[SQL] SQL関数の操作
ORACLE MASTERの取得を目指した連載の第3回は、SQL関数(単一行関数とグループ関数)の使い方について学ぶ。
2017年1月10日 2:50
皆さんこんにちは! 前回はSELECT文によるデータ取得、制限やソート処理について学習しましたね。第3回目は、SQL関数に焦点をあてて解説します。「関数」と聞くとプログラミング的なイメージがあるかもしれませんが、SQL関数の働きは以下のようなものです。
SQL関数の例
SQL関数を使って、文字や数値などに対していろいろと操作ができるといった感じですね。では、さっそく問題にとりかかるとしましょう。
単一行関数とグループ関数(複数行関数)について
単一行関数
SQL関数は、「単一行関数」と「グループ関数(複数行関数)」の2つに大別できます。まずは、単一行関数から学習していきましょう。単一行関数とはその名の通り、単一の行のみで動作して行ごとに結果を戻す関数です。冒頭で小文字を大文字へ変換する図がありましたが、これは「UPPER」という関数に引数「oracle」を渡すことで実現可能です。単一行関数には文字関数や数値関数、日付関数、汎用関数など様々な関数が用意されており、それぞれ覚える必要があります。さっそく最初の問題に挑戦してみましょう。
従業員表(EMPLOYEES)の姓(LAST_NAME列)にaという文字を2文字以上含む社員情報を出力します。以下のSQL文のうち、正しいデータを出力するのはどれですか。
(a)SELECT last_name FROM employees
WHERE INSTR(last_name,'a') <> 0;
(b)SELECT last_name FROM employees
WHERE INSTR(last_name,'a') = 2;
(c)SELECT last_name FROM employees
WHERE INSTR(last_name,'a',1,2) <> 0;
(d)SELECT last_name FROM employees
WHERE INSTR(last_name,'a',1,2) = 0;
(e)SELECT last_name FROM employees
WHERE INSTR(last_name,'a',1,2) IS NULL;
(f)SELECT last_name FROM employees
WHERE INSTR(last_name,'a',1,2) IS NOT NULL;
INSTR関数の使い方に関する問題です。まずは構文を確認してみましょう!
構文:INSTR(CHAR, 'string',[m], [n])
解説:引数CHARで指定した文字データから、引数で指定したstring(文字列)の出現位置を数値で戻します。CHARの部分は、定数あるいは文字型の列名が指定できます。検索を開始する位置をm(先頭が1となります)で指定し、文字の出現回数はnで指定します。m、nを省略した場合は1となります。
構文解説をみてもチンプンカンプン…… という方は、まず実機で動作確認です! 今回は文字列「Nakamura」で検証してみます。以下を実行してみましょう。
SELECT INSTR('Nakamura','a') FROM dual;
※dual 表はダミー表としてすべてのユーザーでアクセス可能な表です
(結果)
INSTR('NAKAMURA','A')
------------------------------------
2
まずINSTR関数の3つ目、4つ目の引数を省略していますので、どちらも1が入っている状態です。つまり先頭から「a」という文字を検索開始し、最初に出現する場所の数値を戻すという動作になるので、結果は2となりますね。いかがでしょう、解説の文章と睨めっこするだけではなく、実際に動作させると「あ、そういうことか」という納得できるのではないでしょうか?
さて、改めて問題1の内容をみてみましょう。「『a』という文字を2文字含む社員情報を出したい」とあるので、「a」が2回出現することが条件となります。つまり引数には、「INSTR(last_name,'a',1,2)」という指定が必要ということです。この時点で(a)と(b)が除外できます。次は、INSTR関数の戻り値について注目します。選択肢(e)と(f)にNULLの文字があります。NULLは第2回目でも説明したように、値が不明な特殊なものでしたね。INSTR関数の戻り値は数値ですので、(e)と(f)も誤りであることが分かります。残りは(c)と(d)になりますが、(d)は「a」という文字がヒットしなかった場合に戻り値が0となるため、誤りです。よって、正解は(c)ですね。
