SODA Data Vision 2023からKubernetes上のアプリケーションデータを保護するKanisterを紹介
Open Source Summit Europe 2023の併設イベントであるSODA Data Vision 2023から、Kanisterを解説したセッションを紹介する。
2023年12月14日 6:00
SODA FoundationがOpen Source Summit Europe 2023の併設イベントとして開催したSODA Data Vision2023から、Kubernetes上のアプリケーションのデータ保護を、カスタムリソースを使ってKubernetesスタイルで実行するオープンソースソフトウェアKanisterを紹介する。約25分のセッションの後半をデモに使って実際にその動作を解説したのは、Veeam SoftwareのField CTO、Michael Cade氏だ。
●動画:Application Level Data Operations on Kubernetes

Kubernetes上のアプリケーションのデータ保護を行うKanisterを説明するCade氏
Cade氏はKubernetesの上で実行されるアプリケーションがステートレスなものからステートフルなものの増加が見られるとしてKubernetesのバージョンを示しながら、追加された機能を紹介した。ここではPersistentVolume、StatefulSetなどの名称が書かれている。Kubernetesの初期の段階ではステートレスなアプリケーションが多かったというよりもステートフルなアプリケーションの実行が想定されておらず、徐々にステートフルなワークロードに対応した機能が増えていったということだろう。
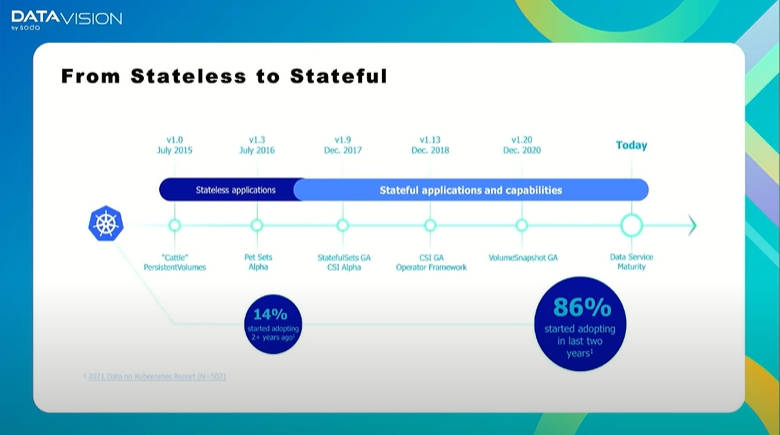
Kubernetesの成熟に合わせてステートフルなアプリのサポートが充実
またDatadogが2022年に行ったリサーチから、コンテナ上で実行されるアプリケーションの種類を紹介。ここではElasticsearchやPostgreSQLなどのオープンソースソフトウェアが多く実行されていると紹介し、Kubernetesで実行されるアプリケーションの増加をデータ保護に対するニーズの背景として解説している。
