App Engineには、トランザクション処理に対する制約があります。例えば、複数エンティティを対象とするトランザクション処理は、原則行うことができません。例外的に、複数エンティティ間に所有・被所有(親子)の関係がある場合に限ってトランザクション処理が有効です。
今回は、最初にApp Engineインターナルにおけるデータ・ストア書き込みサイクルを解説し、次にLow-Level APIを使った所有・被所有(親子)関係の生成、およびトランザクション処理を解説します。
1. データ・ストアの書き込みサイクル
Bigtableに対するデータの書き込みは、JavaによるJDOJPAやLow-level API、またはPythonでのメソッド実行によって行われます。では、このとき内部ではどのような処理が行われているのでしょうか。ここでは、App Engineを例に、分散KVSでの書き込みによる内部処理を解説します。
|
|
| 図1: Bigtableにおける書き込みサイクル(クリックで拡大) |

図1は、Bigtableにおける書き込みサイクルを図で表したものです。
[Bigtableにおける書き込みサイクル]
①ユーザー・プログラムから書き込みのメソッドが実行されると、データ・オブジェクトはプロトコル・バッファでシリアライズされ、送信データはバイナリのバイト・コードに変換されます。
②次に、アプリケーション・サーバーは、プロトコル・バッファでシリアライズされたエンティティ・データを引数にセットして、データ・ストア・サーバーに対してRPCコールを実行します。
- JDOなどの汎用APIだけでなく、Low-level APIの場合も、その上にラッピングされたAPIを使ってデータの書き込み処理を行うため、プロトコル・バッファにおけるシリアライズ処理やRPCコールをユーザー・プログラム・レベルから意識することはありません。
- エンティティのキーは、ユーザーが文字列で指定しない場合は、システムがlong型で生成します。この場合、エンティティ・キーは、次のような構成になります。
- アプリケーションID | 親エンティティのキー | kind名 | ユーザー指定のキー名またはID
データ・ストア・サーバーは、クライアントから送られてきたデータ処理を担当するタブレットを識別し、そのタブレット・サーバーに対してリクエストを、
④コミット(commit)フェーズ、
⑤アプライ(apply)フェーズ
の、2つの処理ステップで実行します。
[App Engineデータ・ストアとテーブル生成手順]
|
|
| 図2: App Engineデータ・ストアとテーブル生成手順(クリックで拡大) |
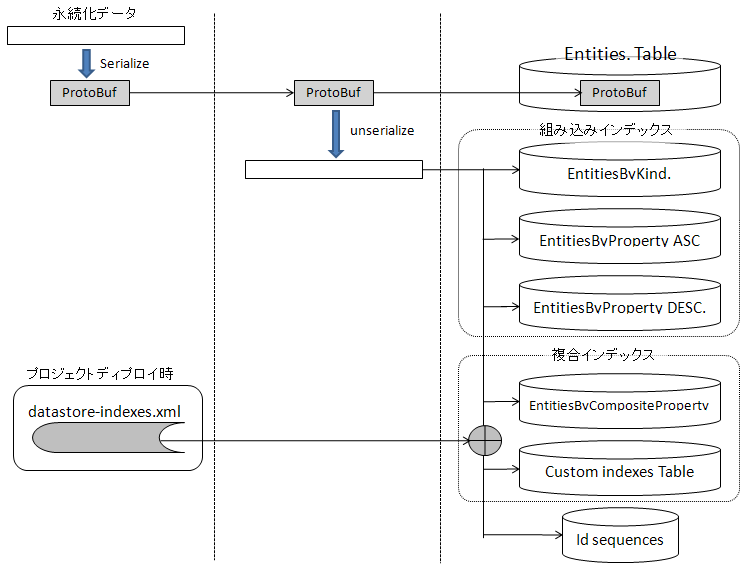
図2は、App Engineデータ・ストアへのデータ書き込みと、テーブル生成手順の概要を表わしています。
永続化(登録)データは、Protocol Buffersでシリアライズされてからサーバーに送られ、そのままバイナリ・フォーマットでEntities.Tableに登録されます。これと同時に、バイナリ・データは、アンシリアライズされてインデックス用のBigtableに追加登録されます。
EntitiesByKind.、EntitiesByProperty ASC、EntitiesByProperty DESCの各テーブルは、そのEntities.Tableに対して作成された検索条件に関係なく標準で作成されるテーブルです。新しいユーザー・データのエンティティ登録と並行して、これらのテーブルに対するエンティティ項目の登録が行われます。
これに対して、EntitiesByCompositePropertyとCustom indexes Tableは、参照プログラムを用いたデータ検索時に、複数のプロパティ項目を条件指定の対象とする場合に限って生成されるインデックス・テーブルであり、カスタム・インデックスと呼ばれます。これらのテーブルは、クラウド環境へのプロジェクト・ディプロイ時に、Javaの場合はdatastore-indexes.xml(自動生成ではdatastore-indexes-auto.xml)、pythonの場合はindex.yamlのアップロード・データから生成されます。
このように、ユーザー・エンティティの登録処理では、サーバーに送信されるのはバイナリ・フォーマットにシリアライズされているデータだけであり、そのままEntities.Tableに登録されるため、データ送信から永続化までの処理効率向上が行われています。
また、送信されたデータから検索用のさまざまなインデックスが作成されますが、これらの処理はサーバーでアンシリアライズされたデータを使用して行われるため、ユーザー・エンティティの登録処理自身には影響を与えないはずです。
[データ・ストア書き込みプロセス]
App Engineのデータ・ストア書き込みプロセスは、2つのマイルストーンで考えられています。
①最初のマイルストーンAは、エンティティに対する変更が適用される時点で、
②次のマイルストーンBは、そのエンティティのインデックスに対する変更が適用される時点です。
