseのインデクスはRowKeyとColumnに付加できます。

図9:HBaseの物理データ構造
キーバリューにはTypeという情報が付加されます(表2)。追加/上書きされたキーバリューのTypeにはPut(表2#1)、削除されたキーバリューのTypeにはDelete系(表2#2~5)の値が付加します。キーバリューの参照時は、キーとしてRowKey、Column、Timestampの3つを指定することでValueの値を取得します。このとき、TypeがDelete系のキーバリューは削除されたキーバリューなので無視されます。この仕組みにより、HBaseはキーバリューの追加だけでキーバリューの削除を表現できます。TypeがDelete系のキーバリューは定期的に行われるコンパクションという処理で削除されます。
表2:キーバリューのType
| # | Type | 説明 |
|---|---|---|
| 1 | Put | 追加/上書きされたキーバリューであることを示す |
| 2 | Delete | RowKey、Column、TimestampがこのRowと一致するキーバリューを削除されたものと見なす |
| 3 | DeleteColumn | RowKey、ColumnがこのRowと一致し、かつTimestampがこのRowと同じまたは小さいキーバリューを削除されたものと見なす |
| 4 | DeleteFamily | RowKey、ColumnFamilyがこのRowと一致し、かつTimestampがこのRowと同じまたは小さいキーバリューを削除されたものと見なす |
| 5 | DeleteFamilyVersion | RowKey、ColumnFamily、TimestampがこのRowと一致するキーバリューを削除されたものと見なす |
Tableが物理的にどのように分割されるのかを図10に示します。TableのキーバリューはRowKeyの範囲でRegionという単位に分割され、Region内のデータはColumnFamily単位でStoreという単位に分割されます。Store内の各キーバリューはMemStore(メモリ上にStoreごとに1個存在)またはHFile(HDFS上にStoreごとに複数存在)に保持されます。

図10:Tableの物理的な分割
HBaseのデータ操作
HBaseのデータ操作のインタフェースにはJava API、REST、Thriftなどがあります。HBaseに対するデータ操作リクエストの一覧を表3に示します。基本的な操作を説明すると、Putでデータを追加してGetまたはScanでデータを取得します。HBaseはデータがキーでソートされた状態で格納されているため、Scanでキーの範囲を指定してまとめてデータを取得できます。したがって、HBaseではデータをうまくScanできるようにキーを設計することが重要になります。
