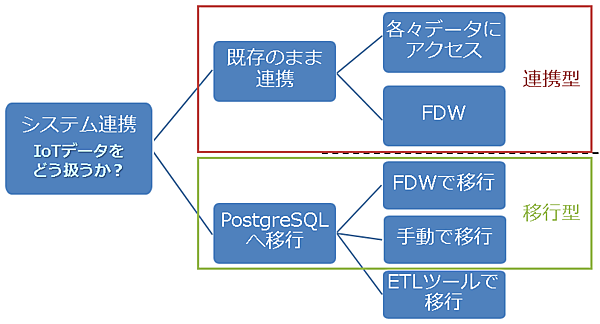
本連載の第1回ではデータ連携の必要性を紹介し、その中で連携の手段について紹介しました。手段を切り分けしたものが図1(再掲)になりますが、既存のシステムのまま連携するパターン(連携型)、PostgreSQLにデータを移行するパターン(移行型)のそれぞれのパターンについて、実機評価を行います。その結果から、業務的に利用できる場面や利用するにあたっての注意点を洗い出したいと思います。
評価環境
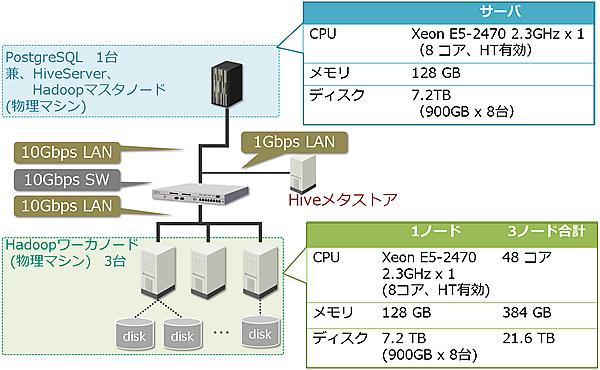
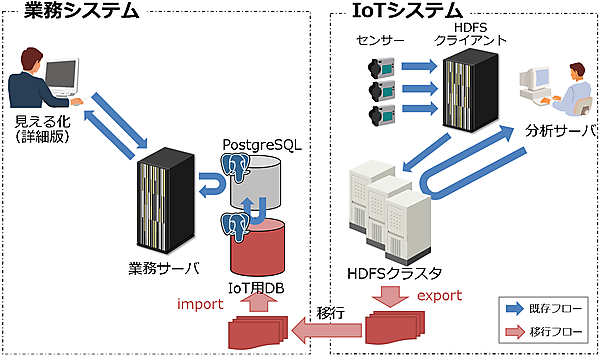
評価内容を説明する前に、評価環境を説明します。今回の評価で使用した物理環境を図2に示します。PostgreSQLサーバ、HiveServer、Hadoopのマスタノードを1台で構成し、 Hadoopのワーカノードは3台構成としました。
次に論理環境を図3に示します。
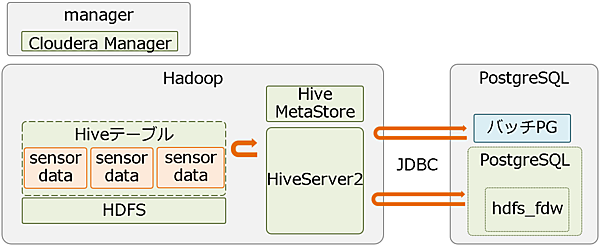
バッチPGは、業務アプリ側(PostgreSQL)で「見える化」するためのETL(データ取得、変換/加工、ロード)を行うプログラムになります。その他、評価で使用したソフトウェアとそのバージョンを表10に示します。
表10:ソフトウェア構成
| ソフトウェア | バージョン |
|---|---|
| OS | RedHat Enterprise Linux 6.7 (x86_64) |
| PostgreSQL | PostgreSQL 10.0 hdfs_fdw 2.0.2 |
| Hadoop | CDH 5.11.1 |
PostgreSQLの設定を表11に示します。
表11:postgresql.conf設定
| パラメータ | 設定値 |
|---|---|
| shared_buffers | 8GB |
| maintenance_work_mem | 2GB |
| wal_level | replica |
| checkpoint_timeout | 30min |
| checkpoint_completion_target | 0.9 |
| archive_mode | on |
| max_wal_senders | 2 |
| hot_standby | on |
| effective_cache_size | 16GB |
| logging_collector | on |
| Autovacuum | on |
| hdfs_fdw.jvmpath | ‘/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.171-8.b10.el7_5.x86_64/jre/lib/amd64/server’ |
| hdfs_fdw.classpath | ‘/usr/local/pgsql/lib/HiveJdbcClient-1.0.jar:/opt/cloudera/parcels/CDH-5.14.2-1.cdh5.14.2.p0.3/jars/hadoop-common-2.6.0-cdh5.14.2.jar:/opt/cloudera/parcels/CDH-5.14.2-1.cdh5.14.2.p0.3/jars/hive-jdbc-1.1.0-cdh5.14.2-standalone.jar’ |
ここまでが、評価環境の概要になります。
連携型の評価概要
それでは、まず連携型の評価を行います。既存システムを活かしたまま連携するに当たっては、次のパターンで比較評価します。
- FDWを使って見える化用データを作成するパターン(以下、「FDW連携」と表記)
- アプリで各々のデータにアクセスし見える化用データを作成するパターン(以下、「アプリ連携」と表記)
