「Terraform」のコードを自分で書けるようになろう
実践編第2回の今回は、Iacツール「Terraform」のコードを自分で書けるようになるための基礎知識について解説します。
2024年5月7日 6:30
はじめに
前回は、Iacツールの「Terraform」について、基本的な使い方と運用管理に必要なコマンド、覚えておくと便利なコマンドを解説しました。前回の解説で、事前に用意されたTerraformのコードなどは問題なく実行できるようになったのではないでしょうか。
今回は、Terraformのコードを自分で書けるようになるため、Terraformのコードとは何か、コードを書いていくにあたり気をつけるべき点、基本的な書き方について解説していきます。
Terraformのコード
TerraformのコードはHashiCorp Configuration Language(HCL)というフォーマットで記述していきます。HCLはHashiCorpによって作らたTerraform専用の独自言語です。構文の詳しい説明については、下記の公式ドキュメントを参照してください。
●Configuration Syntax
●Style Guide
GoogleもTerraformのベストプラクティスについてガイドを公開しています。
HCLの構文
HCLはブロックという単位で構成され、1つのブロックに対し1つのリソースの状態を記述していきます。
resource "aws_instance" "this" {
...
}記述方法は左から順に、ブロックタイプ(上の例ではresource)に応じていくつかのラベルを設定します。ブロックタイプがresourceの場合、リソースタイプ(上の例ではaws_instance)、リソース名(上の例ではthis)と続きます。
リソースタイプに指定できる値はプロバイダーのドキュメントページ左側にあるツリーから確認できます。
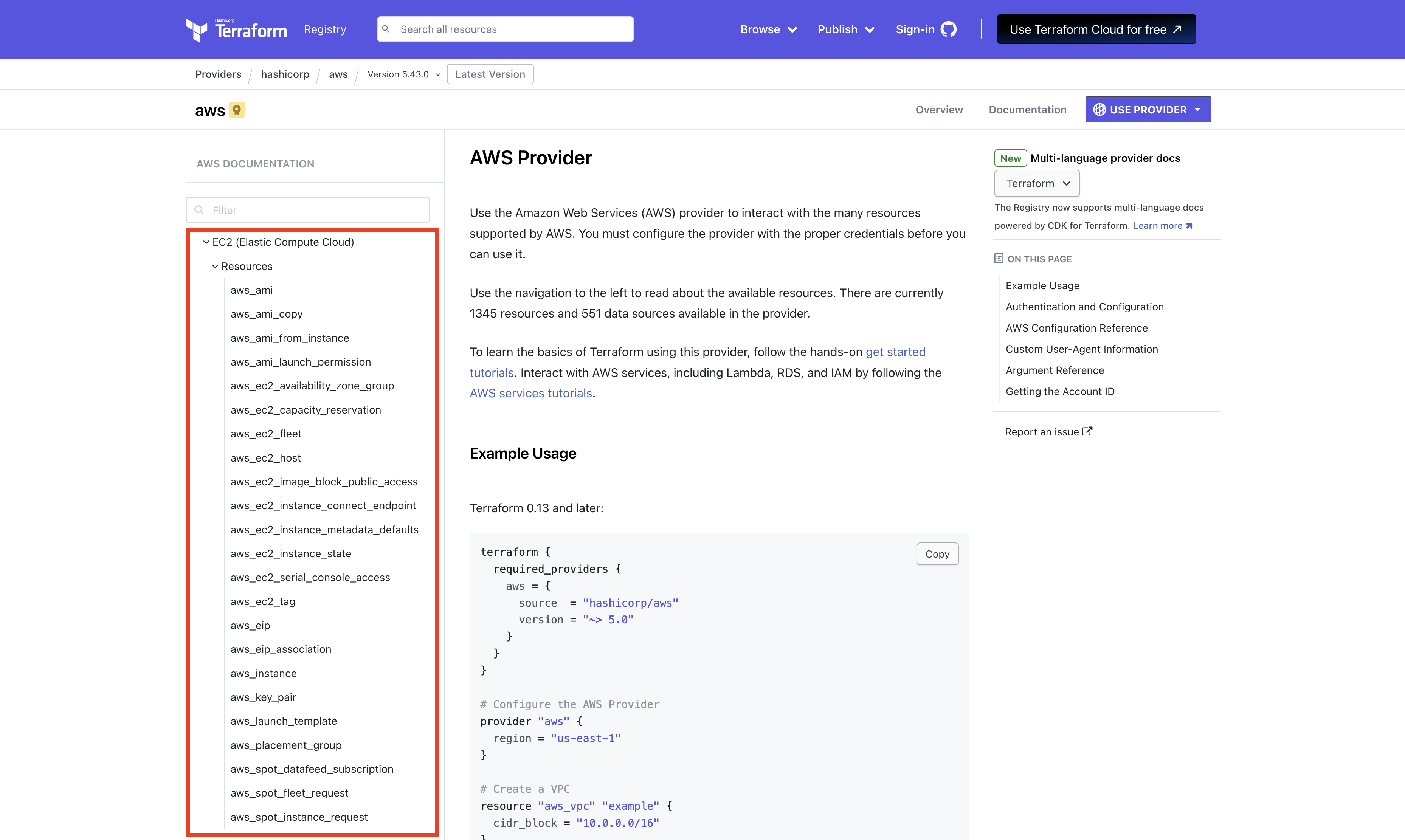
使用可能なリソースタイプ一覧
使用したいリソースタイプを選択すると、そのリソースで設定できる値などが確認できます。コード化する際はこのドキュメントを確認しながら進めることになるので、使い方を覚えておきましょう。
リソース名はTerraformでリソースを管理するために必要な値です。実際に構築したリソースに付けられる名前ではありません。リソースタイプとリソース名はセットで管理され、同じリソースタイプを複数管理する時にリソース名はユニークである必要があります。
【OK】resource "aws_instance" "web" {}
resource "aws_security_group" "web" {}resource "aws_instance" "web" {}
resource "aws_instance" "web" {}TerraformスタイルガイドやGoogleが提唱しているベストプラクティスに則ると、以下のようなルールもあります。
【リソース名を単数形にする】・推奨︎
resource "aws_subnet" "subnet" {}resource "aws_subnet" "subnets" {}・推奨
