[DBA] データベース記憶域構造の管理
ORACLE MASTERの取得を目指した連載の第8回は、データベースを構成するファイル群について学ぶ。
2017年3月23日 0:00
皆さんこんにちは! 前回は、リモート接続の方法とOracleインスタンスについて学習しました。インスタンスとデータベースの違いをしっかりと把握していただけたかと思います。忘れてしまった方は復習してくださいね! 第8回めとなる今回は、制御ファイル、データファイル、REDOログといったデータベースの記憶域構造の部分を学習してきます。本連載も今回を含めて残り2回となりました。最後まで息切れしないように頑張っていきましょう!
データベース・ファイル
さて、前回の復習となりますがデータベースを構成しているファイルにはどのようなものがあったか、以下の図でおさらいです。

データベースを構成しているファイル
赤枠で囲んだ部分が、データベースを構成している物理ファイルになります。今回は記憶域構造の管理として各種ファイルがどのような用途で使われているのか、またどのような情報が格納されているのかについて、しっかりと確認していきましょう。
制御ファイル
制御ファイルにはデータベースを構成するデータファイルやREDOログの名前や場所、ステータス情報が格納されています。では制御ファイルの場所はどこに記載されているのかというと、初期化パラメータCONTROL_FILESで指定されています。SQL*PLUSのshow parameter コマンドで確認してみるといいでしょう。以下、実行例です。
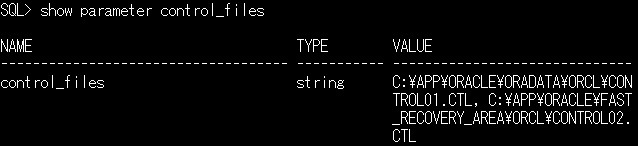
制御ファイルの場所をコマンドで確認
上記の例では、カンマ区切りで2つの場所が指定されています。
C:\APP\ORACLE\ORADATA\ORCL\CONTROL01.CTL
C:\APP\ORACLE\FAST_RECOVERY_AREA\ORCL\CONTROL02.CTL
制御ファイルは重要なファイルですので、ファイル損失によるデータベース障害を防ぐために通常は多重化して運用します。ではここで制御ファイルに関する問題をやってみましょう。
制御ファイルについて正しい説明を述べているものを1つ選択してください
(a)制御ファイルの場所はアラートログファイルに記載されている
(b)制御ファイルは初期化パラメータファイルの記載に基づいてNOMOUNT時に読み込まれる
(c)制御ファイルにはデータファイルやアラートログファイルの場所が格納されている
(d)制御ファイルにはチェックポイント情報が格納されている
(e)制御ファイルの場所はデータファイルに記載されておりMOUNT時に読み込まれる
それでは解説です。まず制御ファイルはデータベース起動のどの段階で読み込まれるか? を考えましょう! イメージ図がパッと思い浮かびますか? 分からなかった方は第7回のNOMOUNT、MOUNT、OPENの図解を再確認しましょう。答えは「MOUNT時に読み込まれる」ですね。データベースをOPEN状態にもっていくには、データファイルやREDOログの読み込みが必要になりますが、それらの名前や場所の情報を持っているのが制御ファイルです。起動の流れもしっかりと図を描けるようにしておきましょう。
