データを集めて可視化しよう(Twitterのつぶやき履歴編)
【誰でも簡単にログ分析!OSSのBIツールElastic Stack解説書!】 株式会社インプレスR&Dより発行された「Elastic Stackで作るBI環境 誰でもできるデータ分析入門」の立ち読みコーナー第3回です。
2018年5月14日 10:00
「セットアップはできたけれど、実際にログをElasticsearchに集めてこないといけないな…。でもどうやってElasticsearchにデータを入れたらいいのかな?」
もふもふちゃん、ついにログの収集を始めるようです。まずはTwitterのつぶやき履歴をLogstashで収集・加工しElasticsearchへ連携するところから始めましょう。
Twilogサービスを利用したログ取得(ログデータの準備)
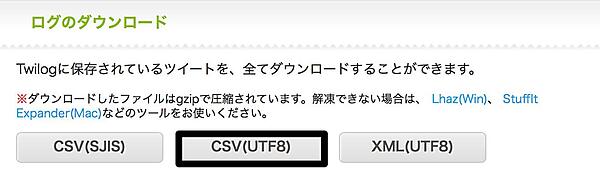
まずはLogstashに取り込むデータを準備します。今回はTwitterアカウントの発言を追いかけるため、Twilogサービスを利用します。Twilogとは、Twitterでのツイートを自動で保存・閲覧できるサービスです。記録された履歴はCSV(SJIS/UTF-8)やXMLでダウンロードできます。今回はCSV(UTF-8)でダウンロードします。
Twilogサービスへの登録
まず、Twilog公式サイト(http://twilog.org)へアクセスします。Sign in with Twitterアイコンをクリックし、Twitterの認証画面でTwilogに自分のTwitterアカウントを登録してください。
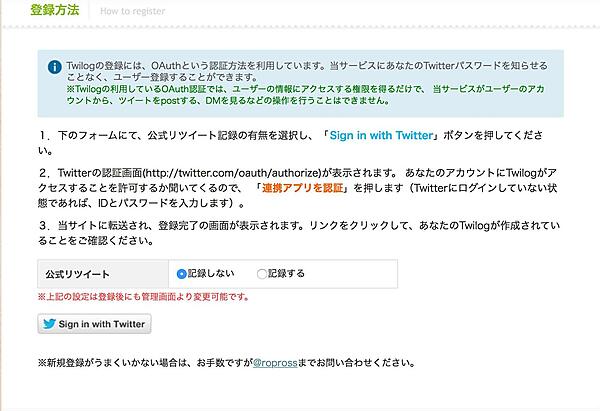
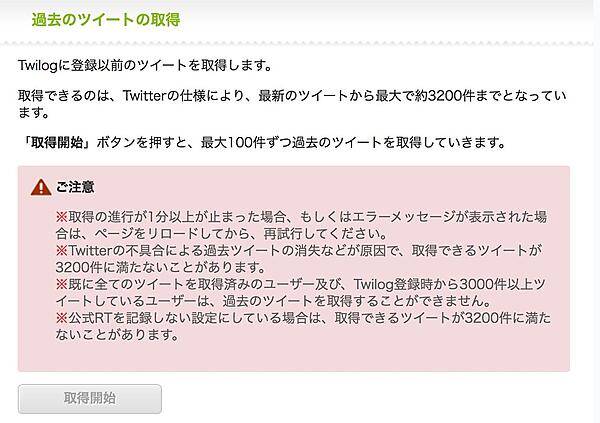
認証後、Twilogの管理画面へアクセスします。Twilogのデフォルト設定では、直近200件分の過去ツイート情報しか取得できません。ログ数を増やすため、過去ツイートの取得から昔のツイートを全て取得しておきましょう。
過去ログのダウンロード
いよいよ過去ログのダウンロードを行います。とは言っても図3.3の画面から好きな形式を選択してダウンロードするだけです。zip圧縮されているため、適宜解凍してください。ログは好きなディレクトリに配置して良いですが、読み取り権限がついているか確認してください。
ログを解凍して中身をみると、このように表示されました。これを延々と読むのはなかなか辛いものがあります。左から、Twitter ID、つぶやいた日時、つぶやいた時、本文となっています。
ログの中身(例)
"839273776948731904","170308 093716","でもその前に、トラブルシュートのダルさだけはなんとかしてほしいもんだな"
"839273607192690688","170308 093635","KibanaのURLを共有しとけば簡単にレポートとか作れちゃうんだもんなあ"
"839273190639591425","170308 093456","Elastic{ON}のKeynote見たけど、Kibana Canvasは良さそうだと思いました"それではこのCSVファイルをLogstashに取り込んでみましょう。
logstash.confとは?
