ビッグデータ処理基盤に対応したFDWの紹介とhdfs_fdwの設計・構築の紹介
2018年8月3日 6:00
はじめに
前回は、ビッグデータ処理基盤とRDBの連携の必要性と、FDWの機能紹介としてPostgreSQLのFDWであるpostgres_fdwを例に挙げご紹介しました。今回は、ビッグデータ処理基盤と連携するために開発されているFDWの紹介と、その中の1つをピックアップし使い方やノウハウを説明したいと思います。
ビッグデータ向けFDW概要
まず、他のRDBやフラットファイル等、様々なデータストアにリモートアクセスできるFDWはPostgreSQL wikiにまとめられていますが、この中で、ビッグデータ基盤にアクセスできるFDWをご紹介します。
なお、PostgreSQL wikiには注釈として、これらのFDWはPostgreSQL開発者グループ(PGDG)によって正式サポートされておらず、またベータ版が多いので、注意して使用するよう記載されています。従いまして、企業で使う場合には、連携先のデータソース以外にも、システムが期待する信頼性に合わせたFDWを選択する必要があります。採用するにあたっては、例えば開発者は誰か、リリース状況はどうか(定期的なバグフィックスやPostgreSQLのバージョンアップへの追随が行われているか)、ライセンス形態がビジネス上問題にならないか、何かあったときのサポートをどうするか(開発元のサポート提供や密な連携が取れる相手がいるか)、といったことを考慮するべきです。
一例として、wikiページの情報に上記に挙げた観点を加えたものを表1にまとめてみました。
表1:ビッグデータ向けのFDWツール(2018/06/12時点)
| Data Source | License | Code | Author | Release | Release Date | Requirement |
|---|---|---|---|---|---|---|
| Elasticsearch | PostgreSQL | GitHub | Mikuláš Dítě | no release | - |
|
| Google BigQuery | MIT | GitHub | Gabriel Bordeaux | 1.1.0 | 2018/5/12 |
|
| file_fdw(Hadoop) | undescribed | GitHub | citusdata | 2.0(β版) | 2014/2/4 |
|
| hadoop_fdw(Hadoop) | PostgreSQL | Bitbucket | OpenSCG | 2.5 | 2016/12/30 |
|
| hdfs_fdw(Hadoop) | Apache | GitHub | EnterpriseDB | 2.0.3 | 2017/12/18 |
|
| Hive | undescribed | GitHub | Youngwoo Kim | 0.0.2 | 2012/4/30 |
|
| Hive/ORC File | undescribed | GitHub | Rami Gökhan Kıcı | no release | - |
|
| Impala | BSD | GitHub | LA-PUG | no release | - |
|
このように整理することによって、利用できるFDWがあるのか、もしくは、従来通りETLツールなどを使って定期的にデータを移行したり、システムに合わせたFDWを新規開発したりするのがよいか、といった判断がしやすくなると思われます。
本記事では、連携するビッグデータ処理基盤はHadoopを想定しており、上記でまとめた結果としてhdfs_fdwが候補として挙がりました。こちらを例に挙げて、ビッグデータ処理基盤との連携を説明したいと思います。
なお、hdfs_fdwのサポートについての補足ですが、EnterpriseDB社がサポートしているhdfs_fdwはバイナリ版のみで、今回利用するGitHubのhdfs_fdwはEnterpriseDB社のサポート対象外となります。そのため、GitHubのhdfs_fdwのサポートが必要な場合には、弊社などEnterpriseDB社のパートナー各社に問い合わせてみるのがよいでしょう。
hdfs_fdw概要
hdfs_fdwは、前節で整理したようにHadoop(HDFS)用のFDWですが、直接HDFSデータにアクセスするのではなく、HiveQL、もしくは、SparkSQLを経由してリモートサイトのHDFSのデータにアクセスします。
FDWという仕組みは、SQLによるアクセスを規定しているSQL/MEDの実装系です。そのためHadoopと連携する場合でも、データをテーブル形式にマッピングし、HiveQLやSparkSQLといったSQLライクの言語を使用してアクセスする、という連携方式になります。今回は、Hiveを使って説明したいと思います。
次に、hdfs_fdwを使ったSQLの処理の流れを図1に示します。
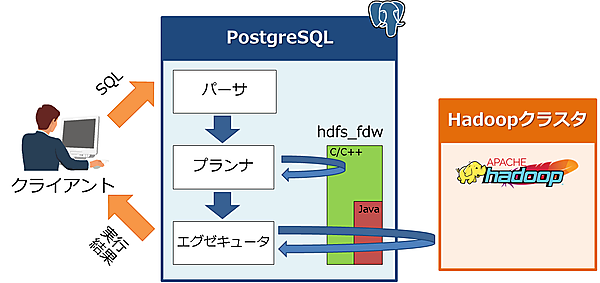
