環境情報の扱い
環境情報の扱い
OpenShiftで設定ファイルやパラメーターといった環境依存情報をPodに追加する基本的な方法には、以下に示す3通りがあります。
- 環境変数
- ConfigMap
- Secret
環境変数は、コンテナだけでなくOSからも利用される仕組みです。それに対してConfigMapとSecretは、変数、設定ファイルをOpenShiftのオブジェクトとして利用します。作成したオブジェクトは、環境変数として利用することも、volumeとしてマウントして利用することも可能です。
上記の3つの中では、環境変数を使うと最も簡単に値の変更・注入ができますが、利用可能なのは単純な変数のみとなります。ファイルそのものの挿入などには、ConfigMapが必要になるでしょう。また、ConfigMapはオブジェクトですので、複数のPodから共通に利用することも可能です。そして、パスワードなどの機密情報を挿入する場合には、Secretや別の方法を検討した方が良いでしょう。それぞれのユースケースや要件で利用を検討してください。
環境変数の利用
まずは、環境変数の挿入方法から見ていきましょう。上で実験したgo-httpdのLiveness Probeですが、ログのタイムゾーンがUTCになっていたことは、気にならなかったでしょうか?
リスト7:ログのタイムゾーンがUTCになっている……
2019-01-06 07:47:45.798994545 +0000 UTC m=+4.165327161: request from: 10.128.0.1:54808
コンテナのタイムゾーンは、ビルドしたイメージで設定されているタイムゾーンが利用されるため、ホストOSのタイムゾーンとは異なるタイムゾーンになります。コンテナのタイムゾーンは、環境変数で設定するだけで簡単に変更可能ですので、試してみましょう。
oc set envコマンドでタイムゾーンをAsia/Tokyoに指定します。
タイムゾーンの設定
$ oc set env dc/go-httpd TZ=Asia/Tokyo
コンテナが再起動され、ログを確認してみると、タイムゾーンがJSTに変更され、現在の日時に変更されました。
リスト8:JSTで記録されるようになった
2019-01-21 18:33:31.573899401 +0900 JST m=+5.528047998: request from: 10.128.0.1:33154
このように環境変数の設定はとてもシンプルですが、少し物足りない気もしますね。そこで、ちょっと変わった設定方法も紹介します。環境変数で、例えば自分のプロジェクトを挿入したい場合には、どうすれば良いでしょうか。これは、valueFromという指定で取ってくることができます。先ほど挿入した、Asia/Tokyoの下に、次の設定を加えてみてください。
リスト9:valueFromの使用例
$ oc edit dc go-httpd
...略...
- name: TZ
value: Asia/Tokyo
- name: MY_NAMESPACE
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: metadata.namespace
Podの再起動後、コンテナにログインして環境変数を確認してみます。
プロジェクト名が環境変数に挿入されている
# oc rsh go-httpd-12-th9rt env |grep MY_NAMESPACE MY_NAMESPACE=demo
自分のプロジェクト名が環境変数に挿入されました。
ConfigMapの作成と利用
次に、ConfigMapを使ってみます。ConfigMapは、oc create configmapで生成可能ですが、いくつかコマンドのオプションがあります。まず、環境変数と同様にKey/Valueで作成する場合には、--from-literalを指定します。
Key Valueを指定したConfigMapの作成コマンド
$ oc create configmap --from-literal=testkey=foo key-val-configmap
また、ファイルそのものをオブジェクトとして作成する--from-fileを指定する方法もあります。
ファイルを指定したConfigMapの作成コマンド
$ echo "configmap test" > ./config-file $ oc create configmap --from-file=./config-file config-file
ConfigMapで設定した情報の使い方ですが、環境変数として利用する方法とvolumeをマウントして利用する方法があります。まずは、環境変数として利用する方法です。
ConfigMapの情報を環境変数として利用する
$ oc set env --from=configmap/key-val-configmap config-file
volumeとして利用する場合は、PVCをテストしたコマンドを-t configmapに変更して挿入します。
ConfigMapの情報をvolumeとして利用する
