OLAPのための高速カラム指向データベースClickHouseの概要を紹介
OLAPのための高速カラム指向データベースClickHouseを、Aivenのエンジニアが解説した動画を紹介する。
2023年10月18日 6:00
オープンソースのカラム指向データベースClickHouseの概要を複数の動画から紹介する。ClickHouseは、元はロシアの検索エンジン最大手YandexのエンジニアであったAlexey Milovidov氏が2009年ごろから開発を始めたカラム指向データベースであり、2012年にYandexの分析ツールとして初めて本番環境で使われたというのがWikipediaやClickHouseの公式ページなどに掲載されている過去の経緯である。
●参考:ClickHouseのページ:Who we are
この公式ページでは「ロシア」「Yandex」という文字列が注意深く排除されているが、Yandexが起源であることはまちがいない。その後、2021年にClickHouseを法人としてシリコンバレーで起業、現在はオランダのアムステルダムにも拠点を作り、オンプレミスだけではなくクラウドサービスとしてもカラム指向データベースサービスを提供している。
今回は2023年7月5日に公開された「What is ClickHouse?」という動画と、2023年6月にベルリンで開催されたBerlin Buzzwordsというイベントで行われたセッション「ClickHouse: what is behind the fastest columnar database」というセッションからその概要を紹介する。
●動画:https://www.youtube.com/watch?v=FtoWGT7kS-cWhat is ClickHouse?
最初に紹介する7分弱の動画ではClickHouseの概要としてOLAP(OnLine Analytical Processing、オンライン分析処理)のデータベースとしての性能比較、ユースケースの概要、簡単な例を用いてその特徴を解説している。

ClickHouseの概要。OSSであること、カラム指向、分散、OLAPのためのDBであることが特徴