まず、FDW連携のイメージを図4、テーブル関連図を図5に示します。
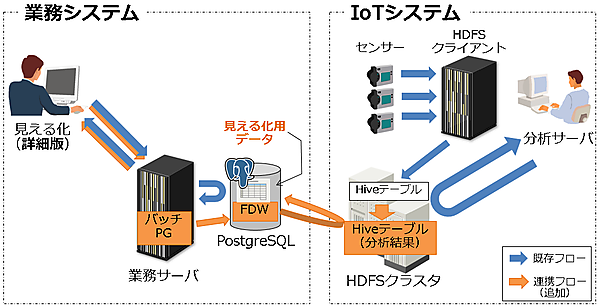
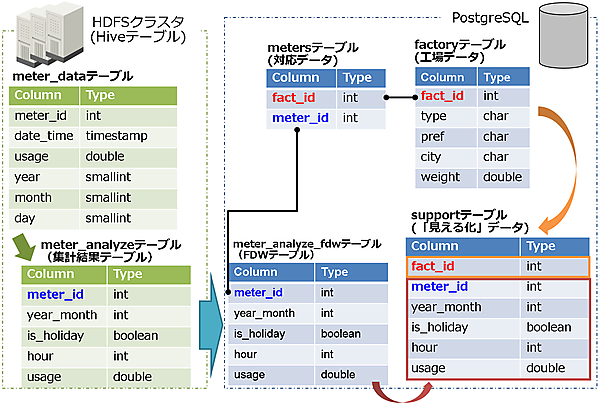
予め、集計結果テーブル(meter_analyzeテーブル)用の外部テーブル(meter_analyze_fdw)を作成し、外部データとしてアクセスできるようにします。このFDWテーブルと対応データ(metersテーブル)を組み合わせて、見える化データ(supportテーブル)を生成します。
この構築した環境で、外部テーブルにアクセスした際のhdfs_fdwの実行計画を確認してみたいと思います。
hdfsfdw=# explain analyze select count(*) from meter_analyze_fdw where year_month = '201701';
QUERY PLAN
------------------------------------------------------------------------------------------
Aggregate (cost=1100002.50..1100002.51 rows=1 width=8) (actual time=39792.123..39792.124
rows=1 loops=1)
-> Foreign Scan on meter_analyze_fdw (cost=100000.00..1100000.00 rows=1000 width=0) (actual time=306.846..38433.607 rows=4800000 loops=1)
Planning time: 112.417 ms
Execution time: 40187.927 ms
(4 rows)図6:実行計画
このように、Foreign Scanとなっていて、外部データを参照していることが確認できます。次に、Hive側のログを確認してみたいと思います。
Compiling command(queryId=hive_id): SELECT * FROM default.meter_analyze WHERE ((year_month = '201701'))
Executing command(queryId=hive_id): SELECT * FROM default.meter_analyze WHERE ((year_month = '201701'))
ORC pushdown predicate: leaf-0 = (EQUALS year_month 201701)
Reading ORC rows from hdfs://pgmaster:8020/user/hive/warehouse/meter_analyze/year_month=201701/000000_0 with {include: [true, true, true, true, true], offset: 0, length: 9223372036854775807, sarg: leaf-0 = (EQUALS year_month 201701)
expr = leaf-0, columns: ['null', 'meter_id', 'is_holiday', 'hour', 'usage']}図7:Hiveログ(対象箇所のみ抜粋)
Hive側のデータは月単位で作成しており、対象ファイルのみアクセス(pushdown)することでI/O削減による高速化ができていることがわかります。
なお、既存システムを活かしたまま連携する、と記載しましたが、今回生データが入っているHiveテーブル(meter_dataテーブル)に直接アクセスして取得するのではなく、分析結果用Hiveテーブル(meter_analyzeテーブル)を予め作成して取得しないといけなくなりました。この点は重要ですので、ここで補足いたします。