Logstashのデータ取得・加工・データ送付先はlogstash.confで設定します。logstash.confはinput、filter、outputの3つに分かれています。動作確認時に少し記載しましたが、この章では本格的にlogstash.confを記載します。
logstash.confの記載を変更する場合、念のためLogstashサービスを停止しておきましょう。
input
inputは、ログをどこから取得するか決める部分です。ログの取得間隔や、Logstashサービス再開時の挙動を指定することも可能です。
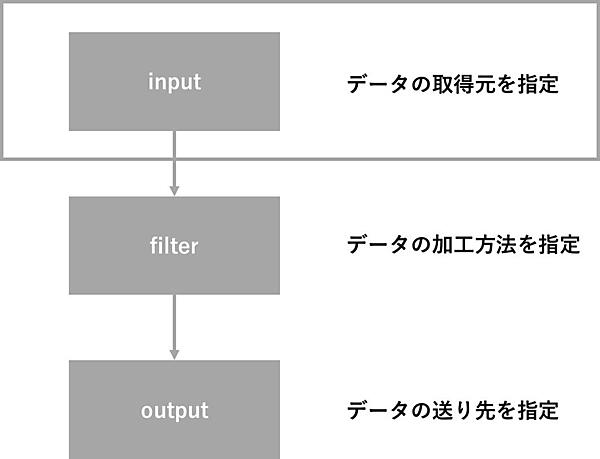
filter
filterは、ログをどのように加工・整形するか決める部分です。「加工」とはいっても、取り込んだログの文言を書き換える、条件に一致するログを消去する等方法は様々です。
output
outputは、ログをどこに送るか指定する部分です。前の章でも述べた通り、Elasticsearchへのデータ送付以外にもCSV形式など指定した拡張子でデータを出力することも可能です。
inputプラグイン
input部分では情報の取得元ごとにプラグインが提供されています。今回はファイルを取得するため、fileプラグインを使います。利用できるプラグインの種類はhttps://www.elastic.co/guide/en/logstash/5.4/input-plugins.htmlで確認できます。
logstash.confの記載はJSON形式で行います。inputプラグインであれば、次のように記載します。
inputプラグインの記載方法
input{
利用するプラグイン名{
設定を記載
}
}pathの記載
各プラグインには必須項目があります。fileプラグインではpathが必須項目にあたります。path => ファイルパスのように指定します。パスの指定には正規表現を利用できますが、フルパスで記載する必要があります。
pathの指定
input{
file{
path => "/フォルダのフルパス/logs/**.csv"
}
}取り込んだログを標準出力する
outputにstdoutを指定すると、コンソール上に標準出力できます。まずはファイルが取り込みできるかテストしてみましょう。
CSVをLogstashに取り込み標準出力するlogstash.conf
input{
file{
path => "/フォルダのフルパス/logs/**.csv"
}
}
output{
stdout{ codec => rubydebug }
}logstash.confの記載ができたら、Logstashを起動します。ここではserviceコマンドを使わず、binディレクトリに配置されている起動スクリプトを利用して起動しましょう。
Logstashの起動
$ sudo /opt/logstash/bin/logstash -f /etc/logstash/conf.d/logstash.conf
-返り値は省略------------------------------------------------------
Pipeline main started
Successfully started Logstash API endpoint {:port=>9600}
//}ファイルの読み込み位置を指定する
実際に実行してみるとわかりますが、このままではLogstashの標準出力には何も表示されません。デフォルトの設定では、起動した後に更新された分だけファイルを読み取る設定になっているためです。
どこまでファイルを読み取ったかは、Logstashが自動で「sincedb」というファイルに記録しています。設定を変更することでsincedbファイルに記録されている履歴の次から情報を取得できます。ファイルの読み込み位置はstart_positionを用いて設定します。
start_positionの指定
# Logsatsh起動後に追加されたログのみ取り込む場合(デフォルト)
start_position => "end"
# Logsatshが停止後に追加されたログも取り込む場合
start_position => "beginning"logstash.conf上で指定する場合、start_positionオプションを自分で追記し「beginning」と記載します。
start_positionを指定したlogsatsh.conf
input{
file{
path => "/フォルダのフルパス/logs/**.csv"
start_position => "beginning"
}
}ファイルにタグをつけて分類する
読み込んだデータを分類したい場合、自分でタグ(tags)をつけることができます。tagsを利用すると、if文などを用いて取り込んだデータに対する固定の処理を指定できます。Kibanaのグラフを作成する際にtagsを指定すると、1つの情報のまとまりごとにデータを分析するグラフを作ることができるようになります。「tags => "好きな名前"」で指定します。
