データ処理ライブラリーの並列化/高速化をRustによって実装したWeld
Stanford大学のチームがデータ処理ライブラリーをRustで実装した。その背景を紹介する。
2020年6月10日 6:00
今回は、Mozilla Foundationが開発をリードするオープンソースのメモリーセーフを実現した低レベルプログラミング言語、Rustのユースケースを紹介する。Stanford大学の研究室で開発されているWeldというデータ解析ライブラリーが、Rustで開発されたことを解説するプレゼンテーションを取り上げて、解説していく。こちらのプレゼンテーションは、RustCon 2019のセッションの一つとして行われたもので、プレゼンターはStanford大学のShoumik Palkar氏だ。

プレゼンテーションはデモを含んだ約30分のセッションとなった
Palkar氏は、最初にこの研究の背景を紹介する。最新のデータ分析アプリケーションでは、多くのライブラリーを利用してデータの集計や解析が行われている。そしてその多くがオープンソースソフトウェアとして実装されており、開発に利用される言語もさまざまである。そのため、高速に実行するための最適化が行われておらず、結果として処理時間が延びてしまうというのが現状であるという。
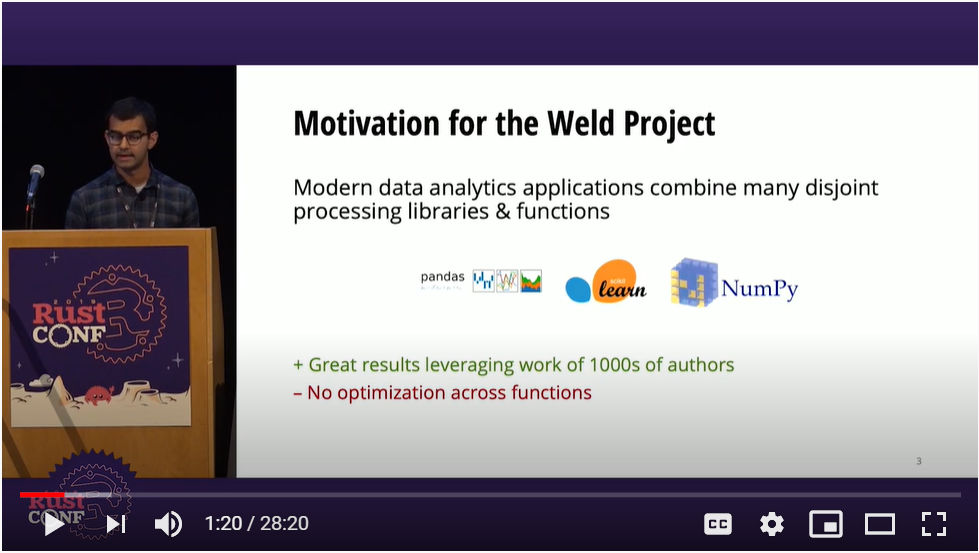
多くのデータ解析ライブラリーが最適化されていないという背景
その一つの例としてPandas、NumPy、Scikit-learnなどのライブラリーを挙げて説明。ここではデータのパース、フィルター、そして平均をとるなどの処理をそれぞれPandas、NumPyのライブラリーを使用するケースを例に説明している。ポイントは多重のループ構造をそのままライブラリーに任せていると、データの配置や演算などに多くのステップが必要となり、最終的に同じ処理を行うコードをCなどで書いた場合の30倍以上の処理時間がかかってしまうという。このことは、Palkar氏のチームにおいては重大な問題であったということだろう。

複数の配列処理に30倍以上の無駄な時間がかかっている
そこでStanford大学のチームはSQLや機械学習、グラフ構造のデータ処理に共通する処理をライブラリーとして並列処理できる形で実装し、高速化を図ることにしたというのが、このスライドだ。

