詳細な原則
詳細な原則
カオスエンジニアリングの原則 - 詳細な原則では、実験を行う上での理想的な応用方法が記されています。ここでは、具体的な例を取り上げながら詳細な原則を見ていきたいと思います。
詳細な原則には、
- 定常状態における振る舞いの仮説を立てる
- 実世界の事象は多様である
- 本番環境で検証を実行する
- 継続的に実行する検証の自動化
- 影響範囲を局所化する
と記載がありますが、このうち「定常状態における振る舞いの仮説を立てる」「実世界の事象は多様である」に関しては検証プロセスの手順で補足しながら取り上げているため、ここでは残りの3項目を扱います。
本番環境で検証を実行する
本番環境以外で行う実験は、結局のところ何か(データやスケール、環境構成など)が不完全です。そのため、カオスエンジニアリングの原則では本番環境上で直接実験を行うことが強く推奨されています。しかし、後述する通り、戦略的にSandbox環境で試してみることや段階的に適用範囲を拡張するアプローチも取ることができるので、バランスを見ながら取り組む必要があります。
継続的に実行する検証の自動化
手作業による検証は、手間や時間がかかることから長続きしない傾向にあります。そのため、実験のプロセスは可能な限り自動化し、継続して実行することが重要です。また、自動化することで人手を介することによるミスを防止できます。
影響範囲を局所化する
実験を行う際には、失敗した際に影響範囲を局所化することが重要です。これには、実装的なアプローチと戦略的なアプローチが存在します。
実装的なアプローチでは、カスケード障害*1を防ぐような仕組みが必要です。具体的には、適切な時間を設定したタイムアウトやリトライ回数の上限の設定、サーキットブレーカー*2の導入などが考えられます。
*1:局所的に発生した障害がその周辺コンポーネント、もしくはシステム全体まで伝播した障害のこと
*2:大量トラフィックによるサービスダウン防止や障害時の通信を遮断/復旧を制御する仕組みのこと
また、戦略的なアプローチとしては、いきなり本番環境から始めるのではなく、Sandbox環境から試してみることや実験の対象範囲を徐々に広げていくこと、トラフィックの流量が少ない時間を選択して実験を行うことなどが考えられます。
Demo: 初めてのカオスエンジニアリング
発表時は、以下のようなシナリオでカオスエンジニアリングのデモを実施しました。
ブログ(WordPress)を運用していることを想定します。ブログのコンテンツをきちんと見てもらうためには、リクエストの応答時間が重要な指標だと考えました。仮にWordPress(AP サーバー想定)とMySQL(DB サーバー想定)の間のネットワークが遅延した場合、エンドユーザーにはどのような影響があるか? という問いに答えられなかったと想定し、これを実験の題材とします。前述したカオス実験のプロセスに当てはめてみると以下のようになります。
