AWSの監視サービス「CloudWatch」でサーバー監視を試してみよう
本連載も今回で最終回となります。今回は、AWSの監視サービス「CloudWatch」を使って、簡単なサーバー監視を試してみましょう。
2024年8月9日 6:30
はじめに
第15回では、システム運用における監視(モニタリング)の重要性について解説しました。
今回はその実践編として、AWSの監視サービスである「CloudWatch」を利用して、AWS上の仮想サーバーを監視し、異常時にアラームを通知するところまでを解説します。内容自体はあくまで簡単な設定例となりますが、具体的な監視の設定をはじめる際の参考にしてみてください。
EC2インスタンスの起動
今回は、EC2インスタンスを対象に監視を設定します。なお「メトリクスの監視」という点で言えば、EC2もRDSのようなマネージドサービスも大きな違いはありません。ここで紹介する内容は他のサービスにも応用が効きますので、ぜひ試してみてください。
- それでは、まずEC2インスタンスを起動しましょう。VPCやインターネットゲートウェイ等のリソースは既に作成済みのものとします。このあたりの設定については範囲外となるため省略します。
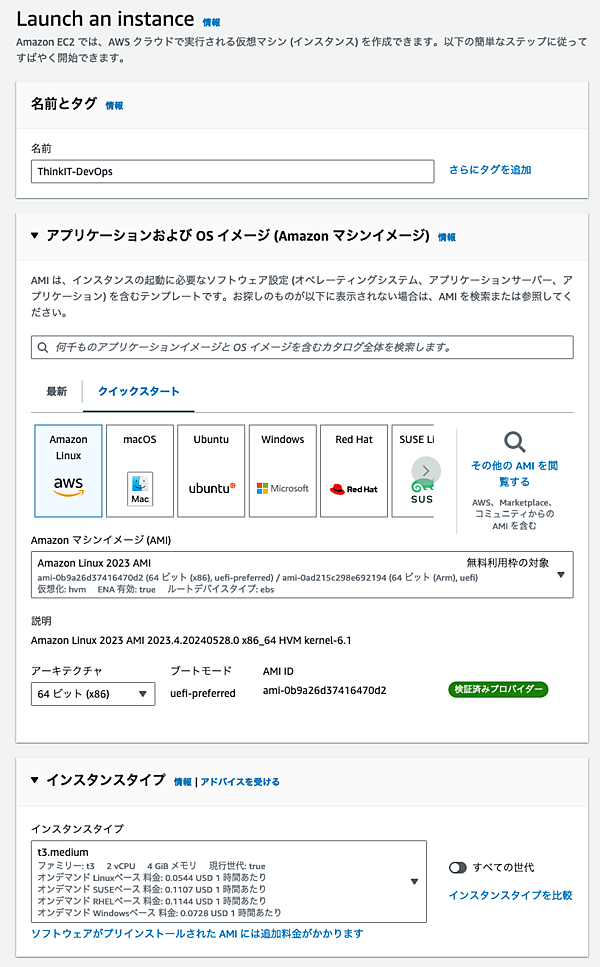
OSはAmazon Linux2、インスタンスタイプはt3.mediumでテスト用のインスタンスを起動した
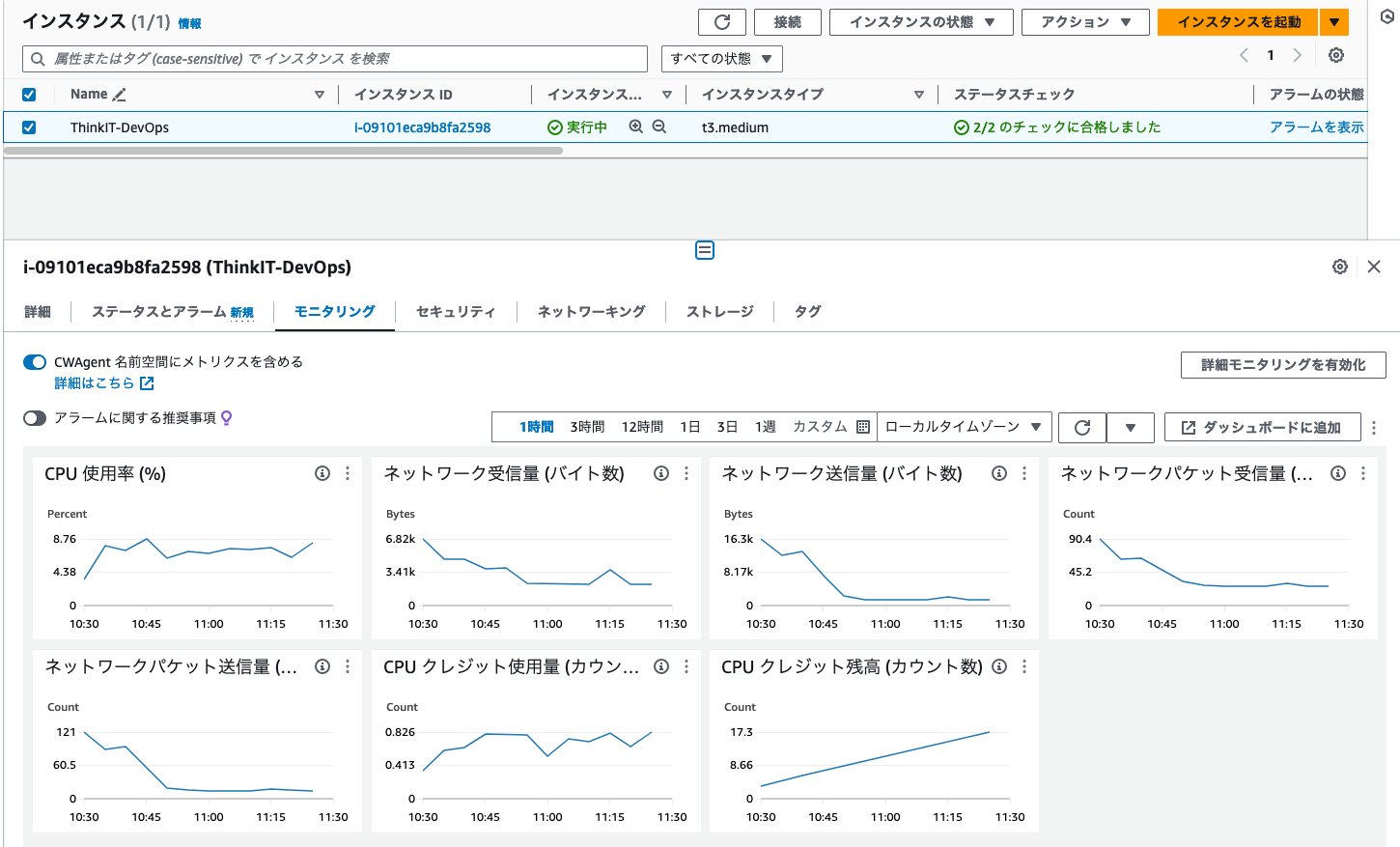
- EC2のインスタンスが起動したら、インスタンス一覧から該当のインスタンスを選択し、ウィンドウ下部に表示されている「モニタリング」タブをクリックしてください。CPU使用率、ネットワーク送受信量、CPUクレジット残高といった、ごくごく基本的な情報であれば、これだけで監視ができていることが分かります。