次のスライドではその高速であるという特性についてAWSのインスタンスを使ってGreenplumやElasticsearch、Druid、MySQL、MongoDBなどさまざまなデータベースシステムと比較を行っている。

ベンチマークによる比較を解説。高速であることを強調
ベンチマークは公式サイトで公開されている。
●参考:ClickBench ? a Benchmark For Analytical DBMS
このページではさまざまなデータベースとデータ形式、インスタンスタイプをGUIから選択することで比較が行える。比較したい対象を変えながらその違いを確認できる。このスライドにあるように、ClickHouse(ベアメタルのインスタンス)は同じメモリーサイズのMongoDBのインスタンスと比べて最大2300倍という大きな差が出ていることがわかる。
そして次のスライド以降ではClickHouseのユースケースとしてリアルタイムダッシュボード、リアルタイムアナリティクス、ビジネスインテリジェンス、データウェアハウスの高速化、ログやメトリクス分析、機械学習などが挙げられている。
リアルタイム分析のユースケースとしてDisney+のロゴがある
その中でも注目すべきはDisney+のユースケースだろう。これはDisneyのストリーミングサービスであるDisney+のログのリアルタイム分析という部分にClickHouseが使われているという内容だが、そのDisney+のエンジニアが2022年12月に別のミートアップで解説をした動画が公開されている。
●動画:Disney+のユースケース:Disney+ClickHouse, Disney's Flexible ELT Pipelines in ClickHouse
約17分の動画で、Disney+が動画配信の際に利用する複数のCDNから出力されるログ分析について、ClickHouseを導入した経緯を駆け足で解説している。選択時には他の候補としてHadoopやFlink、Elasticsearchなどの利用を検討したが、最終的にClickHouseを採用したという内容だ。ここではDisney+がClickHouseを採用した大きな理由が、さまざまなフォーマットのログを格納する間口の広さであったことが強調されている。Disney+レベルのサービスともなると、収集されるログは1週間で約400TBにも及ぶという。以下は上記、Disney+のセッションからの引用だ。