では、個々の選択肢を見ていきます。制御ファイルの場所は初期化パラメータのCONTROL_FILESで指定しますので、選択肢(a)は誤りです。選択肢(b)は「NOMOUNT時に読み込まれる」とあるので、これも誤りです。制御ファイルにはデータファイルやREDOログの情報が格納されていますが、アラートログファイルの情報はありませんので選択肢(c)も誤りですね。さて、選択肢(d)に「チェックポイント」という用語が出てきましたので、こちらを詳しく説明をしましょう。OracleはSCN(System Change Number)と呼ばれる内部タイムスタンプをもっており、データが更新されるとこの値がカウントアップされます。チェックポイントが実行されると、メモリー上(バッファキャッシュ)の変更済みデータがデータファイルにすべて書き出され、その時点のSCNが制御ファイルに記録されます。つまり制御ファイルには「メモリー情報をどこまで物理記憶域であるデータファイルへ反映したか」の情報が格納されているということになります。
チェックポイント動作のイメージ図、関連するプロセスについて以下にまとめておきます。
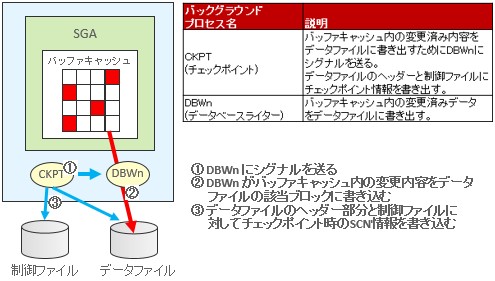
チェックポイント動作のイメージ図
以上のことより、選択肢(d)の内容は正しい内容となります。最後の選択肢(e)は後半部分の「MOUNT時に読み込まれる」という内容は正しいですが、制御ファイルの場所はCONTROL_FILESで指定するので誤りですね。したがって正解は(d)となります。
データファイルと表領域
それでは次にデータファイルにいきましょう。データファイルは文字通り、データベースのデータを格納するファイルになります。データファイルに格納される情報としては、ユーザーが作成する表や索引などのデータや「データディクショナリ」と呼ばれるデータベース自身の管理データなどがあります。表や索引の作成時には、個々のデータファイルを指定するのではなく表領域という論理領域を指定していきます。まずはデータファイルと表領域の関係性を正しく把握しておきましょう。
- 表領域は1つ以上のデータファイルで構成される
- データファイルは1つの表領域のみに属する
- セグメントは1つの表領域内にある複数のデータファイルに分かれて格納できる
言葉だけ見ていると何やら難しいですね(笑)。まずは1と2についての説明のために図を描いてみます。
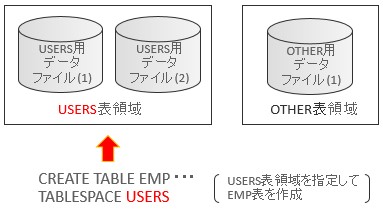
表領域を図示してみる
USERS表領域にはUSERS表領域用のデータファイルが2つあり、OTHER表領域にはOTHER表領域用のデータファイルが1つありますね。このように表領域には1つ以上のデータファイルで構成され、データファイルは必ず1つの表領域に属します。USERS表領域用のデータファイルが、OTHER表領域にまたがるということはありません。
上の図には、CREATE文でEMP表を作成するSQLが書いてありますが、表の格納先を指定するために、データファイルの名前や場所ではなく表領域を用いている点も合わせて確認できるかと思います。