resource "aws_subnet" "public" {}resource "aws_subnet" "public_subnet" {}mainと付けて簡略化する】・推奨
resource "aws_vpc" "main" {}resource "aws_vpc" "vpc" {}上の非推奨パターンでは「リソースタイプを繰り返さない」にも違反しています。無理に名付けるよりmainやthisなどで簡略化しましょう。
_(アンダースコア)を使う】・推奨
resource "aws_instance" "web_server" {}resource "aws_instance" "web-server" {}値の参照
HCLは他のブロックで作成したリソースの値を参照できます。参照するにはブロックタイプ、リソースタイプ、リソース名を.(ドット)で連結します。ただし、ブロックタイプがresourceの場合はブロックタイプを省略できます。
data "aws_ami" "al2023" {
...
}
resource "aws_instance" "this" {
ami = data.aws_ami.al2023.image_id
}
output "instance_id" {
value = aws_instance.this.id # or resource.aws_instance.this.id
}上の例ではamiの値を別のブロックから取得しています。この場合data.aws_ami.al2023はresource.aws_instance.thisより先に解決される必要がありますが、ブロック間の依存関係はTerraformが自動で解決するため、コードの書き方や実行方法で意識する必要はありません。
参照できる値はリソースタイプのドキュメント下方にある「Attribute Reference」の項目で説明されています。

参照できる値の一覧
こちらもコード化する際に必ず確認するドキュメントとなりますので、使い方を覚えておきましょう。
変数定義
HCLではローカル変数とグローバル変数を定義できます。
【ローカル変数】locals {
変数名 = 値
}variable "変数名" {}
変数名 = 値ローカル変数は外部から変数の値を変更できません。変数の定義は.tf拡張子のファイルで行います。ローカル変数を参照するにはlocal.変数名を使用します。
グローバル変数は外部から変数の値を変更できます。.tf拡張子のファイルでvariableブロックを定義し、.tfvars拡張子のファイルで変数に代入します。また、特別なファイルを使用せず環境変数から値を渡すことも可能です。その場合はTF_VAR_変数名という環境変数に値を代入します。グローバル変数に設定された値を参照するにはvar.変数名を使用します。
変数に設定できる型については、公式ドキュメントの「Types and Values」の項で詳しく説明されています。
ループ
HCLはループを使って複数のリソースや値を作成できます。HCLで記述できるループはcount、for_each、forの3つです。それぞれ使い方や動作が異なるため、違いを意識して使用できるようになりましょう。
locals {
instances = ["instance1", "instance2", "instance3"]
}
data "aws_ami" "al2023" {
...