CSVのログにタグ名「CSV」をつける
input{
file{
path => "/フォルダのフルパス/logs/**.csv"
tags => “CSV”
}
}指定したファイルの種類は除外する
zipファイルなど、取り込み対象から除外したいものがある場合、excludeを利用することで指定したものをLogstashの取り込み対象から外すことができます。こちらはフルパス指定は不要です。正規表現を用いて指定できます。「例えば201705」と名前がついているcsvファイルを取り込み対象から外す場合、次のように記述します。
# zipファイルを取り込みから除外する
input{
file{
path => "/フォルダのフルパス/logs/**.csv"
exclude => "201705*.csv"
}
}今まで紹介した設定を全て追加すると、logstash.confはこのようになります。
inputプラグインを追加したlogstash.conf
input{
file{
exclude => "*.zip"
path => " /tmp/logs/**.csv"
start_position => "beginning"
tags => "CSV"
}
}
output{
stdout{ codec => rubydebug }
}この状態でLogstashを起動すると、CSVのデータが標準出力されます。
$ sudo /opt/logstash/bin/logstash -f /etc/logstash/conf.d/logstash.conf
-返り値は省略------------------------------------------------------
Successfully started Logstash API endpoint {:port=>9600}
{
"path" => "/Users/mofumofu/ELK_Stack/logs/froakie0021170311.csv",
"@timestamp" => 2017-03-11T13:07:15.099Z,
"@version" => "1",
"host" => "XX.local",
"message" => "",
"tags" => [
[0] "CSV"
]
}
{
"path" => "/Users/mofumofu/ELK_Stack/logs/froakie0021170311.csv",
"@timestamp" => 2017-03-11T13:07:15.113Z,
"@version" => "1",
"host" => "XX.local",
"message" => "\"730751058306162689\",\"160512 222643\",\"いちごメロンパン食べたい\"",
"tags" => [
[0] "CSV"
]
}outputプラグイン
Kibana上でグラフを作成するためにはElasticsearchにデータが入っている必要があります。このままでは標準出力に取り込んだデータが出てくるだけで、Elasticserachには何もデータがありません。outputプラグインを用いてデータの送り先を指定しましょう。
Elasticsearchにデータを送る
Elasticsearchにログを送付するにはelasticsearchプラグインを利用します。必須項目はありませんが、Elasticsearchのホスト名を指定しない場合、「localhost:9200」にアクセスします。
ElasticsearchのURLを明示的に設定するためにはhostsを利用します。hosts => "Elasticsearchのアクセス用URL"で指定します。
elasticsearchプラグインの指定(ElasticsearchのURLが10.0.0.100の場合)
output {
elasticsearch{
hosts => "http://10.0.0.100:9200/"
}
}送付先indexの指定
Elasticsearchはデータの持ち方がfieldに対するtextという構造になっています。fieldとは、データベースでのカラムに相当します。textはカラムの中に入っている実データです。カラムの中にデータを入れるのと同じように、field内に実際のデータ(text)を保持します。このデータの集まりをindexといいます1。fieldの集まりをドキュメントと呼び、これは1件分のデータに相当します。
デフォルトのindex名は"logstash-%{+YYYY.MM.dd\}"です。elasticsearchプラグインのindexを用いることでindex名を変更できます。
index名の変更
index => "%{index名}-%{+YYYY.MM.dd}"今回はindex名は変更せず、デフォルトの設定のまま利用することにします。ただし1つのElasticsearchに種類の異なるデータを集める場合、データを保存するindexを明示的に指定し保存すると、indexとデータの内容を紐付けることができます。よって、データの管理・運用を楽にすることができます。