表3:データ操作リクエスト一覧
| # | 種別 | リクエスト名 | 説明 |
|---|---|---|---|
| 1 | 更新 | Put | 1個のRowにデータを追加/上書きする |
| 2 | Append | 1個のRowに値を追記する | |
| 3 | Inclement | 1個のRowに値を加算する | |
| 4 | Delete | Row/Column/ColumnFamily単位でデータを削除する | |
| 5 | MutateRow | 1個のRowに対するPut/Deleteをアトミックに行う | |
| 6 | 参照 | Get | 1個のRowのデータを取得する |
| 7 | Scan | RowKeyの範囲指定により複数のRowのデータを取得する | |
| 8 | Exist | Row/Columnの存在確認を行う | |
| 9 | 更新+参照 | Batch | Put/Append/Inclement/Delete/Getを一度に実行する(実行順序は不定) |
| 10 | CheckAndPut | 1個のRowの値を確認し条件に一致すれば上書きする | |
| 11 | CheckAndDelete | 1個のRowの値を確認し条件に一致すれば削除する | |
HBaseのデータ更新/参照処理
更新/参照先Regionの検索
HBaseでデータを更新/参照するためには、まず以下の手順で格納/参照先のRegionServerを見つける必要があります。
- HBase ClientがZooKeeperにアクセスし、カタログTable(HBaseが保持する全データの管理情報)の格納先RegionServerを確認する
- HBase ClientがカタログTableの格納されたRegionServerにアクセスし、更新/参照したいデータがどのRegionに属するのかを確認する
以上の流れを図11に示します。
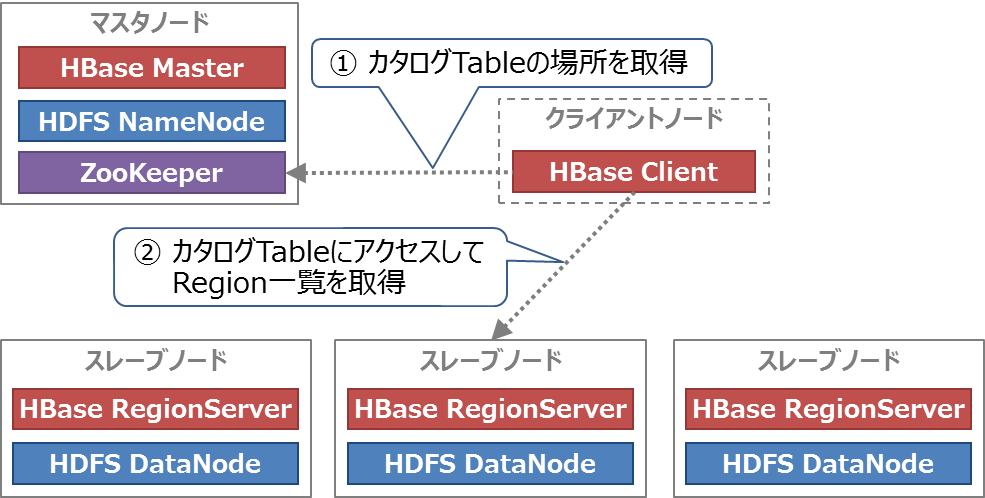
図11:更新/参照先Regionの検索
データ更新処理の流れ
次に、HBaseのデータ更新処理の流れを以下に示します(図12)。
- HBase Clientが更新先のキーバリューが属するRegionServerに更新リクエストを送信する