複数のアプリケーションから利用できる共通の高速処理ライブラリーを目指すWeld
ポイントは「Weld IR(Intermediate Representation)」と呼ばれる中間言語への変換と、それをさらに高速化、最適化するOptimizerの存在だろう。これは一つ前のスライドの例のように複数行の処理をそのまま実行するのではなく、一度IRに変換した後に、並列化、最適化するという2段階の処理となる。
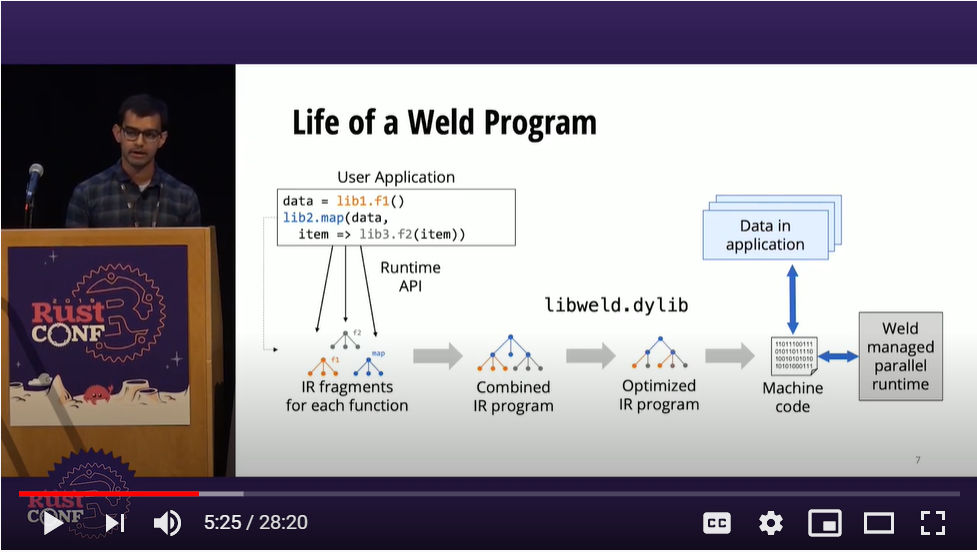
ソースコードからIR、機械語に変換する流れ
このスライドではユーザーアプリケーションに記述された命令を一旦IRに変換した上で、最適化、並列化するフローとなる。

複数のプロセスを経て最適化、並列化される
そしてRustで書き直した結果、処理によって6~180倍という高速化を実現できたというのが次のスライドだ。ここではPandasとNumPy、TensorFlowとNumPy、そしてSpark SQLからの呼び出しの例において大幅な性能向上がみられることが解説された。上のグラフと右下のグラフは対数軸になっていることからもわかるように、大きく高速化が行われたことがわかる。

大幅な高速化が実現できた
ここからWeldのコードをREPL(Read-Eval-Print-Loop)インタープリターを使って実行するデモを行った。ここでは簡単な処理がどのようにIRに変換され実行されているのかをターミナルに表示されるというデモで、短い時間ながら配列から値を取り出し、Loopを回すコードが生成されるようすを見ることができる。
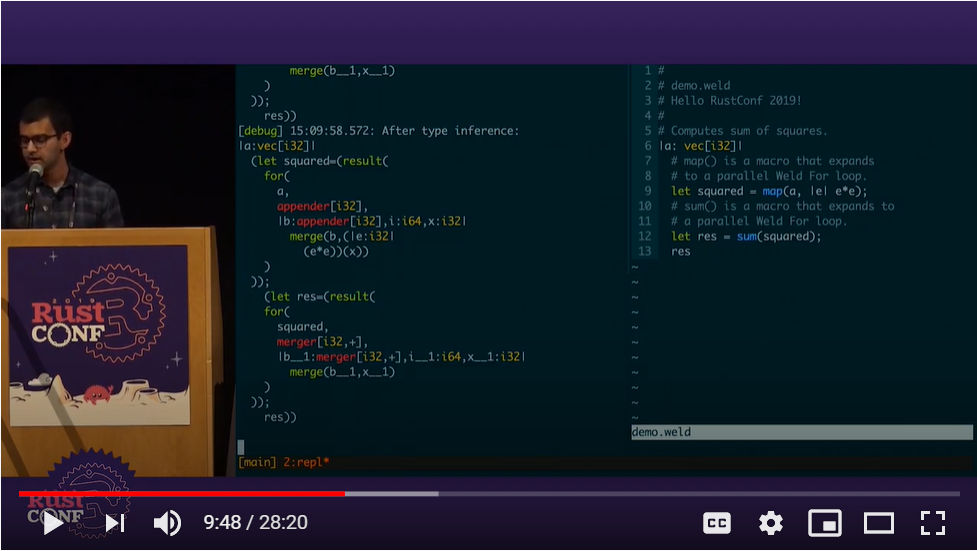
Weldのデモ。元のコードから徐々にIRに変換されていくようす
Stanford大学のチームとしては、高速化のために最初はScalaを使って実装しようとしたことが次のトピックだ。Scalaの良い点として「数値計算やパターンマッチングが得意なこと」「すでに多くの利用者がおり、エコシステムが存在すること」などを挙げた。