Disney+のログ収集分析システムの概要。1週間で約400TB、圧縮して約100TBという規模
元の動画に戻ろう。ClickHouseが高速であるという部分では、GitHubのアクティビティの中から発生したイベント数を集計するSQL文の実行結果を見せて、約50億という数値を出すのに0.002秒しかかからなかったことを見せた。
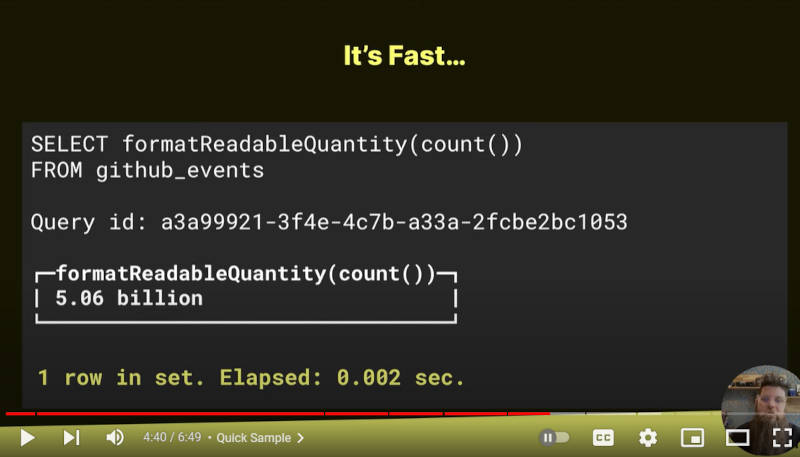
GitHubをサーチして50億のイベント数を集計するのに0.002秒の処理時間
またClickHouseのGitHubにおけるスターの数を年次に集計するSQLにも10万行の処理に0.014秒という結果を示した。
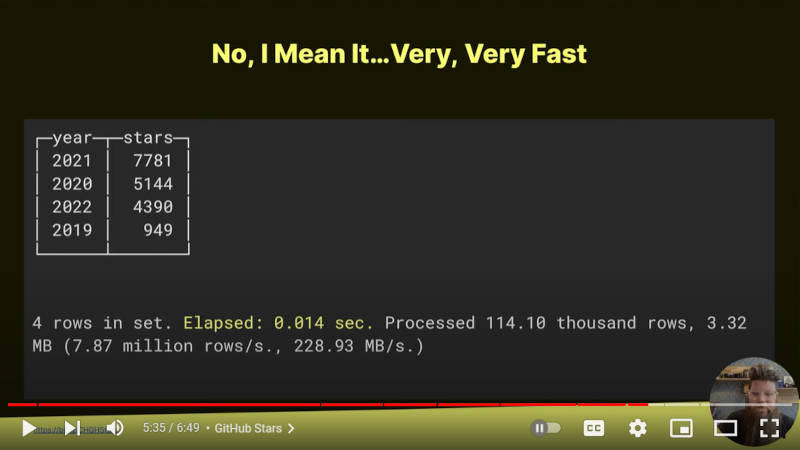
ClickHouseのGitHubページにおけるイベント数を年次に集計
この処理に使われたSQLは以下のスライドで確認できる。
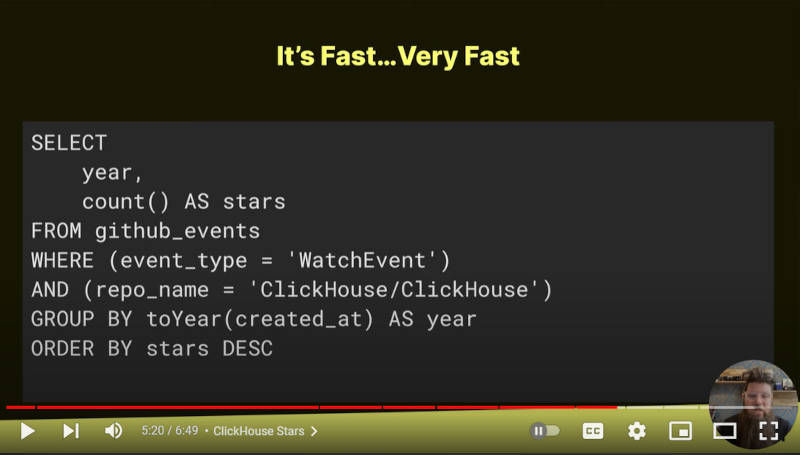
ClickHouseのGitHubにおけるスターの数を集計するSQL
ここからはデータ分析を、パブリッククラウドを活用してサービスとして提供するAivenのエンジニアが解説するBerlin Buzzwordsというイベントでの「ClickHouse: what is behind the fastest columnar database」と題されたセッションから概要を紹介する。プレゼンテーションを行ったのはAivenのOlena Kutsenko氏だ。
●動画:ClickHouse: what is behind the fastest columnar database

プレゼンテーションを行うKutsenko氏
Kutsenko氏はデータベース、データ処理といってもさまざまな種類があること、特にトランザクション処理、ストリーミング処理、データウェアハウス、データレイクなどを例に挙げて解説。
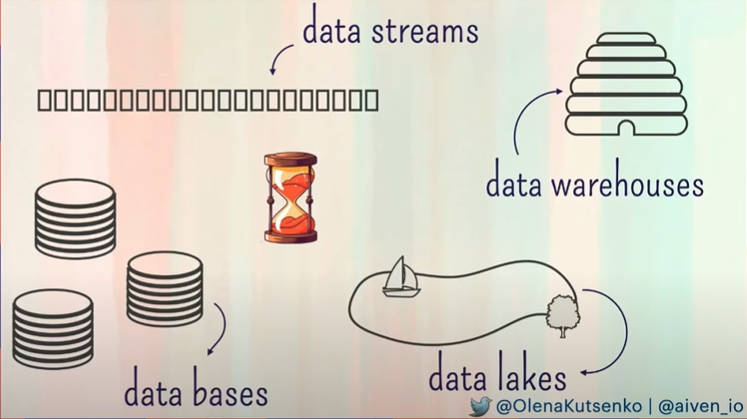
データ処理にさまざまな形態があることを説明
