Oracle Cloud Hangout Cafe Season5 #5「実験! カオスエンジニアリング」(2022年5月11日開催)
連載第5回の今回は、2022年5月11日に開催された「Oracle Cloud Hangout Cafe Season5 #5『実験! カオスエンジニアリング』」の発表内容に基づいて紹介していきます。
2023年5月18日 6:30
はじめに
「Oracle Cloud Hangout Cafe」(通称「おちゃかふぇ」/以降、OCHaCafe)は、日本オラクルが主催するコミュニティの1つです。定期的に、開発者・エンジニアに向けたクラウドネイティブな時代に身につけておくべきテクノロジーを深堀する勉強会を開催しています。
連載第5回の今回は、2022年5月11日に開催された「Oracle Cloud Hangout Cafe Season5 #5『実験! カオスエンジニアリング』」の発表内容に基づいて紹介していきます。アジェンダ
今回は、以下アジェンダの流れに従って解説します。
- カオスエンジニアリングとは?
- Kubernetes上で稼働するアプリケーションに対するカオスエンジニアリング
- カオスエンジニアリングをサポートするツール群
発表資料と動画については、下記のリンクを参照してください。
【資料リンク】
【動画リンク】
カオスエンジニアリングとは?
カオスエンジニアリング…?
カオスエンジニアリングと聞くと、「本番環境のコンポーネントを“ランダム”に壊し、信頼性を高める手法である」や「分散システム(マイクロサービス)にのみ適用されるソフトウェアテスト手法である」と思われる方がいるかもしれません。ここでは、これらがカオスエンジニアリングの一部の側面でしかないことを理解し、カオスエンジニアリングとは何なのか? 実施した上で何が得られるのか? 適用する上で何が大切なのか? ということを整理します。