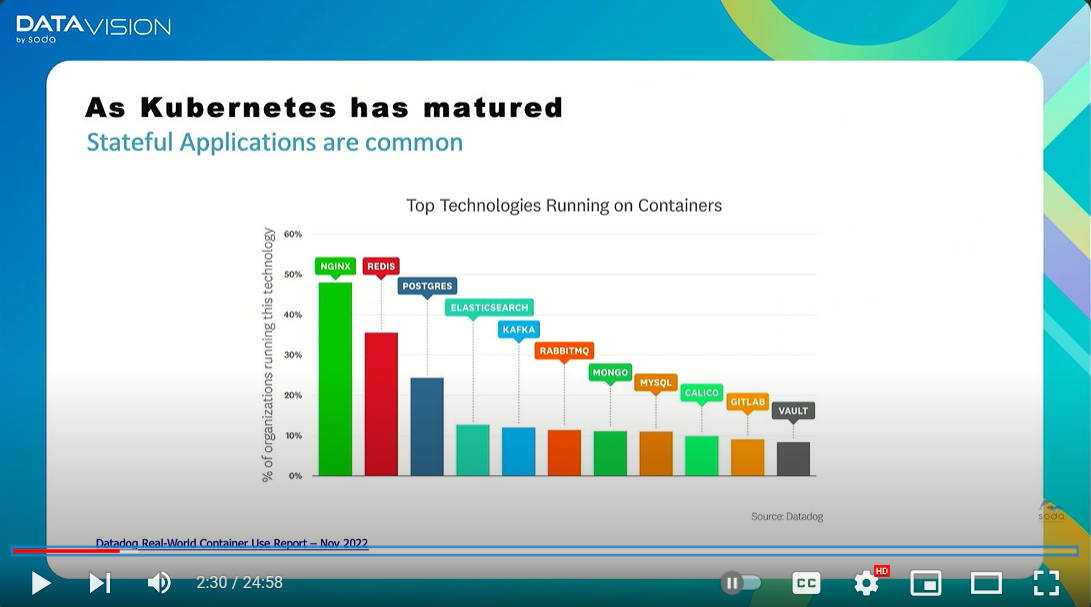
Datadogのリサーチから。ステートフルなアプリケーションがコンテナで実行されている
そうなれば当然、アプリケーションの保護について多くの要因が想定されることを次のスライドで解説した。ここではクラッシュした時のデータ保護、ストレージのスナップショット、データのダンプを行うツール、バックアップなどが想定され、Kubernetesにおいてもそれらが要求されていると語った。
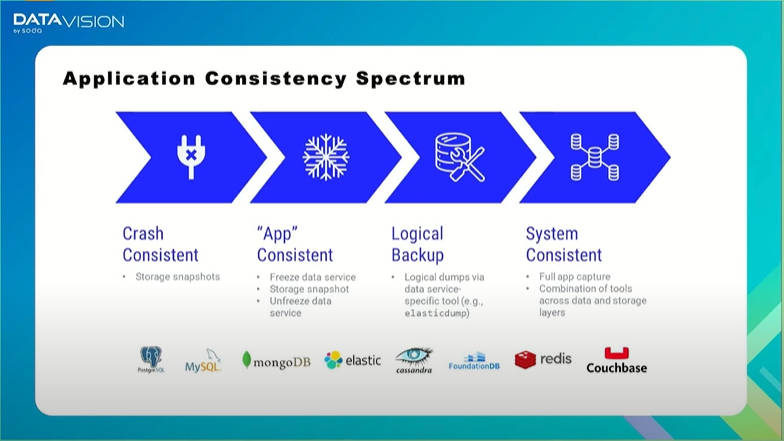
ステートフルなアプリケーションにおける保護の解説
そしてそれをアプリケーションのレベルで行うのがKanisterであると紹介。

Kanisterの紹介。アプリケーションが使うデータ保護をKubernetes上で行う
ここで「アプリケーションレベルのデータ保護」と何度も繰り返しているのは、Kubernetes自体が分散データベースのetcdを使う「アプリケーション」であることが背景にあると思われる。ある時点のKubernetesの状態を保存し、問題発生時にリカバリーとしてその時点に戻るというニーズがあるのに対して、KanisterはあくまでもKubernetesのPodで実行されるアプリケーション、例えばデータベースのバックアップやリストアをKubernetesのスタイルに沿って行うツールだからということだろう。
実際、Cade氏の所属するVeeamはKastenというKubernetesに特化したバックアップソリューションを2020年10月に買収してポートフォリオに加えているが、Kastenについては何も触れずにKanisterの紹介だけに留めているのは、このカンファレンスに参加しているエンジニアに余計な情報を入れたくないという配慮からだろうか。
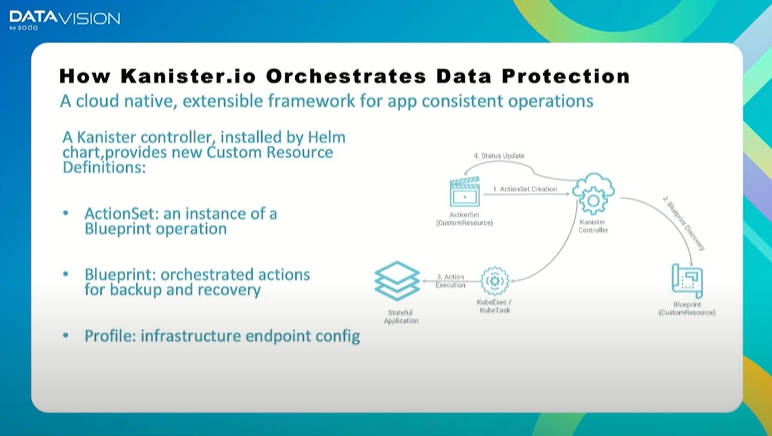
Kanisterの概念図
