はじめに
前回のシステム開発のドキュメントフロー図では、次の3つのデータモデルが出てきました。
- 要件定義工程:「概念データモデル」
- 基本設計工程:「論理データモデル」
- 詳細設計工程:「物理データモデル」
これらのデータモデルとは、いったいどのようなものなのでしょうか。今回は、データ中心設計(Data Oriented Approach)の考え方に則ったデータモデルを理解した上で、現代におけるデータモデリング手法について解説します。
データモデリングとは
データモデリングとは「データを構造的に整理し、ビジュアルなモデルに表現することにより、データを効率的に扱えるようにすること」です。
みなさんは“Data is the new oil”という言葉を聞いたことがありますか? クラウド→ビッグデータ→AIといった最近の技術トレンドを背景にデータの重要性が強く認識され、それを端的に表す言葉として最近よく耳にします。
“The world’s most valuable resource is no longer oil, but data!”
つまり、産業の発達を支えてきた石油に変わって、現代ではデータが最も価値があるというのです。
そして、この言葉には次のような文章が続きます。
“Data is the new oil. It’s valuable, but if unrefined it cannot really be used. It has to be changed into gas, plastic, chemicals, etc to create a valuable entity that drives profitable activity; so must data be broken down, analyzed for it to have value.”
つまり、石油は精製しなければ利用できず、価値があるものにするにはガスやプラスチック、化学などに変える必要がある。同じようにデータに価値を持たすには“broken down”して分析する必要がある。
ここで言う“broken down”がデータモデリングです。実は世の中にあるデータはそのままでは非構造化データです。最近はAIのように非構造化データを扱える技術も出てきましたが、通常、コンピュータが処理するには、これを構造化データにしなければなりません。データモデリングによってデータを構造化し、さらに人が理解しやすいようにビジュアルなモデルにすることでデータが価値を持つのです(図1)。
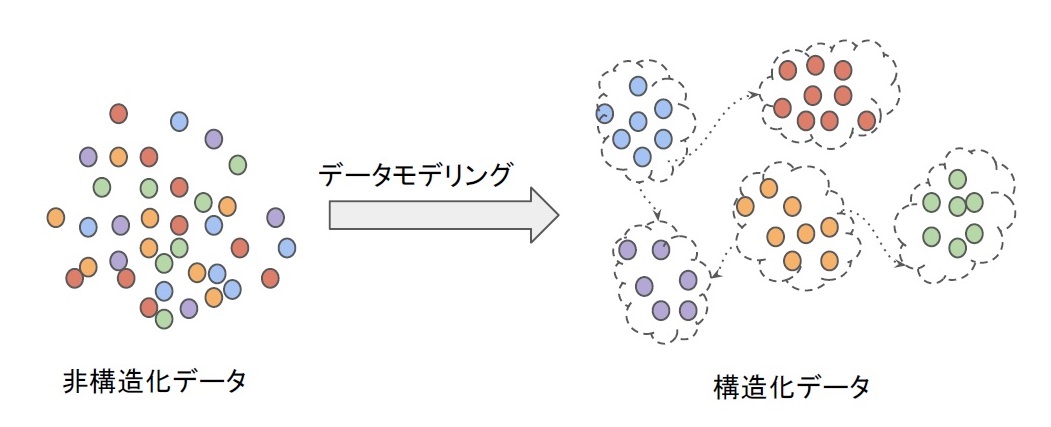