つまり、Protocol Buffersフォーマットにシリアライズされたユーザー・データのEntityテーブルへの書き込みが完了するのが、①のマイルストーンAで、標準インデックスや、必要な場合にはカスタム・インデックスへの書き込みが完了するのが、②のマイルストーンBということになります。
従って、ユーザー・テーブルへの書き込みとインデックス・テーブルへの書き込みには若干ズレが生じ、インデックス・テーブルへの書き込みが遅れることになります。このことから、書き込みとほぼ同時にエンティティの読み取りが行われるような場合には、次のような点に留意する必要があることが分かります。
エンティティに対する変更が適用される時点をマイルストーンA、エンティティのインデックスに対する変更が適用される時点(commit()が返される時点)をマイルストーンBと呼ぶことにします。
マイルストーンAに到達するときには、エンティティに対する変更はすべて適用済みとなっており、さらに、マイルストーンBに到達するときには、エンティティのインデックスに対する変更が適用済みとなっています*1。
- [*1] マイルストーンAに到達すると、エンティティは登録済みになります、従って、複合インデックスを使用する場合は、複合インデックス用のテーブル生成のために時間が余計にかかりますが、エンティティの登録時間にはまったく影響を与えません。筆者も、サンプル・プログラムを作成して確認しましたが、むしろ複合インデックス用のテーブルを作成する場合の方が、書き込みに要する時間が短くなる結果も出ています。
|
|
| 図3: エンティティ変更のマイルストーン(クリックで拡大) |

マイルストーンAに到達した後は、更新されたエンティティをそのキーで検索すると、必ず更新後の最新のエンティティが返されます。ただし、これと同時に発生したほかのリクエストによってクエリーが実行され、その述語(SQL/GQLの「Where句」)が更新前のエンティティではなく更新後のエンティティに合致する場合、そのエンティティが結果セットに含まれるのは、commit()処理がマイルストーンBに到達した後に実行されたクエリーだけとなります。
つまり、非常に短い間ですが、キーによる検索の結果として、プロパティがクエリーの述語に合致するエンティティが、結果セットに含まれない可能性があります。同様に、キーによる検索の結果として、プロパティがクエリーの述語に合致しないエンティティが結果セットに含まれる可能性もあります。
つまり、クエリーによってどのエンティティが返されるかが決まる前は、マイルストーンAとマイルストーンBの間にある変更をクエリーに反映することはできません。一方、クエリーによってどのエンティティが返されるのかが決まった後は、常にマイルストーンAの時点のエンティティが返されます。
データ・ストアへの書き込みでは、書き込み対象のエンティティ・データをエンティティ・グループのログに書き込み、その後に書き込まれたログ・データにcommited(コミット済み)のマークを付けます。
その後、エンティティとインデックスの行データがハード・ディスクに並行処理で書き込まれます。エンティティを構成するプロパティによっては、インデックスの数が相当大きな数になる場合もあります。データ・ストアでは、アクセスするアプリケーションによって設定される複合インデックスが問題なく設定されているかどうかをチェックします。
書き込みと読み取りがほぼ同時に行われた場合、データ・ストアからクエリーまたはget()によって取得されるエンティティには、コミットされたデータだけが含まれ、部分的にコミットされて取得されたデータがエンティティに含まれることはありません。つまり、一部はコミット済みで一部はまだコミットされていない、という状態になることはありません。
2. 所有・被所有関係とトランザクション処理
App Engineのデータ・ストアでは、1つのエンティティに対するトランザクション処理、例えば数値プロパティのインクリメント処理などは利用できますが、複数のエンティティ項目を含むようなトランザクション処理は利用できません。
エンティティ項目が複数になる場合、それぞれのエンティティはチャンク(一定サイズ毎のデータ格納エリア)ごとに分散配置される可能性が出てきます。App Engineのような大規模分散システムでは、チャンク間の距離などによる制約から、ACID特性を維持できる限界を超えてしまうからです。この場合、巨大分散システムでの制約として知られているCAP定理およびBASE理論が適用される領域になってきます。
ただし、トランザクション処理を不可能にしている制約要件が「距離」によるものなので、この制約を外してしまえば、トランザクション処理も可能になるはずです。そして、この制約を外す方法として、エンティティ間の所有・被所有関係があります。
複数のユーザー・テーブル(Bigtable)間に、所有・被所有の関係を持たせた場合は、それらのデータ・オブジェクトは、分散ネートワーク上の同じエリア(チャンク)に格納されることになります。トランザクション処理において、単一性・一貫性を持ったデータ操作を行うことが可能になります。
- この記事のキーワード
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