基本的には、前回説明したpostgres_fdwの処理の流れと同じです。今回はHadoopと連携するため、エグゼキュータが処理を実行する場合、hdfs_fdwはJavaを使ってHadoopにアクセスしデータを取得するというのがポイントになります。
hdfs_fdwの設計・構築と使い方とそのノウハウ
hdfs_fdwの基本的な構築手順はソースのREADMEやINSTALLに記載されていますがわかりづらいため、ここでは、連携するための設計・構築を手順を追って説明するとともに、実際に構築して得られたノウハウも併せて説明していきたいと思います。
初めに、今回の連携シナリオとシステム構成について説明します。
連携シナリオ
前回、各システムがサイロ化されているという点を説明しましたが、今回はIoTシステム(具体的にはスマートメータのデータを使用します。後述参照)と業務システムが分断されているところにhdfs_fdwを使って連携し、業務システムで活用できるようにします(図2)。
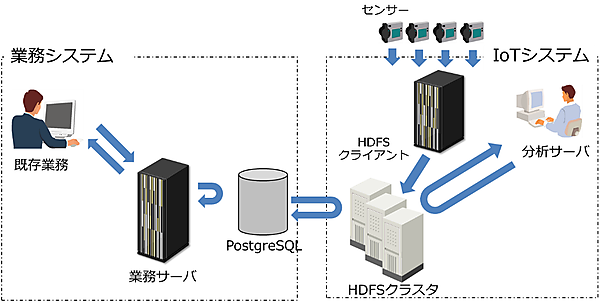
システム構成
hdfs_fdwを使ったシステム構成を図3に示します。
hdfs_fdwはHadoopのクエリエンジンであるHiveを使用して、Hadoopの分散ファイルシステムであるHDFS上のデータ(Hiveテーブル)にアクセスします。
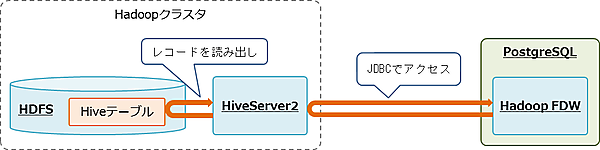
それでは、ここから連携させるための設計・構築について説明します。なお、本連載ではfirewallとSELinuxはdisableに設定しています。
1.Hadoopクラスタ環境側の設計・構築
(1)Hadoopクラスタの構築
今回は、Hadoopクラスタの構築にCloudera社のHadoopディストリビューションであるCDH(Cloudera’s Distribution including Apache Hadoop)と、その運用管理ソフトウェアであるCloudera Managerを使用します。Cloudera Managerを使用することで、手間のかかるシステム構築やパラメータチューニングをほぼ自動的に行えるほか、クラスタの運用管理や性能監視をWebブラウザ上から簡単に行うことができます。Cloudera Managerを用いたHadoopの環境構築手順の詳細は公式ドキュメントを参照してください。
hdfs_fdwは認証方法として、NOSASLまたはLDAPのみをサポートしており(参考情報)、ここではNOSASLを用いることにします。Hadoopの環境構築が完了したら、Cloudera Managerから表2の設定を行ってください。
表2:Hiveの設定
| 設定ファイル | パラメータ | 値 |
|---|---|---|
| hive-site.xml | hive.server2.authentication | NOSASL |
Hadoopに格納するデータとして、今回はスマートメータ(次世代電力計)が収集する電力消費量のデータを使用します。スマートメータとは、電力事業者によって住宅や店舗などに設置され、電力消費量などのデータを自動収集する機器です。収集したデータは料金計算や電力需要の予測などの分析に利用されます。今回はこのデータを、Hadoopクラスタ上に作成したHiveテーブルに格納します。
(2)Hiveテーブルの設計・構築
Hadoopを用いたビッグデータ処理では、実施したい処理(クエリ)の内容に合わせて、複数あるテーブル設計テクニックから必要なものを選択します。そのため、設計の前に処理(クエリ)内容を明確にしておく必要があります。この点が、データ中心の設計であるRDBの設計方式と大きく異なります。今回作成するHiveテーブル(meter_dataテーブル)のスキーマを表3に示します。
表3:meter_dataテーブルのスキーマ
| # | カラム名 | 型 | サイズ | 説明 |
|---|---|---|---|---|
| 1. | meter_id | Int | 4bytes | スマートメータを示すID |
| 2. | date_time | Timestamp | 8bytes | 収集時刻 |
| 3. | usage | Bigint | 8bytes | 電力消費量 |
| 4. | year | Smallint | 2bytes | 収集時刻の年 |
| 5. | month | Smallint | 2bytes | 収集時刻の月 |
| 6. | day | Smallint | 2bytes | 収集時刻の日 |
今回は、指定したスマートメータの指定した期間の時系列データを参照する、というクエリを想定します。このクエリに合わせて、以下のようなテクニックを用いてmeter_dataテーブルを設計しました。
- 対象のレコードをまとめて効率よく取得できるように、meter_id -> date_timeの順でソートしてから格納しました。