図1:データモデリングのイメージ
データモデリングとER図
一般に、データモデリングはリレーショナルデータベース(RDB)の設計に使われます。データを構造化してER図と呼ばれる図法でモデル化し、リレーショナルデータベースの構築を効率化します。ここで言うERとは、次のようなものです。
- E(Entity):データの集合を表す概念(図1右の“囲み”)
- R(Relation):エンティティ同士の関係(図1右の“矢印”)
3つのデータモデル
冒頭で述べたように、データモデルには「概念データモデル」「論理データモデル」「物理データモデル」の3種類があります。それぞれがどのような役割を果たすのか、前回ユースケース図で表したプログラミング判定サービス「TOPSIC」を題材にして説明しましょう。
(1)概念データモデル
図2は「TOPSIC」の概念データモデルです。複数の問題からテストが作られ、それをアカウント(利用者)が受験し、受験結果が記録されるというデータ関係がシンプルに表されています。前回のユースケース図と見比べてください。ユースケース図になかった「テスト」や「受験結果」というエンティティが新たに登場し、ユースケース図では別々だった「SI管理者」「ユーザー管理者」「中途応募者」というアクターが「アカウント」というエンティティにまとめられています。
図2:概念データモデル
こうやって比較してみると、どちらも概要を理解するために作成するものなのに、まったく違いますね。それはひとえに目的が違うからです。ユースケース図は、どんな人(アクター)が存在して、彼らがシステムにどのように関わるか(ユースケース)を理解するためのものです。一方、概念データモデルは、どんなデータ(エンティティ)が存在して、データ同士がどのような関係(リレーション)かを表すもので、あくまでもデータベース設計を行うためのモデルなのです。
(2)論理データモデル
概念データモデルは大まかなデータ(エンティティ)の持ち方を整理したものですが、これをより具体的で詳細なモデルにしたものが論理データモデルです。IDEF1X(アイデフワンエックス)という記法で書かれた論理データモデル(図3)を使って説明しましょう。

図3:論理データモデル
図2の概念モデルではエンティティ名だけでしたが、表示レベルを上げて「テスト」や「問題」などのエンティティ名の他に、「テストID」や「テスト名」などの項目(Attribute:属性)まで表示しています。エンティティを表す四角形は上下に区切られていますが、上部が一意となる項目(主キー)で下部がその他の項目(アトリビュート)です。