- RegionServerはリクエスト内容をHDFS上のWrite Ahead Log(WAL)に書き出す。WALは追記型のログファイルで、高速な書き込みが可能である。WALはノード障害時にMemStore上の永続化されていないデータを復旧するために使用される。MemStoreのデータがHDFSに書き出されたら、その分のWALは不要となるため削除される
- キーバリューのRowKeyから格納先のRegionを決定し、ColumnFamilyから格納先のStoreを決定する。そして、格納先のStoreが持つMemStoreにキーバリューを書き込む
- MemStoreに書き込まれたデータ量が一定のサイズに達したら、MemStore内のキーバリューをHDFS上に新しいHFileとして書き出す。このときHFileにはキーバリュー検索用のインデクスとブルームフィルタ*1を追加する
- HDFSに書き出されたHFileは定期的にマージされる(これをコンパクションと呼ぶ)。これにより、HFileが増えすぎることを防ぐ
*1:ブルームフィルタは特定の要素(キーバリュー)が特定の集合(HFile)に含まれているか否かを判定しますが、一定の割合(デフォルト設定では1%)で間違った結果を返してしまいます。具体的には、特定のキーバリューが特定のHFileに含まれていると判定したのに、実際は含まれていなかった、といったことがあります(なお、含まれていないと判定したのに実際は含まれていた、ということはありません)。ブルームフィルタは確実に判定できない代わりにインデクスと比較して少ない容量で保持できます。詳細はHBaseの公式ドキュメントを参照してください。
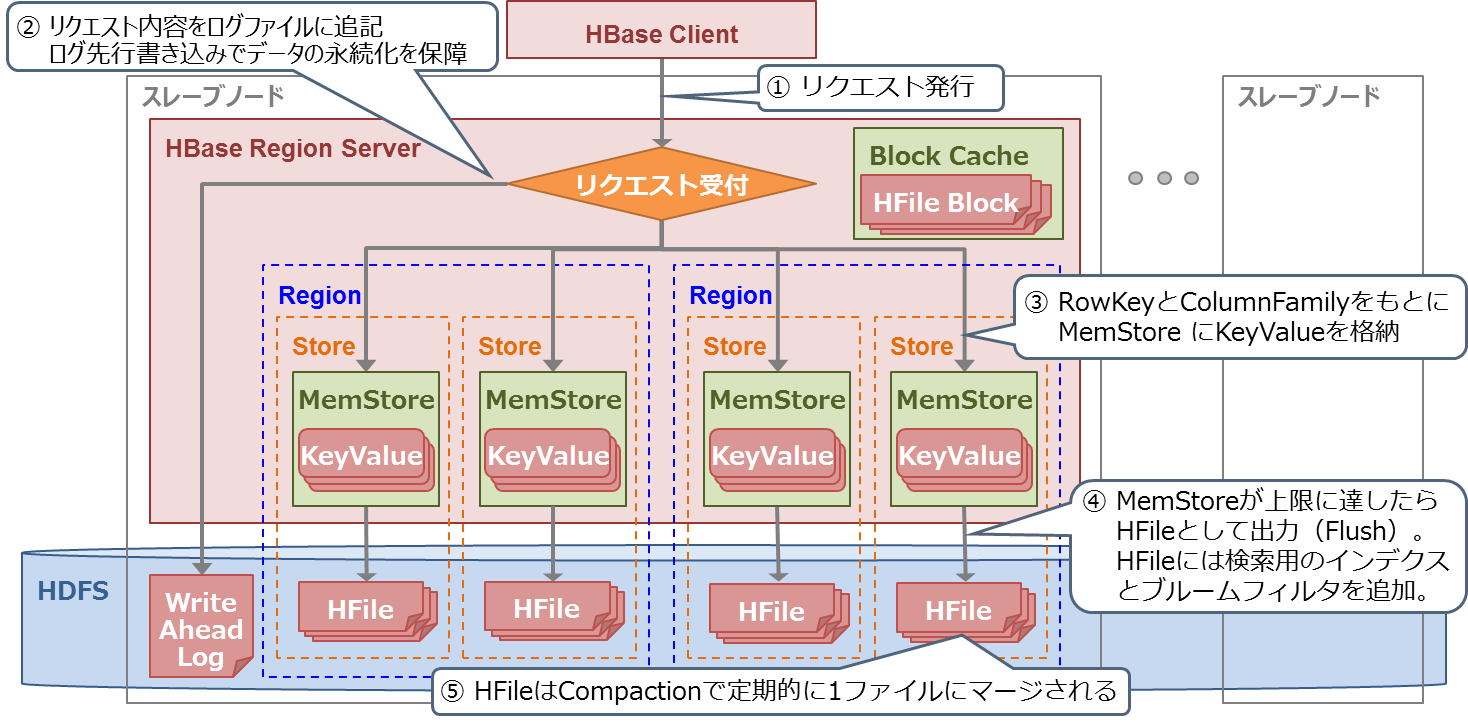
図12:HBaseのデータ格納処理の流れ
以上の処理の流れにより、データの書き込みをRegion間で分散処理できます。また、メモリ上のMemStoreでデータをバッファリングしてからディスクにまとめて書き込むことで、大量のランダム書き込みに対応できます。
データ参照処理の流れ
最後に、HBaseのデータ参照処理の流れを以下に示します(図13)。
- HBase Client が参照先のキーバリューが属するRegionServerに参照リクエストを送信する
- RegionServerは、Block Cache*2およびBucket Cache*3から目的のキーバリューを探す
- 目的のキーバリューがBlock CacheおよびBucket Cacheになければ、MemStoreからキーバリューを探す
