データ分析システムの全体像を理解する(8) データカタログとデータ・プレパレーション・ツール
2021年7月13日 6:30
はじめに
前回は、「統計的な分析」=「ビッグデータ解析」において新たに必要となるテクノロジーとして、データウェアハウスとは異なる構造を持つデータレイクと、RDBMSとは異なる種類のNoSQLデータベースについて解説しました。今回は、引き続き新しいテクノジーとしてデータカタログとデータ・プレパレーション・ツールについて解説します。
スキーマ・オン・ライトとスキーマ・オン・リード
前回は、データウェアハウスとデータレイクの違いをデータベース構造の視点から見ていきましたが、今回は、別の視点で見てみましょう。
データウェアハウスとデータレイクは、ともにデータ分析に必要となる多種多様な大量のデータを1ヵ所に蓄積することを目的としていますが、蓄積前後でのデータ収集と加工処理を行う順序が大きく異なります(図1)。
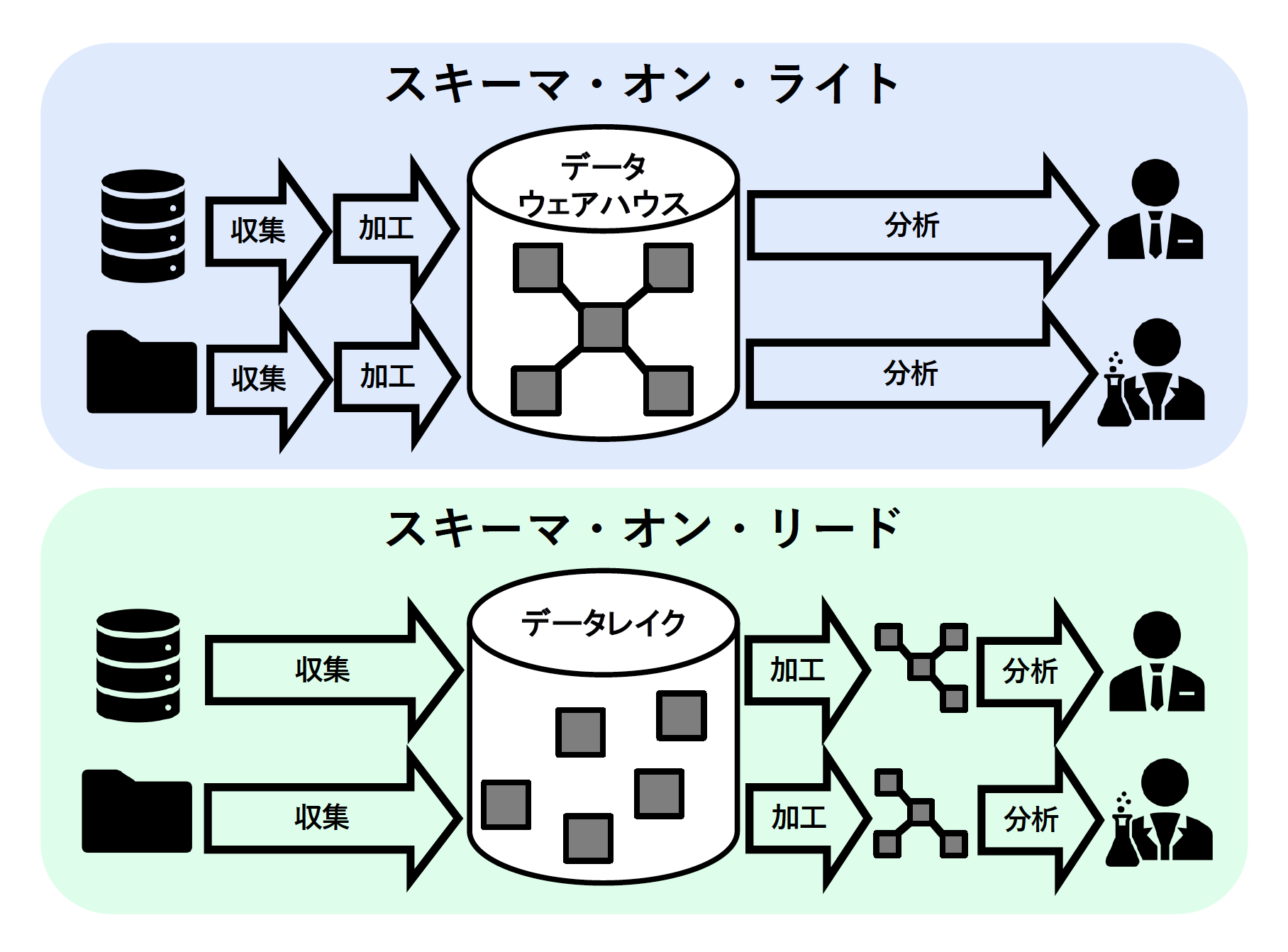
図1:スキーマ・オン・ライトとスキーマ・オン・リード【出典】ITR
データウェアハウスでは、データ分析を行うユーザーの要件をあらかじめ定義したうえでデータモデルを設計し、それに合わせて必要なデータを収集、加工してから蓄積するという順序になります。このやり方は、データの蓄積(書き込み)の時点で、データベースの構造(スキーマ)がすでに決定されているという意味で、スキーマ・オン・ライト(Schema on Write)と呼ばれます。
一方、データレイクでは、ユーザー要件定義を行うことなく、収集可能なデータを全て未加工の状態で蓄積します。その後、データレイクのユーザーが、各自の要件に基づいて必要なデータを抽出し、自ら加工します。このやり方は、蓄積済みのデータをユーザーが抽出(読み込み)した後で、データベースの構造(スキーマ)が決定されるという意味で、スキーマ・オン・リード(Schema on Read)と呼ばれます。
スキーマ・オン・リード方式をとるデータレイクは、ビッグデータ解析において大きなメリットがあります。ビッグデータ解析で行われるデータマイニングでは、解析結果の検証と分析モデルの修正を繰り返すことで、初めて十分な精度が得られます。このような手順を踏むためには、蓄積後にデータ加工を行うスキーマ・オン・リード方式が適しています。また、ビッグデータのような短時間で大量に発生するデータを漏れなく蓄積するためには、データベースへの書き込みをできるだけ高速に実行する必要があり、この点でも蓄積前でのデータ加工を必要としないスキーマ・オン・リード方式が適しています。
データスワンプとデータカタログ
スキーマ・オン・リード方式をとるデータレイクには、デメリットも存在します。データレイクに蓄積されたデータはスキーマを持たないため、データレイク内のどこにどのようなデータが存在するかがわからず、分析に必要なデータを特定し抽出できなくなるデータスワンプ(Data Swamp:データの沼地)と呼ばれる状態に陥ります。したがって、データレイクを有効に利用するためには、意図的にメタデータ情報を収集・管理し、データの所在とその属性を効率的に特定できる仕組みを作る必要があります。
