データベース性能の基本的な考え方
連載第1回目となる今回は、データベース性能の基本的な考え方について解説します。
2024年2月15日 6:30
目次
はじめに
スマートフォンをはじめとした各種スマートデバイスの普及に伴い、データの容量が爆発的に増加しています。これらのビッグデータをどのように活用するかが大きな関心を呼んでいますが、その性能に対する関心は低いように感じます。しかし、性能の低いビッグデータ基盤では分析結果を得るまでの「ターンアラウンドタイム」が長くなるため、試行錯誤を行うことや分析結果を活用することが困難になります。今後のビッグデータ基盤には、増え続けるデータを高速に分析処理できる性能が要求されるようになるでしょう。
本連載では、まずデータベースの性能に関する基本的な考え方と一般的な高速化手法を解説します。その後、GPUを活用したデータベース「PG-Strom」が行っている新しい高速化手法を紹介します。PG-StromはPostgreSQLを拡張する形で実装されており、基本的な機能はOSS版として誰でも利用できますので、導入方法と基本的な使い方について解説します。
データベースの性能とは
「データベースの性能」とひとことで言っても、そのデータベースの用途がどのようなものかによって要求する性能が異なります。本連載が想定しているのはビッグデータ基盤のためのデータベースなので、大容量データからの検索処理や集計処理が高速に行えることが性能として求められることになります。
データベースの検索・集計性能は、主に以下の3つの処理性能から決まります。
- データの読み込み処理
- 検索処理
- 集計処理

以降では、各処理の性能を左右するポイントを見ていきましょう。
データの読み込み処理
データベースはHDDやSSDなどのストレージにデータを保管し、必要に応じてそのデータをメモリに読み込んで検索処理や集計処理を行います。ストレージはCPUやメモリなどに比べて速度が遅いため、性能のボトルネックになりやすい部分です。
ストレージの読み込み速度はさらに、ストレージ自体の速度と、ストレージとメモリを接続する経路の速度に分けることができます。
・ストレージ自体の速度
ストレージ自体の速度は、IOPS(Input/Output PerSec: 1秒あたりのI/O回数)や読み書き速度(○MB/秒)で表されます。IOPSはランダムアクセスに、読み書き速度は大きなデータを読み込む際の性能に影響します。ビッグデータ処理の場合、ランダムアクセスをすることは少ないので、連続的(シーケンシャル)な読み込み速度が大きく影響します。HDDなら回転速度、SSDなら使用しているシリコン記憶素子、そして接続を司るコントローラーの性能が重要となります。
これらの数値はカタログスペックのほか、ベンチマークツールで計測することもできるので、自分が普段から使っているストレージのベンチマークを行って、肌感覚を養っておくと良いでしょう。
容量の面でコストパフォーマンスが高いのはHDDです。性能が要求されないシステムではまだまだHDDが使われていますが、SSDも大容量化してきているため用途に応じて使い分けられるようになってきています。
・ストレージ接続経路の速度
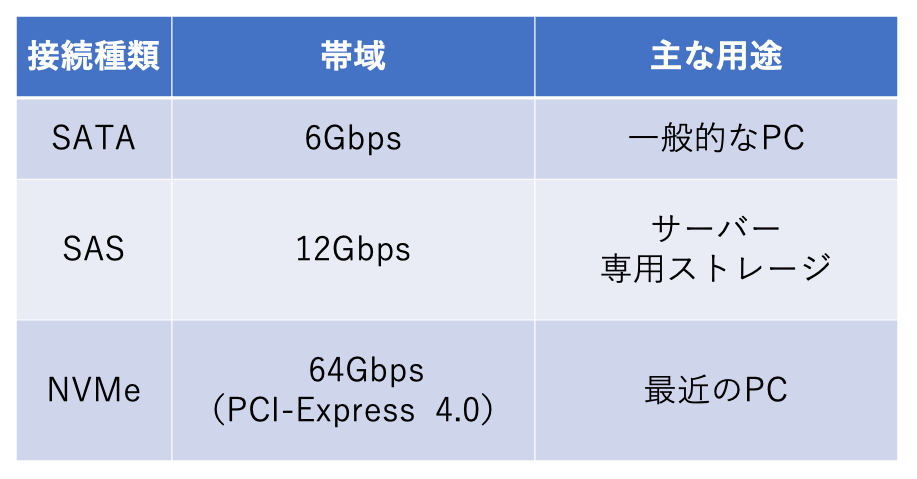
現在のストレージ接続の種類には、主に以下のものがあります。性能は、一度にやり取りできるデータの帯域幅で表されます。
・SATA(Serial ATA)
一般的なPCで使われていた接続方式。最近は減ってきている。接続帯域は6Gbps。
・SAS(Serial Attached SCSI)
ストレージ接続の規格であるSCSI(Small Computer System Interface)をシリアル通信化した接続方式で、サーバー機でよく使用されている。接続帯域は6Gbpsから12Gbps。
・NVMe(Non-Volatile Memory Express)
SSDのようなメモリ型ストレージに最適化された接続方式。PCのデバイス間通信で使用されるPCI-Expressに直接接続して動作するため、少ないオーバーヘッドでデータの読み書きが行える。最近のPCで使われるようになってきている。接続帯域は64Gbps(PCI-Express 4.0 x4レーンの場合)。
・データベース性能を考慮したストレージ選び
データベース用途で考えると、現状では容量と性能のバランスが良いSAS接続のストレージが多く使われています。NVMeは帯域性能が高く高性能に見えますが、PCI-Express直結という接続方式のため、1台のマシンに接続できるストレージデバイスの数が制限されます。NVMeは容量がそれほど必要とされないPCでの採用が進んでいますが、今後PCI-Expressが高速化し、容量の多いSSDのコストがさらに安くなれば、性能が要求されるサーバーのストレージとして採用されるケースも増えそうです。
検索処理
ストレージからメモリに読み込んだデータから、必要となるデータをさらに絞り込む処理です。SQLを使用して操作するデータベースであれば、WHERE句による条件一致検索処理などがこれにあたります。IN演算子やLIKE演算子などを併用すると、それだけ比較演算を行うための処理が増えるため、性能は劣化します。
JOIN句による表結合処理、SELECT選択リストによる必要なデータ列のみの抽出などの処理も必要となります。
・副問い合わせによる性能の劣化
副問い合わせを行うと検索処理が増えるだけでなく、比較演算の処理も増えるため、さらに性能が劣化することになります。ビッグデータの分析では、ある表の検索・集計結果を条件にして検索・集計を行うことが多いため、必然的に副問い合わせによる性能劣化が起きやすくなります。
集計処理
検索処理で絞り込まれたデータを、さらに分析するために集計を行う処理です。集計処理を分析用のアプリケーションで行う場合もありますが、検索処理で絞り込まれたデータの量が多い場合には集計処理までデータベース側で行うことが多いです。
SQLにはGROUP BY句による集約や、COUNT関数などの集約関数を使った集計処理が用意されています。また、ORDER BY句によるソート処理なども行うことができます。
・集計処理に必要となるメモリ
これらの集計処理はCPUを使った計算量が必要なだけでなく、データ容量の分だけメモリを消費するため、ビッグデータ基盤を構築する場合には1TBといった大容量メモリを搭載したサーバーを用意することになります。
おわりに
連載第1回目となる今回は、データベース性能の基本的な考え方について解説しました。次回は、データベースの性能を向上させるためにはどのようにすれば良いのかについて解説します。
この記事をシェアしてください
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