また、エンティティとエンティティの関係(リレーション)は連結線で表わされます。線の終端が黒丸の方がn(複数)、何もない方が1(単数)を意味します。例えば、アカウントと受験結果の関係は1人のアカウントが複数のテストを受けた結果を持つので1対nのリレーションとしています。
「テスト」と「問題」は両端が黒丸、つまりn対nのリレーションになっていますね。複数の問題を選んで1つのテストが作成されると同時に、同じ問題がいろいろなテスト(例えば中途採用のテスト、新人教育用テストなど)に使われる関係が線を見るだけでわかります。
(3)物理データモデル
論理データモデルを物理データモデル化したものが図4です。ここで定義した内容は、そのままリレーショナルデータベースに実装展開できます。「TEST」や「PROBLEM」などのエンティティはテーブル名となり、「TEST_ID」や「TEST_NAME」などの属性名はテーブルの列名(カラム名)となります。日本の場合はテーブル名や列名に半角英数字を使うことが多いので、論理データモデルでは日本語(全角)で表し、物理データモデルは半角英数字を使うケースが多いです。
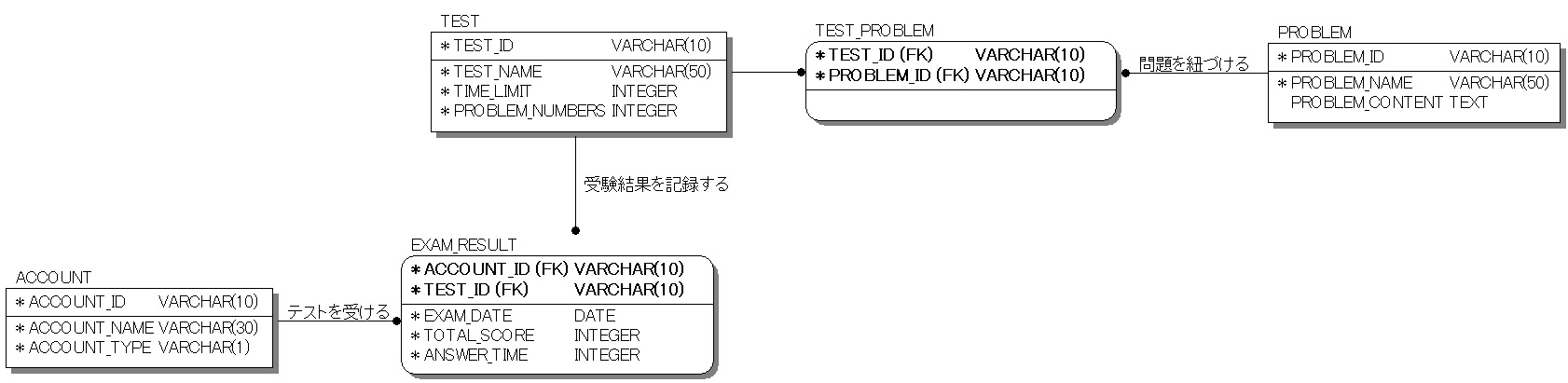
図4:物理データモデル
ここでは表示レベルをさらに上げて、属性名に加えてデータ型とサイズも表示しています。例えば「TEST」エンティティの主キー「TEST_ID」のデータ型はVARCHAR、サイズは10になっていることが分かります。リレーショナルデータベースではn対nリレーションは実装できないので、両端が黒丸というリレーションは使いません。そのため「TEST_PROBLEM」という中間エンティティを用意して、2つの1対nリレーションで関連付けできるようにしています。
データモデリングの流れ
包丁を研ぐときは、まず「荒砥」で砥ぎ、次に「中砥」でより細かく砥いで、最後に「仕上げ砥」できめ細かく仕上げます。絵を描くときもデッサンからスタートしますし、小説を書くときもあらすじから作り始めるのが普通です。何かを作るには大まかなデザインからスタートして、順次、詳細な内容を詰めてゆくのが王道なのです。
データモデリングも同じです。最初に「概念データモデル」で大まかなエンティティを定義し、次に「論理データモデル」でより詳細な内容に落とし込み、最後に「物理データモデル」でそのままリレーショナルデータベースに実装できるレベルに仕上げます(図5)。
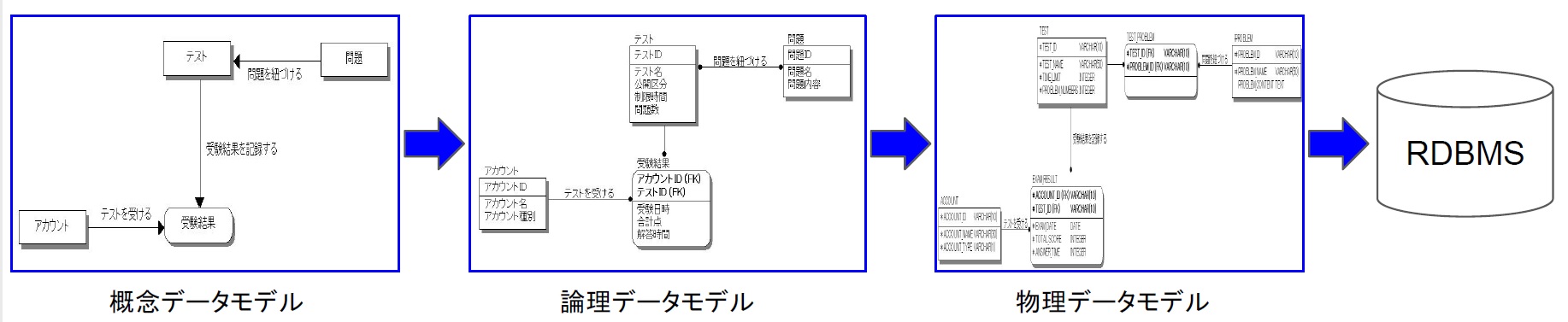
図5:データモデリングの流れ