残りの3について説明します。文章の後半部分である「表領域内にある複数のデータファイルに……」という部分は先ほど確認したので問題ないとして、前半部分の「セグメント」という用語が初めて出てきました。セグメントは表などのスキーマ・オブジェクトを構成する要素です。
他にも「エクステント」「データ・ブロック」という構成要素がありますので、しっかりと押さえておく必要があります。言葉だけ暗記しても意味がないので、以下の処理STEPの図を見ながら確認していきましょう。
STEP 1
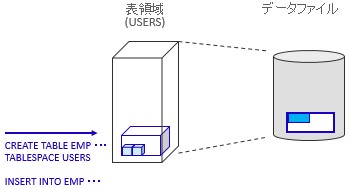
表領域の使われ方STEP 1
SQL文は、USERS表領域にEMP表を作ってデータをINSERTするという内容です。それに従って、EMP表専用の入れ物を表領域に作って、そこにデータをINSERTしています。表領域は論理領域となりますので、実際のデータはデータファイルに存在しています。
STEP 2
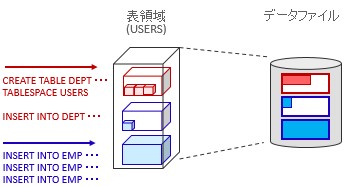
表領域の使われ方STEP 2
EMP表へデータのINSERTが続きます。最初に用意した入れ物が一杯になりましたので、新たにEMP表用の入れ物を作って処理を続けています。さらに、別の表であるDEPT表を作ってデータを入れる操作も加わりました。EMP表とは別の表になりますので、DEPT表専用の入れ物を表領域に作ってデータのINSERTを行っていきます。
STEP 3
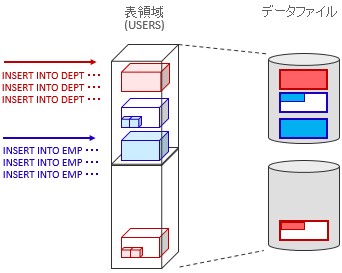
表領域の使われ方STEP 3
EMP表、DEPT表へのデータINSERTが続き、DEPT表用の入れ物が一杯になりました。新たに入れ物を作ってINSERT処理を続けようとしましたが、データファイルの領域が一杯の状態となりました。EMP表用の入れ物はまだ空いていますが、DEPT表のデータは入れることができません。そのためUSERS表領域用のデータファイルをあらたに追加して、領域を増やしました。領域を増やしたことでDEPT表用の入れ物を作り、データのINSERTを継続しています。
はい、ここまでの説明の中ですでにセグント、エクステント、データ・ブロックの図が出てきていますので、以下の内容で最終確認です。
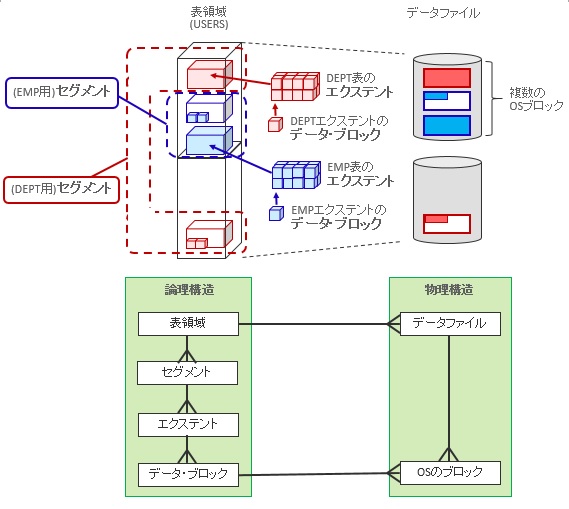
表領域と実際のデータファイルの関係
「セグメントは1つの表領域内にある複数のデータファイルに分かれて格納できる」というのが3の記載でした。上図のDEPT用セグメントを見ていただくと分かるように、複数のデータファイルに分かれて格納されているのが確認できますね。イメージができたところで、それぞれの用語をまとめておきましょう。
データ保存の論理構造に関する用語
| 用語 | 説明 |
|---|---|
| 表領域 | 1つ以上のデータファイルから構成され、1つ以上のセグメントを格納できる |
| セグメント | 1つ以上のエクステントにより構成される |
| エクステント | 連続したデータ・ブロックにより構成される |
| データ・ブロック | OracleにおけるI/Oの最小単位(複数のOSブロックにより構成) |
かなり説明が長くなりましたが、この表領域、データファイルの関係性と構造を把握した上で問題を解いていきましょう!