$ oc set volumes dc/go-httpd --add --name=configmap-test -t configmap --configmap-name=config-file --mount-path=/config
Podにログインして確認すると、環境変数としてもファイルとしてもどちらも挿入されていることが分かります。
ConfigMapの情報を2通りの方法で参照する
# oc rsh go-httpd-21-dtnlc env |grep TESTKEY TESTKEY=foo $ oc rsh go-httpd-21-dtnlc cat /config/config-file configmap test
リソース管理
今回、最後の設定ポイントはリソース管理です。アプリケーション開発者が設定するリソースの制限には、LimitsとRequestsがあります。それぞれどういう意味か、まずは理解しましょう。
リスト10:LimitsとRequestsの定義例
resources:
limits:
cpu: 200m
memory: 512Mi
requests:
cpu: 100m
memory: 512Mi
まずLimitsですが、この値は実際にランタイムで設定される制限です。Limitsが設定されたコンテナやPodは、設定されたCPUやメモリの上限を超えないように制限されます。一方Requestsは、オブジェクト作成時に要求する値です。OpenShiftは、Requestsの値をもとにPodをスケジューリングし、Limitsの値でランタイムのリソース制限をします。LimitsとRequestsは、どちらか一方だけ設定すれば良いということものではありません。Limitsを指定しておかなければ、アプリケーションが暴走した際にCPU、メモリの制限が効かず、OS側のリソースを使い尽くしたり、OutOfMemoryエラーが発生したります。またRequestsを指定しておかないと、大量にリソースを消費するPodが1つのノードに偏ってしまう可能性があります。
なお、NodeのCapacityを超えた場合、PodのQuality of Service(QoS)クラスに基づいてPodがkillされていきます。QoSには、BestEffort、Burstable、Guaranteedといった種類があり、Podに設定されたRequests値とLimitsによって自動的に付与されます。LimitsもRequestsも設定がないPodは、最も優先度の低いBestEffortと見なされ、真っ先にkillされてしまいます。
LimitsとRequestsの値は、アプリケーション開発者側で設定可能ではあるのですが、実際の運用ではクラスタ管理者によって、各プロジェクトでLimitRangeやResouceQuotaで、LimitsやRequestsのデフォルト値や上限値が指定されていることが多いです。通常、一般ユーザーからLimitsやRequestsの書き換えは不可能ですが、参照することは可能です。LimitsやRequestsの値について、予め確認しておくと良いでしょう。
Limit Rangeの確認コマンドと出力例
$ oc describe limitrange -n demo Name: core-resource-limits Namespace: demo Type Resource Min Max Default Request Default Limit Max Limit/Request Ratio ---- -------- --- --- --------------- ------------- ----------------------- Pod memory 6Mi 1Gi - - - Pod cpu 200m 2 - - - Container cpu 100m 2 200m 300m 10 Container memory 4Mi 1Gi 100Mi 200Mi - ``` Resource Quotaの確認コマンドと出力例 ``` $ oc describe resourcequota -n demo Name: core-object-counts Namespace: demo Resource Used Hard -------- ---- ---- configmaps 0 10 persistentvolumeclaims 0 4 replicationcontrollers 2 20 secrets 9 10 services 0 10
LimitsとRequestsの設定
それでは、例にならってoc setコマンドでDeploymentConfigにリソースの上限を追記してみましょう。
oc set resourcesによるLimits、Requestsの追加
$ oc set resources dc/go-httpd --limits=cpu=200m,memory=512Mi --requests=cpu=100m,memory=512Mi
追加が終わったら、oc describeコマンドで確認してみます。Limits、Requestsどちらも追加されていることが確認できます。
Limits/Requestsの設定を確認
$ oc describe dc go-httpd
... 略 ...