このスライドではKanisterがBlueprint、ActionSet、Profileという3つのカスタムリソースを追加して使用すること、Kanister Controllerが動作の基本プロセスであることなどを解説している。またインストールにはHelmが用いられることも記載されている。
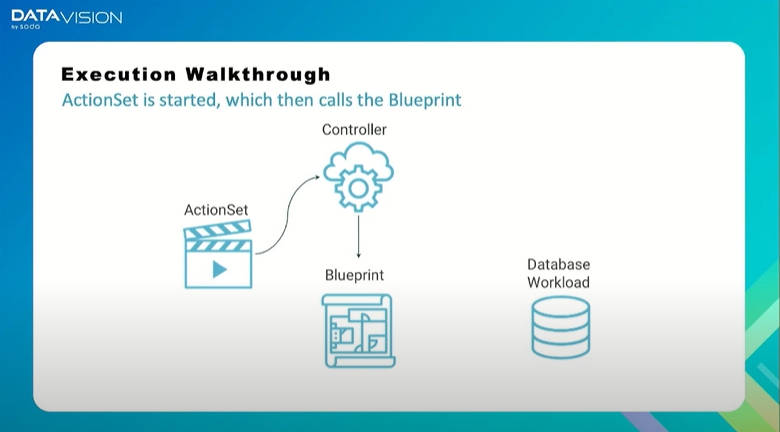
Kanisterの動作の流れを紹介。ActionSet起動からBlueprintが呼び出される
カスタムリソースであるActionSetが起動されると、必要なBlueprintが呼び出されるという順番で処理が進み、Kanister Controllerが対象となるデータベースのバックアップを行う。
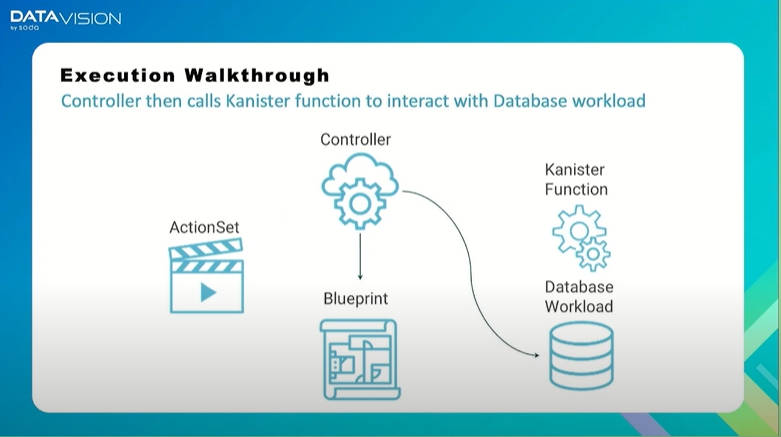
ControllerがBlueprintに従って対象となるデータベースのバックアップを始める
その後、バックアップされたアーカイブデータは別のクラスターやパブリッククラウドなどに保存されるというのが、例として示されたバックアップを行う際の一連の流れになる。
そしてここからはターミナルを使ってKubernetesのPodやカスタムリソース、ネームスペースなどを確認しながら、ElasticsearchにJSONでデータを保存、それをバックアップしてからデータを削除、その後、バックアップしたアーカイブデータからデータをリストアするというデモを実施した。
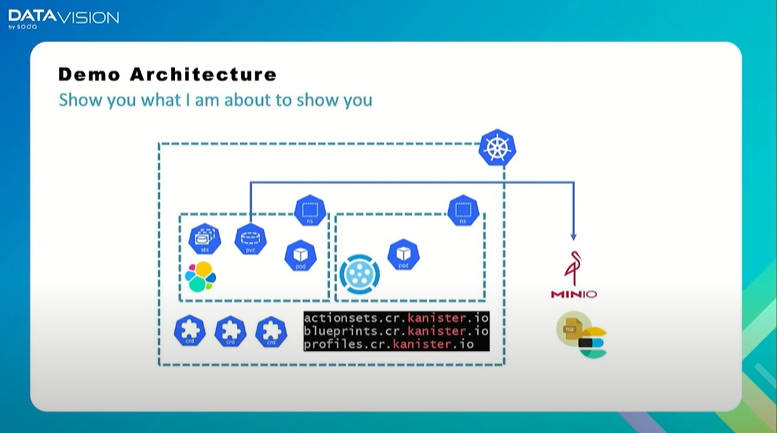
2つのネームスペースを用意してバックアップリストアのデモを実施
ここでは「これはデモだから同じクラスターにバックアップしているけど、実際には別のクラスターやパブリッククラウドにデータを退避して欲しい。そうでなかったらバックアップの意味がないよね?」とコメントし、あくまでも動作を見せるためのデモであることを強調した。この辺りはデータ保護を専門にしているVeeamのエンジニアらしい気の使い方だろうか。
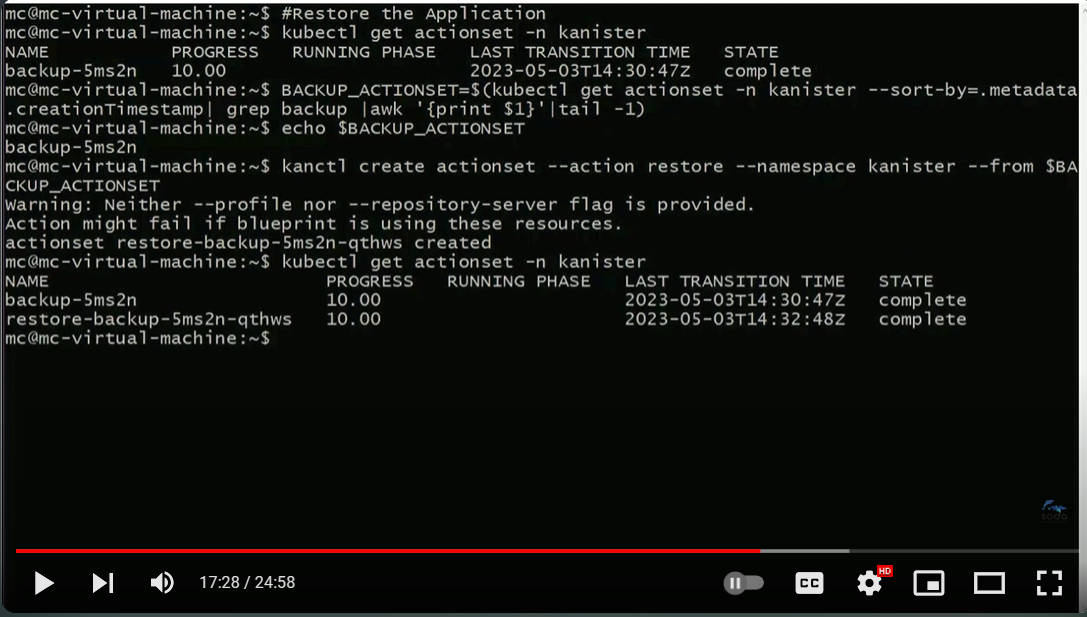
ActionSetというカスタムリソースにバックアップとリストアが作られていることを表示