これで、outputプラグインも書くことができました。他のプラグインを利用すると、データをファイルに出力することも可能です。利用できるプラグインは公式サイトhttps://www.elastic.co/guide/en/logstash/current/output-plugins.htmlに一覧があります。
では、再度outputプラグインの設定も追加したlogstash.confをみてみましょう。次のようになります。ElasticsearchのURLは独自に設定したものに変更して下さい。
outputを記載したlogstash.conf
input{
file{
exclude => "*.zip"
path => " /tmp/logs/**.csv"
start_position => "beginning"
tags => "CSV"
}
}
output{
stdout{
codec => rubydebug
}
elasticsearch{
hosts => "http://10.0.0.100:9200/"
}
}filterプラグイン
今の状態だと、ログはこのようにElasticsearchへ連携されます。=>の左側はfield、右側は実際のデータです。
標準出力で出ているログ
{
"path" => "/Users/mofumofu/ELK_Stack/logs/froakie0021170311.csv",
"@timestamp" => 2017-03-11T13:07:15.113Z,
"@version" => "1",
"host" => "XX.local",
"message" => "\"730751058306162689\",\"160512 222643\",\"いちごメロンパン食べたい\"",
"tags" => [[0] "CSV"]
}これをこのままKibanaで可視化するのは抵抗があります。というのも、field名「host」ではホスト名が丸見えです。サーバーのホスト名であればまだ良いですが、仮に個人PCでLogstashを起動している場合、自分のPC情報がKibanaで閲覧できてしまいます。
さらに、@timestampはUTC時間で出力されており、ログの出力時刻はLogstashにデータ連携された時間となっています。このままではいつツイートしたのかを追いかけることはできません。もっと欲を言えば、messageの中のログは1つの情報ごとに分割したいですよね(今回はCSVのカラム単位に分割します)。このままでは肝心の中身を詳しく分析することができません。
そこで、filterプラグインを使ってログの中身を整形する必要があります。プラグインの一覧はhttps://www.elastic.co/guide/en/logstash/current/filter-plugins.htmlに情報がまとまっていますので、扱うデータに合わせて使用するプラグインを変更しましょう。
また、filterプラグインは記述した順番に処理が行われます。ログの加工順序を考えつつ、filterプラグインを記載すると良いでしょう。
ちなみに、このURLの「current」は最新バージョンのURLリンクです。利用するLogstashのバージョンが最新版でない場合、currentをバージョン名に変更してください。例えばLogstashのバージョンが5.4の場合、https://www.elastic.co/guide/en/logstash/5.4/filter-plugins.htmlのように指定します。
CSV形式のログを分割する
CSV形式のログを分割するためにはcsvプラグインを利用します。必須項目はありません。filterプラグインの中にcsv {} と記述すれば最低限の分割はできます。
filterにcsvを指定したlogstash.conf
input{
file{
exclude => "*.zip"
path => " /tmp/logs/**.csv"
start_position => "beginning"
tags => "CSV"
}
}
filter{
csv{
}
}
output{
stdout{
codec => rubydebug
}
elasticsearch{
hosts => "http://localhost:9200/"
}
}実際にログを出力すると、column1などと、カラムごとにfieldも分割されます。
csvフィルタを指定してLogstashを起動した場合
{
"column1" => "700941673379987456",
"path" => "/Users/mofumofu/ELK_Stack/logs/froakie0021170311.csv",
"@timestamp" => 2017-03-11T14:20:08.119Z,
"column3" => "test",