Scalaの欠点
一方Scalaの欠点として「他の言語へのエンベッドが難しいこと」「JIT(Just in Time)コンパイルが遅いこと」「JVM(Java Virtual Machine)を利用しないといけないこと」「ビルドシステムが使いづらいこと」などを挙げた。そしてそれらを踏まえた上で、チームとして必要な要件を挙げた。

ライブラリーに必要な要件
そしてそれに適合するプログラミング言語としてGo、Java、C++、Rust、Python、Swiftが候補になったという。

Weldの開発言語の候補となったプログラミング言語
その結果、最終的に残ったのがRustだったというのが次のスライドだ。

Rustが最後に残った
「高速であること」「安全であること」「ランタイムの管理が不要なこと」「豊富なライブラリーが存在すること」「関数型言語であること」そして最後に強調したのが「優れたパッケージマネージャーであるCargoがあること」。これらのポイントにより、Rustが選ばれたというわけだ。
CargoについてはRustのプロジェクトが正式に採用する唯一のビルドツールであり、パッケージマネージャーである。またcrates.ioというパッケージリポジトリーの存在もシンプルなビルドプロセスの構築に役立っていると言えるだろう。イラストとして使われたピカチュウでCargoがコミュニティに愛されていることを示した形になった。

Cargoの良さを解説するPalkar氏
特にビルドするためのmakefileについては、「私はゼロからちゃんと動くmakefileの書き方を知らない(けど、Cargoに任せておけばRustは大丈夫)」というコメントで会場からは笑いが起きたのは、多くのデベロッパーがビルドツールについては痛みを共有しているということの現れだろう。
次に現在のWeldの構造について説明を行った。これはv2.0の実装ということだが、最後の並列化の部分は100%Rustで実装されているようだ。
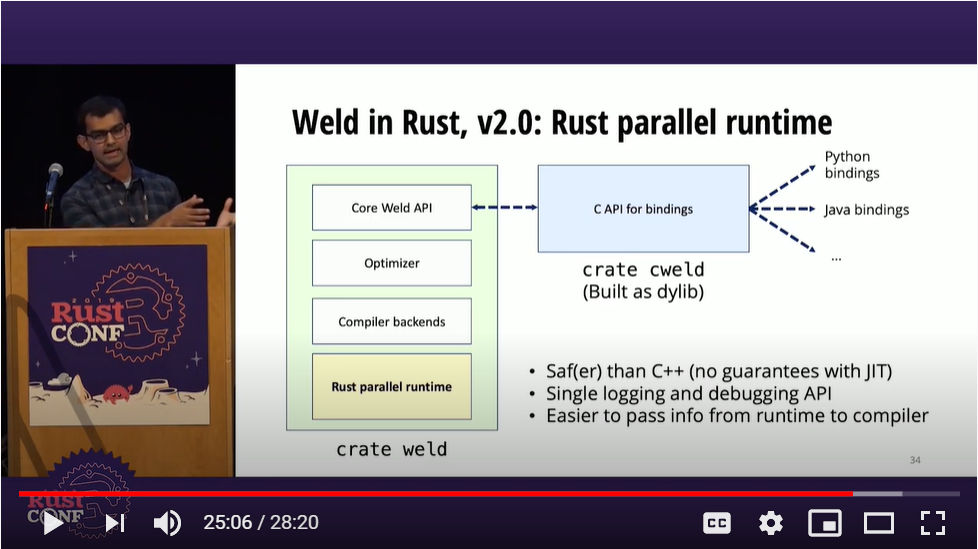
Rustで実装されたWeldの構造
少し前のスライドでこうなる前の構造が紹介されており、こちらのスライドを見ればv1.0ではCでの実装がそのまま残っていたことがわかる。それがRustによる実装に変わったことで、より安全、かつ並列化が行われた上に、これまでC++のモジュールとRustのモジュールが別々にモニタリングやデバッグする必要があったものが、すべてRustだけで完結していることがわかる。
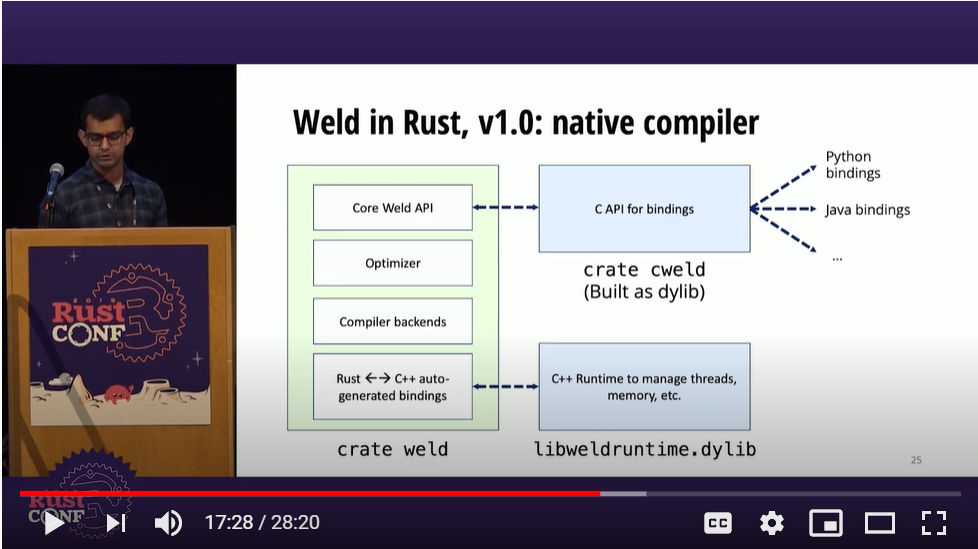
v1.0のWeldの実装。C++の部分が残っている
次に並列化について説明を行い、WeldのコードがRustベースのランタイムで別プロセスとして起動されるようすが解説された。