デモでは、すでにDeployされているKubernetesにKanisterをHelmでインストールしたのち、カスタムリソースを作り、Elasticsearchが実行されているPodでデータを追加する。その後バックアップを取り、データを削除してリストアを行い、再度データを確認するという流れだ。Kanisterの基本的な動作を紹介するという目的には最適な内容と言えるだろう。ちなみにストレージはMinioを使っている。
最後にこのカンファレンスのホストであるSODA FoundationのプロジェクトであるKahuについても簡単に触れ、KahuがKubernetes自体のデータ保護を目的としているのに対し、KanisterはKubernetes上で動くステートフルアプリケーションのデータ保護が主眼であるというように棲み分けていることを紹介した。

Kahuとの違いを解説。K8s自体のバックアップかアプリケーションデータ保護かの違い
ここでもVeeamのソリューションであるKastenについては何もふれず、SODAのプロジェクトとの違いを解説したに留まっており、敢えて自社製品の宣伝を排除していることを暗に示した格好となっている。
Kanisterについては以下の公式サイトを参照されたい。
●参考:Kanister公式ページ:https://kanister.io/
この記事をシェアしてください
バックナンバー
この記事の筆者

筆者の人気記事
SASEのCato Networks、CEOによるセミナーとインタビューを紹介
2020年4月16日 6:00
Rustのエコシステムの拡がりを感じるデスクトップアプリのためのツールキットTauriを紹介
2022年12月16日 6:00
Zabbix式オープンソースの秘密に迫る
2025年1月31日 6:00
WebAssemblyとRustが作るサーバーレスの未来
2020年4月21日 6:00
三菱電機が設立したOSPOのメンバーにインタビュー。「インナーソース」を戦略的に使う背景とは?
2025年10月3日 6:00
エンタープライズLinuxを目指すSUSE、Red Hatとの違いを強調
2015年2月3日 19:00
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
