TFXを使った機械学習パイプラインの構築(実装編その1)
連載の4回目となる今回は、TFXを使ってKubeflow上で動かす機械学習パイプラインを構築していきます。
2021年12月22日 10:14
はじめに
前回は、KubeflowのNotebook Serversを使って作成したJupyter notebook上で、データの分析からモデル作成までの手順を解説しながら、初期の機械学習モデル作成を行いました。今回は、そのモデルの本番運用を想定した機械学習パイプラインを構築していきます。複数回に分けてパイプラインの実装からデプロイまで解説していく予定です。本稿は「実装編その1」として、TFXの概要の紹介と機械学習パイプラインの構築のうち前半部分について解説していきます。
TensorFlow Extended(TFX)の概要
TFXは機械学習パイプラインを構築するためのフレームワークです。TFXはパイプライン内の各ステップをコンポーネントとして提供します。そのコンポーネントを組み合わせてパイプラインを定義し、Kubeflowなどのパイプラインオーケストレータで実行します。
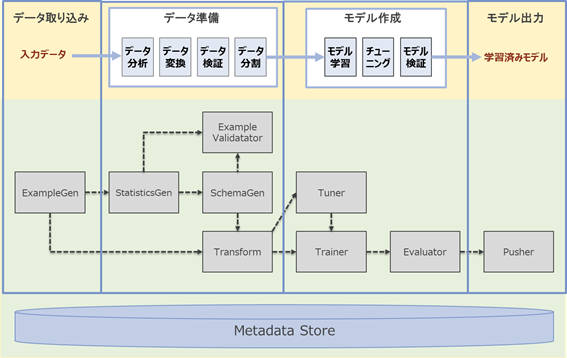
図1:機械学習モデル開発のステップとTFXコンポーネント
TFXが標準で提供するコンポーネントは、前回解説した機械学習モデル開発の各ステップに対応するものとなっています。図1.で示す四角の箱がコンポーネントを、破線がコンポーネント間のデータの流れを表しています。各のコンポーネントの概要は次のとおりです。
TFXのコンポーネントの概要
| コンポーネント | ステップ | 概要 |
|---|---|---|
| ExampleGen | データ取り込み・データ分割 | TFXパイプラインにデータセットを取り込み分割する |
| StatisticsGen | データ分析 | データセットの統計量を計算する |
| SchemaGen | データ分析 | データセットの統計量からスキーマを生成する |
| Transform | データ変換 | データセットを機械学習モデルの学習で利用できるデータに変換する |
| ExampleValidator | データ検証 | 入力データや変換済みデータに対して検証を行う |
| Trainer | モデル学習 | 機械学習モデルの学習を行う |
| Tuner | チューニング | 機械学習モデルのハイパーパラメータチューニングなどを行う |
| Evaluator | モデル検証 | 学習済みモデルに対して評価を行う |
| Pusher | モデル出力 | 学習済みモデルをサービング環境と共有できるストレージなどにPush(アップロード)する |
TFXを使って機械学習パイプラインを構築する際は、この枠組み(フレームワーク)に沿って各ステップの処理を実装していきます。
TFXを使って機械学習パイプラインを構築する主なメリット
- コンポーネント間の依存関係を意識することなく実装できる:TFXを使って機械学習パイプラインを構築する場合は、各ステップに対応するコンポーネントに対し処理を実装します。コンポーネント間の依存関係はTFXによって管理されるため、開発者はその依存関係を意識する必要はありません
- 学習時と推論時のスキュー(不整合)を回避できる:TFXパイプラインで出力するモデルは、データ変換処理と機械学習モデルを一緒にエクスポートできるため、学習時と推論時のスキューを回避できます
- データやモデルの品質を一定に保つことができる:TFXのパイプラインにデータやモデルに対する検証プロセスを組み込むことができます。これにより、新しいデータを取り込んで再学習する際に学習で利用するデータやモデルの品質を一定に保つことができます
- データに対する操作の過程を追跡できる:TFXのコンポーネントは入出力データを直接やり取りせず、メタデータを介してその参照を受け渡します。これによって入出力の情報を集約でき、データセットに対する操作の過程を追跡することなどが可能になります
- 大規模なデータセットに対してもスケールして対応できる:TFXのバックエンドは、大規模データに対してもスケールして対応できる処理エンジンを使用しています。
以降、これらの点についてTFXを使ったパイプラインの実装やKubeflowへのデプロイを通して解説していきます。
機械学習パイプラインの構築(ハンズオン)
本稿では、機械学習パイプラインのステップのうち前半部分の「データ準備」について解説していきます。
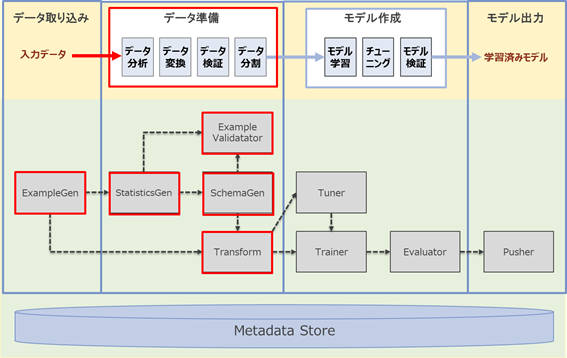
図2-1:機械学習モデル開発のステップとTFXコンポーネント(本稿で解説する範囲を赤枠で記載)
解説の流れ
本稿では、データ準備の各ステップで利用するTFXコンポーネントについて、前回の記事で作成したモデルをベースにTFXでの実装例を交えて解説します。
- 入力データの取り込み:ExampleGenを使ったデータセットの取り込みと分割方法について解説します
- データ分析:StatisticsGenとSchemaGenを使ったデータセットの分析方法について解説します
- データ変換:Transformを使って機械学習モデルの学習に利用できるデータに変換する方法を解説します
- データ検証: ExampleValidatorを使ってデータ検証を行う方法について解説します
- データ分割:上記ステップを経て出力される「学習用データ」と「評価用データ」を取り出し確認する方法について解説します
機械学習パイプライン構築の進め方
TFXは「インタラクティブパイプライン」という機能をサポートしています。インタラクティブパイプラインは、TFXコンポーネントの実行結果を確認しながら段階的に実装を進められる機能です。以降、解説で用いるコード例をJupyter notebook上で順番に実行していくことで、機械学習パイプラインの構築が進んでいきます。
事前準備
- 新しいノートブックの作成
前回作成したNotebook Serverを引き続き利用します。今回の解説向けに、以下の手順で新しいノートブックを作成します。