そのインスタンスのCPUやネットワークの使用状況であれば、ここから簡易的に確認できる
CloudWatchでメトリクスを監視する
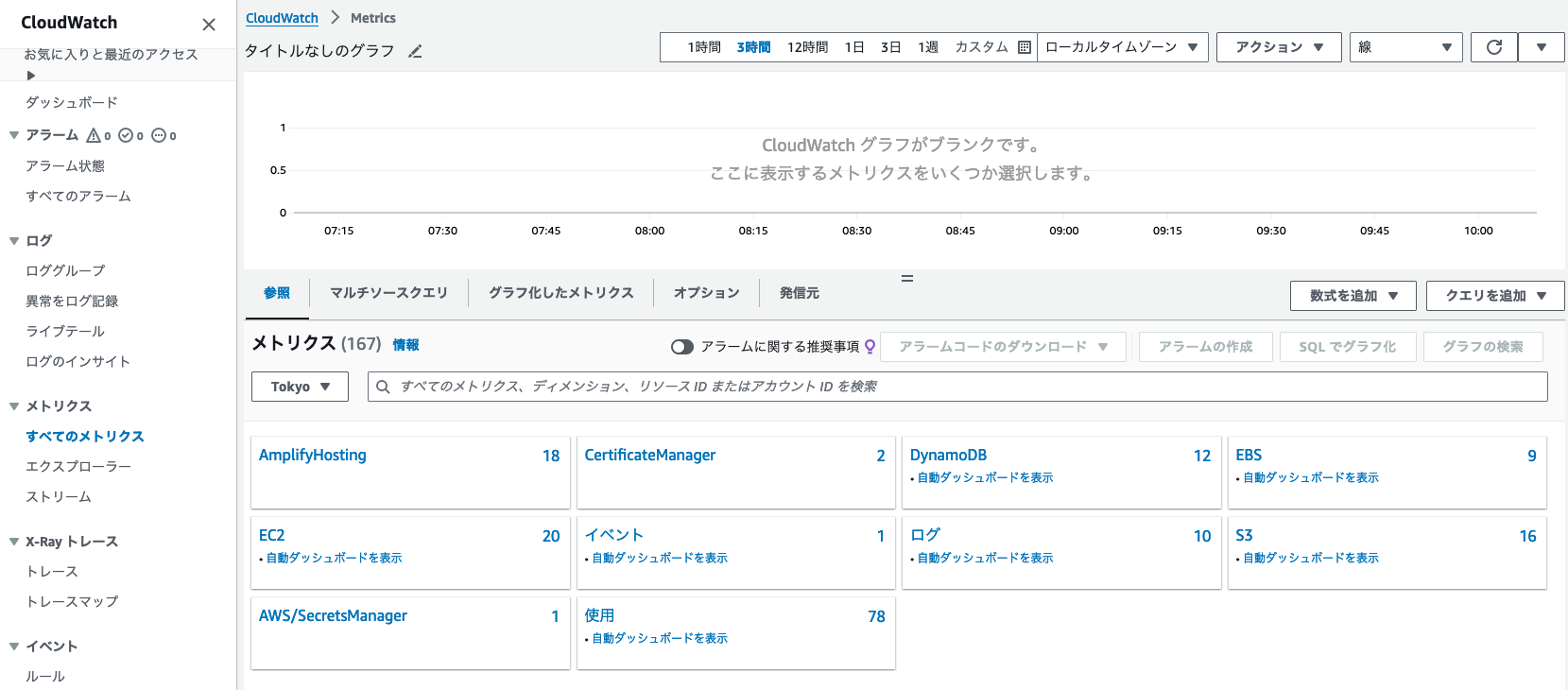
EC2のダッシュボードから確認できる情報は、ごくごく基本的なメトリクスのみでした。CloudWatchを利用すれば、もう少し詳細にメトリクスを確認できます。「まだ何も監視の設定をしていないよ」と思うかもしれませんが、ご安心ください。EC2ではCPU使用率といった基本的なメトリクスは、インスタンスを起動するだけで自動的に収集されるようになっています。
- CloudWatchを開いて「すべてのメトリクス」をクリックします。続いて「EC2」→「インスタンス別メトリクス」の順にクリックしてください。

CloudWatchのメトリクスを開くと、収集されているメトリクスがカテゴリごとに表示される
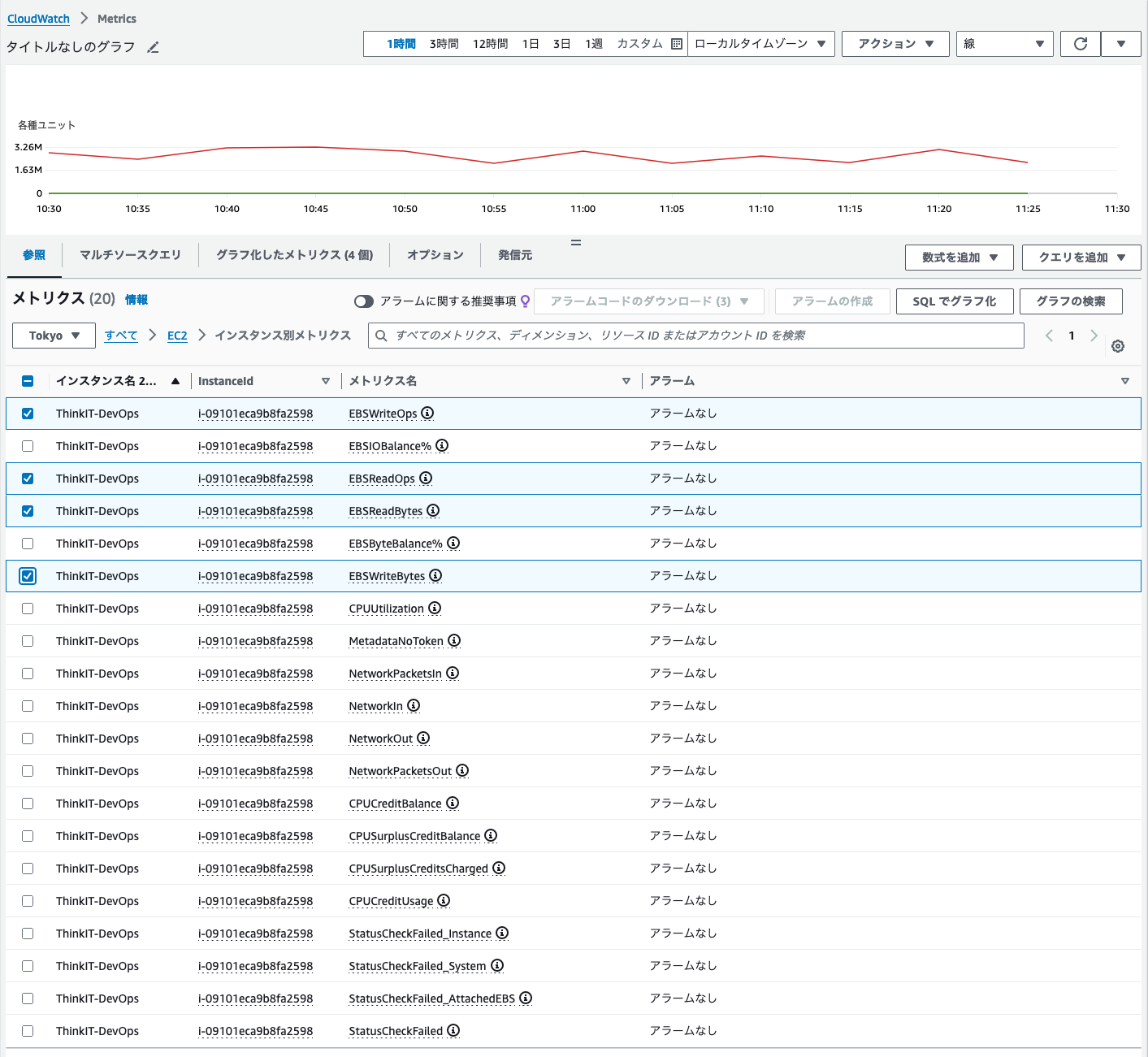
- 「インスタンス別メトリクス」を開くと、EC2インスンタンスのメトリクスがインスタンス別にリストアップされます。ここから表示させたいメトリクスにチェックを入れると、1つのグラフとして表示できます。

EBS(ブロックストレージ)のリードとライトの状況をグラフに重ねて表示してみた例