その中でオンライントランザクション(OLTP)とオンラインアナリティクス(OLAP)の違いを詳しく説明した。ここではECサイトでモノを買うというユーザーの行動を確実に処理するのがOLTP、それを分析するのがOLAPという区分けだ。OLTPがデータベースでいうところの行単位の処理に対して、OLAPは分析の特性に合わせてカラムベースの処理が必要になり、OLTPとは性格が違うことを解説した。またトランザクション処理ではRead/Write/Update/Delete機能が必須となるがOLAPでは主にRead処理が実行されるということも強調し、データを効率的に読み込むデータベースが必要だと語った。
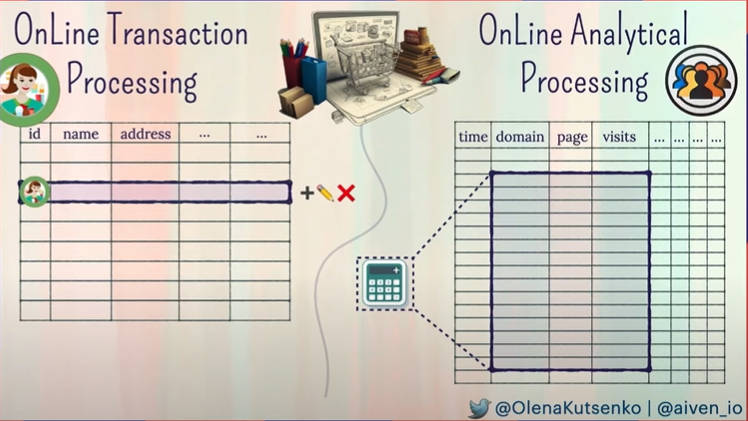
ECサイトを例に挙げてOLTPとOLAPの違いを説明
そしてPostgreSQLとClickHouseの違いというスライドではカラムごとに別のファイルとして格納されるという特性を紹介。
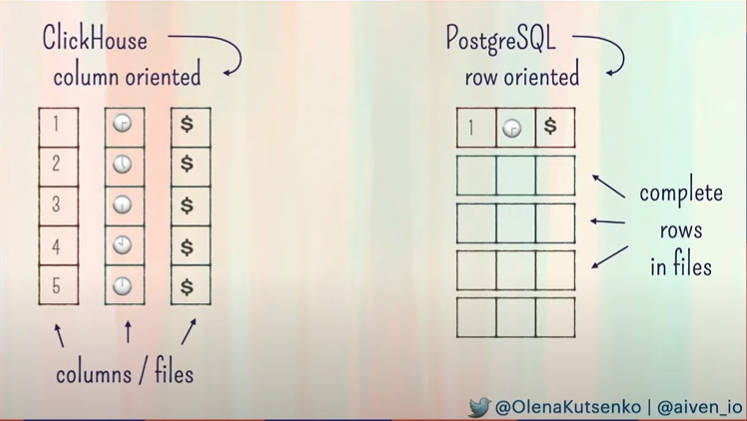
カラムと行の違いをPostgreSQLとClickHouseで比較
ここではカラムごとにさまざまなデータの種類が格納されるデータベースに対し、カラム単位でファイルを分けて格納することの利点を説明した。

ClickHouseの高速性を実現するSparse IndexとSkipping Indexを紹介
ここでは高速にデータの読み込みを行うために分散されたインデックスの概要を説明。Sparse IndexとData Skipping Indexを解説した。Sparse Indexはカラムデータの中の8192行ごとにインデックスを分散させる機能、データスキッピングはSparse Indexを使って高速にインデックスにアクセスする機能だ。
ここからはClickHouseのデモとしてニューヨーク公共図書館に保管されている1800年代から現代までのレストランのメニューから文字列を抜き取ってデータ化したパブリックドメインのデータセットを使って集計の内容を見せた。
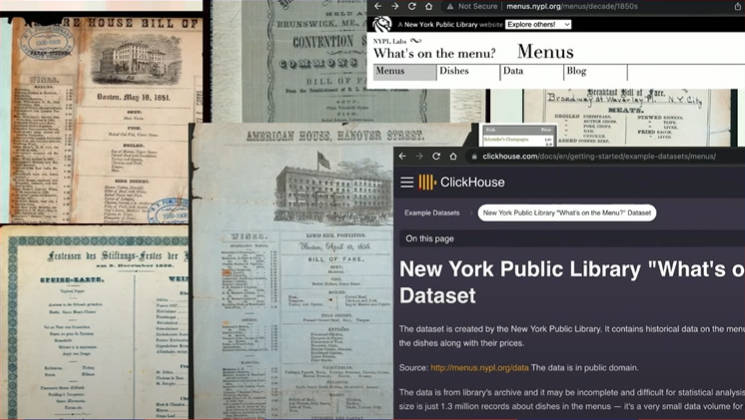
ニューヨーク公共図書館に保存されているメニューからデータ集計を実行