}
resource "aws_instance" "this" {
count = length(local.instances)
ami = data.aws_ami.al2023.image_id
tags = {
Name = local.instances[count.index]
}
}countは指定された回数分処理を繰り返します。上の例ではinstancesというローカル変数にインスタンス名をlistでセットし、length()関数でlistの要素数をcountにセットしています。count.indexで現在のインデックス番号を取得し、Nameタグにインスタンス名をセットしています。このコードが展開されると以下のようになります。
resource "aws_instance" "this" {
ami = data.aws_ami.al2023.image_id
tags = {
Name = "instance1"
}
}
resource "aws_instance" "this" {
ami = data.aws_ami.al2023.image_id
tags = {
Name = "instance2"
}
}
resource "aws_instance" "this" {
ami = data.aws_ami.al2023.image_id
tags = {
Name = "instance3"
}
}リソースを参照するにはインデックス番号を指定して、aws_instance.this[0]やaws_instance.this.1でアクセスできます。
countを使用する際は、インデックスが変更されたときの動作に注意が必要です。例えば、ローカル変数のリストからインデックス番号1の値"instance2"を削除したとしましょう。動作として下図の状態を期待します。
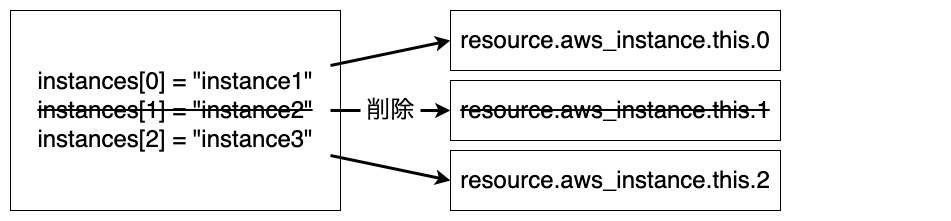
期待する動作
しかし、実際の動作は下図のようになります。
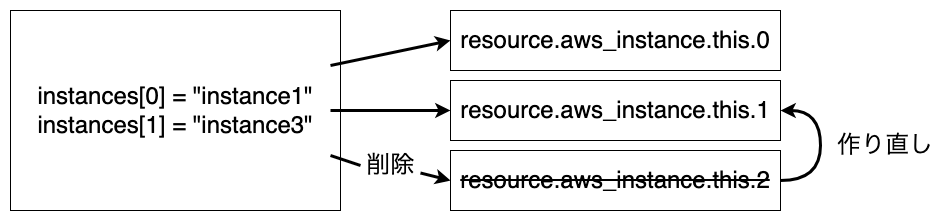
実際の動作
listは途中のインデックスを削除すれば後続の値が繰り上がってきます。リソースを管理しているインデックスが変更となるため、リソースの再作成が発生します。
【for_each】locals {
instances = ["instance1", "instance2", "instance3"]
}
data "aws_ami" "al2023" {
...
}
resource "aws_instance" "this" {
for_each = toset(local.instances)
ami = data.aws_ami.al2023.image_id
tags = {
Name = each.value
}
}for_eachは渡されたオブジェクト数分処理を繰り返します。上の例ではlistの値をtoset()関数でset型に変更しています。set型は重複する値を削除しソートしてくれます。for_eachはset型かmap型を受け取ります。ループしているキーや値にはeach.keyやeach.valueでアクセスできます。コードを展開するとcountのときと同様ですが、リソースへのアクセス方法が変わります。for_eachで作ったリソースへはaws_instance.this["instance1"]でアクセスできます。countはキーがインデックス番号だったのに対し、for_eachは連想配列のような構造になってます。そのためlistはset型に変換し重複を削除する必要があったのです。この構造のおかげで一部の値が削除されたとしてもcountのときのようにインデックスが切り詰められることはありません。
locals {
instances = ["instance1", "instance2", "instance3"]
}
data "aws_ami" "al2023" {
...
}
resource "aws_instance" "this" {
for_each = toset(local.instances)
ami = data.aws_ami.al2023.image_id
tags = {
Name = each.value
}
}
output "instance_id" {
value = [for x in aws_instance.this : x.id]
}forはcountやfor_eachと少し毛色が違います。countやfor_eachはリソースを繰り返し作成していたのに対し、forは何らかの値を加工するのに使います。上の例では作成したリソースをforループにかけて、それぞれのリソースからインスタンスIDを取得するコードです。
countやfor_eachを処理の分岐に使用する方法もあります。
locals {
create_instance = false
}
resource "aws_instance" "count" {
count = local.create_instance ? 1 : 0
...
