PingCAP CEOのMax Liu、米HTAP Summit 2022でHTAP登場の背景を語る
PingCAPのCEOが語るHTAPの背景と未来、そして実装の解説。
2023年1月11日 6:30
目次
- HTAP誕生の背景
- デモでHTAPを実現する
「TiDB」活用の具体例を示す - HTAPシステムの特徴は
シンプルなアーキテクチャー そこでLiu氏が使ったのは次のスライドだ。HTAPデータベースを中心にしたシンプルなアーキテクチャーここではシンプルにオレンジ色の部分が中核となるHTAPデータベースを置き、その前後にデータ入力のトランザクションを行う部分とユーザーインターフェースとして様々な切り口で分析を行う機能などが並んでいる。しかしこのデータベースの中身を見てみると、シャーディングされた複数のデータベースのレプリカ、Kafkaなどのストリーミングデータサービスモジュール、そして分析用にETL加工されたうえでデータレイクに格納するまでが必要となると説明した。中核のデータベースサービスの中身は複雑なモジュールの組み合わせこの部分はHTAPとして機能することが期待されるが、従来のSQLデータベース、NoSQLなどでは複雑になるだけでスケーラブルに拡張できるとはとても思えないだろう。ではどうしてそれが可能になるのか、HTAPの実装例としてOSS Insightでも使われていたTiDBの中身を紹介していこう。 ここからはこのセッションから少し脱線して、PingCAPの日本法人、PingCAP株式会社のCTO、林 正記氏が2022年4月14日に行ったWebinarで公開したスライドから抜粋して、HTAPをPingCAPのテクノロジーであるTiDBがどうやって実装されているのかを紹介する。スライドの全体は以下を参照して欲しい。 【参考】「DB性能でお悩みの方必見。スケーラブルなRDB NewSQLはどこまでできるか。」