最近の多くのWebアプリは「ダッシュボード」と呼ばれる機能を備えています。本来は車の計器盤を指す言葉で、速度計や回転計、燃料計、水温計などが配置されており、ドライバーが車の状態を瞬時に把握するための装置です。Webアプリのダッシュボードも同様に、アプリの現在のデータを分かりやすく整理して可視化するためのインターフェイスです。ダッシュボードには様々なウィジェットやメトリクスを配置でき、ユーザーが自由にカスタマイズできるのが一般的です。
CloudWatchもダッシュボードを備えています。まず左ペインの「ダッシュボード」→「ダッシュボードの作成」から新しいカスタムダッシュボードを作成しておきましょう。そして、前述のようにメトリクスからグラフを作成したら「アクション」→「ダッシュボードに追加」でダッシュボードにグラフを配置できます。
以下は「CPUクレジットの残量と使用状況」「ネットワークの送受信トラフィック」「EBSのリードとライト状況」を表す3つのグラフを作成し、ダッシュボードに配置してみた例です。
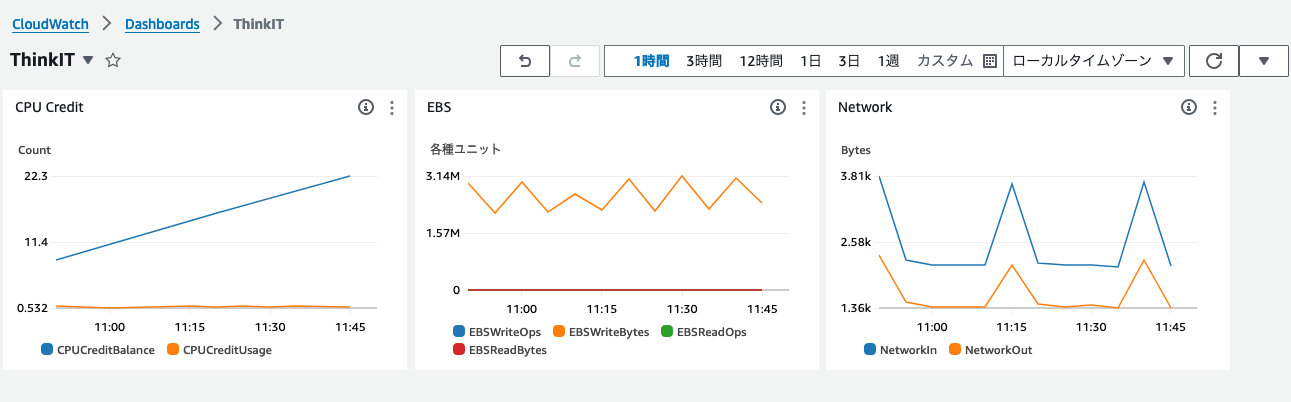
ダッシュボードを活用することで、自分にとって必要な情報だけを見やすく配置できる
CloudWatchは多くのメトリクスを取得しているため、都度必要なメトリクスを探すのは手間ですし、時間もかかります。システムの状況を把握しやすくするためにも、必要な情報だけを見やすく整理することを心がけましょう。なお、カスタムダッシュボードを利用するには別途料金がかかりますので、その点には注意してください。
より詳しい監視を行うには
一般的な監視ツールの利用経験がある方は、CloudWatchのメトリクスを見て「必要なメトリクスが足りない」と感じたのではないでしょうか。具体的にはサーバー監視でよくある「メモリ使用量」や「ディスク使用量」といったメトリクスが存在しません。