- 検索範囲を絞りやすいように、Hiveテーブルのパーティションをyear, month, day列で定義しました。これらの列の値でディレクトリ階層が切られるため、特定期間のレコードを検索する際に検索範囲を絞りやすくなります。
- 読み出しを高速化するために、データの格納には列指向ファイルフォーマットであるORCを使用し、SNAPPYアルゴリズムで圧縮を行いました。ORCは列単位でデータを保持する列指向ファイルフォーマットであり、効率的なエンコーディングと圧縮が可能です。これによりデータの読み出し時に必要なI/Oの量を大幅に削減できます。また、ORCファイルはインデクスを持つため、レコードの検索を高速化できます。
以上の設計を元に、表3のmeter_dataテーブルを作成するHiveクエリを以下に示します。このクエリをHiveのコマンドラインツールから実行することでテーブルを作成できます。
CREATE TABLE meter_data (
meter_id INT,
date_time TIMESTAMP,
usage BIGINT)
PARTITIONED BY (
year SMALLINT,
month SMALLINT,
day SMALLINT)
STORED AS ORC
TBLPROPERTIES(
"orc.compress"="SNAPPY");次に、作成したmeter_dataテーブルに対してデータを格納します。まず、格納するデータを以下のようなCSVファイルで用意して、HDFS(の/dataディレクトリ)に格納しておきます。
0,2018-01-01 00:00:00.0,15240,2018,1,1
0,2018-01-01 00:01:00.0,21180,2018,1,1
0,2018-01-01 00:02:00.0,16920,2018,1,1
0,2018-01-01 00:03:00.0,13320,2018,1,1
0,2018-01-01 00:04:00.0,24000,2018,1,1
0,2018-01-01 00:05:00.0,18600,2018,1,1
0,2018-01-01 00:06:00.0,17640,2018,1,1
0,2018-01-01 00:07:00.0,18060,2018,1,1
0,2018-01-01 00:08:00.0,22800,2018,1,1
0,2018-01-01 00:09:00.0,18120,2018,1,1
0,2018-01-01 00:10:00.0,18120,2018,1,1
……(省略)……そして、HiveからCSVファイルにアクセスするために、Hiveの外部テーブル定義します。以下のクエリを実行することで、HDFS上の/dataディレクトリ以下にあるCSVファイルに対して、Hiveの外部テーブル(meter_data_csv)を定義します。
CREATE EXTERNAL TABLE meter_data_csv (
meter_id INT,
date_time TIMESTAMP,
usage BIGINT,
year SMALLINT,
month SMALLINT,
day SMALLINT)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
LOCATION '/data';最後に以下のクエリを実行することで、meter_data_csvテーブルのレコードを、meter_dataテーブルにコピーします。
INSERT OVERWRITE TABLE meter_data PARTITION(year, month, day)
SELECT * FROM meter_data_csv;以上で、Hadoopの環境構築とデータの準備は完了です。
2.PostgreSQL環境側の設計構築
次に、hdfs_fdwの構築手順を説明します。
PostgreSQLは構築済みであることを前提に説明します。今回の環境構築は、PostgreSQL 10を使用し、ソースからインストールを行いました。インストール先はデフォルト値を使用しています。
なお、前提条件として、以下のソフトウェアをインストールしておく必要があります。
- java-1.8.0-openjdk
- java-1.8.0-openjdk-devel
- gcc-c++
(1)環境変数の設定
PostgreSQLの環境変数と合わせて、以下の設定を行います。
export PATH=/usr/local/pgsql/bin:$PATH
export LD_LIBRARY_PATH=/usr/local/pgsql/lib:$LD_LIBRARY_PATH
export JDK_INCLUDE=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.171-8.b10.el7_5.x86_64/include
export INSTALL_DIR=/usr/local/pgsql/lib(2)hdfs_fdwをダウンロードします。
ダウンロードは、GitHubのreleaseタブから実施します。
(3)hdfs_fdwを展開します。