HTAPのユースケース、ZTO Expressのビフォア&アフターこのユースケースでは、Oracle Exadataを使っていたユーザーが容量の上限、ピーク性能の限界、データベースシャーディングによるリアルタイム分析の限界などの問題点をHTAPシステムであるTiDBが解消したことが説明されている。 では、どのように容量、性能の限界を打ち破ったのか、シャーディングが不要なのはどうしてか? について説明しているのが次のスライドだ。SQL解析を担当するTiDBと堅牢なデータストアを実装するTiKVに分離TiDBのアーキテクチャーを解説したスライドではGoogleがSpannerを開発する際の発想と同じでデータベースの役割を明確に分離したこと、それぞれが分散処理によってスケールアウトを可能にしたことを示している。この分散構造にはマスターとなるリーダーノードを固定せずに動的な分散処理を行うため「Raft」と呼ばれる分散合意アルゴリズムを利用している。これはクラウドネイティブなコンテナーオーケストレーションツールの代名詞であるKubernetesの中核であるデータストア、etcdも利用する堅牢かつ高速な分散処理技術だ。最低3つのノードがリーダー、フォロワーを動的に分担することで分散処理を実行また、TiDBではデータストアのメタデータなどを管理するPDクラスタにより複数のノードが自律的に運用できることを示している。SQL解析、分散データストア、データのロケーション管理をそれぞれ分離このように、TiDBそのものが水平にスケールできる分散データベースとしてHTAPに必要な要素を備えていることが解説されている。特にデータベースの分割、シャーディングはデータベース運用チームにとっては頭の痛い問題点であり、これが解決されることは要注目だろう。 - 分散データベースは全てHTAPになる
HTAP誕生の背景