Rustによる並列化のコード例
Weldプロジェクトそのものについては、現在、30名程度のコントリビューター、Apache Sparkの開発元であるDatabricksやNEC、スウェーデン王立工科大学、オランダのCWIなど産学双方からの支援を受けていることを紹介した。

DatabricksやNEC、スウェーデン王立工科大学などが支援
最後にまとめとして、Rustが高速化、並列化を実現するJITコンパイラを作るための言語として最適であることを紹介して、セッションを終えた。

高速なJITコンパイラを作るためには最適なRust
システム記述言語としてRustが注目を集めているが、ライブラリーを高速化、並列化するための手段として選択したStanford大学の知見は記憶に留めておくべきだろう。メモリーセーフであることから、所有や束縛という新しいパラダイムを学ぶために学習時間が掛かると言われるRustだが、以下のような日本語ドキュメントも用意されているのでぜひ、チャレンジして欲しい。
Rustドキュメントt:プログラミング言語Rust
また英語ながら、Rustを例から学ぶドキュメントサイトも存在する。参考:Rust By Example
今回のWeldについては以下のサイトを参照されたい。
Weld:https://www.weld.rs/
今回の動画は以下のURLから見ることができる。
RustConf 2019 - Rust for Weld, A High Performance Parallel JIT Compiler by Shoumik Palkar
- この記事のキーワード
この記事をシェアしてください
関連記事
Community Over Code Asia 2025、Rustだけのトラックを紹介。中国で着実に拡がるRustエコシステム
2025年12月15日 6:01
RustとGraphQLの連携で高速/シンプルなプログラミングを実現するJuniperとは
2020年7月8日 6:00
高速でメモリーセーフなプログラミング言語、Rustの特徴を紹介
2020年6月3日 6:00
RustNL 2024からデータ圧縮ライブラリーzlibをRustで書き直したプロジェクトのセッションを紹介
2024年8月8日 6:00
Microsoftの年次イベントBuild 2020でメモリーセーフなプログラミング言語Rustを紹介
2020年6月19日 6:00
WebAssemblyを取り巻く最新情報をMeetupから紹介(前半)
2022年7月13日 6:00
バックナンバー
この記事の筆者

筆者の人気記事
SASEのCato Networks、CEOによるセミナーとインタビューを紹介
2020年4月16日 6:00
Rustのエコシステムの拡がりを感じるデスクトップアプリのためのツールキットTauriを紹介
2022年12月16日 6:00
Zabbix式オープンソースの秘密に迫る
2025年1月31日 6:00
WebAssemblyとRustが作るサーバーレスの未来
2020年4月21日 6:00
三菱電機が設立したOSPOのメンバーにインタビュー。「インナーソース」を戦略的に使う背景とは?
2025年10月3日 6:00
エンタープライズLinuxを目指すSUSE、Red Hatとの違いを強調
2015年2月3日 19:00
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