データレイクがデータスワンプ状態に陥るのを防ぐためには、データカタログ・ツールを利用したデータカタログの構築が有効です。データカタログとは、元来、企業内で保有するデータの発生元、形式、定義、計算方法といったメタデータが一元管理される格納場所のことを意味し、データディクショナリやメタデータ・リポジトリとも呼ばれます。一方、メタデータを収集、管理、検索する機能を提供するツールをデータカタログ・ツールと呼びます。
データカタログ・ツールが提供する基本的な機能は、以下の2つです。
- メタデータの収集と登録
・ファイル/テーブル/カラムの名称やファイル/データ形式といった物理的なデータ属性を収集し、業務における呼称などの検索に有用となるビジネス用語(キーワードや説明)を付加する機能 - メタデータの検索とデータの閲覧、抽出
・キーワードを入力して関連度の高いメタデータを一覧表示し、メタデータと紐づけられた実データの内容を閲覧、抽出する機能
データカタログの構築においては、いくつかの留意点があります。
データカタログ・ツールを導入すれば、入れ物としてのデータカタログは作成されますが、それだけで自動的にメタデータが収集・登録されるわけではありません。また、物理的なデータ属性の収集と登録はIT部門で行えますが、効果的な検索を可能にするためのビジネス用語の登録には、ユーザーが多大な工数と時間を提供する必要があります。したがって、データカタログ構築の初期段階においては、優先度の高いユーザーに限定して、メタデータの収集と登録を行うのが効率的と言えます。
データカタログの運用も重要です。ビッグデータ解析のテーマが追加されると同時に、データレイクにも新たなデータソースからのデータが格納されるようになります。また、IoTのようなデバイス依存性の高いデータソースの場合、デバイスの更新・変更によってデータ形式が変わってしまうことも珍しくありません。データレイクにおけるデータカタログの運用には、このようなデータソースの頻繁な追加・変更に対応できる体制を整備する必要があり、IT部門だけでなくユーザー部門やデータソースに関連する部門も含めた連携が求められますが、その実現は容易ではありません。
データカタログの構築と運用には、第5回「自由な分析環境とデータガバナンス強化を両立させる組織体制」で解説したコーポレート・データモデルの作成と運用と同様に、BICC、データスチュワード、CDOなどの組織体制の整備が必要となります。
ETLツールとデータ・プレパレーション・ツール
スキーマ・オン・ライトとスキーマ・オン・リードの違いの1つに、データ分析前のデータ加工のタイミングがあります。この違いは、データ加工に使われるツールの選択にも影響します。第3回「データウェアハウスとスタースキーマ」でも解説したとおり、データウェアハウスへのデータ蓄積前に行われる加工処理、すなわちETL処理にはETLツールが使われます。一方、データ分析者が、各自の分析要件に基づいてデータレイクから必要なデータを抽出し、自ら加工する場合には、データ・プレパレーション・ツールが使われます。
ここからは、ETLツールとデータ・プレパレーション・ツールの違いについて解説します。
データウェアハウス(DWH)内のデータを最新の状態で維持するために、業務システムで新たに生成されるデータを抽出(Extract)、変換(Transform)し、DWHにロード(Load)する一連の処理をETL処理と呼びます。ETL処理は、SQLやC言語などを使ったプログラミングにより開発されますが、ETLツールは、GUIを用いて視覚的に処理フローを定義する、あるいは標準的な処理を部品化し、再利用するといった機能を提供することで、ETL処理の開発生産性を向上させます。