次は、もう少し複雑な問題にトライしましょう。

上記の結果を参考に、以下のSQL文を実行した際に出力される結果について正しいものを選択してください。
SELECT INITCAP(CONCAT(SUBSTR(job_id, -4), '_ORA'))
FROM employees WHERE department_id=10;
(a)Ad_As_Ora
(b)Ad_As_ORA
(c)A_ORA
(d)Asst_ORA
(e)Asst_Ora
(f)ネスト構造が3つ以上のため実行するとエラーとなる。
(g)SUBSTR関数の引数にマイナス値は指定できないのでエラーとなる。
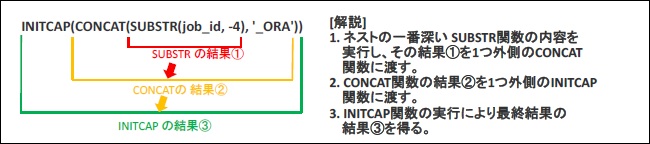
SELECT句に、なにやら関数が被せるようにたくさん書いてありますね。このような記述を「ネスト構造」(入れ子)と呼びます。ネストされた関数は、最初にもっとも深いレベル(もっとも内側)の関数が実行され、その結果が1つ浅いレベル(1つ外側)へ渡されます。以下、「内側の関数の結果を外側の関数に渡す」を繰り返し、最終的な結果が得られます。今回の問題を例に、図解を示しておきます。
関数のネスト構造
このネスト構造は、単一行関数では任意のレベルで使用することができます。つまり制限なしということですね。そのため選択肢(f)は誤りです。ちなみに、この後で説明するグループ関数にはネストは2つまでという制限があります。この違いも頭に入れておきましょう。さぁ、個々の関数を見ていきましょう! まずは構文と解説です。
構文:SUBSTR(CHAR, m, [n])
解説:引数CHARで指定した文字データからm、nで指定した文字を戻します。CHARの部分は定数あるいは文字型の列名が指定できます。mは文字データの先頭からの位置(m番目、先頭が1となる)を指定し、nは抜き出す文字長を指定します。nを省略した場合、m番目から最後の文字まで表示します。mが負の数値の場合、文字データの末尾から数えた位置となります。
構文:CONCAT(CHAR1, CHAR2)
解説:引数CHAR1、CHAR2 の2つの文字データを結合します。CHAR1、CHAR2の部分は定数あるいは文字型の列名が指定できます。
構文:INITCAP(CHAR)
解説:引数CHARの文字データの各単語の先頭文字を大文字にし、残りを小文字で表示します。各単語は空白または英数字以外の文字で区切られます。
解説を読んでイメージが湧いてこない方は、実機検証です! 「ネスト構造が複雑だなぁ」と思う方は、関数を1つ1つ別々に実行してみればいいのです。先の図解も参考にしつつ、まずはSUBSTR関数だけを実行してみましょう。
SELECT SUBSTR(job_id, -4) FROM employees WHERE department_id=10;
結果①:ASST
SUBSTR関数の引数に負の値である「-4」が指定してありますので、文字データAD_ASSTの末尾から数えて4番目からデータ抜き出し開始となります。抜き出すデータ長の指定は省略されているので、最後まで読み込む動作になり、結果として「ASST」が返ります。この結果が外側にあるCONCAT関数に渡されるわけですね。こちらも単独で実行してみましょう。
SELECT CONCAT('ASST', '_ORA') FROM employees WHERE department_id=10;
結果②:ASST_ORA
SUBSTR関数から受け取った結果と「_ORA」という文字を連結させた結果が出ました。最後に、この結果を1番外側の関数INITCAPに渡します。
SELECT INITCAP('ASST_ORA') FROM employees WHERE department_id=10;
結果③:Asst_Ora
あら、答えが出ちゃいました(笑)。単一行関数の使い方に慣れてない場合は、今回のようにバラバラに実行して動作確認すると理解が深まります。この時点でもう一度関数の解説部分を読んでみると内容が頭に入ってくるのではないでしょうか。以上の内容から正解は(e)となります。
では第3問目です!