ここで用いられるのは主に文字列からなる130万件のデータセットで、ClickHouseが扱うデータとしては小規模なデータを使ったデモということになる。
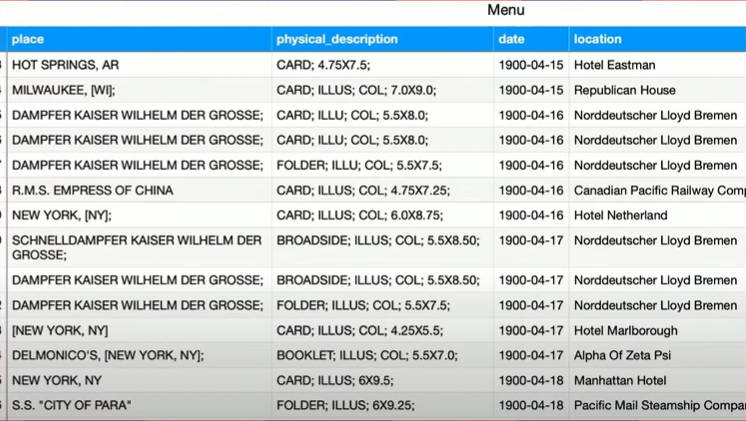
実際のメニューデータの一部、レストラン名、住所などが見て取れる
ここから例として料理の名前に「potatoes」が含まれるデータを1850年に限定して集計するというデモを見せた。
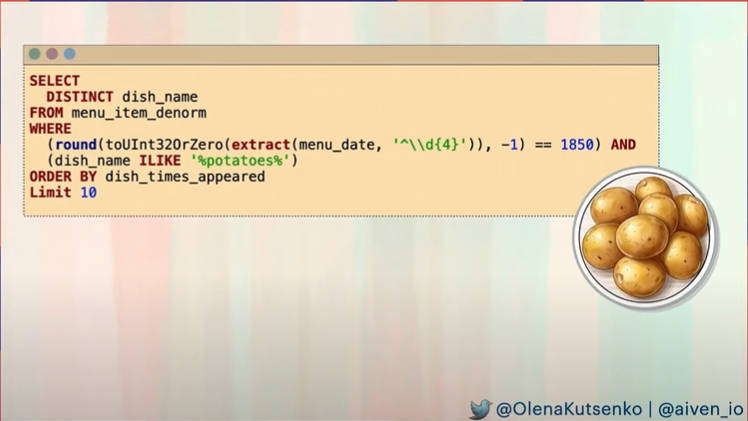
1850年に料理の名前に「potatoes」が含まれるものを集計するSQL
結果は以下のように料理の名前に「potatoes」を含むものが10件ヒットしていることがわかる。
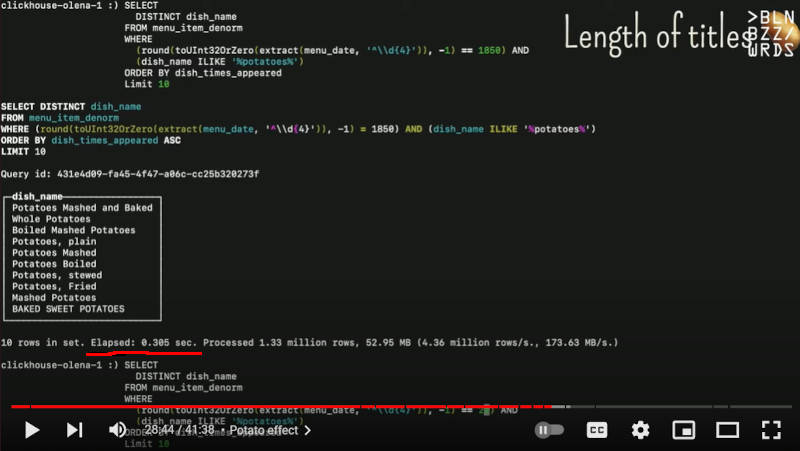
133万件の集計を0.305秒で処理
また年代を1950年から2000年に変更して実行したのが、次のスライドだ。
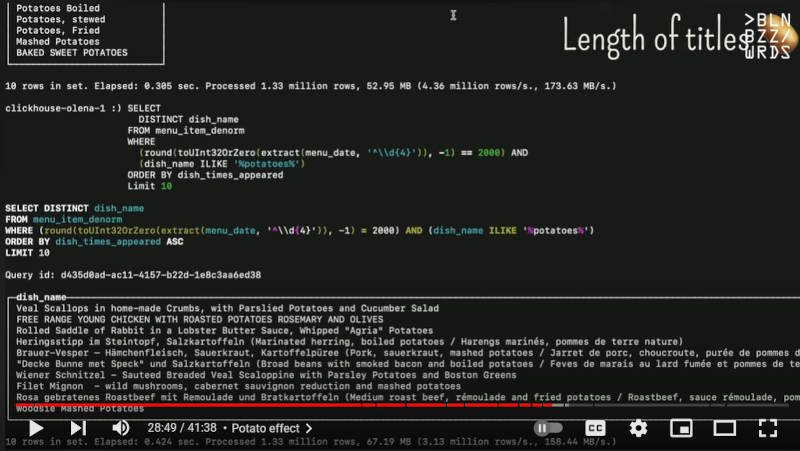
1850年を2000年に変更して集計。料理の名前が長くなっているのがわかる
そして年代ごとに料理の名前の長さの平均を集計したのが次のスライドで解説されている。
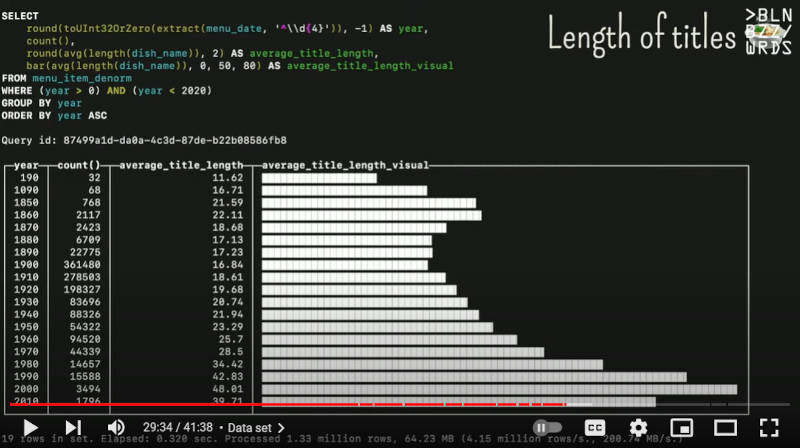
1920年代から徐々に名前の長さが増えていることが可視化されている
デモで使われたメニュー分析デモに関しては以下のリンクを参考にして欲しい。
●参考:New York Public Library "What's on the Menu?" Dataset
この例を示す前に、ClickHouseにおけるテーブルの概要についても解説しており、複数のテーブルがどのように接続されるのかを説明している。ここではテーブルを処理するエンジンがそれぞれ用意されていることに注目したい。
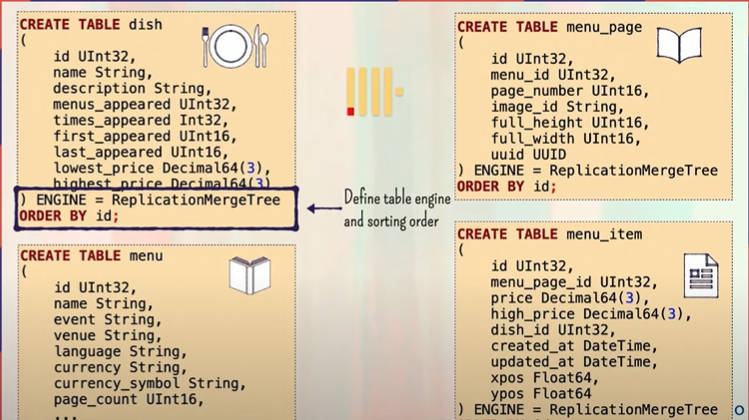
ClickHouseのテーブル定義の例。テーブルエンジンという部分に注目
テーブルエンジンにはさまざまな種類が用意されており、「テーブルをどう接続するのか?」や他のシステムとのインテグレーションの種類などによって選択するというのがポイントだろう。Disney+が多様なログを処理できるという利点に注目したことを思い出して欲しい。