- 定常状態を定義する
- k6というOSSの負荷試験ツールの実行結果に含まれる平均応答時間を定常状態として定義します
- デモ実施時は、数100msオーダーでした
- 仮説を立てる
- WordPressとMySQLの間の通信に1sの遅延を仕込んでも平均応答時間は、3s を超えないはず
- ※今回の 3sという指標は、応答時間が3sを超えるとユーザーの離脱率が大幅に上がることが一般的に知られているので、それを前提とした仮の指標です
- 現実世界のイベントを反映する変数を導入する
- ToxiproxyというTCPレイヤーのプロキシをサーバーの機能を用いて、WordPressとMySQL間に1sの遅延を追加します
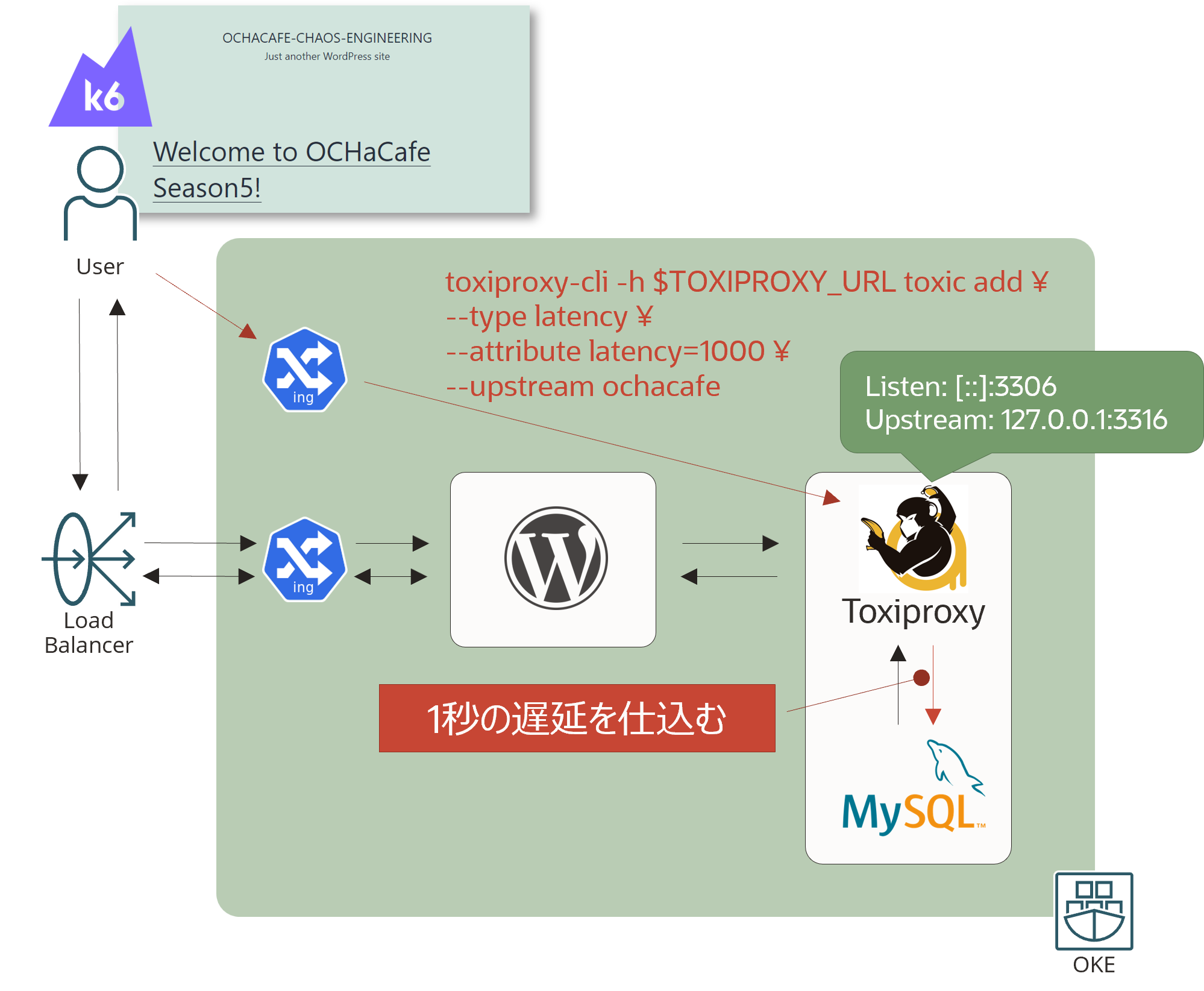
デモでは、実際に1sの遅延を追加した状態で再度k6を用いて、平均応答時間を測定したところ約45sという結果になってしまい、仮説と反することが確認できました。これにより、WordPressとMySQL間の通信で何が行われているのか? を具体的に調査するきっかけとなったり、どの程度の遅延であれば3s以内の平均応答時間となるのか? を遅延を調整しながら確認するアクションに繋げることができます。
発表時のデモは、アーカイブに残していますので、ぜひ参照ください。
ここまでのまとめ
カオスエンジニアリングとは、対象システムの振る舞いを学習するために適切に制御された実験を行い、その結果を観察することで新しい気づきを得ようとするアプローチのことです。Principles Of Chaos Engineeringの初版以降、事例やツールなどが沢山出てきましたが、やはり原則に立ち返ることが重要だと感じています。実験的な意味合いが非常に強いため、その結果を観測するためのObservabilityは欠かせない要素ですし、再現性を高める意味でも実験は極力シンプルになるように心がけることが重要です。
Kubernetes上で稼働するアプリケーションに対する
カオスエンジニアリング
ここまで、カオスエンジニアリングの全体像を説明してきました。以降では、Kubernetes上で稼働するアプリケーションに焦点を当て、そのアプリケーションに対してカオスエンジニアリングを適用する方法について説明します。具体的にはChaos Meshというツールを扱います。
Chaos Meshで考える詳細な原則
今回の詳細な原則では「検証は自動化する」「影響範囲を局所化する」「本番環境で検証を実行する」ことを扱いました。このうち、検証の自動化と影響範囲の局所化について、Chaos Meshは強力な機能を有しています。