ビッグデータや機械学習を始めとして、インターネットサービスにおいて大量データの活用は既にメインストリームだ。またスマートフォンのモバイルアプリをプラットフォームとしてEコマース、SNS、オンライン動画サイトなど大量のユーザー行動データから産み出されるリアルタイムのレコメンデーションは消費者にとって既に当たり前の機能だろう。
このような大量データのリアルタイム処理を実装することは従来のリレーショナルデータベースでは非常に複雑なシステムが必要となる。またシステム運用も従来のように予め想定されるユーザー数/アクセス数に応じたシステム規模や性能予測ではインターネットから一気に立ち上がるアクセスや爆発的に増えるユーザーに対する様々な分析のニーズに対応できないことが明らかになってきた。
そのようなシステムへの要求に対して、国際的な調査会社であるガートナーは2014年にOLTPとOLAPの両方の機能を備えた新しいデータベースシステムとして「HTAP(ハイブリッドトランザクションアナリティカルプロセッシング)」と呼ばれるカテゴリーを提案した。これまでのリレーショナルデータベースによるトランザクションとリアルタイムの分析処理を同時に処理しながら、分散処理によるスケーラビリティを保証する新しいバックエンドシステムと言える。
今回は、米カリフォルニアで2022年11月1日に初開催された、HTAPに特化したカンファレンス「HTAP Summit 2022」のキーノートから、オープンソースの分散データベースを開発するPingCAPの共同創業者でありCEOのMax Liu氏のセッションを紹介する。セッションのタイトルは「Rise of HTAP」だ。

キーノートセッションに登壇したLiu氏
デモでHTAPを実現する
「TiDB」活用の具体例を示す
Liu氏はHTAPが誕生した背景として、これまでのSQLデータベースは30年前、40年前であれば問題なかっただろう、なぜならビッグデータもなければOLAPも必要なかったからと説明した。しかし現在は大量データのトランザクションとリアルタイムのオンライン分析機能が必須になっていると説明。その両方を兼ね備えたシステムがHTAPだと語った。