Principles Of Chaos Engineering
Principles Of Chaos Engineeringという、カオスエンジニアリングのコアになる考えを記したドキュメントがあります。発足当時に比べるとツールや事例が充実してきましたが、Principles Of Chaos Engineeringに則ったものばかりのため、基本に立ち返ることは重要です。Principles Of Chaos Engineeringは、以下のような構成となっています。
- 序文
- カオスエンジニアリングを行うモチベーション
- カオスエンジニアリングの定義
- 検証におけるカオス
- 検証プロセス(=カオス実験)の手順
- 詳細な原則
- 検証プロセスの理想的な応用方法
以降では、Principles Of Chaos Engineeringに記載のある原理・原則を分かりやすく理解するために、実例などを交えながら解説します。
あらためて、カオスエンジニアリングとは?
Principles Of Chaos Engineeringの序文に書かれている定義を整理すると、「対象システムの振舞いを理解するため適切に制御された実験を行い、その結果を観察することで新しい気づきを得ようとするアプローチのこと」と表現できます。ここでのポイントは、以下の2点です。
- 実験という手法を用いること、かつその実験は適切に制御されていること
- 新しい気づきを得ようとするアプローチであること
つまり、カオスエンジニアリングの目的は、実験を通して、下図のUnknownをKnownに変えるためのアプローチと言い換えることができます。

実験とテスト