先ほど「EC2を起動しただけで自動的に監視が始まる」と述べましたが、実は標準で監視される項目は非常に限定されています。より詳細なメトリクスを収集したい場合は、EC2インスタンスに「CloudWatchエージェント」をインストールする必要があります。
- まず、前準備としてCloudWatchへ情報を書き込める権限をEC2インスタンスに付与します。AWSのドキュメントを参考にして「CloudWatchAgentServerPolicy」ポリシーがアタッチされたロールを作成してください。

作成したロール
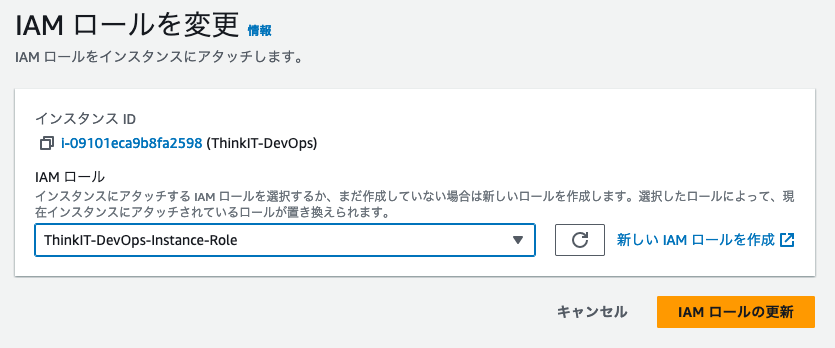
- EC2インスタンスの一覧でインスタンスを選択して「アクション」→「セキュリティ」→「IAMロールを変更」をクリックします。アタッチするIAMロールを選択するページに遷移しますので、先ほど作成したロールを選択してください。

CloudWatchに書き込めるポリシーを持ったロールを、インスタンスにアタッチする
- 続いてインスタンスにログインし、CloudWatchエージェントと、将来的にカスタムメトリクスを収集できるようにcollectdをインストールしておきます。以下のコマンドを実行してください。
$ sudo dnf install amazon-cloudwatch-agent collectd $ sudo systemctl enable --now collectd.service - CloudWatchエージェントの設定は、対話的なウィザードを使って行います。以下のコマンドを実行してください。