カラム数が増えても性能に影響しない、非正規データは圧縮に適していることを強調
このスライドではカラム数が増えても処理の性能には影響しないこと、そして非正規データ(文字列)は圧縮することが可能という点を強調している。
そして他のシステムとの連携という部分では、Kafkaによるデータストリームからデータを受け取ってClickHouseで処理するための例を紹介。ここではKafka engineの他にKafka Connectというツールがあると説明。
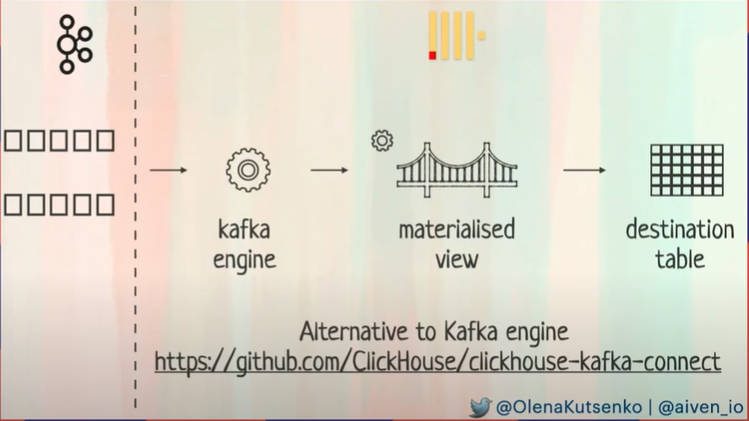
Kafkaとの連携を紹介
他のデータソースとの連携についても説明。
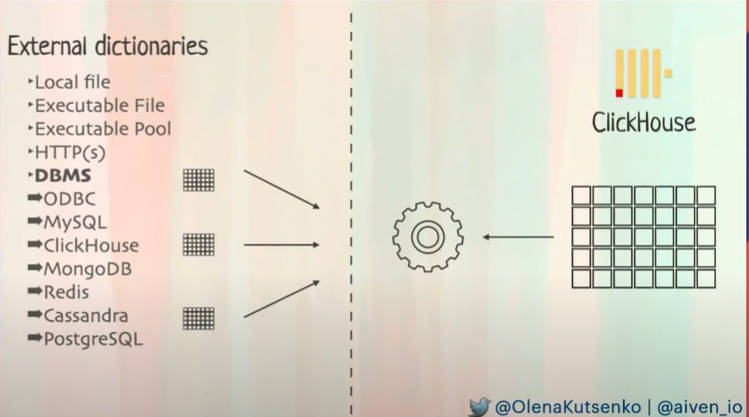
MySQL、MongoDB、Redisなどからのデータ連携を紹介
また、ClickHouseに適さない使い方として、OLTPとして使うこと、キーバリューデータベースとして使うこと、データファイルの保存用、ドキュメントデータベースとしての使用を挙げて説明した。

ClickHouseに向いていない使い方を紹介
PostgreSQLやMySQLのようなトランザクション用DBやMongoDB、RedisなどのNew SQLデータベースとの違いを最後に説明し、今回のプレゼンテーションのベースとなっているGitHubページを紹介してセッションを終えた。このリポジトリはAiven公式とは異なり、Olena Kutsenko氏個人のもののようだ。
●参考:ClickHouse: what is behind the fastest columnar database
Aivenについては、これまでにもいくつかの記事で紹介している。
●参考:Aivenに関する記事:
マルチクラウドのDBaaSを抽象化するAivenの製品担当VPにインタビュー
パブリッククラウドを使ったDBaaSを展開するAivenの日本代表にインタビュー