"column2" => "160220 161452",
"@version" => "1",
"host" => "XX.local",
"message" => "\"700941673379987456\",\"160220 161452\",\"test\"",
"tags" => [
[0] "CSV"
]
}カラムのデータ型を変更する
よく見るとcolumn2は年・月・日と時刻となっており、日付のデータです。今はテキスト扱いなので、日付型として扱うことができません。
このように、データの型を変更したい場合convertオプションを使うと、column1、column2(以下略)内のデータ型を変更できます。{convert => { "column2" => "変更したい型" } のように記載します。変更できる型の種類はhttps://www.elastic.co/guide/en/logstash/current/plugins-filters-csv.html#plugins-filters-csv-convertを参照してください。
今回はcolumn2の中に日付と時刻が記載されているため、column2のみ型を変更します。
convertを記載したlogstash.conf
filter{
csv{
convert => {
"column2" => "date_time"
}
}
}不要なfieldを消す
時には見せたくないカラムの情報もあるかと思います。今回はcolumn1、path hostの情報は不要なので消します。
不要なfield(今回の場合)
{
"column1" => "700941673379987456",
"path" => "/Users/mofumofu/ELK_Stack/logs/froakie0021170311.csv",
"host" => "XX.local",
}不要なfieldを削除する場合、remove_fieldオプションを利用します。remove_field => ["削除したいfield名"]のように指定します。複数指定する場合、コロンで繋げます。
remove_fieldオプションの指定例
filter{
csv{
remove_field => ["column1", "host", "path"]
}
}実行すると、指定したfieldが削除されます。
remove_field指定後の出力結果
{
"@timestamp" => 2017-03-12T01:16:04.983Z,
"column3" => "いちごメロンパン食べたい ",
"column2" => "160512 222643",
"@version" => "1",
"message" => "\"730751058306162689\",\"160512 222643\",\"いちごメロンパン食べたい\"",
"tags" => [
[0] "CSV"
]
}ログが出力された時刻を編集する
@timestampの時刻が実際のログとずれる理由ですが、Logstashの仕様に原因があります。Logstashはデータを取り込んだ時間を@timestampとして付与します。これにより、データの持っている時刻と@timestampの時間がずれているように見えたのです。
また、Logstashは世界標準時間(UTC)を利用するので、日本時間からマイナス9時間となっています。これらを解消するためには、@timestampの情報をデータ内の情報で置き換える必要があります2。
時刻を変更したい場合dateフィルタを指定します。dateフィルタのmatchオプションを使ってどのfieldを時刻として利用するか決定しましょう。match => ["field名", "実データの日付記載方式" または "変換方法"]と指定します。
field名column2内のデータ"16年05月12日 22時26分43秒"を置き換える場合、以下の指定方法となります。match => [ "column2", "YYMMdd HHmmss", "ISO8601" ]と指定すると、"YYMMdd HHmmss"の形式または"ISO8601"のデータがログに含まれていた場合@timestampに変換します。
matchオプションの指定例
date{
match => [ "column2", "YYMMdd HHmmss" ]
}
//}
# 実際に出力してみると、@timestampの項目がログの時刻と一致する。
//emlist[
matchオプション指定後の出力結果(抜粋)
]{
{
"@timestamp" => 2016-05-12T13:26:43.000Z,
"column2" => "160512 222643",
}時刻の指定方法はhttps://www.elastic.co/guide/en/logstash/current/plugins-filters-date.htmlに記載があります。変換方法はカンマで複数指定できます。
logstash.confのテスト方法
