CNDT 2022、ChatworkのSREがSLO策定にカオスエンジニアリングを使った経験を解説
CNDT 2022、ChatworkのSREがカオスエンジニアリングを応用してSLOの作成に役立てたセッションを紹介する。
2023年5月29日 12:37
CNDT 2022から、ChatworkのSREがSLO(Service Level Objective)策定の経験を語るセッションを紹介する。プレゼンターはSRE部の佐々木真也氏、タイトルは「SLO策定までの道とChaos Engineeringを使った最適解の見つけ方」と題されている。

セッションを行う佐々木氏
●動画:SLO策定までの道とChaos Engineeringを使った最適解の見つけ方
元々ChatworkにおいてSRE部はSLO/SLIの担当ではなかったが、前任者である副本部長から引き継いだという背景を説明し、SLO/SLIについては定義されドキュメント化もされてはいたものの、佐々木氏自身も知ってはいたが具体的な数値などについては把握してはいなかったと語った。そして四半期ごとのレビューも実施されてはいたものの、存在を知らない人が多かったことを解説した。

知らない人が多かったという当時の状態を説明
このため、定義はできてはいるが運用されていないという状態を改善しようというのが、引き継いだ時の課題ということになったと思われる。その運用の理想として一般論としては開発者がSLO/SLIを意識して信頼性についての指針としていること、違反ポリシーや変更プロセス、コンセンサスなどについて説明を行った。

一般的なSLO/SLI運用の理想
ただ現状のまま運用をしても納得が得られないという想定から、納得を得るための段階的なフェーズを定義して、まずはプロダクトチーム全体でSLO/SLIの運用をゴールとして活動が始まったことを説明した。

SLO/SLI運用の段階的な進め方の説明
そして現行のSLO/SLIは可用性とレイテンシーについてのみ定義されていたとしてその例を紹介した。

可用性とレイテンシーのSLO/SLIの例。30日という期間が対象
周知を拡大というフェーズにおいてはレスポンスが悪くなったという状態がアラートとして挙がったとしても、その責任がどのチームにあるのかが不明確であるならば、対応も難しくなるという想定から、単にシステムの性能劣化ではなく「ユーザーがどういうことを行った時に性能が劣化したのか?」を明らかにするためにCUJ(Critical User Journey)ごとにSLOを定義するという方法を採用したと説明した。

より具体的なCUJごとにSLOを設定
これによってどのグループが担当している動作/パスにどういう可用性劣化やレイテンシー劣化が発生しているのかを細かく設定することで、責任担当を明確にしたという。
また例えばレイテンシーについてはこれまでのシステムの平均的なレイテンシーから設定した値が本当に妥当なものなのか? についても、納得させるためにはシミュレーションを行って体験してもらうしかないということが、後述のカオスエンジニアリングを使う背景となっていることを説明した。

SLOを体験するためには実際にシミュレーションすることが必要
ここからChatworkにおけるカオスエンジニアリングの内容に入っていくが、まずはカオスエンジニアリングの概要を紹介した。

カオスエンジニアリングの概要を紹介
ソフトウェアはCNCFでホスティングされているChaos Meshを採用している。採用の理由として使いやすさや、Kubernetes用にデザインされているため、Chatworkが利用しているAWS上のマネージドKubernetesサービスであるEKSとの親和性が良いことなどを挙げた。

Chaos Meshの紹介
Chaos Meshのアーキテクチャーについても簡単に紹介し、ダッシュボードやKubernetesに特化していることなどを紹介した。

Chaos Meshはコマンドライン(kubectl)から使えるのがポイント
特に値を変えて繰り返し実行を行うような場合にはGUIよりもコマンドラインからの操作がやりやすかったとして、実際に操作を行ったエンジニアらしい感想を述べた。またAWS/EKSにおいてもマネージドサービスとしてChaos Meshが利用可能であることも簡単に紹介。ここではAWSユーザー限定になってしまうことにも言及しているのがポイントだ。
ここからは実際に実験を行った環境について解説を行った。

レイテンシーの実験の概要。2つのグループに分け片方にレイテンシーを追加
このスライドでは、アクセスされるサイトのパスによってレイテンシーを追加する設定を行ってシミュレーションを実施したことを説明した。実際に監視ツールであるDatadogで実行結果を確認するという内容だ。
ただHTTPアクセスに対するカオスエンジニアリングという目的については、Chaos Meshが用意しているNetworkChaosという種類のアタックでも良かったのでは? という問いには、多くのコンポーネントに影響を与えるため指定したレイテンシーよりも大きくなりがちでコントロールが難しかったと説明。単にシステムに対して負荷をかけると目的ではなく、ユーザーが体験する遅さをSLOの値として検証するという目的には合わなかったということだろう。
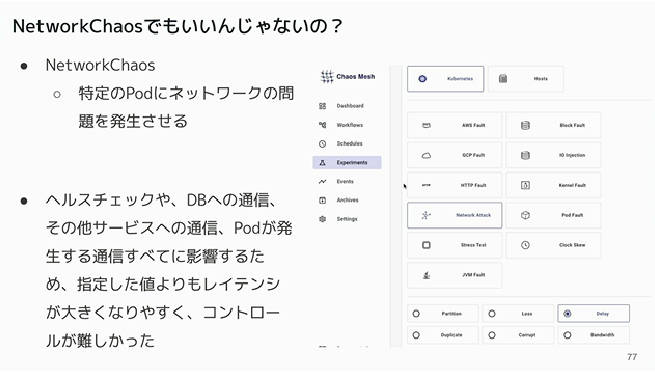
NetworkChaosを使わなかった理由を説明
またHTTPアクセスを振り分けるという目的には、ロードバランサーで行うのではなくChaos Meshの機能を使うという選択肢もあったが、同じ対象に2つの実験を設定すると応答がなくなるという不具合に遭遇したため、選択しなかったことを説明した。本来の目的はシミュレーションを実施することであり、Chaos Meshのデバッグではないということだ。
また可用性についても実験を行っており、99.9%の可用性、つまり1000回に1回はHTTPのエラーコード500のエラーが返るという部分においても行っているが、発生頻度が低すぎてシミュレーションにならないということから85%、つまり1000回に15回エラーが返るという設定について説明を行った。

可用性の実験では15%のエラーを設定して実施
可用性に関しては「どの期間内で何回エラーが起きるか?」をエラーバジェットとして設定し、そのエラーバジェットを消費するレートをバーンレートと呼ぶことについても解説を行った。
最後にまとめとして、SLO/SLIを社内に浸透させるためにシミュレーションを行ったこと、シミュレーションとしてのカオスエンジニアリングを使ったことなどを解説してセッションを終えた。実験としては不具合に遭遇しながらも、シミュレーションという目的にはChaos Meshが充分に使えるものであることを解説したセッションとなった。
- この記事のキーワード
この記事をシェアしてください
バックナンバー
この記事の筆者

筆者の人気記事
SASEのCato Networks、CEOによるセミナーとインタビューを紹介
2020年4月16日 6:00
Rustのエコシステムの拡がりを感じるデスクトップアプリのためのツールキットTauriを紹介
2022年12月16日 6:00
Zabbix式オープンソースの秘密に迫る
2025年1月31日 6:00
WebAssemblyとRustが作るサーバーレスの未来
2020年4月21日 6:00
三菱電機が設立したOSPOのメンバーにインタビュー。「インナーソース」を戦略的に使う背景とは?
2025年10月3日 6:00
エンタープライズLinuxを目指すSUSE、Red Hatとの違いを強調
2015年2月3日 19:00
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