カオスエンジニアリングは、実験という手法を用いてUnknownをKnownに変えるアプローチであると述べました。似たような言葉にテストという言葉があります。これらの違いを理解すると、カオスエンジニアリングのイメージが掴みやすいため、ここでは両者の言葉の定義を復習します。
実験とは「構築された仮説や、既存の理論が実際に当てはまるかどうかを確認することや、既存の理論からは予測が困難な対象について、さまざまな条件の下で様々な測定を行うことであり、知識を得るための手法の1つ。」です。つまり、結果の分からない事象に対して、様々な測定を通して理解を深めることと言うことができ、これはカオスエンジニアリングの定義とよく似ています。実際、LitmusChaosのように実験をモチーフとしたカオスエンジニアリングのツールも存在します。
一方、テストとは「被験者または試料の能力や性質を測定するために行う行為のこと」です。つまり、あらかじめ結果が分かっている事象に対して、そのような結果になることを確認すると言うことができます。
両者の違いは、学生時代の理科の実験と中間、期末テストを思い返すとさらにイメージしやすいかと思います。
カオスエンジニアリングを行うモチベーション
カオスエンジニアリングを行うモチベーションは、大きく2つあります。
1つ目は、システムの運用に自信を持つことです。例えば、特定の事象が発生しても、エンドユーザーには大きな影響がないことをあらかじめ実験を行い確認することで自信を持つことや、詳細が不明なレガシーシステムの運用担当者となってしまったので、実験を通して振舞いを理解することで自信を持ちたいなどです。
2つ目は、今まで意識することもできなかった問題を実験を通して発見することです。これは、実験を通して判明した事象に対して具体的な調査を行うことができたり、多少の犠牲を払って、より大きな問題となる前に発見するといった意味があります。