- 目的のキーバリューがMemStoreになければ、HFileからキーバリューを探す。まず、各HFileに含まれているブルームフィルタを使用して目的のキーバリューが含まれている可能性があるHFileを探す。目的のキーバリューが含まれている可能性がある場合は、そのHFileに含まれているインデクスを使用して目的のキーバリューを探索・取得する。取得したキーバリューの含まれているBlockはBlock CacheおよびBucket Cacheに保持する
*2:Block CacheはHFileを構成するBlock(HBaseのI/Oの最小単位であり、デフォルト設定では64KB。このBlockはHDFSやファイルシステムのBlockとは無関係)をキャッシュします。キャッシュにはRegionServerのJavaヒープメモリを使用します。
*3:Bucket CacheもBlock Cacheと同様にHFileを構成するBlockをキャッシュします。キャッシュにはJavaヒープメモリ以外にオフヒープメモリやディスクも使用できます。Bucket CacheはBlock Cacheと組み合わせて使用することを前提に設計されています。その場合Block CacheはL1キャッシュとしてHFileのブルームフィルタやインデクスが含まれているブロックを格納し、Bucket CacheはL2キャッシュとしてHFileのキーバリューが含まれているデータブロックを格納します。
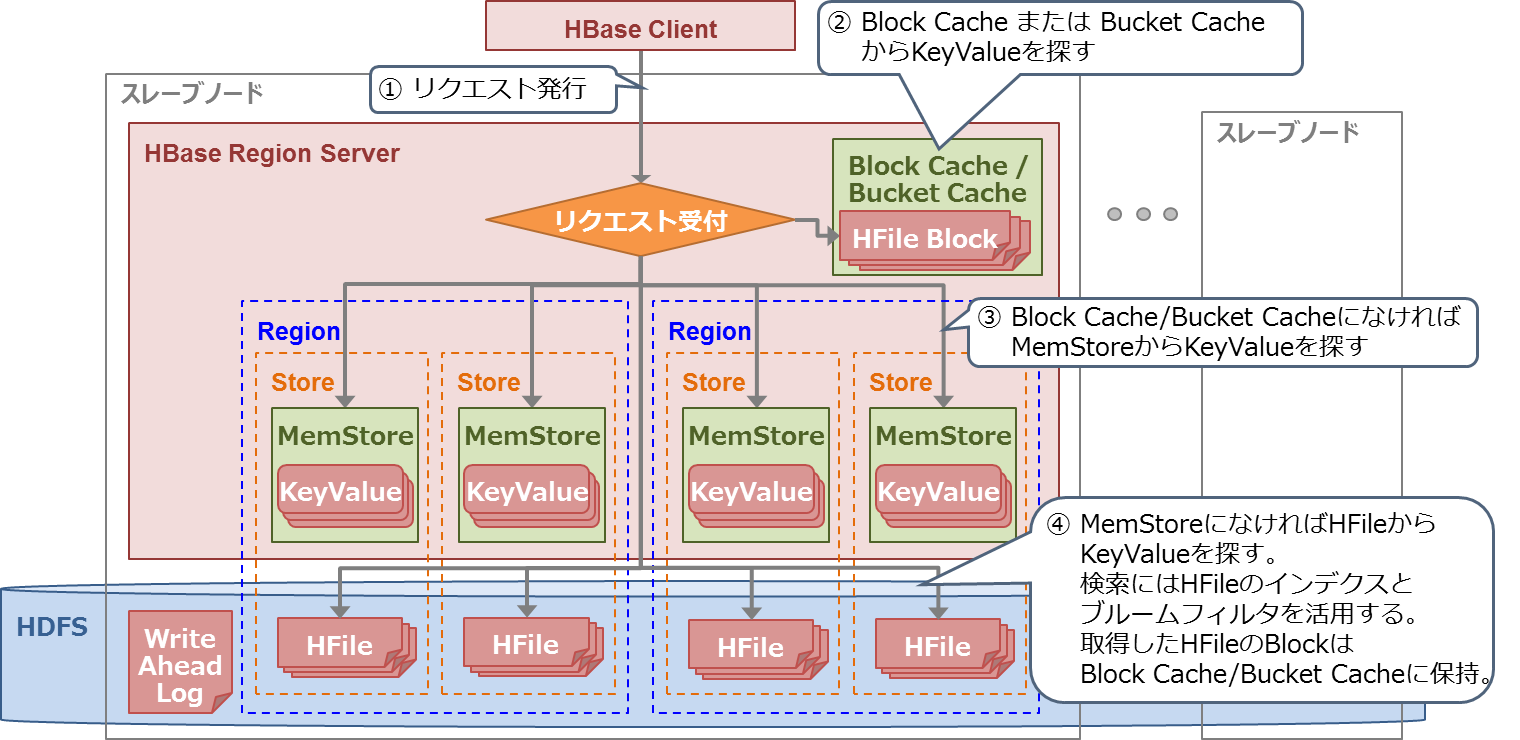
図13:HBaseのデータ参照処理の流れ
以上の処理の流れにより、データの読み出しをRegion間で分散処理できます。また、Block Cache/Bucket CacheおよびMemStoreによるキャッシュとブルームフィルタとインデクスによるデータ検索により、読み出し処理を低レイテンシで実行できます。
おわりに
今回はNoSQLにおけるHBaseの位置付け、およびHBaseの概要とアーキテクチャについて解説しました。RDBに対するHBaseの最大の利点は処理性能の高さです。しかしHBaseとRDBにはデータモデルや機能に多くの違いがあるため、RDBをそのままHBaseに置き換えることはできません。
次回は、HBaseの導入を検討する際の参考情報として、HBaseの長所と短所およびHBaseに適したユースケースを紹介します。また、HBase導入する際の推奨ハードウェア/ソフトウェア構成、および設計ノウハウも紹介します。
- この記事のキーワード
この記事をシェアしてください
バックナンバー
この記事の筆者
筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