Limits:
cpu: 200m
memory: 512Mi
Requests:
cpu: 100m
memory: 512Mi
LimitsとRequestsの設定が有効になっていることを確認するために、実際に負荷をかけてCPUリソース制限が働くか確認してみましょう。Probeの実験で利用したGoアプリケーションにstressHandler()を追加します。
リスト11:負荷を掛けるstressHandler()の追加
import (
"fmt"
"runtime"
"net/http"
"time"
)
func stressHandler(w http.ResponseWriter, r *http.Request) {
done := make(chan int)
for i := 0; i < runtime.NumCPU(); i++ {
fmt.Printf("Running ... core #%+v\n", i) // output for debug
go func() {
for {
select {
case <-done:
return
default:
}
}
}()
}
time.Sleep(time.Second * 300)
close(done)
}
func main() {
...
http.HandleFunc("/stress", stressHandler)
...
}
今回は、/stressというエントリーポイントを追加しています。/stressにアクセスするとstressHandler()を呼び出し、5分間無限ループを回します。
Podの状態を確認
$ oc get pod -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE go-httpd-13-k7kc7 1/1 Running 1 12m 10.128.1.138 knakayam-ose311-all <none> $ curl 10.128.1.138:8080
別のターミナルを立ち上げて、Node上でtopコマンドを実行してみます。CPUの利用率が100%にはならず、一定の値で制限されていることが分かります。
無限ループを回してもCPU利用率は100%にならない
# top PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 79214 1000100+ 20 0 108696 2940 2124 S 19.7 0.0 0:05.07 main
水平Podオートスケール(Horizontal Pod Autoscaler)
Horizontal Pod Autoscaler(以下、HPA)は、CPUやメモリリソースの値に基づいて、Podを自動的に水平スケールさせる仕組みです。まずは、HPAの概要を見てみましょう。OpenShiftで水平Podオートスケールを利用するときには、HPAというオブジェクトを利用します。HPAが、metrics-serverからメトリックスデータを収集し、DeploymentConfigやReplicationControllersを操作して、水平にPodをスケールさせます。
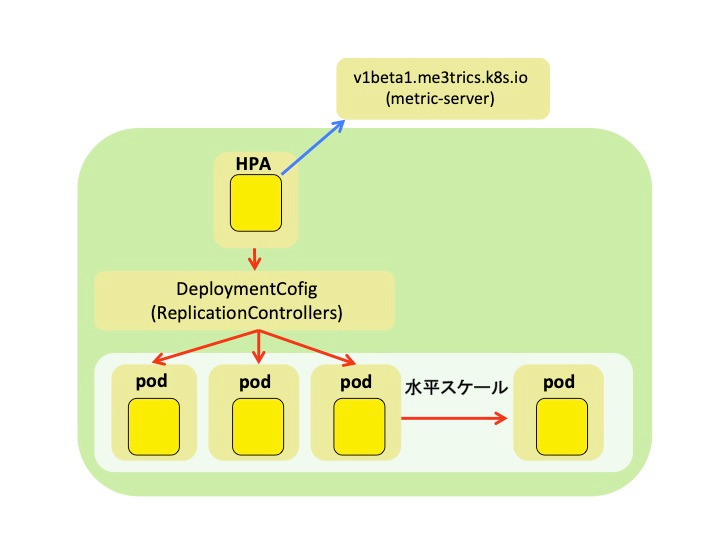
HPAオブジェクトのフロー
Podをスケールアウトまたはスケールインさせる時のPodの数の計算式は、以下のようになります。
ターゲットとなるPodの数 = 切り上げた値((現在のPodのCPU使用率の合計)/(HPAで設定されたCPU使用率のターゲット値))
具体的な値に置き換えて考えてみるとわかりやすいでしょう。例えばA、B、Cという3台のPodがあったとして、ターゲットのCPU使用率は70%とします。以下のケースでPodの数はどうなるでしょうか?