わざわざ分析結果用のデータを予め作成する必要があるのは、生データをPostgreSQLでETL処理を行おうとすると、データの取得サイズが巨大になり、メモリを消費し尽くしてしまい、OOM Killerが発生してしまったためです。その対策として、Hadoop側で出来る範囲でETL処理を行った結果(分析結果)データを持っておくという対応が必要でした。この点は、利用にあたって、注意が必要な点かと思います。なお前章で、「リモート側で結合やソート、集約関数等のpushdown対応」をやってほしい理由は、このためになります。
次に、アプリ連携のイメージを図8、テーブル関連図を図9に示します。
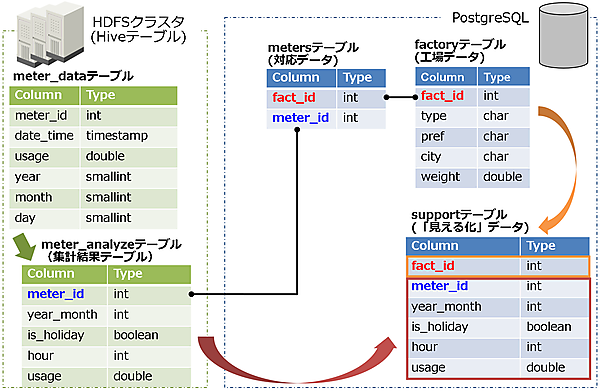
アプリ連携では、集計結果テーブル(meter_analyzeテーブル)と対応データ(metersテーブル)をアクセスし、アプリ側で組み合わせて、見える化データ(supportテーブル)を生成します。
以上が、評価の概要になります。次に、評価項目を説明します。
評価項目
評価項目は、次の3点について評価していきます。
- 評価1:設計・開発、運用・保守、業務変化への対応について、連携方式ごとに机上評価
- 評価2:開発コストの比較(見える化テーブルの生成)
- 評価3:性能面の比較
それでは、さっそく評価結果を説明します。
評価結果
評価結果1
設計・開発、運用・保守、業務変化への対応について、机上評価を行った結果を表12に示します。
表12:システム設計・運用各フェーズでの各連携方式の比較評価(机上評価)
| フェーズ | FDW連携 | アプリ連携 |
|---|---|---|
| 設計・開発 |
|
|
| 運用・保守 |
|
|
| 業務変化への対応 |
|
|
このように、どのフェーズにおいても、各連携方式でメリット・デメリットが存在します。したがって、デメリットが許容できる連携方式を選択する必要があります。
評価結果2
次に、開発コストの比較をします。見える化テーブルを生成するに当たっての開発量を比較してみます。
FDW連携
FDW連携は非常に単純です(図10)。PostgreSQLにアクセスすることで、裏でHadoop側のデータを取得し、業務データとマージした結果を格納できます。
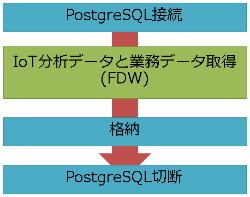
この処理のソースを図11に示します。下記以外にMeterObjectのデータクラスを作成していますが、そちらのソースは割愛します。
import java.sql.*;
import java.util.ArrayList;
class MierukaUseFdw {
public static void main (int year_month) {
// classロード
try {
Class.forName("org.postgresql.Driver");
} catch (ClassNotFoundException e) {
System.err.println("Class Not Found.");
e.printStackTrace();
System.exit(1);
}
// データベース接続
Connection con = null;
try {
con = DriverManager.getConnection("jdbc:postgresql://192.168.1.1:5432/postgres", "postgres", "postgres");
} catch (SQLException e) {
System.err.println("Connection Error.");
e.printStackTrace();
System.exit(1);
}
// SQL実行
PreparedStatement pstmt = null;