と、ここまで説明してきてなんですが、データモデリングの教科書に出てくるこの“王道”は、実際にはあまり使われません。その一番の課題は可逆性がないことで、ER図のメンテナンスが大変だからです。
概念データモデル→論理データモデル→物理データモデル→RDBMSという流れで実装するのは一見きれいですが、実際にはRDBMSのテーブルや列の変更が頻繁に生じます。その都度、ER図の各モデルを上流から順番に変更してゆくのは面倒ですし、逆にRDBMS→物理データモデル→論理データモデル→概念データモデルと変更を遡ってメンテナンスしてゆくのもやっかいです。そのため、Visioなどの作図ツールで“王道”に従ってER図を書いていた人も、メンテナンスの大変さに直面して少数派に留まっていたのです。
この状況を一変させたのが専用のERツールです。データベースに接続できるデータモデリングツール(ERツール)が登場した結果、図6のように論理モデルと物理モデルを一緒に設計する論物一体方式が主流になり、メンテナンス面で断絶のある概念モデルは、特別の事情がない限り(もしくはやはり王道を重視するタイプ以外は)、あまり作成されていません。
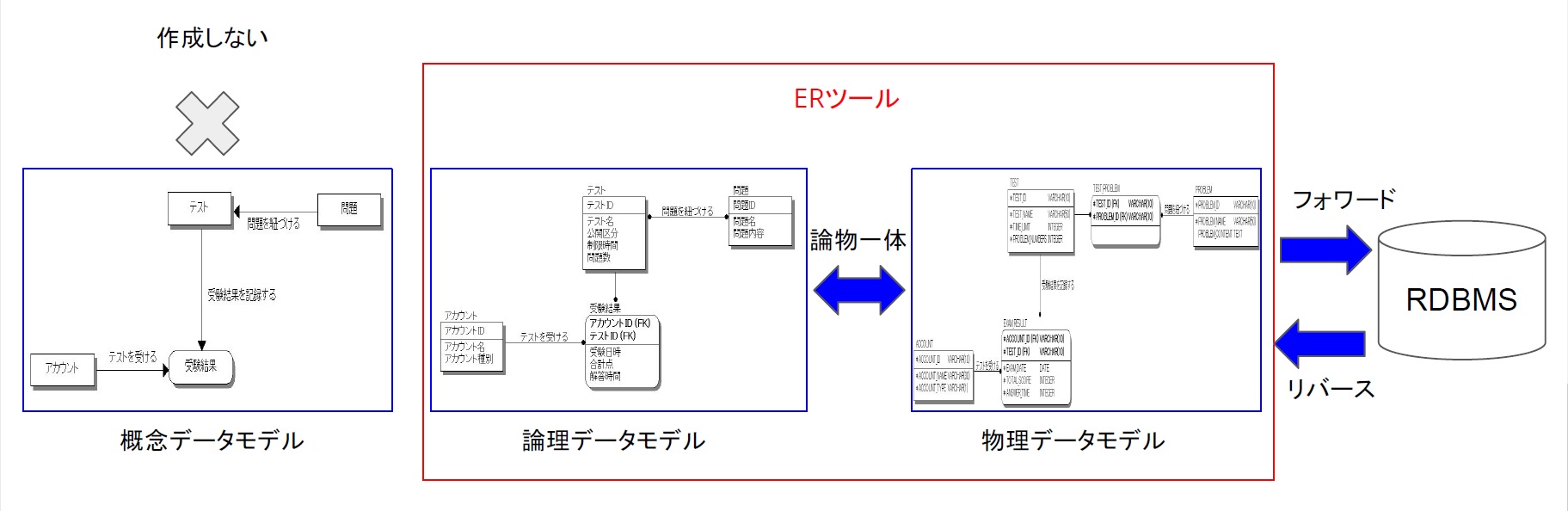
図6:ERツールを使ったデータモデリング
ERツールは、物理データモデルの情報をRDBMSのテーブルや列、制約などに「フォワード」することができます。また、RDBMSのメタデータをリバースしてER図を逆生成することもできるので、RDBMSの変更を一瞬で物理データモデルに反映できるようになったのです。つまり物理データモデルとRDBMSの間は双方向に連携できるため、メンテナンスフリーになったわけです。
ここまでくると、今度は論理データモデルのメンテナンスがやっかいです。そこで、論理データモデルは物理データモデルと同じ一体構造にして、論理と物理もメンテナンスフリーにしたのが論物一体モデルの考え方です。図3の論理データモデルではn対nリレーションを使っていましたが、これだと物理データモデルと構造が異なるので、図7のように中間エンティティを入れて同じ構造にするのです。
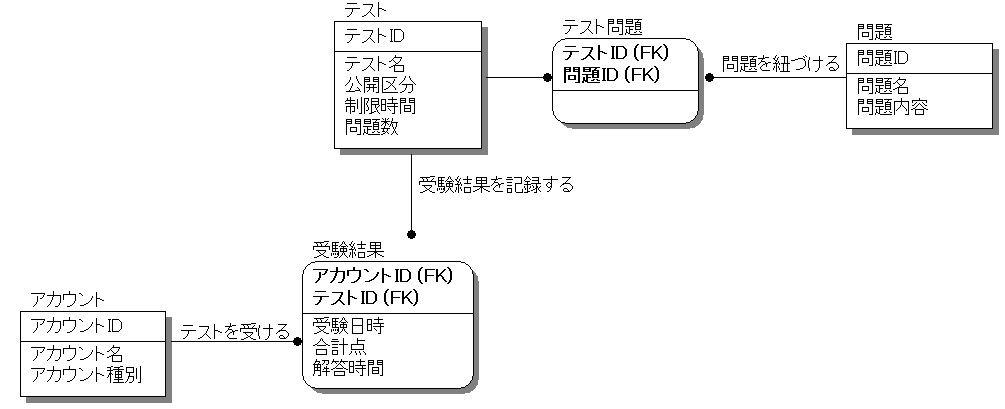
図7:論理データモデル(論物一体)
- 麻里:論物一体モデルってってどういう意味なんですか?
- 先輩:具体例で説明しようか。これはERツール(OBER)で「テスト」エンティティを定義した内容なんだけど、ここには論理データモデルの情報と物理データモデルの情報が一体となって定義されている(図8)。
- 麻里:???