- 「Kubeflow UI」にアクセス
- 「Notebook Servers」へ画面遷移し、Notebook Server一覧を表示
- 前回作成済みの「example-notebook」に接続
- Python 3のノートブックを作成
Python 3のノートブックの作成が完了したら、次にセットアップを行います。
セットアップ
- 必要なパッケージをインポート
import os
import pandas as pd
import tensorflow as tf
import tensorflow_data_validation as tfdv
import tensorflow_transform as tft
import tensorflow_model_analysis as tfma
from tfx import v1 as tfx
from tfx.components.trainer.executor import GenericExecutor
from tfx.dsl.components.base import executor_spec
from tfx.orchestration.experimental.interactive.interactive_context import InteractiveContext
# TensorFlowの警告出力を抑止する
import logging
import warnings
logger = tf.get_logger()
logger.setLevel(logging.ERROR)
warnings.filterwarnings('ignore')
- 環境変数を設定
os.environ['UNSUPPORTED_DO_NOT_PACKAGE_USER_MODULES'] = 'True'
- インタラクティブパイプラインを利用するためのコンテキストを作成
context = InteractiveContext()
なお、データセットは前回に引き続き「米国国勢調査所得データセット」を使用します。また、前処理や機械学習モデルについても前回作成したものをベースに解説を進めます。データセットの内容や前処理の内容、モデルについては前回記事を参照してください。
入力データの取り込み
はじめに、機械学習パイプラインに入力データを取り込む方法について解説します。このステップでは、TFXで効率よく処理するためのデータ形式への変換とExampleGenというTFXコンポーネントでデータセットをパイプラインに取り込む方法について解説します。
- ExampleGenとは
ExampleGenはパイプラインにデータ取り込みを行うTFXコンポーネントです。ローカルのファイルを読み込むか、Amazon Simple Storage Service(S3)やMinIO(S3互換のオブジェクトストレージ)などのリモートストレージ、Google Cloud BigQueryなどの外部サービスに接続してデータを取り込むことも可能です。それぞれのデータソースに対応したExampleGenの派生コンポーネントが標準で定義されています。
ExampleGen派生コンポーネント
| コンポーネント | 説明 |
|---|---|
| ImportExampleGen | TFRecord ※ 形式のデータ取り込みに対応 |
| CsvExampleGen | CSV形式のデータ取り込みに対応 |
| FileBasedExampleGen | 汎用的なデータファイルの取り込みに対応 |
| BigQueryExampleGen | Google CloudのBigQueryテーブルからのデータ取り込みに対応 |
| PrestoExampleGen | Prestoデータベースからのデータ取り込みに対応 |
上記以外のデータソースからデータ取り込みを行いたい場合は、ExampleGenをベースとした独自のカスタムコンポーネントを作成することも可能です。詳細は公式マニュアル(カスタムコンポーネントの構築)を参照してください。
※ TFRecordとは:大規模なデータセットの読み込みに最適化した軽量フォーマットです。小容量のデータセットであれば、事前にメモリ上に乗せて処理できますが、ディープラーニングのように大容量のデータセットを扱う場合は、メモリ上に乗りきらない場合があります。データセットをTFRecord形式に変換することで分割(通常100~200MB程度に分割)して連続的に読み込むことができます。なお、TFRecordはTensorFlowの推奨形式となっています。
本稿では、ImportExampleGenを使ってTFRecord形式のデータセットを取り込む方法を解説していきます。また、Kubeflowでパイプラインを実行する際、入力データはS3やMinIOなどネットワークアクセスできるリモートストレージから読み込むことが多いでしょう。本稿ではKubeflowの標準コンポーネントとして利用できるMinIOにデータセットをアップロードします。※以降、解説内でMinIOにアップロードする手順が複数ありますが、データセットと同様にKubeflow上でパイプラインを実行する際、その処理で利用する資材(スクリプト、定義ファイルなど)は、リモートアクセスできるストレージに格納する必要があるためです。
それでは、次の流れで入力データを取り込む手順を解説します。
- データファイルを読み込む
- CSV形式のデータセットをTFRecord形式に変換し出力する
- MinIOに変換済みのデータファイルをアップロードする
- ImportExampleGenでデータファイルを取り込む
- 1. データファイルを読み込む
ローカルのデータファイルをPandasのDataFrameに読み込みます。
header = [
'age','workclass','id','education','education-num','marital-status',