ResultSet res = null;
ArrayList<MeterObject> meterMap = new ArrayList<MeterObject>();
MeterObject currentMeter = null;
try {
// データ取得
pstmt = con.prepareStatement("select b.fact_id, a.meter_id, a.month, a.is_holiday, a.hour, a.usage from meter_analyze_fdw a, meters b where ((a.meter_id = b.id) and (a.year_month = ?))");
pstmt.setInt(1, year_month);
res = pstmt.executeQuery();
while (res.next()) {
currentMeter = new MeterObject(Integer.valueOf(res.getString(1)),
Integer.valueOf(res.getString(2)),
Integer.valueOf(res.getString(3)),
Boolean.valueOf(res.getBoolean(4)),
Integer.valueOf(res.getString(5)),
Double.valueOf(res.getString(6)));
meterMap.add(currentMeter);
}
res.close();
// データ格納
con.setAutoCommit(false);
pstmt = con.prepareStatement("insert into support values (?, ?, ?, ?, ?, ?);");
for(MeterObject meter:meterMap){
pstmt.setInt(1, meter.getFact_id());
pstmt.setInt(2, meter.getMeter_id());
pstmt.setInt(3, meter.getYear_month());
pstmt.setBoolean(4, meter.getIs_holiday());
pstmt.setInt(5, meter.getHour());
pstmt.setDouble(6, meter.getUsage());
pstmt.addBatch();
}
pstmt.executeBatch();
con.commit();
} catch (SQLException e) {
System.err.println("Execute Error.");
e.printStackTrace();
System.exit(1);
} finally {
if (pstmt != null) {
try {
pstmt.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if (con != null) {
try {
con.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
}
}図11:FDW連携(MierukaUseFdw.java)ソース
アプリ連携
アプリ連携の場合は、アプリ側でIoTデータと業務データにそれぞれ接続、取得し、さらにマージしてから格納する必要があります(図12)。
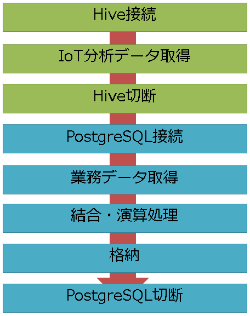
この処理のソースを図13に示します。先ほどと同様に、MeterObjectのデータクラスの説明は割愛します。
import java.sql.*;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.Map;