OLTPとOLAPを同時に実行できるのがHTAP
そしてビッグデータの誕生以降、トランザクション処理とオンライン分析を兼ね備え、水平にスケールアウトできるデータベースシステムを簡単に説明することは難しいとして「ここからは例を使って説明しよう」と語り、「OSS Insight」というサイトの概要を説明するデモムービーを紹介した。これはソースコードリポジトリとして世界最大を誇るGitHubのリポジトリをデータソースにして様々な分析を実行するWebサービスであり、バックエンドはPingCAPが開発するオープンソースの分散データベース「TiDB」で実装されている。
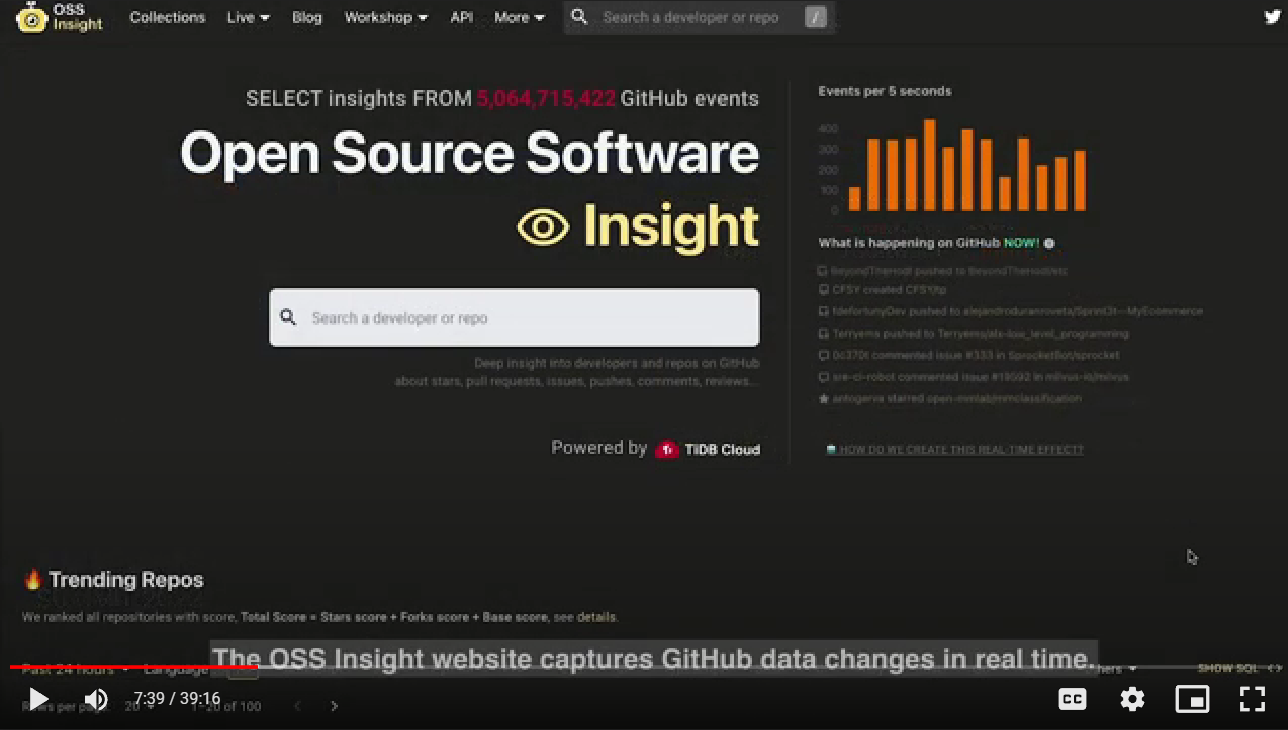
リアルタイムでGitHubの中のデータを分析する「OSS Insight」の紹介
このムービーではGitHub上で実行された50億件以上のプルリクエストやコメント、マージなどのイベントをデータソースとしてリアルタイムに分析を行う様子が紹介されている。
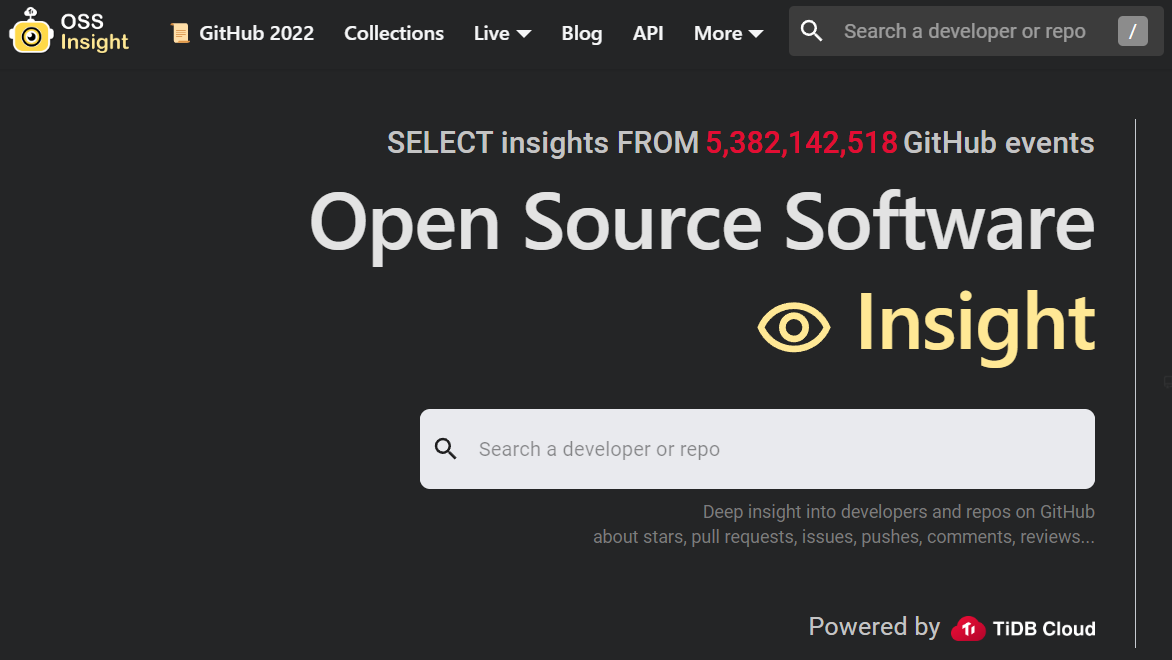
記事執筆時のスクリーンショット。この時点で53億件のイベントを処理している
OSS InsightはGitHubをデータソースとしてリアルタイムで複雑な分析を行うWebサービスだが、このWebサービスの特徴を次の3つのポイントでまとめている。
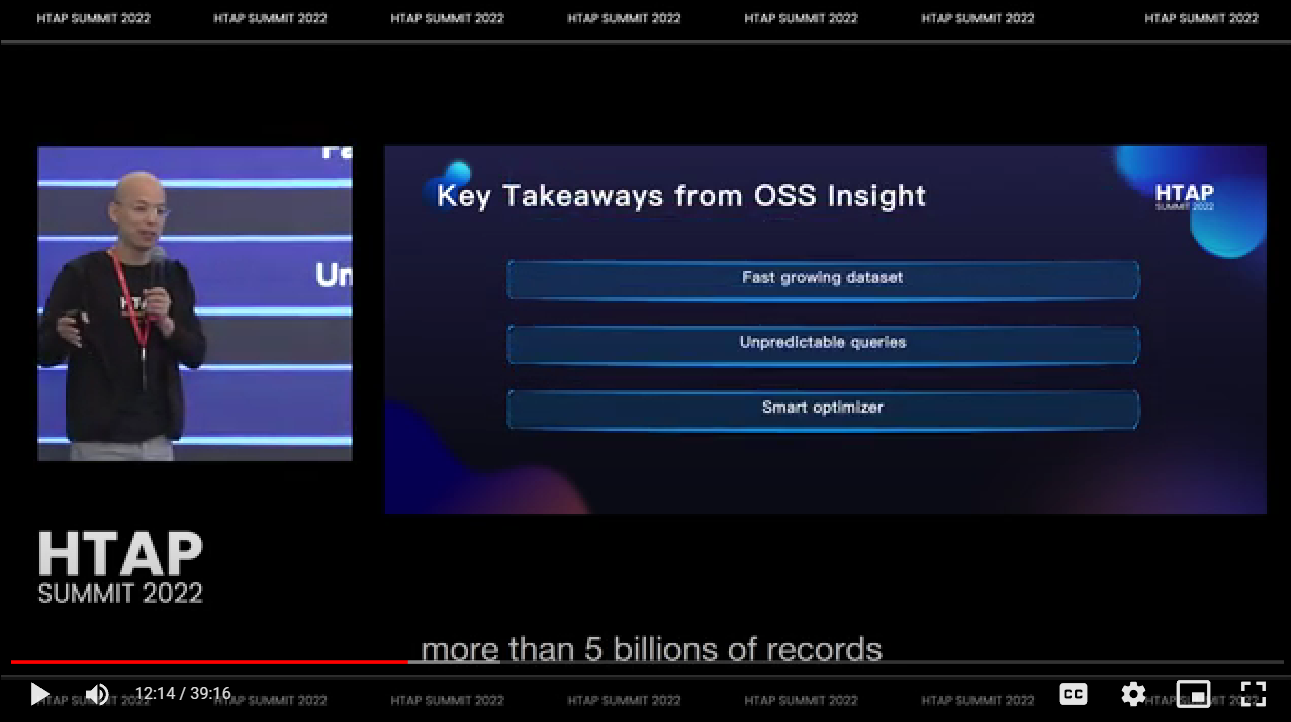
OSS Insightの特徴
ここでは非常に急速に成長しているデータセットであること、様々なユーザーからの多種多様なクエリーリクエストを実行する必要があること、最適化が重要であることなどについて触れた。
次に紹介したのは「KNN3」、Web3と呼ばれるブロックチェーン技術を使った分散金融システムやスマートコントラクトなどの情報を包括するポータルサイトだ。