logstash.confを作成するときは、このようにログの取り込み・出力を繰り返しながら必要に応じてデータが連携されるように調整を繰り返すことになります。logstash.confの編集を繰り返していくと文法ミスが見つけにくくなるため、適宜コンフィグファイルのテストを行いましょう。
コンフィグファイルのテストはLogstashの起動時に-tオプションを指定するだけです。コンフィグファイルが間違っている場合、行数がエラー出力されます。
記載していたコンフィグ(抜粋)
filter{
csv{
convert => {
"column2" => "date_time"
}
remove_field => [ "column1", "host", "message", "path", "@version" ]
}
date{
match => [ "column2" => "YYMMdd HHmmss", "ISO8601" ]
remove_field => [ "column2" ]
}
}コンフィグテストの例
$ sudo /opt/logstash/bin/logstash -f /etc/logstash/conf.d/logstash.conf -t
# 出力結果
[2017-03-12T10:50:00,519][FATAL][logstash.runner] The given configuration is invalid.
Reason: Expected one of #, {, ,, ] at line 18, column 25 (byte 323) after filter{
csv{
convert => {
"column2" => "date_time"
}
remove_field => ["column1", "host", "message", "path", "version"]
}
date{
match => ["column2"間違っていた箇所は、date filterのmatchオプションの部分です。カンマでfield名と時間の指定方法を区切るべきでしたが、=>で区切っていたのでエラーとなっていました。
間違っていた箇所
date{
match => [ "column2" => "YYMMdd HHmmss", "ISO8601" ]間違っていた箇所(正解)
date{
match => [ "column2" , "YYMMdd HHmmss", "ISO8601" ]具体的にどこが間違っているかは示すことが難しいのが現状ですが、サービスを起動した後にコンフィグファイルが間違っていることに気づくよりは良いはずです。logstash.confを変更した後はテストを行い、正しさを確認しておいた方が良いでしょう。
ここまでで作成したlogstash.confをおさらいする
ここまでのまとめとして、Twilogサービスから取得したCSVファイルをElasticsearchへ連携するlogstash.confの一例を記載します。
column2はdateフィルタで@timestampに変換後は不要なカラムとなるため、削除しました。そのほかにも余計な情報は極力削除しています。また、コメントアウトは# (半角スペース)で行います。
作成したlogstash.conf
input{
file{
exclude => "*.zip"
path => " /tmp/logs/**.csv"
start_position => "beginning"
tags => "CSV"
}
}
filter{
csv{
convert => {
"column2" => "date_time"
}
remove_field => [ "column1", "host", "message", "path", "@version" ]
}
date{
match => [ "column2", "YYMMdd HHmmss", "ISO8601" ]
remove_field => [ "column2" ]
}
}
output{
# stdout{
# codec => rubydebug
# }
elasticsearch{
hosts => "http://localhost:9200/"
}
}実際のデータとLogstashへの取り込み結果を比較してみます。出力結果は標準出力の結果ですが、Elasticsearchにも同じようにデータ連携されます。
取り込んだデータ
"730751058306162689","160512 222643","いちごメロンパン食べたい "標準出力の結果
{
"@timestamp" => 2016-05-12T13:26:43.000Z,
"column3" => "いちごメロンパン食べたい ",
"tags" => [
[0] "CSV"
]
}(次回に続く)
- この記事のキーワード
この記事をシェアしてください
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