ほとんどの設定はデフォルトのままで良いのですが、今回はログ監視を行わず、System Managerのパラメータストアも使用しないように設定しました。収集するメトリクスセットとしては、最も詳細な「Advanced」を選択しています。ウィザードの詳細はドキュメントを参照してください。$ sudo /opt/aws/amazon-cloudwatch-agent/bin/amazon-cloudwatch-agent-config-wizard - ウィザードによって作成された設定の雛形は「/opt/aws/amazon-cloudwatch-agent/bin/config.json」に保存されていますが、実際にCloudWatchエージェントのプロセスは「/opt/aws/amazon-cloudwatch-agent/etc/amazon-cloudwatch-agent.d/」以下から設定を読み込みます。そこで以下のコマンドを実行すると、設定を反映した後にCloudWatchエージェントのサービスを起動します。
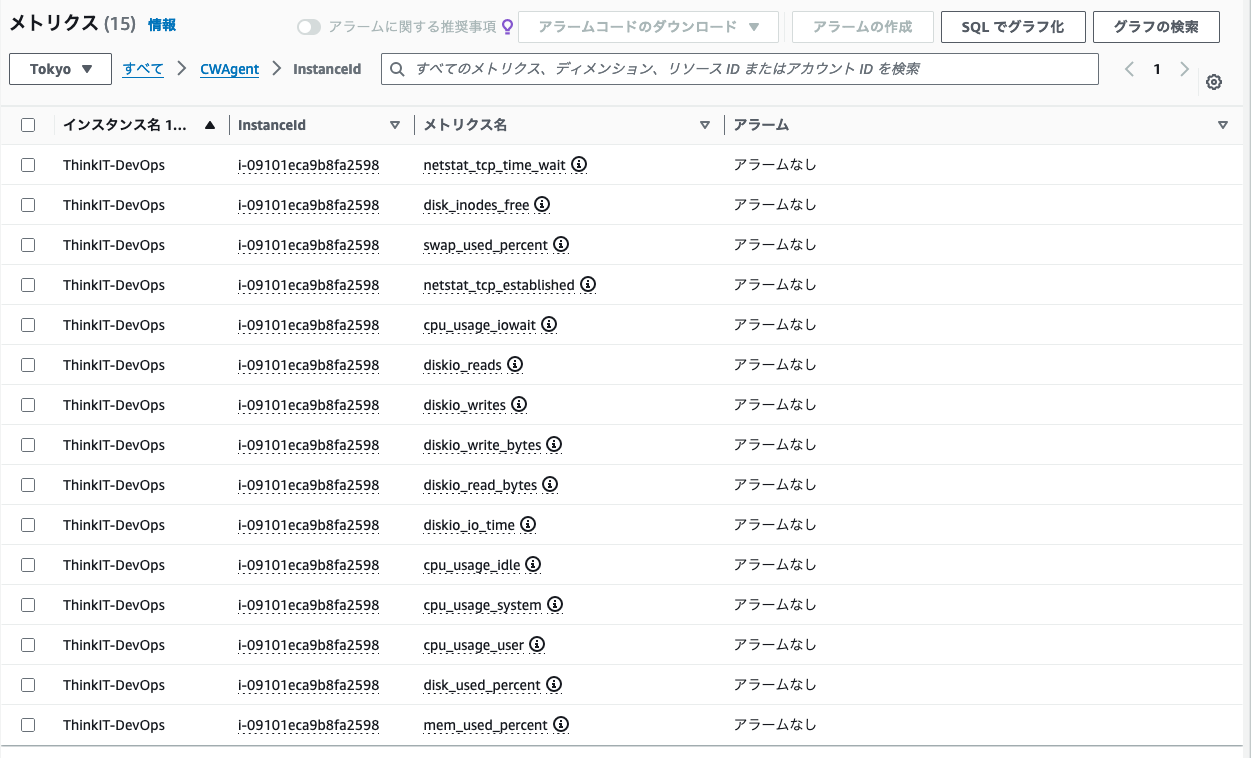
$ sudo /opt/aws/amazon-cloudwatch-agent/bin/amazon-cloudwatch-agent-ctl -a fetch-config -m ec2 -c file:/opt/aws/amazon-cloudwatch-agent/bin/config.json $ sudo systemctl enable --now amazon-cloudwatch-agent.service - しばらく待つと、CloudWatchのメトリクスに「CWAgent」というカスタム名前空間が表示されます。CloudWatchエージェントが収集したメトリクスは、その中に集められています。