従業員表(EMPLOYEES)の部門ID(DEPARTMENT_ID列)が50の従業員のデータに対して以下の問合せを実行しました。
SELECT first_name, salary, NVL(commission_pct, 'Commission is Null')
FROM employees WHERE department_id = 50;
どのような結果になるか適切なものを選択してください。なお、従業員表の構造は以下になります。

(a)COMMISSION_PCT列がNULL値の場合、'Commission is Null'という文字列を
表示する。
(b)COMMISSION_PCT列がNULL値の場合、'Commission is Null'という文字列を
COMMISSION_PCT列に挿入する。
(c)COMMISSION_PCT列がNULL値でない場合、'Commission is Null'という
文字列を表示する。
(d)エラーになる。
汎用関数といわれているNVL関数の問題になります。正解として(a)を選んだ方! おしい…… あともう少しですね。今回は先に正解を紹介しましょう。正解は(d)になります。では解説をしていきます。NVL関数はNULLを扱える関数となっており、以下のような動きになります。
NVL関数の使用方法

つまり、NVL(commission_pct, 0) と指定があればNULLを数値の0へ変換するという動作になります。あれ? やっぱり(a)が正解なのでは…… と思うかもしれませんが、NVL関数を使用する際には注意事項があります。NVLは引数を2つ取りますが、第1引数で指定した列名のデータ型と変換する値のデータ型はそろえる必要があります。従業員表の構造が問題文にありましたね。COMMISSION_PCT列のデータ型を見てみると、NUMBER型になっています。選択肢(a)は「'Commission is Null'という文字列を表示」とありますが、データ型が一致していないので誤りとなります。実際に問題文のSQLを実行すると「ORA-01722: 数値が無効です。」とエラーになりますので、ぜひ試してみてください。
では、このNVL関数でデータ型が一致していない場合、対処方法はないのでしょうか? 実はデータ型を一致させるために単一行関数の変換関数を使用することで、(a)の選択肢のように文字列を表示させることができます。変換関数には「TO_NUMBER」「TO_DATE」「TO_CHAR」の3つがあります。今回の場合は以下のように「TO_CHAR」を使うことで実行が可能になります。
SELECT first_name, salary, NVL(TO_CHAR(commission_pct),'Commission is NULL')
FROM employees WHERE department_id = 50;
これらの関数についてもあわせて学習しておいてくださいね。
グループ関数(複数行関数)
続きまして、グループ関数(複数行関数)について学習していきます。グループ関数は複数行をグループ化し、そのグループごとに1つの結果を戻す関数となります。
主なグループ関数としてまずは以下を押さえておきましょう。
主なグループ関数
| 関数名 | 説明 |
|---|---|
| AVG(列名) | 列の平均値。NULL値は無視 |
| COUNT(列名) | NULL値以外の列の値がある行数(※1) |
| MAX(列名) | 列の最大値。NULL値は無視 |
| MIN(列名) | 列の最小値。NULL値は無視 |
| SUM(列名) | 列の合計値。NULL値は無視 |
※1 COUNT(*)とした場合は、NULLも含めた全行数をカウント
では参考までに、グループ関数を使ったSQL文の実行例を紹介しましょう。
SELECT AVG(salary), MAX(salary), MIN(salary) FROM employees;
(結果)
AVG(SALARY) MAX(SALARY) MIN(SALARY)
--------------------- ---------------------- ---------------------
6461.83178 24000 2100
上記の結果はSALARY列の平均値、最大値、最小値を出力する内容となります。ではさっそく、このグループ関数を用いた問題を解いてみましょう。
従業員表(EMPLOYEES)の部門ID別(DEPARTMENT_ID列)、職種ID別(JOB_ID列)に給与の最大値と平均値を求め、給与の最大値が12000以上の情報を表示したい。該当するSQL文を選択してください。
(a)SELECT department_id, job_id, MAX(salary), AVG(salary)
FROM employees
HAVING MAX(salary) >= 12000;
(b)SELECT department_id, job_id, MAX(salary), AVG(salary)
FROM employees
GROUP BY department_id
HAVING MAX(salary) >= 12000;
(c)SELECT department_id, job_id, MAX(salary), AVG(salary)
FROM employees
GROUP BY department_id, job_id
HAVING MAX(salary) >= 12000;
(d)SELECT department_id, job_id, MAX(salary), AVG(salary)
FROM employees
WHERE MAX(salary) >= 12000
GROUP BY department_id, job_id;
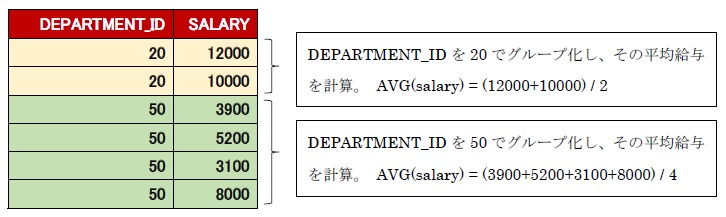
グループ関数と組み合わせてGROUP BY句とHAVING句が新たに出てきていますね。まずはGROUP BY句から確認していきましょう。GROUP BY句は、指定した列名で表内の行をグループに分けることができます。例えば以下の表データがあった場合に、DEPARTMENT_IDでグループ化して、SALARYの平均を求めるといった感じです。
GROUP BY句の使用例
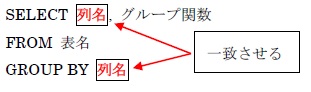
GROUP BY句を使用する際の注意事項としては、SELECT句にグループ関数でない列名を含む場合には、その列名はすべてGROUP BY句に含める必要があることです。つまりは以下のようなことになります。
GROUP BY句を使う際の注意点