検証の自動化については、CIの一貫として組み込んだり、Chaos Meshの持つスケジュール実行機能を活用したり、Chaos Meshのワークフロー実行機能を活用する方法を取ることができます。また、影響範囲の局所化についても、CIの一環として組み込む方法やChaos Meshのセキュリティ機能を活用する方法を取ることができます。
以降で、Chaos Meshについて詳細に紹介します。なお、発表当時のChaos Meshの最新バージョンはv2.2.0でしたが、2023年4月現在の最新バージョンはv2.5.1です。ここでは、本記事執筆時の最新バージョンであるv2.5.1に基づいて説明します。
Chaos Mesh
Chaos Meshは、Cloud Native(Kubernetes)環境用に設計されたカオスエンジニアリングプラットフォームです。2023年4月現在ではv2.5.1が最新版であり、サポート対象のKubernetesのバージョンは1.20〜1.25です。豊富な実験タイプが提供されていたり、ユーザーフレンドリーなUIや専用のCLI(chaosctl)が提供されています。また、前述した通り、検証の自動化をサポートするような機能や安全に実験を行うための機能も兼ね備えています。
Chaos Meshのアーキテクチャ
Chaos Meshのアーキテクチャは、下図のようになっています。

ユーザーが実験を作成し、適用する方法としては専用のWeb UI(Chaos Dashboard)を用いるか、実験の詳細を書いたKubernetes - Manifestをkubectl applyする方法が存在します。Chaos Dashboardで作成した実験をKubernetes - Manifestとして出力することもできるので、Manifest作成の補助に活用したり、トライ&エラーでChaos Dashboardから作成した実験を同じ実験内容で別環境で行う等が可能です。
実験がKubernetes API Serverに提出されると、Chaos Controller ManagerがCustom Resource Definitions(CRDs)として定義されている実験リソースの管理を行います。
最終的に、DaemonSetとして各ノードに配置されているChaos Daemonが対象コンテナに対してイベントを注入することでカオスエンジニアリングを行います。
Chaos Meshのコンポーネント
以降で、Chaos MeshのコンポーネントであるChaos Dashboard、Chaos Controller Manager、Chaos Daemonについて説明します。
Chaos Dashboard
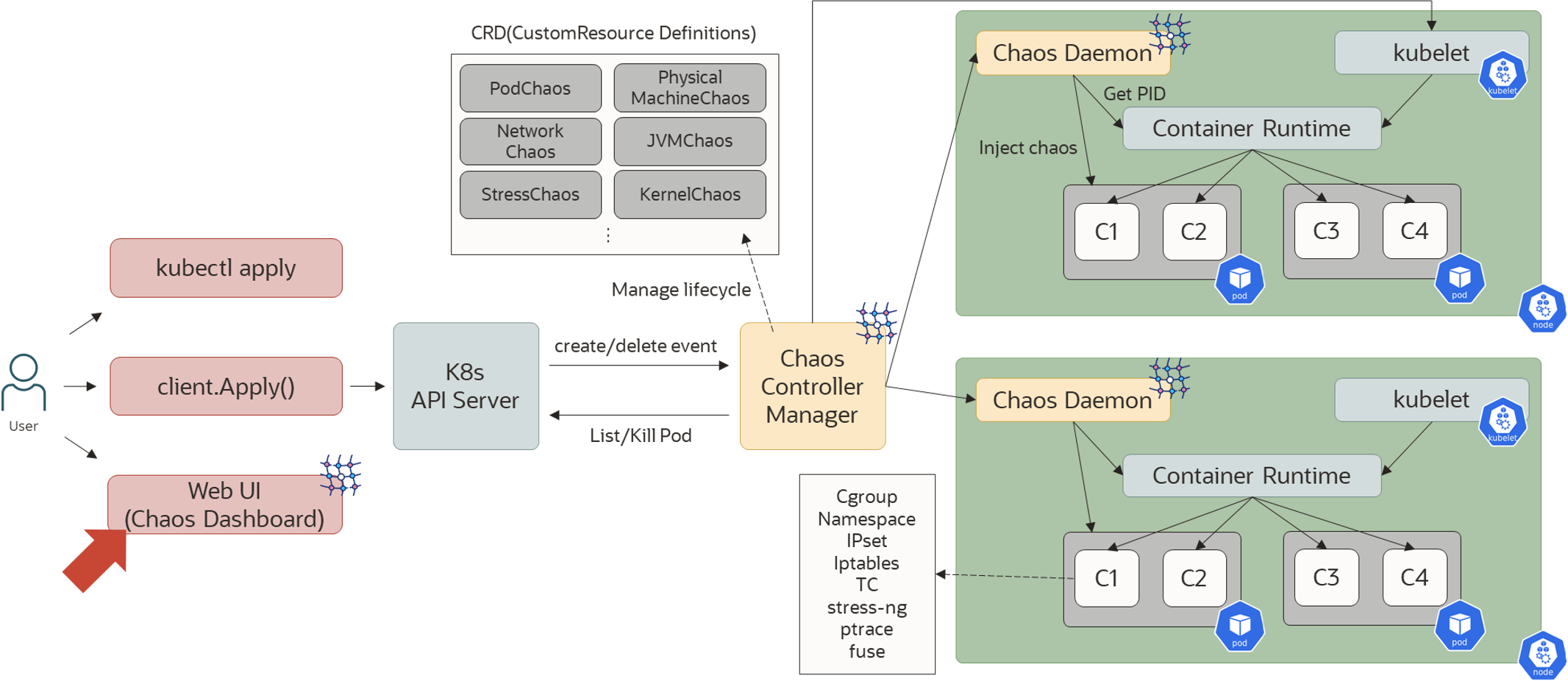