'occupation','relationship','race','gender','capital-gain','capital-loss',
'hours-per-week','native-country','income'
]
df = pd.read_csv('adult.data', names=header, delimiter=', ', usecols=lambda x: x not in ['id', 'race', 'native-country'])
- 2. CSV形式のデータセットをTFRecordに変換して出力する
データセット内のレコードをtf.ExampleというTensorFlowのシリアライズ形式に対応したデータ構造に変換します。次のようなヘルパー関数を定義しておくとコードの冗長性を削減することができます。
def _bytes_feature(value):
return tf.train.Feature(bytes_list=tf.train.BytesList(value=[value]))
def _int64_feature(value):
return tf.train.Feature(int64_list=tf.train.Int64List(value=[value]))
def create_tf_example(features, label):
tf_example = tf.train.Example(features=tf.train.Features(feature={
'age': _int64_feature(features[0]),
'workclass': _bytes_feature(features[1].encode('utf-8')),
'education': _bytes_feature(features[2].encode('utf-8')),
'education-num': _int64_feature(features[3]),
'marital-status': _bytes_feature(features[4].encode('utf-8')),
'occupation': _bytes_feature(features[5].encode('utf-8')),
'relationship': _bytes_feature(features[6].encode('utf-8')),
'gender': _bytes_feature(features[7].encode('utf-8')),
'capital-gain': _int64_feature(features[8]),
'capital-loss': _int64_feature(features[9]),
'hours-per-week': _int64_feature(features[10]),
'income': _bytes_feature(label.encode('utf-8')),
}))
return tf_example
ヘルパー関数を使用して、データセットをTFRecord形式のデータファイルに変換します。
tfrecord_data_root = os.path.join(os.getcwd(), 'tfrecord_data', 'span-1', 'v1')
tfrecord_data_path = os.path.join(tfrecord_data_root, 'adult.span-1.tfrecords')
os.makedirs(tfrecord_data_root, exist_ok=True)
with tf.io.TFRecordWriter(tfrecord_data_path) as writer:
for row in df.values:
features, label = row[:-1], row[-1]
example = create_tf_example(features, label)
writer.write(example.SerializeToString())
- 3. MinIOに変換済みのデータファイルをアップロードする
次のようにMinIOの接続設定を記述します。
import boto3
from botocore.client import Config
os.environ['AWS_ACCESS_KEY_ID'] = 'minio'
os.environ['AWS_SECRET_ACCESS_KEY'] = 'minio123'
os.environ["AWS_REGION"] = 'ap-northeast-1'
os.environ["S3_ENDPOINT"] = "http://minio-service.kubeflow.svc.cluster.local:9000"
s3_resource = boto3.resource('s3',
endpoint_url = os.environ["S3_ENDPOINT"],
aws_access_key_id = os.environ['AWS_ACCESS_KEY_ID'],
aws_secret_access_key = os.environ['AWS_SECRET_ACCESS_KEY'],
region_name = os.environ["AWS_REGION"],
config = Config(signature_version='s3v4'))
データセット等を格納するバケットを作成します。
bucket_name = 'census-income'
bucket_name_s3_prefix = 's3://%s' % bucket_name
try:
bucket = s3_resource.Bucket(bucket_name)
bucket.create()
print("Create S3 bucket:", bucket_name)
except:
print("Exsiting S3 bucket:", bucket_name)
先ほど作成したTFRecord形式のデータファイルをMinIOにアップロードします。