class MierukaUseHive {
public static void main (int year_month) {
/* hive */
// classロード
try {
Class.forName("org.apache.hive.jdbc.HiveDriver");
} catch (ClassNotFoundException e) {
System.err.println("Class Not Found.");
e.printStackTrace();
System.exit(1);
}
// Hive接続
Connection con = null;
try {
con = DriverManager.getConnection("jdbc:hive2://192.168.1.101:10000/default", "", "");
} catch (SQLException e) {
System.err.println("Connection Error.");
e.printStackTrace();
System.exit(1);
}
// SQL実行
PreparedStatement pstmt = null;
ResultSet res = null;
HashMap<Integer,Integer> meter2factMap = new HashMap<Integer,Integer>();
ArrayList<MeterObject> meterMap = new ArrayList<MeterObject>();
MeterObject currentMeter = null;
try {
// データ取得(IoT分析データ)
pstmt = con.prepareStatement("select * from meter_analyze where year_month = ?");
pstmt.setInt(1, year_month);
res = pstmt.executeQuery();
while (res.next()) {
currentMeter = new MeterObject(Integer.valueOf(res.getString(1)),
Integer.valueOf(res.getString(2)),
Boolean.valueOf(res.getBoolean(3)),
Integer.valueOf(res.getString(4)),
Double.valueOf(res.getString(5)));
meterMap.add(currentMeter);
}
res.close();
} catch (SQLException e) {
System.err.println("Execute Error.");
e.printStackTrace();
System.exit(1);
} finally {
if (pstmt != null) {
try {
pstmt.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if (con != null) {
try {
con.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
/* postgres */
// classロード
try {
Class.forName("org.postgresql.Driver");
} catch (ClassNotFoundException e) {
System.err.println("Class Not Found.");
e.printStackTrace();
System.exit(1);
}
// データベース接続
try {