}
reousrce "aws_instance" "for_each" {
for_each = local.create_instance ? [1] : []
}上の例では、create_instanceの値がtrueだったらcountに1をセットし、falseの場合はcountに0がセットされます。for_eachの場合は要素が1つのリストか空のリストが渡されます。どちらの場合も0か空のリストであれば処理が実行されません。つまり、リソースの作成を変数でコントロールできるようになります。公開モジュールなどを見てみると、このような実装が至る所で確認できます。
ここまでのサンプルコード
ここまでのコードをまとめると、以下のようになります。
provider "aws" {
region = "ap-northeast-1"
}
locals {
instances = ["instance1", "instance2", "instance3"]
}
data "aws_ami" "al2023" {
most_recent = true
owners = ["amazon"]
filter {
name = "architecture"
values = ["x86_64"]
}
filter {
name = "name"
values = ["al2023-ami-2023.*"]
}
filter {
name = "virtualization-type"
values = ["hvm"]
}
}
resource "aws_instance" "this" {
for_each = toset(local.instances)
ami = data.aws_ami.al2023.id
instance_type = "t3.micro"
tags = {
Name = each.value
}
}
output "instance_id" {
value = [for x in aws_instance.this : x.id]
}このコードをmain.tfなどに保存して実行すると、ap-northeast-1にt3.microのEC2が最新のAmazon Linux 2023で3つ起動します。実行に成功すると起動したEC2のinstance_idが標準出力されます。
コードを見ると分かる通り、宣言型特有の望む構成が記述されているのみです。手続型のような構築手順などの記載が一切ないため、どのような構成で構築されるかコードから簡単に読み取れます。
ステートファイルの分割
多くのリソースを管理するようなコードを書き始めるには、ステートファイルの分割粒度を考えておく必要があります。ステートファイルの分割粒度とは「どの粒度でリソースをまとめて作成するか」ということです。Terraformのステートファイルはディレクトリ単位で分割されます。つまり、1つのディレクトリ以下ですべてのリソースを管理するか、ある程度の粒度でディレクトリを分割し管理するかを考える必要があります。
前者は全く分割しない方法です。これは依存関係の全てをTerraformが解決し、1度のapplyで必要なリソースを全て作成します。環境を構築するための特別な知識を必要としません。一方で、一部のリソースにだけ変更を適用しようと考えたときにはTerraformやコード、クラウドの知識が求められます。意図しないリソースの再作成や破壊しても問題のない環境で使用する分には問題ありませんが、停止できないリソースがある場合は、そのリソースを別のコードで作成した方が良いでしょう。
後者はリソースごとのグループで分割する方法です。ここで重要なのはリソースごとのグループで分割するという点です。例えば全てのリソースで分割したことを考えてみましょう。リソース間の依存関係は自分で解決する必要があり、プロビジョニングの順番が重要になってきます。これではTerraformを使用している旨みが減ってしまいます。
そこで筆者がおすすめするのはグループで分割する方法です。グループとは、それぞれの分割されたリソースは疎結合を保ちつつ、密結合となるリソースはまとめてグループ化する方法です。これは1つの例ですが、以下のような分割が思いつきます。
- 基盤となるVPC
- LBとエンドポイントの設定にDNS、SSL証明書の発行、バックエンドインスタンス
- RDB
- NoSQL
- CDNとオリジン
基盤となるVPCにはSubnetやRoute Tableも含まれます。ここを分割して管理する必要がないからです。他も同じように必要となる設定はまとめてしまいます。それぞれ分割されたリソースにはVPC IDなどが必要となりますが、それ以外はお互いをあまり必要としていない状況です。
このように疎結合にしておけばLBだけ作り直す、RDBだけ更新するなど個別に変更を加えていけるので管理が楽になります。また、これくらいの粒度であればプロビジョニングする順番が重要になったとしても人間が解決できる分量でしょう。
おわりに
今回は、Terraformのコードを書いていくに当たって基本的な書き方、気をつけるべき点、意識する点をまとめました。コードの書き方や構文は公式ドキュメントを参考にしていただくのがベストです。書き方や構文はTerraformのバージョンによって変化するものだからです。ステートファイルの分割は担当するプロジェクトやチームの方針によりけりですので、必ずしもこれがベストとは言えませんが、参考になれば幸いです。
この記事をシェアしてください
バックナンバー
この記事の筆者

筆者の人気記事
「Terraform」のコードを自分で書けるようになろう
2024年5月7日 6:30
WSLとWindowsの設定ファイルを「chezmoi」を使って安全に管理しよう
2025年2月19日 6:30
バージョン管理を柔軟に! プロジェクト単位で「asdf」を使いこなす
2025年5月7日 6:30
インフラエンジニアの視点で見る、DevOpsを実現するためのツールとは
2023年5月16日 6:30
CI/CDを実現するツール「GitHub Actions」を使ってみよう
2024年6月27日 10:13
WSLで「direnv」を活用してプロジェクト単位で環境変数を管理しよう
2025年5月27日 6:30
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