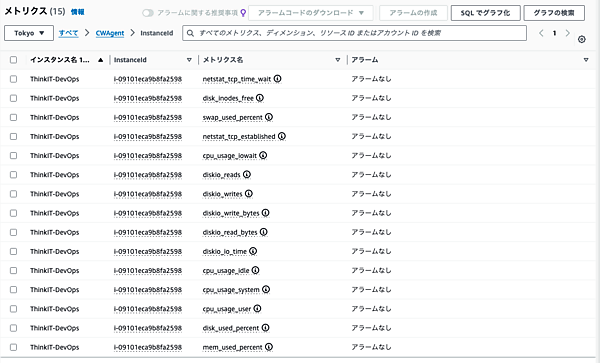
インスタンスIDごとに、CPU使用の内訳や、メモリ使用率、ディスク使用率といったシステムレベルのメトリクスが収集されている

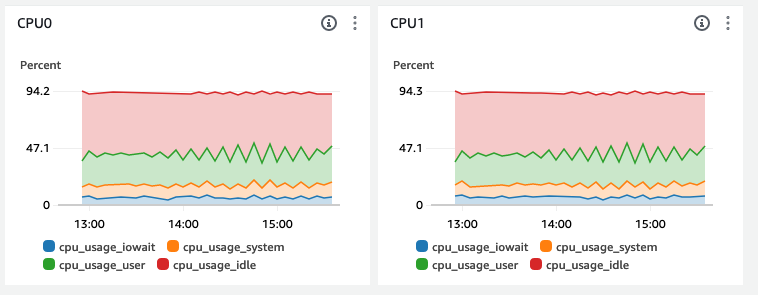
コアごとのCPUの利用状況を詳細なグラフにし、ダッシュボードに表示してみた例
アラームの設定
メトリクスは見られるようになりましたが、それだけでは不十分です。異常が発生したときに気づけるよう、監視したい項目にはアラームを設定しましょう。ここでは例として、データベースサーバーなどでありがちな、サーバーのストレージが枯渇したときのアラームを設定してみます。
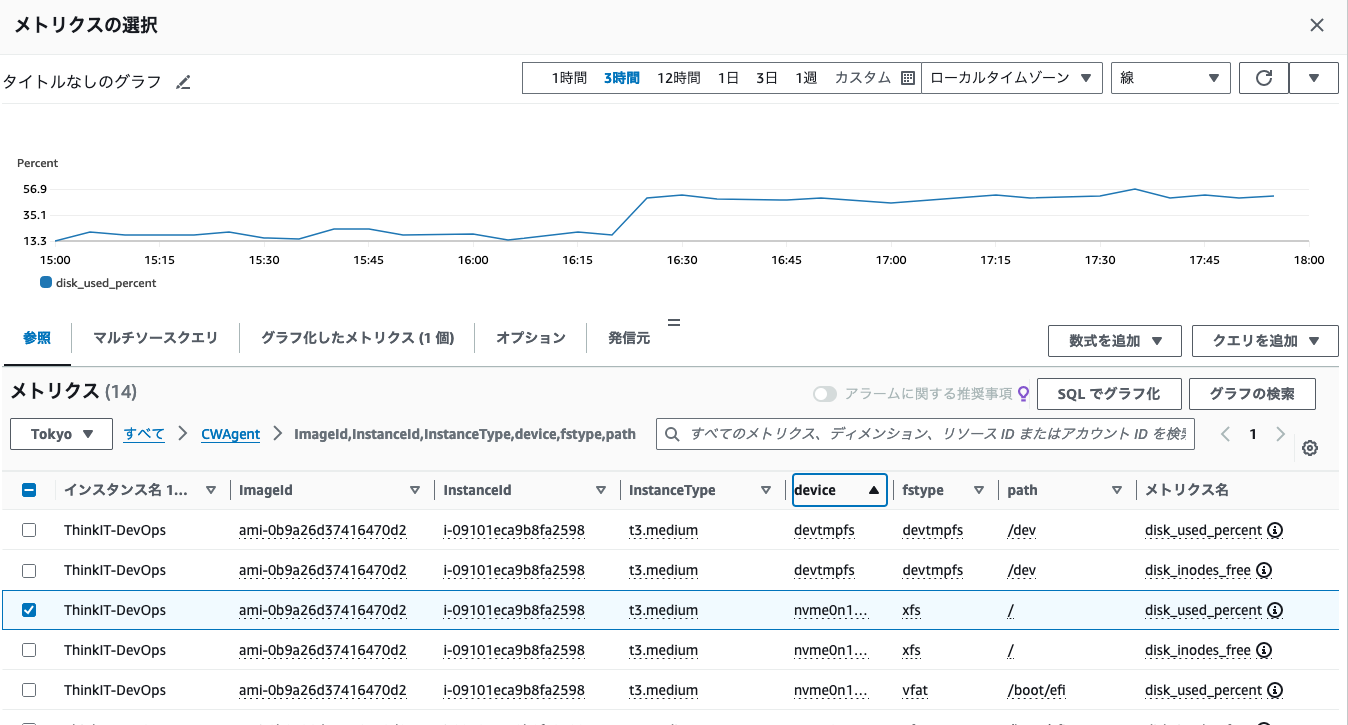
- まずCloudWatchの左ペインから「すべてのアラーム」を選択し、「アラームの作成」をクリックします。対話的なアラームの設定が開始するので、まずはアラームのトリガーとなるメトリクスを選択します。「メトリクスの選択」をクリックし、CloudWatchで収集しているメトリクスを選択してください。
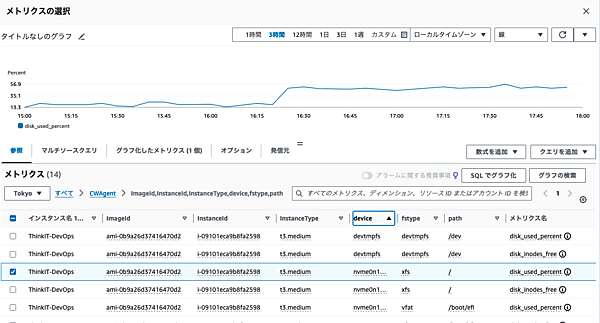
今回はストレージの容量を対象とするアラームなので、CloudWatchエージェントが収集しているメトリクスのうちサーバーのルートディレクトリの「disk_used_percent」を選択した
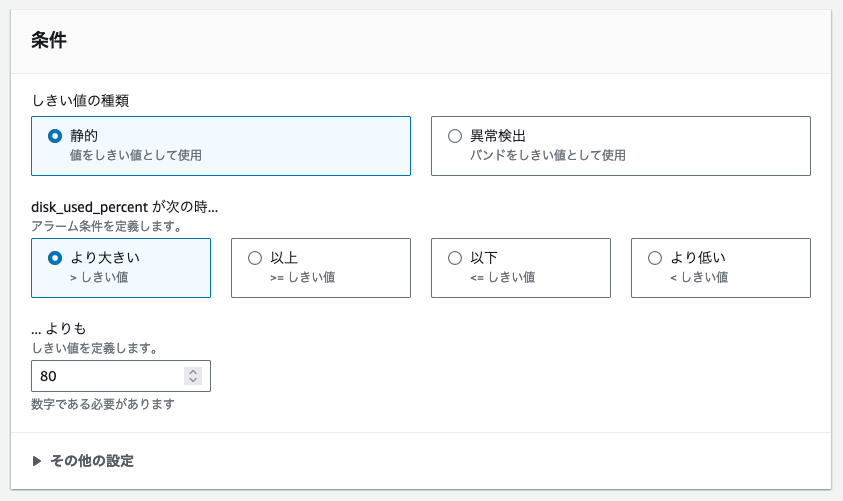
- 続いて、アラームが発生する条件を設定します。