表領域に関する説明して誤っているものを2つ選択してください。
(a)データファイルは複数の表領域で共有することはできない
(b)エクステントは連続したデータ・ブロックから構成される
(c)セグメントは複数のデータファイルをまたがることができない
(d)エクステントは複数のデータファイルにまたがることができる
(e)セグメントは1つ以上のエクステントにより構成される
先ほどのイメージ図を思い出してください。まず選択肢(a)ですが、表領域は1つ以上のデータファイルで構成されるため複数のデータファイルを扱うことができますが、特定のデータファイルを複数の表領域で共有することはできません。USERS表領域用のデータファイルを、OTHER表領域は扱えないですよね。よって(a)の記述は正しい内容です。選択肢(b)はまさにそのとおりなので、正しい内容です。この内容とあわせて選択肢(d)を見てみましょう。エクステントは連続したデータ・ブロックから構成されなければいけないため、1つのエクステントが複数のデータファイルにまたがることはできません。よって、選択肢(d)の内容は間違っています。選択肢(c)は、先に解説した図解のDEPT表セグメントをもう一度見てみましょう。複数のデータファイルに格納されていますよね。よって(c) は誤った内容となります。最後残った選択肢(e)は正しい内容になります。誤っているものを選択する問題なので、正解は (c) と (d) になります。
表領域に関する問題をもう1問やってみましょう。
特定の表領域のサイズを拡張したい。拡張方法として正しいものをすべて選択してください。ただし特定の表領域はsmallfile表領域を使用しているとします。
(a)表領域のデータファイルのサイズを増やす
(b)表領域にデータファイルを追加する
(c)smallfile表領域は領域の拡張ができないためbigfile表領域に変更する
(d)表領域に対応するデータファイルが自動拡張(AUTOEXTEND)するように設定する
(e)拡張したい表領域と同じ名前で表領域を新規作成する
表領域の拡張方法の問題です。「smallfile」「bigfile」という用語が出ていますが、これは表領域を作成するときのデータファイルのタイプとなります。違いについて以下の表で確認しておきましょう。
データファイルの種別について
| データファイル・タイプ | 説明 |
|---|---|
| BIGFILE | bigfile表領域に格納されるのは1つのデータファイルまたは一時ファイルのみであり、このファイルには最大約40億(2の32乗)ブロックを格納できる |
| SMALLFILE | smallfile表領域は、Oracle従来の表領域であり最大で1022のデータファイルまたは一時ファイルを含めることができ、それぞれのファイルは最大で約400万(2の22乗)のブロックを格納できる |
大規模システムなどでは最大で約40億データ・ブロックを格納できるBIGFILEの使用が好ましいことがあるかもしれません。BIGFILEの注意点は、表領域に対応するデータファイルが1つに制限され、後から追加することができないという点ですね。領域が不足した場合は、既存のデータファイル自体のサイズを大きくする必要があります。
さぁ「smallfile」「bigfile」が何者か分かったところで選択肢を見ていきましょう。選択肢(a)のように、smallfile表領域であっても既存のデータファイル自体のサイズを大きくすることは可能ですので、正しい内容です。選択肢(b)も正しい内容です。先の説明でデータファイルを追加した図がありましたね。選択肢(c)は「smallfile」「bigfile」が理解できていないと選んでしまいそうですが、誤った内容です。選択肢(d)のようにデータファイルの自動拡張(AUTOEXTEND ON)の設定は表領域作成時、あるいは作成後に行うことができますので、正しい内容です。選択肢(e)は、表領域の構造が理解できていれば間違った内容であることが分かりますよね。正解は(a)(b)(d)となります。
表領域にはユーザーが作成する以外に以下のような事前定義済みのものがありますので、あわせて確認しておきましょう。
事前定義済みの表領域
| 表領域名 | 説明 |
|---|---|
| SYSTEM | データディクショナリ表および他の管理データが含まれる |
| SYSAUX | SYSTEM表領域の補助表領域 |
| UNDOTBS1 | トランザクションのロールバックや読み取り一貫性のためのUNDOデータが格納される |
| TEMP | ソート処理など、セッション継続中にのみ存在する一時データを含む |
| USERS | ユーザーが作成する表、索引データを格納するためのデフォルト領域 |
| EXAMPLE | サンプルスキーマ(HR、SHなど)のための領域 |
REDOログ