(4)hdfs_fdwのC/C++パートインストール
libhiveディレクトリ下に移動し、ライブラリのインストールを行います。
(5)hdfs_fdwのJavaパートインストール
libhive/jdbcディレクトリ下に移動し、jarファイルを作成します。

(6)hdfs_fdwのインストール
展開直下のディレクトリに移動し、hdfs_fdwのインストールを行います。

(7)postgresql.confの設定
postgresql.confに、hdfs_fdw.jvmpathとhdfs_fdw.classpathの設定を追加します。

(8)設定が完了したら、PostgreSQLを起動します。
(9)psqlでログインしてCREATE EXTENSIONを実行します。

(10)CREATE SERVERを実行します。
(11)CREATE USER MAPPINGを実行します。
(12)外部テーブルを作成します。
表3のHiveテーブルに対応する外部テーブルを作成します。
ここで、HiveテーブルとPostgreSQLテーブルのマッピングが必要になるため、前述の通り、Hiveテーブルの設計はポイントの一つになります。
また、データ型のマッピングについては、EDB Data Adapter for Hadoop 2.0のドキュメントが参考になります。

これで、外部テーブル(Hiveテーブル)を検索できれば、構築は完了です。

ここで、定義内容を確認してみましょう。これらを覚えておくと便利です。
- FDWの確認(\dew)
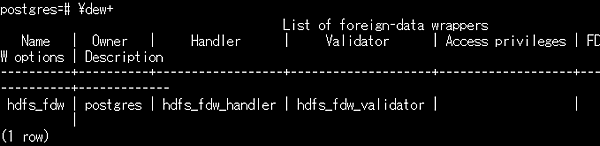
- 外部サーバの確認(\des)
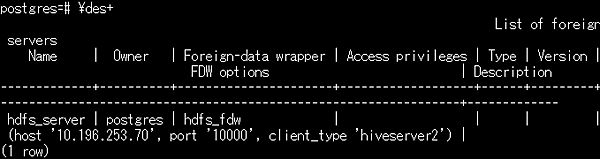
- ユーザマッピングの確認(\deu)

- 外部テーブルの確認(\det)

最後に前回同様、explain analyzeを使って、実行計画を確認しました。その結果、外部表へ検索しに行っていることが確認できます。
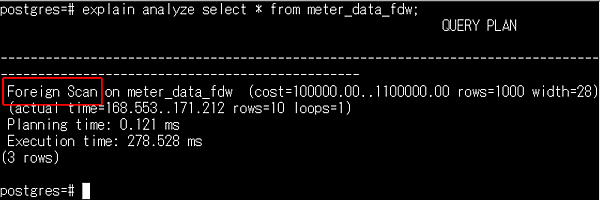
以上で、ビッグデータ処理基盤(Hadoop)にあるデータにアクセスできるようになりました。次回は、hdfs_fdwの中身をもう少し深掘りし、評価していきたいと思います。
- この記事のキーワード
この記事をシェアしてください
関連記事
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