con = DriverManager.getConnection("jdbc:postgresql://192.168.1.1:5432/postgres", "postgres", "postgres");
} catch (SQLException e) {
System.err.println("Connection Error.");
e.printStackTrace();
System.exit(1);
}
// SQL実行
try {
// データ取得(業務データ)
pstmt = con.prepareStatement("select * from meters");
res = pstmt.executeQuery();
while (res.next()) {
meter2factMap.put(Integer.valueOf(res.getString(1)), Integer.valueOf(res.getString(2)));
}
res.close();
// データ処理&格納
con.setAutoCommit(false);
pstmt = con.prepareStatement("insert into support values (?, ?, ?, ?, ?, ?);");
for(MeterObject meter:meterMap){
pstmt.setInt(1, meter2factMap.get(meter.getMeter_id()));
pstmt.setInt(2, meter.getMeter_id());
pstmt.setInt(3, meter.getYear_month());
pstmt.setBoolean(4, meter.getIs_holiday());
pstmt.setInt(5, meter.getHour());
pstmt.setDouble(6, meter.getUsage());
pstmt.addBatch();
}
pstmt.executeBatch();
con.commit();
} catch (SQLException e) {
System.err.println("Execute Error.");
e.printStackTrace();
System.exit(1);
} finally {
if (pstmt != null) {
try {
pstmt.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if (con != null) {
try {
con.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
}
}図13:アプリ連携(MierukaUseHive.java)のソース
今回の例では、「結合・演算処理」部分が単純なジョインのみだったので開発工数は少ないですが、それでもそれぞれ接続、取得処理を行わないといけないため開発工数はほぼ倍になりました。実際には、もっと複雑なSQLを演算処理する必要になると思いますし、開発工数が膨れ上がるにつれ、その分テストも行う必要が出てくるので、その点を考えただけでもSQLで処理ができるFDW連携の優位性が感じられるのではないかと思います。
評価結果3
3つ目に、性能面の比較をしたいと思います。性能面の比較については、見える化テーブルの作成時間と、作成処理にかかるシステム影響を見てみたいと思います。
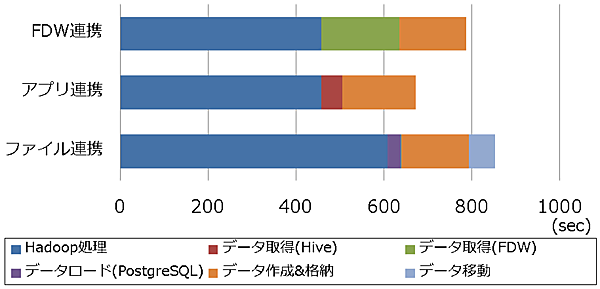
まず、見える化テーブルの作成時間の比較結果を図14に示します。HiveからデータをエクスポートしてPostgreSQLにデータをロードするといった従来の方法も併せて比較しました(「ファイル連携」と表記)。
なお、Hadoop、PostgreSQLのキャッシュによる影響が出ないように初期化を行ってから、測定しています。
