ベンチマークで「PG-Strom」のクエリパフォーマンスを確認してみよう
連載第4回となる今回は、ベンチマークで「PG-Strom」をどれくらい爆速化できるのか、クエリパフォーマンスの例を挙げながら解説します。
2024年5月21日 6:30
はじめに
データベースの性能を定量的に測定するには、ベンチマークが欠かせません。今回は、データベースのベンチマーク手法を解説し、その後、第3回で紹介した「PG-Strom」用いた際の、クエリパフォーマンスの例を紹介します。
PG-StromはGPUを活用して性能を爆速化するデータベースで、PostgreSQLのエクステンションとして提供されています。
データベースの性能を測るということ
第3回まででは、さまざまなデータベース性能向上方法とその限界を紹介しました。ところで、ひとことで「データベースが速い」と言いますが、それはどのように測定すれば良いのでしょうか。第3回の最後でも紹介したように、OLTP(Online Transaction Processing)用途とOLAP(Online Analytical Processing)用途では、データベース内部での動作は大きく異なります。前者は、同時に大量にやってくる処理リクエスト(クエリ)を高速に捌くこと、後者は、ビッグデータとも呼ばれる膨大なデータを検索・集計を高速に実施することと言えるでしょう。
データベースの速度を計測するには、独自に用意したデータで、独自に決めたシナリオに従ったクエリを実施することで、その高速性をアピールすることもあります。しかし、シナリオや設計が独自であるために他の製品との比較が難しかったり、客観性に欠けるシナリオとなる場合も少なくありません。
そういった課題を解決する速度計測方法として、業界団体が策定している速度測定方法があります。
ベンチマーク規格「TPC」
TPC(Transaction Processing Performance Council)という業界団体が、データベースの速度を計測するための手法をいくつか公開しています。OLTP向けとして「TPC-E」や「TPC-C」など、OLAP向けとしては「TPC-H」や「TPC-DS」などが知られています。
TPCは1980年代の設立ですが、筆者の肌感覚では当初はいまひとつ採用は拡がっていない印象でした。ここ10年くらいはTPCベースのベンチマーク結果を目にする機会も多くなり、データベース共通のベンチマーク手法としての採用が定着しつつあるように感じます。
スタースキーマベンチマークの登場
このように、データベース間の速度比較のためのツールとして拡がってきたTPCベンチマークですが、やや複雑に過ぎるとの声もありました。例えば、OLAP用途のベンチマークとして使われるTPC-Hは8個のテーブルが複雑に関連し合うテーブル構造となっており、実行にも多くの時間を必要とします。
実際の現場では、ここまで複雑なテーブル間連携を行うものよりも、1つのテーブルを中心として、その周りに属性情報を持つテーブルを複数連携させる「スタースキーマ型」の設計がよく行われます。