ETLツールの利用者は、ITスキルを持つエンジニアであり、データベースの専門知識やプログラミング・スキルを持っていることが前提となります。
DWHの構築は、要件定義、設計、開発からテストに至るウォーターフォール型のシステム開発プロセスで行われるのが一般的です。ETLツールは、このプロセスの開発フェーズで利用されますが、バグの修正や機能要件の追加、変更がない限り、一度開発されたETL処理は変更されないため、ETLツールの利用も1度だけとなります。
データ・プレパレーション・ツールは、データ・サイエンティストが行う「統計的な分析」プロセスの中のデータ準備フェーズにおいて、データ収集やデータ加工のために利用されます(図2)。
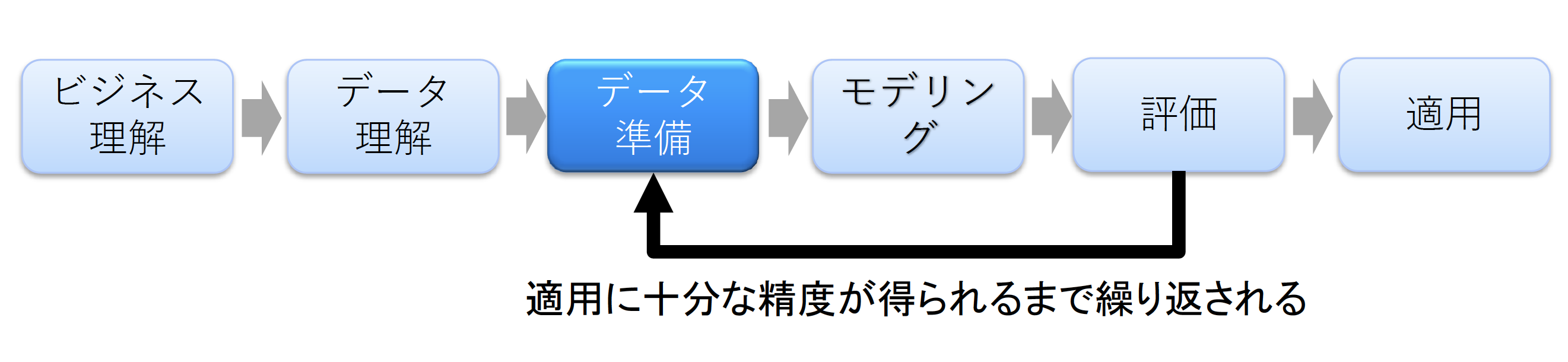
図2:データ・サイエンティストが行う「統計的な分析」プロセス【出典】ITR
データ準備フェーズで行われる処理は、ETL処理で行われる抽出(Extract)、変換(Transform)、ロード(Load)とほぼ同じです。しかし、データ・プレパレーション・ツールの場合、利用者であるデータ・サイエンティストは、ITエンジニアのようなデータベースの専門知識やプログラミング・スキルを持ちません。したがって、処理の開発はプログラミングを必要とせず、GUI操作のみで完結できるようになっています。
データ・サイエンティストが行う統計的なデータ分析プロセスは、分析モデルの精度が向上し適用フェーズに至るまでは、データ準備、モデリング、評価の3フェーズを繰り返す、部分的にスパイラル型となります。そのため、データ・プレパレーション・ツールは、1人のデータ・サイエンティストが継続的に利用します。
ETLツールとデータ・プレパレーション・ツールには、利用局面や想定される利用者の性質に明確な違いがありますが(図3)、データの抽出(Extract)、変換(Transform)、ロード(Load)という中心となる機能は同じであるため、単純な機能比較では区別がつきにくいと言えます。さらに、ツール提供ベンダーの多くは、ETLツールとデータ・プレパレーション・ツールの両方を提供しており、ベンダー単位での選定だけで適切な製品を選択できるとは限りません。

図3:ETLツールとデータ・プレパレーション・ツールの相違点【出典】ITR
ETLツールとデータ・プレパレーション・ツールの製品選定においては、両者の利用局面や想定される利用者の性質の違いを正しく理解し、自社のニーズを明確にしたうえで、候補となるベンダーや製品をリストアップしなければなりません。
おわりに
今回まで、データ分析の高度化ステップの第4段階「統計的な分析」までを解説してきました。次回からは、データ分析の高度化ステップの最終段階である「推論・予測」について解説していきます。
「推論・予測」における最大のポイントはAI/機械学習の活用であり、この最終段階は「AI/機械学習を活用した分析」と言い換えても過言ではありません。そこで、テーマを「AI/機械学習とデータ分析の関係を知る」と改め、AI/機械学習がデータ分析の業務、組織、システムに与える影響を解説していきます。
この記事をシェアしてください
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