次にシステムへの影響を見てみます。CPUとメモリの負荷影響を実機検証しましたが、メモリの負荷については連携方式による差は見られませんでした。そのため、CPUの負荷について、それぞれの連携方法についての比較結果を図15に示します。
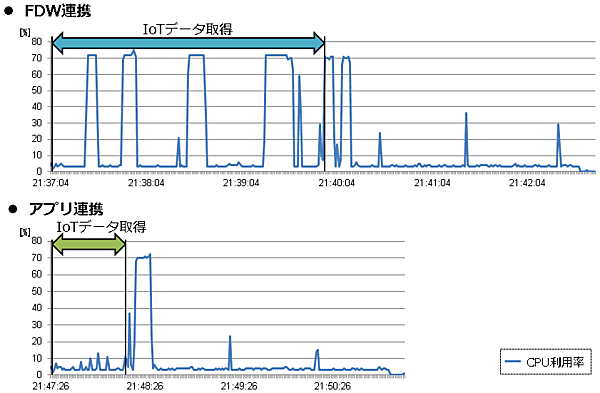
図15で示したように、アプリ連携に比べ、FDW連携はCPU利用率が高騰する頻度が高く、特に、IoTデータ取得時に高くなる傾向になりました。業務影響がでるかといった事前の負荷検証は実施すると思いますので、もし性能が課題になりそうであれば、スケールアップ等を検討してください。
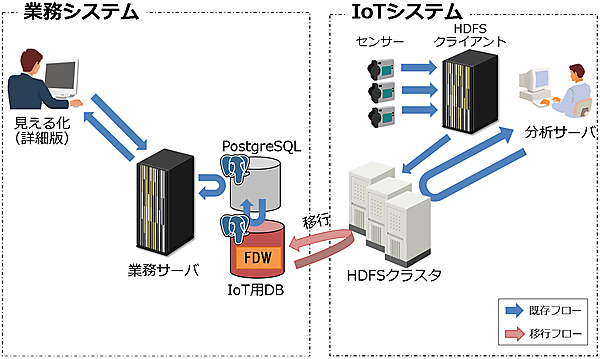
移行型の評価概要
次に、移行型の評価を行います。シナリオは、IoTシステムを業務システム側に統合する当たって、Hadoopに格納されているIoTデータをPostgreSQLに移行する必要があります。そのデータ移行について、次のパターンで比較評価します。
- FDWを使って移行するパターン(以下、「FDW移行」と表記)
- 手動で移行するパターン(以下、「手動移行」と表記)
次に、FDW移行のイメージを図16、テーブル関連図を図17に示します。
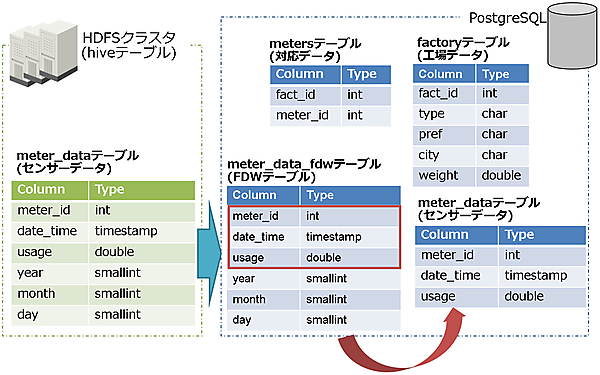
次に、手動のイメージを図18、テーブル関連図を図19に示します。
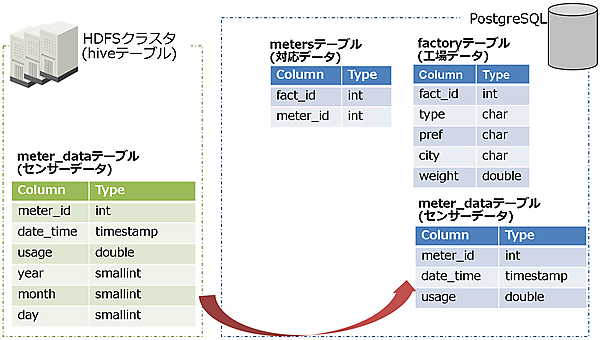
以上が、評価の概要になります。次に、評価項目を説明します。
評価項目
評価項目は、FDW移行(2種類)と手動移行の計3種類の方法で、データ移行時間を評価していきたいと思います。
- FDW移行
- SQL(INSERT-SELECT文)で直接移行する
- SQL(COPY文)で一度ファイルに出力し、そのファイルを使って移行する
- 手動移行
評価結果
データ移行時間の比較結果を図20に示します。なお、FDW移行については、連携型の時と同様に、全データを一度に移行しようとすると、データの取得サイズが巨大になるため、OOM Killerが発生してしまいます。そのため、移行できるサイズに分割して、移行した結果(総計)となっています。
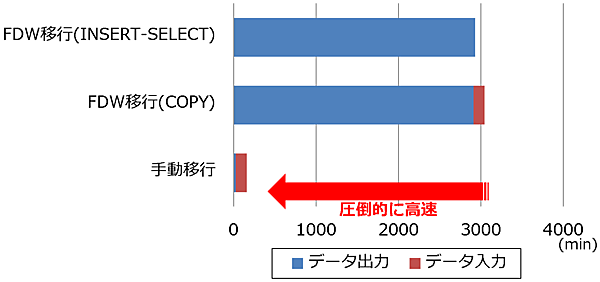
今回の結果では、FDW移行に比べ、手動移行の方が圧倒的に高速に移行できました。業務的に移行を考えた場合、短時間での移行が望まれるため、FDWを利用するより手動で移行することが望まれると思います。このように、何でもFDWを利用する、というわけではなく、きちんと実機調査して利用するようにしてください。
おわりに
以上が、hdfs_fdwを実機検証した結果となります。
近年は、データの量や種類が膨大になる中で、様々なデータを組み合わせて付加価値のある情報を得ようとします。そのため、システム連携は避けられないものであり、PostgreSQLのFDWは非常に便利なツールで、今回の検証結果から、hdfs_fdwは、HadoopとPostgreSQLを連携した開発や運用を容易にできるという点で有効性が確認できたと思います。
ただ、どのツールでもそうですが、設計・開発や運用面、性能面等へのメリット・デメリットがあり、利用するに当たっては業務システムに合うか検証してから適用する必要があります(特に、今回の検証結果では性能面が懸念になりそうであり、実機検証は必須です)。
なお、hdfs_fdwについては、まだ開発途上であり機能拡張を通じて使いやすくなると思いますので、引き続きウォッチしていこうと思います。
以上で、今回の連載を終了します。本連載がPostgreSQLを活用する上でのFDWの有用性や設計・開発の参考になれば幸いです。
- この記事のキーワード
この記事をシェアしてください
関連記事
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