そこで、TPC-Hをベースにしてより簡略化した「スタースキーマベンチマーク」が登場しました。スタースキーマベンチマークは、1つの中心テーブル(ファクトテーブルと呼びます)から、4つの属性テーブル(ディメンションテーブルと呼びます)をそれぞれ結合するスタースキーマ型のテーブル構造を持つデータベースに対するベンチマークです。
次の節では、スタースキーマベンチマークについてもう少し詳しく説明します。
スタースキーマベンチマークの構造
スタースキーマベンチマークのテーブル構造は図1のようになっています。

図1:Star Schema Benchmarkのテーブル
lineorderが中心にあり、その周囲にcustomer、part、supplier、dateの各テーブルが結合される構造となっていることを読み取れるかと思います。中心にあるテーブルのことをファクトテーブルと呼び、周囲のテーブルをディメンションテーブルと呼びます。このようなテーブル設計は、ファクトテーブルから周囲のテーブルに線が伸びている様子が星のようであることから、スタースキーマ型と呼ばれます。
この中で最も件数が多いテーブルが、中心にあるlineorderテーブルです。ディメンションテーブルのデータ件数は、ファクトテーブルに比べると非常に少ないものとなります。
スタースキーマベンチマークでは、これらのテーブルに対してQ1からQ4の4パート、合計13個のクエリが用意されています。Q1では2テーブル結合での単純な抽出、Q2~Q4では4個ないし5個のテーブルを結合して集計(グルーピング)した結果を得るクエリとなっています。
PG-Stromでのスタースキーマベンチマーク実施
ここで、第3回で紹介したPG-Stromを使用してスタースキーマベンチマークを実施した結果を紹介します。PG-Stromには下記の特長があり、ビッグデータの分析を行うのに適しています。
- GPUの大量のコアを活用した超並列処理
- GPUDirect Storageによるデータ読み込みの高速化
PG-Stromによる
スタースキーマベンチマーク実施環境
今回のベンチマークに使用した環境は下記のとおりです。通常のPostgreSQLは処理にCPUのみを使用しますが、PG-StromではGPUのパワーを活用できるため、検証機にはA100(80GB)というGPUを搭載しています。また、ストレージには読み書きが非常に高速であることからNVMeを採用しています。
- CPU: AMD EPYC 7443 24-Core Processor(24 cores/48 Processsors)
- OS: Red Hat Enterprise Linux release 8.8 (Ootpa)
- Memory: 131,330,728 kB
- GPU: NVIDIA A100 80GB PCIe (6,912 Cuda cores)
- CUDA Version: 12.3
- PostgreSQL Version: 16.1
- PG-Strom: 5.0* (githubより検証実施時点の最新版ソースコードからビルド)