データベースに特化したサービスプロバイダーで、複数のパブリッククラウドを抽象化してデータベースをサービスとして提供するベンチャーだ。データベースについては極めてプロフェッショナルなエンジニア集団と言える。そのAivenがClickHouseを最大限に評価していることからもClickHouseの良さが伝わってくる。ログの分析に苦労しているインターネット企業は注目しても損はないだろう。これからも注目していきたい。
この記事をシェアしてください
関連記事
Community Over Code Asia 2025、ClickHouseと競合するMySQL互換の分散OLAPベータベースApache Dorisのセッションを紹介
2025年11月18日 5:25
ClickHouseがミートアップ開催。最新情報やPOSデータ分析のユースケースなどを紹介
2025年10月30日 6:00
KubeCon Europe 2023よりGitHubがMySQL互換のVitessを使った事例のセッションを紹介
2023年8月9日 6:00
MySQL互換のTiDBを開発するPingCAP、日本での本格始動を開始
2021年10月14日 6:00
カラム指向DBのClickHouseのCTOにインタビュー、コンピューターとの出会いから生成AIによる未来まで語る(前編)
6月12日 5:59
Cloud Native Wasm Dayから大規模言語モデルをWasmで実行するデモを解説するセッションを紹介
2024年2月8日 6:00
バックナンバー
この記事の筆者

筆者の人気記事
SASEのCato Networks、CEOによるセミナーとインタビューを紹介
2020年4月16日 6:00
Rustのエコシステムの拡がりを感じるデスクトップアプリのためのツールキットTauriを紹介
2022年12月16日 6:00
Zabbix式オープンソースの秘密に迫る
2025年1月31日 6:00
WebAssemblyとRustが作るサーバーレスの未来
2020年4月21日 6:00
三菱電機が設立したOSPOのメンバーにインタビュー。「インナーソース」を戦略的に使う背景とは?
2025年10月3日 6:00
エンタープライズLinuxを目指すSUSE、Red Hatとの違いを強調
2015年2月3日 19:00
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