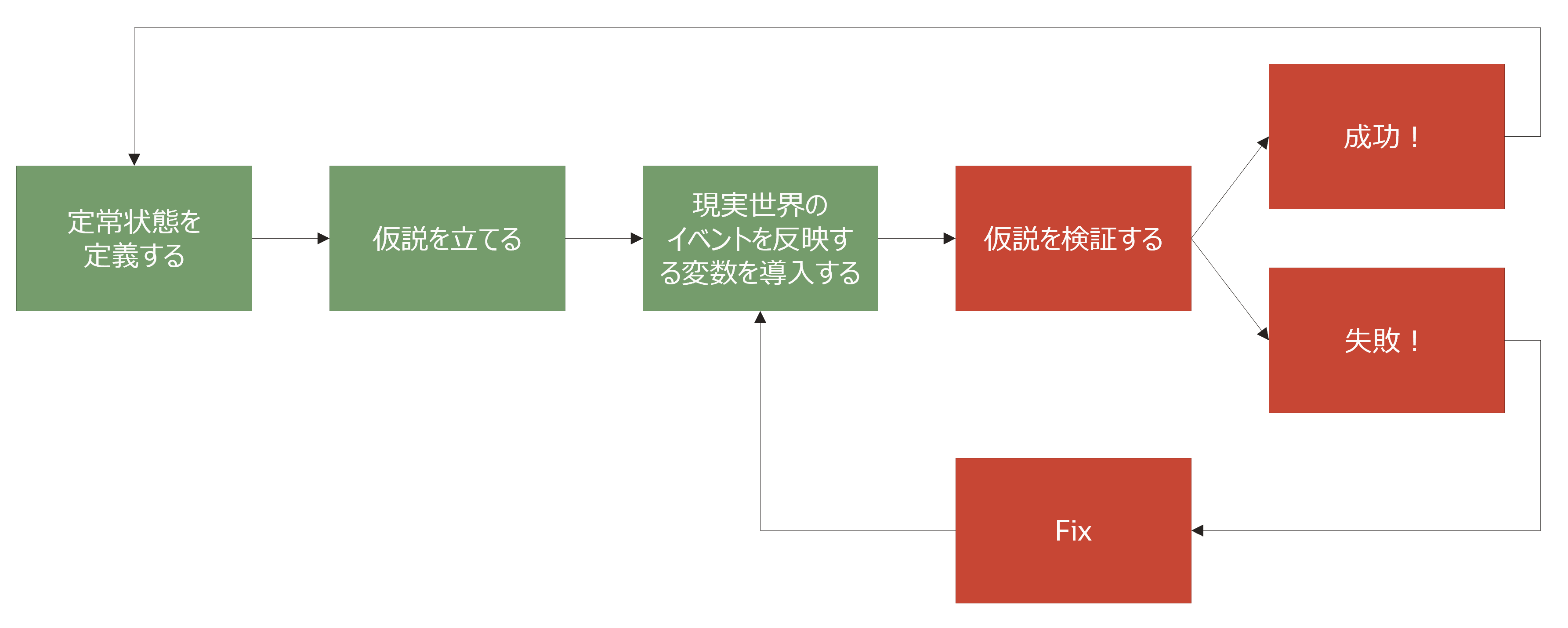
検証プロセスの手順
ここでは、検証プロセス(以降、カオス実験と呼ぶ)を具体的に見ていきます。下図がカオス実験の手順です。
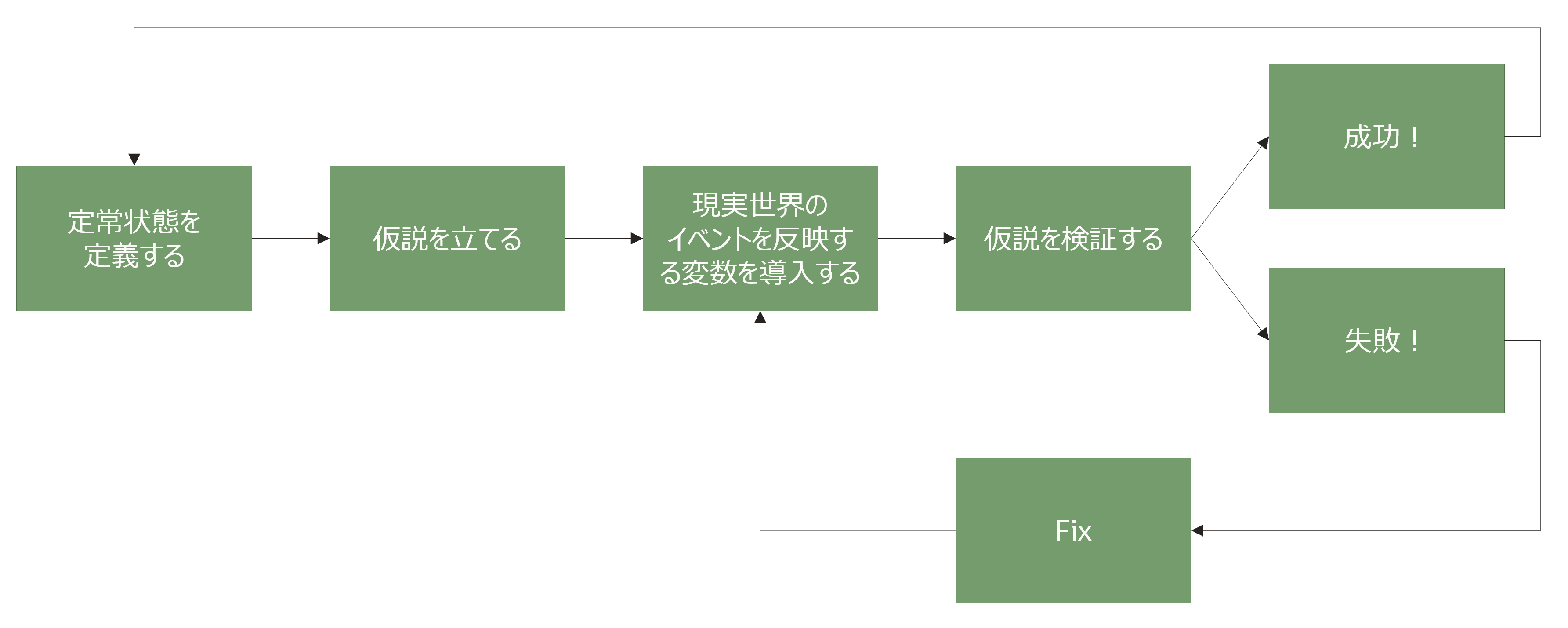
大きく、4ステップで構成されています。
- 定常状態を定義する
- 仮説を立てる
- 現実世界のイベントを反映する変数を導入する
- 仮説を検証する
以降で、順番に見ていきます。
1. 定常状態の定義
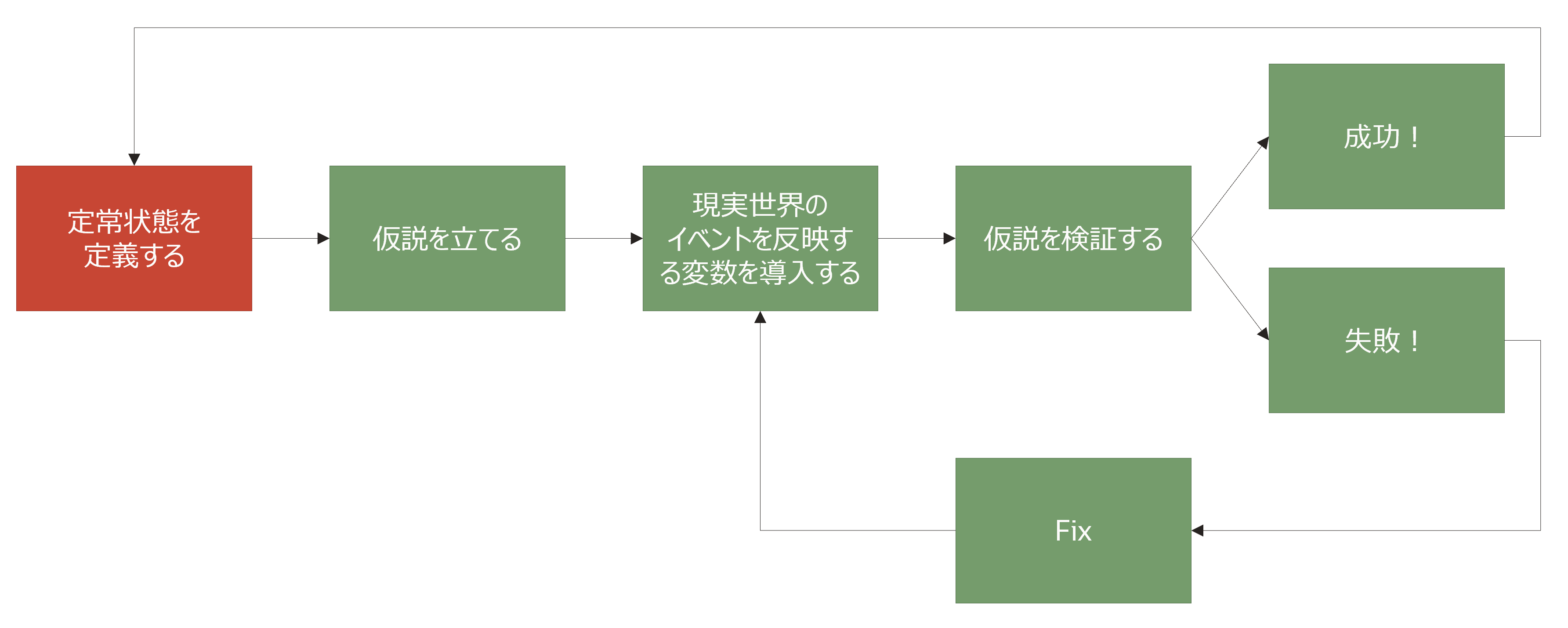
まずは、定常状態を定義します。定常状態の定義もいくつかの手順があります。
最初に、計画を立てます。無計画に実験を始めるのではなく、ビジネス/サービスの発展に影響がありそうなことや安定稼働に影響がありそうなことに基づき、どのようなデータを取得する必要があるのかを計画します。例えば、自分がECサイトの運用者である場合、ユーザーを離脱させずに自サイトで購入してもらうことを考えると、リクエストの応答時間は良い題材と言えるでしょう。また、この段階で実験が複雑になりすぎないように注意する必要もあります。当たり前ですが、実験はシンプルなほど再現や自動化が容易です。
計画を立てたら、データを取得するための可観測性を確保します。このとき、システムの内部属性ではなく、測定可能な出力に焦点を当てることが重要です。具体的には、システム全体のスループットやCPU/メモリの使用率等が候補となります。こちらも、初めのうちはあまり大掛かりな監視システムを構築しようと考えずに、簡単に取得できるものが望ましいです。