*:2024年5月21日現在、PG-Strom 5.1が公開されています
ベンチマークに使用したデータ
スタースキーマベンチマークでは、検証に使用するデータを作成する際にスケールファクタ(s)を指定して、生成するデータサイズを制御できます。今回の検証では s=400 でデータ生成しました。各テーブルの件数は図2のとおりです。
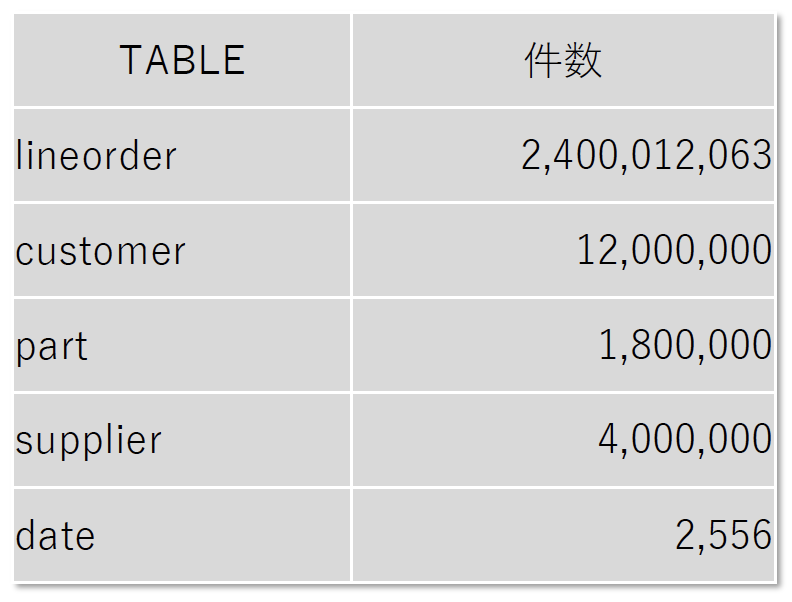
図2:ベンチマークに用いた件数
ファクトテーブル(スターの中心となるテーブル)の件数が約24億件と非常に大きいデータとなっていることが分かります。周囲のテーブルはそれよりも2桁以上少ない件数です。これがスタースキーマの特徴です。
これらのデータは、通常のPostgreSQLのテーブル(heap)に格納されています。 lineorderは \dt+ で表示されるテーブルのサイズ約350GBとなっています。
GPUを使用したPG-Stromでの
スタースキーマベンチマーク実施結果
スタースキーマベンチマークの実施結果は図3のようになりました(各3回ずつ実施の平均値)。青色の棒がPostgreSQL、オレンジ色の棒がGPUを使用したPG-Stromです。縦軸は秒数で、棒が長いほどそのクエリの処理に時間がかかったことを表します。
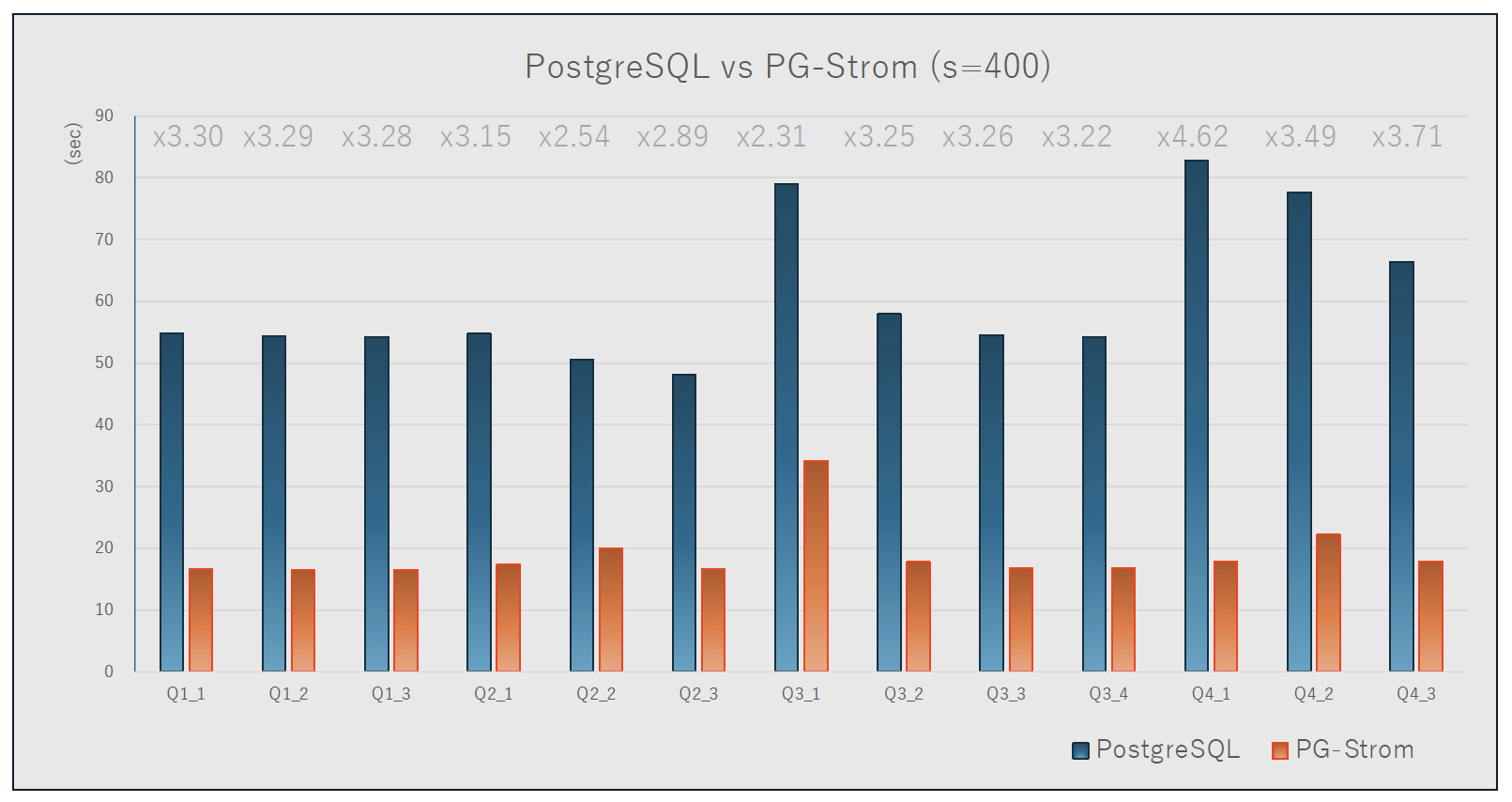
図3:Star Schema Benchmark実施結果
ひと目見て、PG-Stromでの処理がすべてのクエリに対して大幅に高速に処理されていることを見て取れると思います。データを高速に処理装置(GPU)へ転送するGPUDirect Storageと、GPUの多コアを活用した並列処理というPG-Stromの特長が、今回のスタースキーマの大量データにマッチしていることがよく現れた結果になっています。
また、特筆すべきは、ストレージに格納されているデータ自体はPostgreSQLのデフォルトの格納方式(heap)のままであるということです。つまり、PG-Stromでの高速処理を行うための特別な事前のデータ加工処理などを行っているわけではないのです。もともとのPostgreSQLの格納データそのままでこれだけの処理速度の差が出るのは、技術的にもかなり面白いのではないでしょうか。
おわりに
今回は、OLAPのベンチマークとしてスタースキーマベンチマークがどういったものかを解説し、実際にスタースキーマベンチマークで大量のデータをPG-Stromで処理した結果を紹介しました。Q4_1の結果のように、これまで80秒以上かかっていた集計処理が20秒未満で実施できることは、目の前のビッグデータに対して切り口を変えながらクエリを何度も実行していく必要がある統計家や分析屋さんにとって、試行を繰り返しやすくなる点で大きな魅力になるのではないでしょうか。
次回は、皆さんのお手元でPG-Stromを動作させるための環境構築方法を解説します。
この記事をシェアしてください
関連記事
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