この構文を機械的に覚えるのではなくて、なぜ一致させる必要があるのかも考えていきましょう。例えば以下のSQL文を実行するとエラーとなります。
SELECT department_id, SUM(salary) FROM employees;
行1でエラーが発生しました。:
ORA-00937: 単一グループのグループ関数ではありません
なぜエラーになるかは、SELECT句で指定しているdepartment_idとSUM(salary)を分けてSQL文を実行するとよく分かります。

これでは表示することができませんね。さて、ここまでの学習で問題の選択肢を絞り込むことができます。SELECT句で指定しているグループ関数以外の列名はGROUP BYですべて指定する必要があるわけですから、(a)と(b)が誤りであることが分かります。残りはHAVING句です。対象行を絞り込む方法としてこれまではWHERE句を使ってきましたが、グループ関数を絞り込み条件として指定するには、WHERE句ではなくHAVING句を使用する必要があります。WHERE句にグループ関数を使用すると「ORA-00934: ここではグループ関数は使用できません。」というエラーで怒られます。以上の結果から正解は(c)となります。
では今回の最後の問題にいきましょう。
従業員表(EMPLOYEES)の部門ID(DEPARTMENT_ID列)が20、30、60の従業員の姓(LAST_NAME)を従業員ID(EMPLOYEE_ID)で昇順してリスト表示したい。以下の結果を得るための正しいSQL文はどれになりますか。

(a)SELECT department_id,
LISTAGG(last_name, '; ') WITHIN GROUP(ORDER by employee_id) "EmpName"
FROM employees WHERE department_id in (20,30,60);
(b)SELECT department_id,
LISTAGG(last_name, '; ') WITHIN GROUP(ORDER by employee_id) "EmpName"
FROM employees WHERE department_id in (20,30,60)
GROUP BY department_id;
(c)SELECT department_id,
LISTAGG(employee_id, '; ') WITHIN GROUP(ORDER by last_name) "EmpName"
FROM employees WHERE department_id in (20,30,60)
GROUP BY department_id;
(d)SELECT department_id,
LISTAGG(employee_id) WITHIN GROUP(ORDER by last_name '; ') "EmpName"
FROM employees WHERE department_id in (20,30,60)
GROUP BY department_id;
(e)SELECT department_id,
LISTAGG(last_name) WITHIN GROUP(ORDER by employee_id) "EmpName"
FROM employees WHERE department_id in (20,30,60)
GROUP BY department_id;
これまで学習したグループ関数とは別の新たな関数LISTAGGに関する問題です。この関数を使用すると、問題文にあるように1つのフィールド内にグループ化した行データをリスト表示することができます。LISTAGG関数もグループ関数ですから、SELECT句にグループ関数以外の列名がある場合はGROUP BY句でその列名を指定する必要があります。この時点でまず(a)が誤りと分かりますね。ではこのLISTAGG関数の構文について見ていきましょう。
LISTAGG(メジャー列名, 'デリミタ') WITHIN GROUP (ORDER BY リスト値のソート列)
何だか難しそうに見えますよね。そういうときは、もう何度も繰り返しになりますが実機での確認です。簡単な例を使って動作を確認してみましょう。
SELECT last_name
FROM employees WHERE department_id = 60 ORDER BY last_name;
(結果)
LAST_NAME
-------------------------
Austin
Ernst
Hunold
Lorentz
Pataballa
この結果を参考に、LISTAGG関数を使って1つのフィールドにリスト表示してみます。デリミタ(区切り文字)は「;」で表示してみましょう。
SELECT LISTAGG(last_name, ';') WITHIN GROUP(ORDER BY last_name)
FROM employees WHERE department_id=60;
(結果)
LISTAGG(LAST_NAME,';')WITHIN GROUP(ORDERBYLAST_NAME)
-----------------------------------------------------------------------------------------------------
Austin;Ernst;Hunold;Lorentz;Pataballa
いかがですか? 実際に動作させてみるとよく分かりますよね。さぁ、問題文と選択肢をもう一度見てみましょう。選択肢の(c)と(d)は、employee_idをリスト表示するようになっているので誤りです。(d)にいたっては、デリミタの指定方法も間違っていますね。残りは(b)か(e)になりますが、(e)にはデリミタの指定がありません。指定がなくてもSQL文は実行できますが、得たい結果とは異なりますので正解は(b)となります。
第3回目はSQL関数の学習を行いました。何度も「実機、実機」としつこく記載しましたが、実際にSQL文を動作させることによって構文の理解がより深まることを実感してもらえれば、非常にうれしく思います。ぜひ、構文間違いなどでエラーをバシバシ発生させて「何が間違っているのか?」と考えて、SQL文を記述する練習にもなるといいですね(笑) 次回もSQL文の学習です。それではまた~。
* OracleとJavaは、Oracle Corporation 及びその子会社、関連会社の米国及びその他の国における登録商標です。文中の社名、商品名等は各社の商標または登録商標である場合があります。
- この記事のキーワード
この記事をシェアしてください
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