最後に、定常状態を定義します。実験を行った結果発生した事象が予想の範囲内/外であることを直観的に理解するためには、正常な状態(=定常状態)の定義が必要です。例えば「1 リクエストの平均応答時間は100ms以内である」や「app=hogeとラベルの付いた全てのPodが安定稼働している」などです。
これまでのプロセスを図示すると、以下のようになります。

これを読んでいただければ分かる通り、カオスエンジニアリングと可観測性(Observability)は切っても切り離せない関係となっています。OCHaCafe Season4 #6 - Observability 再入門では、Observabilityの基本からCloud NativeなObservabilityを実現するツール群まで扱っていますので、こちらも併せてご参照ください。
2. 仮説を立てる
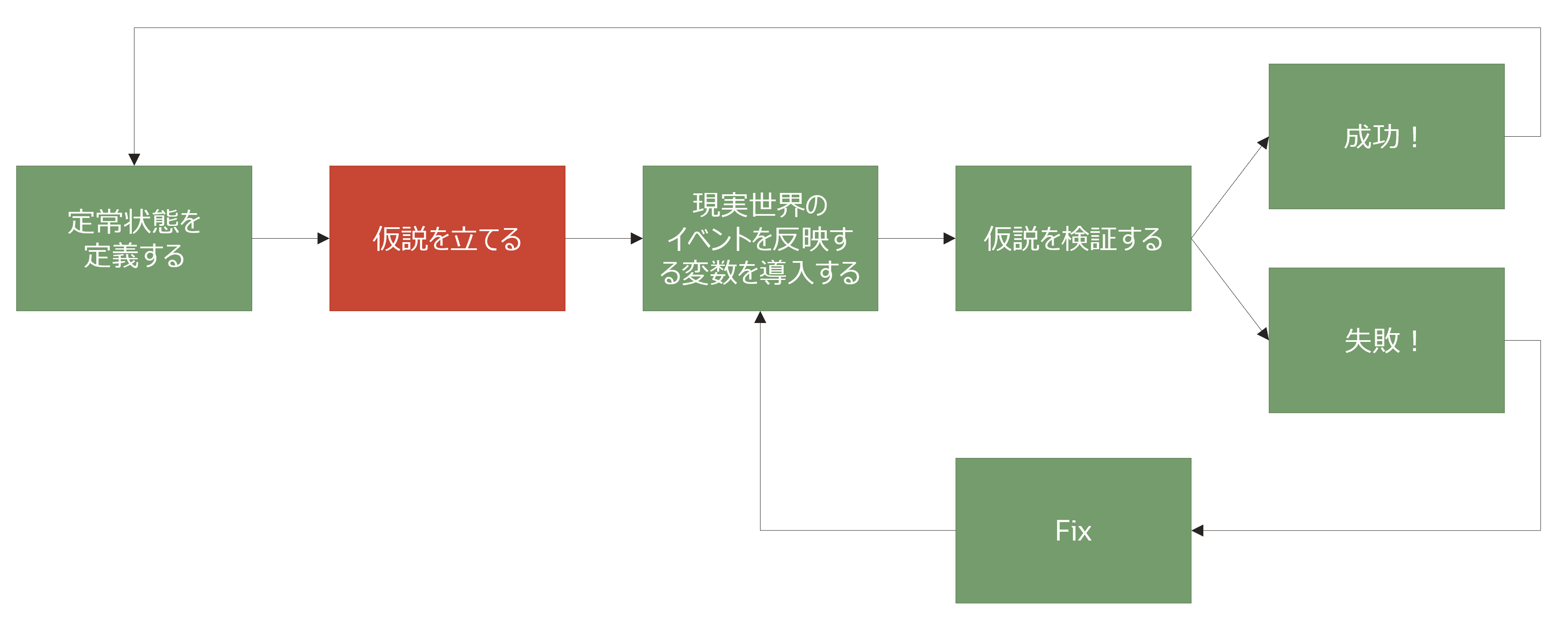
実際に収集した信頼できるデータや過去の経験をもとに直観的に判断できる仮説を立てます。例えば「定常状態における1リクエストの平均応答時間は、50msなので、AP-DBサーバ間に1sの遅延を追加しても平均応答時間は、2.5sを超えないだろう」や「今まで数年間安定稼働している実績があるので、app=hogeのラベルが付いたPodの50%がダウンしても業務は続行可能だろう」などです。この仮説における数値は、1回決めたら終わりではなく、実験のサイクルを回していく中で適切に調整していく必要があります。また、この仮説を立てる際には、以下のようなイベントが発生したらシステムがどのように振舞うか? を問いてみると良いです。その問いに答えられないのであれば、実験に取り組む価値があると言えるでしょう。
仮説を立てる際に役に立つイベントの一例:天災系のイベント(地震、洪水、火災、停電、etc.)、ハードウェアの障害、リソース不足、人為的なエラー、トラフィックの遅延/増加、etc.