選択したメトリクスが「ディスクの使用量」のため(「空き容量」ではないため)しきい値を80(%)より大きいとした
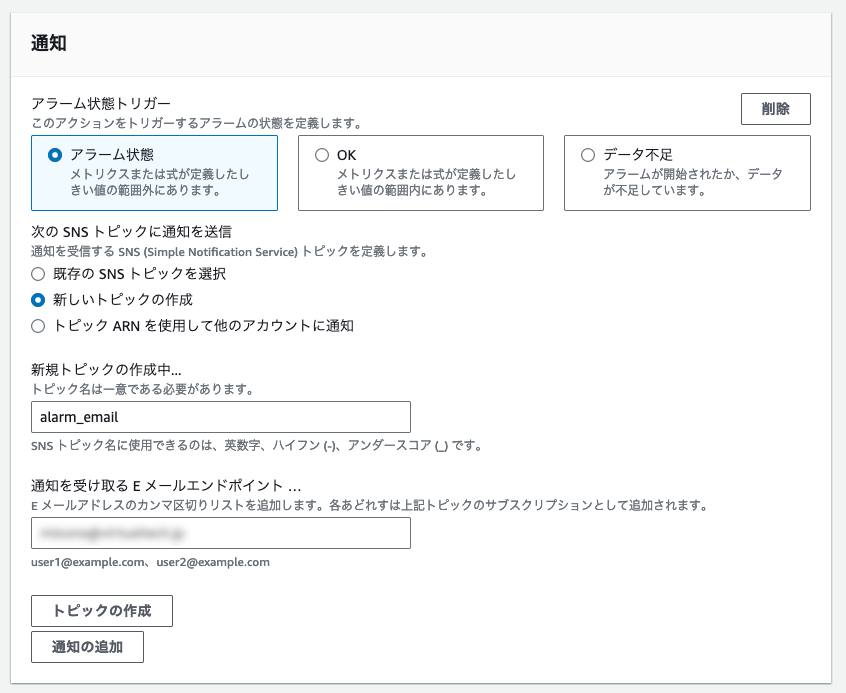
- 通知先を設定します。通知にはAWSのSNSを利用するため、SNSトピックが必要です。今回は特定のメールアドレス宛てに通知する新規トピックを作成しました。もちろん既存のトピックを使うこともできます。
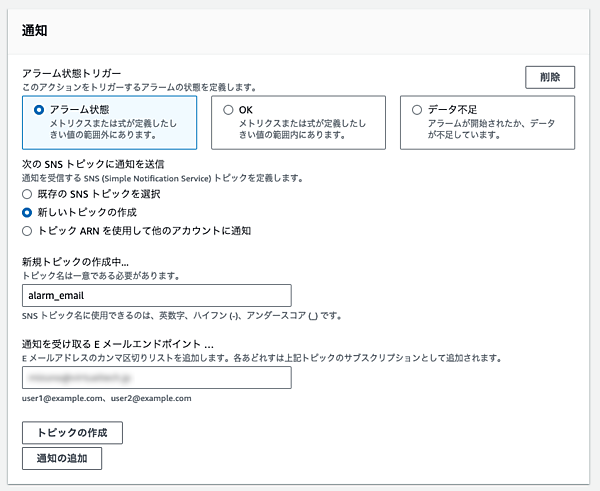
トピックの名前と通知を受け取るメールアドレスを入力して「トピックの作成」をクリックするとメールアドレス宛てに確認のメールが送信される。指示に従ってconfirmのリンクをクリックしておく必要がある
- 最後にアラームに名前を付けて完了です。

アラームは複数作ることになるため、分かりやすい名前を付けておこう
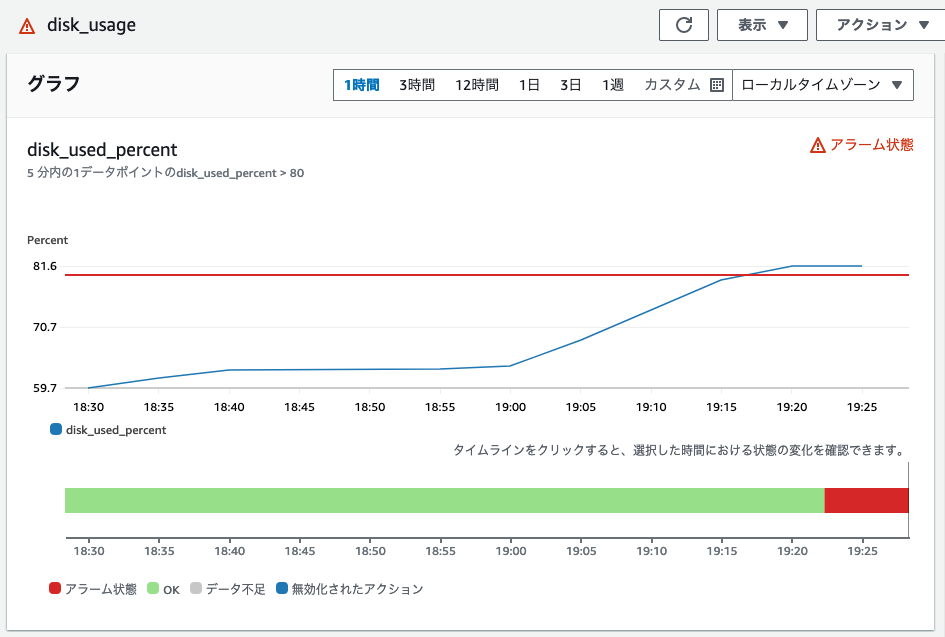
- これでディスク使用量が80%を越えたときにアラームが発生します。

急激にサーバーのストレージが消費されはじめた例。このままではストレージが枯渇してサーバーが停止してしまう可能性もあるが、80%を越えた時点でアラームにより異常に気づくことができた
おわりに
今回は、これから監視をはじめる方向けに、AWSにおける基本的なメトリクス監視の方法を紹介しました。メトリクスを収集し、アラームを設定するだけであれば、AWSの基本的な機能だけで簡単に行えることが理解できたのではないでしょうか。