- ケース1:A(70%)、B(60%)、C(80%)
- ケース2:A(10%)、B(10%)、C(10%)
ケース1を計算式に当てはめると
(70 + 60 + 80) / 70 = 3
となり、Podの数は3にスケールアウト/インされます。
一方、ケース2を計算式に当てはめると、
(10 + 10 + 10) / 70 = 1(切り上げ)
となり、Podの数は1にスケールアウト/インされます。
それでは、次にHPAを利用してみたいところですが、OpenShift 3.11でHPAを利用する場合には、metrics-serverというサービスが起動している必要があります。クラスタ管理者権限で、コマンドoc describe apiservice v1beta1.metrics.k8s.ioを実行してみましょう。以下のようなStatusが確認できれば、metrics-serverがデプロイされ、利用できる状態です。
metrics-server APIのステータス確認
# oc describe apiservice v1beta1.metrics.k8s.io
... 略 ...
Status:
Conditions:
Last Transition Time: 2019-01-12T01:41:26Z
Message: all checks passed
Reason: Passed
Status: True
Type: Available
oc adm topコマンドによるpodのリソース使用率の確認
# oc adm top pod NAME CPU(cores) MEMORY(bytes) go-httpd-8-n8kcc 47m 18Mi
metrics-serverがデプロイされていて、リソース確認が可能な環境であった場合には、HPAを利用してみましょう。HPAの利用には、horizontalpodautoscalers(hpa)というオブジェクトを作成します。HPAは、DeploymentConfigとは異なる、独立したオブジェクトです。DeploymentConfigにHPAを設定するわけではないので、今回はoc autoscaleというコマンドを利用します。
oc autoscale コマンドによる、HPAオブジェクトの作成
# oc autoscale dc go-httpd --min=1 --max=3 --cpu-percent=10 # oc get hpa NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE # oc get hpa NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE go-httpd DeploymentConfig/go-httpd <unknown>/10% 1 3 0 19s
oc get hpaを実行すると、DeploymentConfigと同じ名前のhpaオブジェクトが作成されていることが確認できます。TARGETSが<unknown>/10%となっていますが、1分ほどで値が取得できるので少し待ちましょう。
TARGETSの値が取得できた後の表示
# oc get hpa -w NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE go-httpd DeploymentConfig/go-httpd 0%/10% 1 3 1 27s
無事に値が取得できたら、Limitsの検証で利用した/stressのアクセスポイントにアクセスして、負荷をかけてみましょう。
負荷をかけてみる
$ curl `oc get pod go-httpd-8-n8kcc -o template={{.status.podIP}}:8080/stress`
負荷をかけると、TARGETSの値が増加します。REPLICASの数が--maxで指定した3まで増えることが確認できました。
オートスケールされていることを確認
# oc get hpa -w NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE go-httpd DeploymentConfig/go-httpd 47%/10% 1 3 1 1m go-httpd DeploymentConfig/go-httpd 47%/10% 1 3 3 1m
念のため、oc get podで確認しても、3つのPodにスケールアウトされていることが分かります。
Podも増えている
# oc get pod NAME READY STATUS RESTARTS AGE go-httpd-8-5x54h 1/1 Running 0 20s go-httpd-8-crq94 1/1 Running 0 20s go-httpd-8-n8kcc 1/1 Running 0 1m
5分間待てば、負荷をかけるプロセスも終了しますが、Podを削除しても構いません。高負荷状態が収まると、CPU使用率も低下し、スケールインが始まります。
高負荷状態が収まるとスケールイン
# oc get hpa -w NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE go-httpd DeploymentConfig/go-httpd 0%/10% 1 3 3 7m go-httpd DeploymentConfig/go-httpd 0%/10% 1 3 1 7m
以上が、HPAの利用方法でした。今回はCPUを対象に実施しましたが、メモリやカスタムメトリックスを使って、別の値でHPAを実現することも可能です。
- この記事のキーワード
バックナンバー
この記事の筆者
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