- 先輩:テーブル名、カラム名、データ型、長さ、なんかはRDBMSのメタデータになるから、物理データモデルの定義だろ。
- 麻里:あ、確かにそうですね。
- 先輩:で、必須、デフォルト値、制約、定義内容などは、それぞれNull制約、デフォルト制約、チェック制約、カラムコメントに相対しているから、これも物理と言える。
- 麻里:制約なんかもERツールで定義できたりするんですね。
- 先輩:一方、エンティティ名や属性名、ドメイン、コード定義などは、RDBMSに対応するメタデータがない。これらは、あくまでもER図で効率的に設計するため論理データモデル情報なんだ。
- 麻里:エンティティ名や属性名ってわかるけど、ドメインって何ですか?
- 先輩:属性のディクショナリ(辞書)のこと。例えば「テストID」って属性は「テスト」や「テスト問題」「受験結果」などのエンティティで使われるだろう。そういう場合、この属性をドメインとしてデータ型や長さなどの定義も一緒に辞書化しておくと、ドメインを変更するだけで全てのエンティティに変更を反映できるんだ。
- 麻里:なるほど、エンティティごと個別だと定義ミスが発生しうるけど、それも防止できますね。もう1つコード定義っていうのも論理?
- 先輩:うん、これもディクショナリだよ。このようなコード定義をExcelに書き留めるのではなく、ERツールで定義しておけば、どの属性でどのコード定義を使うのか分かって便利だろう(図9)。さらに「定義した内容で制約を作成」というチェックをOnにすればチェック制約が作成できるから、物理データモデルの要素もある。
- 麻里:な~るほど。同じ情報なのに物理にも論理にもなるんですね。
- 先輩:そういうの多いよ。例えばリレーションだってRDBMSに反映させれば参照整合性制約になるから物理だろう。でも、参照整合性制約を作りたくないケースもあって、そんな場合でもER図上はリレーションの線が見えた方がわかりやすいから、論理だけの線にすることもできるんだ。
- 麻里:たしかに、リレーションのないER図って間が抜けてますよね。
- 先輩:論理データモデルは設計用、物理データモデルは実装用と考えれば良い。論理データモデルで設計した後で物理データモデルを実装するという王道ではなく、論理と物理を一緒に設計して表示の仕方で切り替えるというのがERツールならではの使い方かな。
- 麻里:でも、男女の付き合いはやっぱり王道が良いなぁ。最初にこういう感じで、次にこうなって、そしてこんなことになっちゃって…(うふっ)。
- 先輩:やれやれ、なに妄想を膨らましてんだか…。

図8:ERツール(SI Object Browser ER)のエンティティ画面
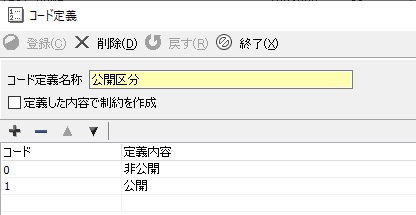
図9:コード定義のディクショナリ化
データベースなどに実際に格納されるデータに対し、格納するための定義情報のことをメタデータと言います。タンスに例えれば、タンスに収納される洋服や下着などがデータで、引き出しの数や高さ、幅、奥行などの情報がメタデータです。
RDBMSで言えば、テーブル名「TEST」やカラム名「TEST_ID」「TEST_NAME」、データ型「VARCHAR」、サイズ「10」などがメタデータで、そこに格納される実際のデータ(test001、2020中途採用テストなど)がデータです。
SQLで言うと、DML(Data Manipulation Language:データ操作言語)のSelect、Insert、Update、Deleteはデータを対象にし、DDL(Data Definition Language:データ定義言語)のCreate、Drop、Alterなどはメタデータを対象にしたコマンドです。
おわりに
通常、アプリケーション設計とデータベース設計は同時並行で行われます。今回は、きれいなデータベース設計を行うためのデータモデリングについて“王道”と“実際”という観点から解説しました。
ツールの登場が“王道”の手順を変えることはままあります。例えば、昔の会計では仕訳入力→仕訳帳→総勘定元帳→試算表→精算表→決算書という手順が王道で、簿記試験でもこれに沿った問題が出ていました。でも会計システムの登場により、仕訳入力するだけで、必要に応じて各種の帳票がさっと出力できるようになっています。
システムを積極的に活用して業務効率を飛躍的に上げる、現代のエンジニアにとってそんなスキルも重要なのだと思います。
この記事をシェアしてください
関連記事
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