REDOログというのはデータベースの変更履歴が記録されるファイルになります。例えばUPDATE文によってデータを「A」から「B」に変更した場合、この内容がREDOログファイルに格納されるといった具合です。これも図を描いて確認しておきます。

REDOログの働き
上記の図にあるように、COMMITを実行してもバッファキャッシュ上の変更されたデータはデータファイルにすぐに反映されるとは限らないという点が重要です。COMMITやROLLBACKの際に毎回データファイルにアクセスしてデータの書き換えを行っているとパフォーマンスに影響が出るため、REDOログに変更情報を残しておくというわけですね。もし何らかのトラブルによりインスタンスがダウンしてメモリー上のデータがなくなってしまっても、物理ファイルであるREDOログに変更履歴が残っていれば、確定したデータに対して復旧ができるというわけです。REDOログの役割が分かったところで問題にいきましょう。
REDOログファイルについて正しい内容を述べているものを3つ選択してください。
(a)データベースへの変更履歴を保存するために使用される
(b)インスタンスリカバリの際にCOMMITされた変更内容をロールフォワードするために使用される
(c)データベースの変更を元に戻すために使用される
(d)REDOログはディスク障害に備えて多重化することが望ましい
(e)データベースにREDOログのグループは1つ以上必要である
では解説です。選択肢(a)はREDOログの説明となるので正解です。選択肢(b)ですが、インスタンスが何らかの問題により異常終了した場合、次回起動時に自動的にインスタンスリカバリが実行されます。その際にCOMMITされた内容がデータファイルに反映されていない場合はREDOログファイルの内容を使って変更内容をロールフォワードして復旧します。(b)の内容も正しいですね。選択肢(c)のデータベースの変更内容を元に戻すのはUNDOデータとなるので、これは誤りです。REDOとUNDOの違いについても押さえておきましょう。
選択肢(d)と(e)は以下の図を見ながらあわせて確認していきます。
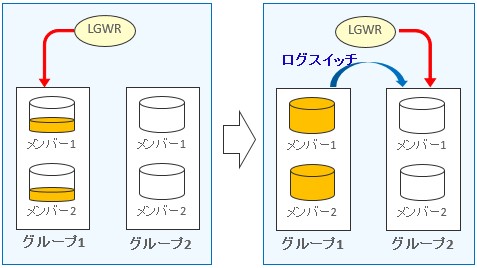
REDOログのスイッチ
REDOログはグループとメンバーから構成され、REDOログを多重コピーしたファイルはグループ内のメンバーと呼ばれます。上の図では各グループ内にメンバーが2つありますので、REDOログを多重化している状態です。左側の図からみていきましょう。LGWR(ログ・ライター)がREDOログバッファの内容をREDOログに書き出している様子を示しており、グループ1の全メンバー(メンバー1、メンバー2)に同じレコードが書き込まれていきます。
しばらく運用を続けることによりグループ1のREDOログが一杯になったため、書き込み先をグループ2へ変更している様子を示しているのが右側の図になります。このような書き込み先を変更する動作のことをログスイッチといいます。されに運用を続けることでグループ2のREDOログが一杯になった場合は、再び書き込み先をグループ1へログスイッチします。このようにREDOログは循環式に使われていくため、REDOログのグループは必ず2つ以上必要になります。
メンバーについてはグループ内に1つ以上あれば運用可能ですが、障害に備えて多重化することが望ましいです。
例えば以下の図のように2つ以上のメンバーが存在していれば、1つのメンバーに障害が発生しても運用を継続することが可能です。
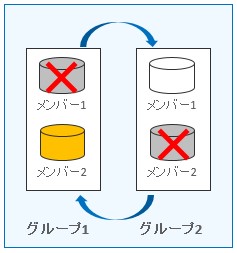
メンバーを複数持つことで、障害時にも運用を継続できる
では、選択肢の確認にもどりましょう! 選択肢(d)は多重化するのが望ましいと書いてあるので正しい内容ですね。REDOログは循環する必要があるため、グループは2つ以上必要となりますので、選択肢(e)は誤りです。メンバーとグループを混同しないように、イメージ図がしっかりと描けるようにしておきましょう。以上の内容から正解は(a)(b)(d)になります。
今回は記憶域構造の管理として、データベースを構成するファイルについて学習しました。内部のアーキテクチャの話が出てきて少し戸惑った方もいたかもしれませんが、前回と同様、絵を描いて理解するという学習方法をぜひ取り入れてください。蓄積していった知識がパーッと繋がり、目の前の道が開ける! という感覚を得られること間違いなしです(笑)。用語だけをただ暗記するというのは絶対にNGですよ。さて今回の連載も、とうとう次回で最後になりますが一緒に頑張っていきましょう!
* OracleとJavaは、Oracle Corporation 及びその子会社、関連会社の米国及びその他の国における登録商標です。文中の社名、商品名等は各社の商標または登録商標である場合があります。
- この記事のキーワード
この記事をシェアしてください
関連記事
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