Chaos Dashboardは、ユーザーが実験を作成したり、簡易的に観察するためのWeb UIを提供します。オプションとして、Kubernetesの RBAC機能を用いた権限制御を行うことができます。

実行された実験、スケジュールされている実験、ワークフローとして管理されている実験の総数の確認や時系列として実行された実験の一覧を確認できる様子

Chaos DashboardからRBAC制御に必要なServiceAccount、Role、RoleBindingを生成する様子
Chaos Controller Manager

Chaos Controller ManagerはChaos Meshの中核をなす論理コンポーネントで、主にカオス実験(CRDs)のスケジューリングと管理を担当します。実体は複数のコントローラーの集合体となっています。
Chaos Daemon

実験の実行を担うのがChaos Daemonというコンポーネントです。KubernetesのDaemonSetとして動作するので、各ノードに1つずつPodが存在します。
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
10.0.10.129 Ready node 4h17m v1.22.5
10.0.10.35 Ready node 4h59m v1.22.5
10.0.10.72 Ready node 5h11m v1.22.5
$ kubectl -n chaos-testing get daemonsets.app chaos-daemon
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
chaos-daemon 3 3 3 3 3 <none> 6d8h
$ kubectl -n chaos-testing get po -o wide | grep -i chaos-daemon
chaos-daemon-45pdc 1/1 Running 0 5h3m 10.244.3.131 10.0.10.35 <none> <none>
chaos-daemon-d25kp 1/1 Running 0 5h15m 10.244.3.11 10.0.10.72 <none> <none>
chaos-daemon-lsfwp 1/1 Running 0 4h21m 10.244.4.3 10.0.10.129 <none> <none>
デフォルトでPrivileged権限を持つPodで、このPodがターゲットとなるPodのNamespaceにハッキングすることでネットワークデバイスやファイルシステム、カーネルに干渉し、イベントを注入します。
- この記事のキーワード
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