3. 現実世界のイベントを反映する変数を導入する
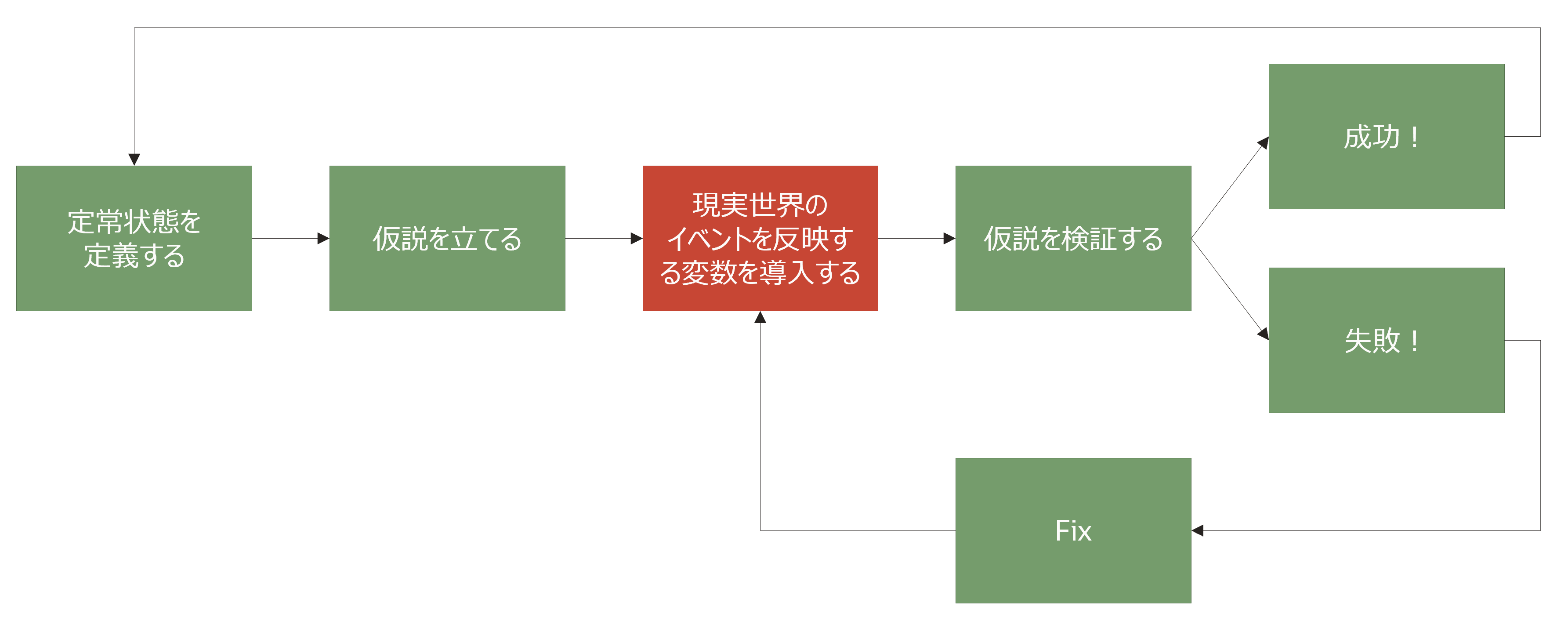
仮説に基づき、実験を行うための変数をシステムに導入します。このときの導入ポイントや方法は様々存在します。
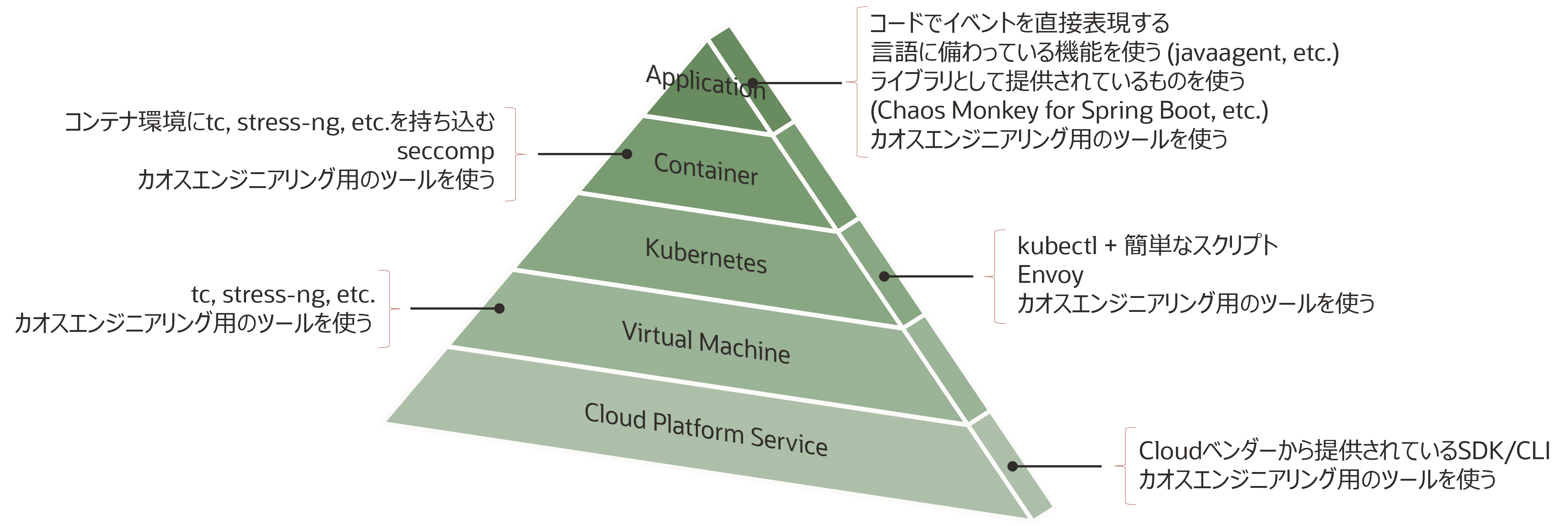
上図の導入ポイントを大きく2分すると、アプリケーションのレイヤーとインフラストラクチャのレイヤーで分けることができます。それぞれのメリット/デメリットを簡単にまとめたので、検討の材料としてご活用ください。
| Layer | Pros | Cons |
|---|---|---|
| Application | ・イベントの表現がコードレベルで柔軟にできる ・特別なツールの準備や事前の学習コストが不要 | (複雑な依存関係を持つ)大規模なアプリケーションには不向き |
| Infrastructure (Container/K8s/VM/Platform) | ・エコシステムが充実している (監視ツールとの連携のしやすさ、etc.) ・影響範囲が(コードで表現するよりも) 限定しやすい | ツールの習熟やセットアップには時間がかかる |
また、この選択に答えはないため、何を優先するか? を考慮し、適材適所で選択することが重要かと思います。
4. 仮説を検証する
実験を行った結果を観測し、仮説を検証します。仮説が正しかった場合、そのシナリオに対する自信をつけることができます。一方、仮説が誤っていた場合には「予想しえない事象が発生することを知ることができた」「問題を改善するために具体的な調査を行うことができる」「実験の条件を変えることでより詳細な情報を得ることができる」などの結果が得られます。
- この記事のキーワード
この記事をシェアしてください
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