ここで紹介した内容は、EC2インスタンスの情報を集めて監視する、いわゆる「内部監視」ですが、実際にサービスを運用する場合はユーザーに正しく応答を返せているのかを監視する「外部監視」が必須となるでしょう。実はCloudWatchにはスクリプトを実行してAPIを外部から監視する「CloudWatch Synthetics」という機能が用意されています。
この機能については名前の紹介に留めますが、詳しくはドキュメントを読んでみてください。
また、CloudWatchエージェントはメトリクス以外にもログファイルやAWS X-Rayのトレースを収集することもできます。オブザーバビリティ的な観点から見ると、収集するデータはメトリクスだけでは不十分です。こうした機能もあることを念頭に置いて、より高度な監視システムを考えてみてください。
この記事をシェアしてください
バックナンバー
この記事の筆者
筆者の人気記事
クラウドネイティブ開発で注目されるPlatform Engineering、チーム作りから環境構築までのポイントを知る
2024年1月30日 6:45
開発環境としてのハードウェア、開発マシンについてのイロイロ
2016年8月18日 8:43
新たな自動化で熱視線! AIエージェントの「推論能力」を支える2つのコンポーネントとは?
2025年11月28日 6:30
クラウドのコスト最適化を推進する“3要素” ─NECが見据えるFinOpsへの到達法とは
2024年1月26日 6:30
AWSの監視サービス「CloudWatch」でサーバー監視を試してみよう
2024年8月9日 6:30
生成AIの企業活用推進のため「一般社団法人Generative AI Japan」発足、共創の場作りと政策提言を目指す
2024年1月17日 17:40
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