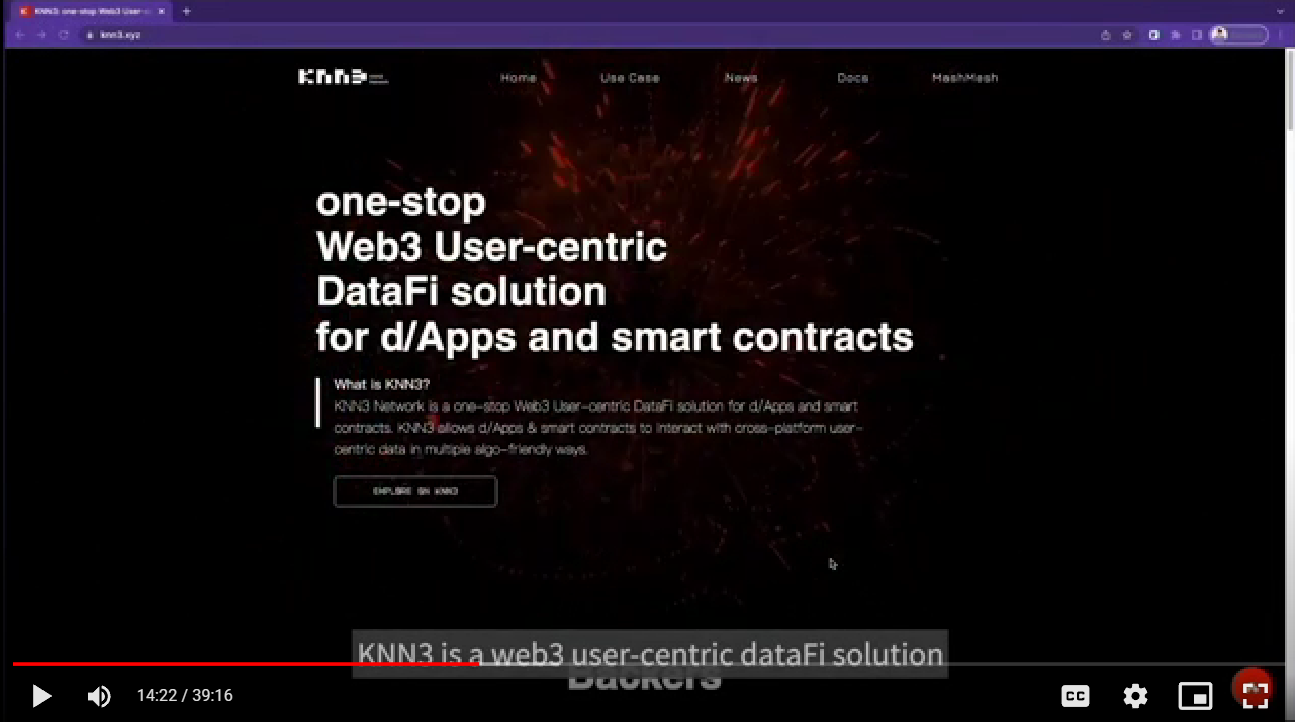
Web3のポータルサイト「KNN3」を紹介
KNN3は、ブロックチェーンを使った分散暗号データを俯瞰するためにリアルタイムの分析機能と、大量データを安全に処理するトランザクション機能が必要になるシステムバックエンドに使われているWebサービスとなる。
Liu氏は「もしもあなたが自社のサービスとしてカスタマー管理のシステムを作るとしたら何が必要だろう? どのようなデータを入力として、どのようなクエリーを行えばカスタマー管理として合格点なのだろうか?」と問いかけた。ここではSalesforceやZendesk、顧客からの電子メールやレガシーなExcelファイルなどをデータソースとして入力に使い、顧客のニーズに合わせて様々なクライテリアで検索や分析機能を実装しなければならないと説明。
このようなシステムを実装するために必要なシステムアーキテクチャーはどのようなものだろう?とLiu氏は参加者に語りかけた。
- この記事のキーワード
この記事をシェアしてください
バックナンバー
この記事の筆者

筆者の人気記事
SASEのCato Networks、CEOによるセミナーとインタビューを紹介
2020年4月16日 6:00
Rustのエコシステムの拡がりを感じるデスクトップアプリのためのツールキットTauriを紹介
2022年12月16日 6:00
Zabbix式オープンソースの秘密に迫る
2025年1月31日 6:00
WebAssemblyとRustが作るサーバーレスの未来
2020年4月21日 6:00
三菱電機が設立したOSPOのメンバーにインタビュー。「インナーソース」を戦略的に使う背景とは?
2025年10月3日 6:00
エンタープライズLinuxを目指すSUSE、Red Hatとの違いを強調
2015年2月3日 19:00
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