bucket.upload_file(tfrecord_data_path, 'data/span-1/v1/adult.span-1.tfrecords')
- 4. ImportExampleGenでデータファイルを取り込む
ノートブック上で実行するためにInteractiveContextにMinIOの接続設定を追加します。
beam_pipeline_args = ['--s3_access_key_id=%s' % os.environ['AWS_ACCESS_KEY_ID'],
'--s3_secret_access_key=%s' % os.environ['AWS_SECRET_ACCESS_KEY'],
'--s3_endpoint_url=%s' % os.environ["S3_ENDPOINT"],
'--s3_region_name=%s' % os.environ["AWS_REGION"],
'--s3_verify=0',
'--s3_disable_ssl',
'--direct_num_workers=1']
context.beam_pipeline_args=beam_pipeline_args
ImportExampleGenを使ってMinIOに格納されているTFRecord形式のデータファイルを取り込みます。なお、ここで設定している「input_config」と「output_config」については「ExampleGenの入出力設定」で解説します。
example_gen_input = {"splits": [{"name": "single_split",
"pattern": "span-{SPAN}/v{VERSION}/*"}]
}
example_gen_output = {"split_config": {"splits": [{"name": "train", "hash_buckets": 2},
{"name": "eval", "hash_buckets": 1}]
}}
example_gen = tfx.components.ImportExampleGen(input_base = '%s/data/' % bucket_name_s3_prefix,
input_config = example_gen_input,
output_config = example_gen_output)
context.run(example_gen)
実行すると次のような表示になります。
図2-2:ImportExampleGenの実行結果
このようにして、リモートストレージ上にあるTFRecord形式のデータファイルを取り込むことができます。
- ExampleGenの入出力設定
ExampleGenでは、データセットの入力設定(input_config)と出力設定(output_config)を設定できます。
- SPANとVERSIONによる取り込み対象のデータセット設定例(input_config)
機械学習パイプラインのユースケースの一つとして、新しいデータが利用可能になった際の、機械学習モデルの更新があります。これを実現するためには、動的に最新のデータセットを取り込む必要があります。次のようにSPANとVERSIONという設定を行うことで、このユースケースに対応することができます。
example_gen_input = {"splits": [{"name": "single_split",
"pattern": "span-{SPAN}/v{VERSION}/*"}]
}
SPANはデータセットのスナップショットを示しています。例えば日次で取得したデータ、月次で取得したデータなどに対応します。VERSIONはそのSPANに対する変更履歴を示しています。例えばSPANのデータセットを変換して利用する場合に元のデータセットを保持したまま変換済みのデータセットを利用できます。今回の設定では、新たなデータセットをMinIOの「/census-income/data/span-1/v2/adult.span-1.tfrecords」(Versionを1つ上げる)または「/census-income/data/span-2/v1/adult.span-2.tfrecords」(Spanを1つ上げる)に格納すると、次回パイプラインを実行する際に新たなデータセットを取り込みます。
- データセットの分割設定例(output_config)
ExampleGenで取り込んだデータセットをデフォルトでは2:1の比率で学習用と評価用のデータセットにそれぞれ分割し出力しますが、この設定を変更することが可能です。次の例では、データセットを6:2:2の比率で学習用、評価用、テスト用に分割しています。比率の設定は、「hash_buckets」で指定できます。この設定に関する詳細は公式マニュアル(Span, Version, Split)を参照してください。
example_gen_output_three_division = {"split_config": {"splits": [{"name": "train", "hash_buckets": 6},
{"name": "eval", "hash_buckets": 2},
{"name": "test", "hash_buckets": 2}]}}
example_gen_three_division = tfx.components.ImportExampleGen(input_base = '%s/data/' % bucket_name_s3_prefix,
input_config = example_gen_input,
output_config = example_gen_output_three_division)
context.run(example_gen_three_division)
- この記事のキーワード
この記事をシェアしてください
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
