Observability Conference 2022から、求人向け検索エンジン及び広告配信を展開する株式会社スタンバイのセッションを紹介する。セッションを行ったのはスタンバイのSRE(Site Reliability Engineering)チームの小林良太郎氏だ。
動画:マイクロサービスアーキテクチャな組織、システムにSLOを導入している話
小林氏は「オブザーバビリティとは何か」「SLO/SLI」とは何かに続いて、オブザーバビリティの目的について解説を行った。特に単に観測を行うだけではなく「観測することでどんな課題を解決するのか?」を明確にすることが必要だと強調。ビジネスを運用する経営の側面から見れば、ITエンジニアが新しいオモチャを手に入れたような状況になるのは好ましくないと説明した。

わかりやすい例でSLO/SLIを解説
このスライドではSLO(Service Level Objective)とSLI(Service Level Indicator)について解説を行った。ここでは例としてSLIはWebサーバーのエラーレート、Webサーバーが目指すべき正常運転の目標などを使って説明している部分に小林氏の経験が表れていると言える。
またオブザーバビリティについても、Twitterにおける事例やマイクロサービスにおいてログの肥大化が問題視されていることでログ、メトリクス、トレーシングなどが見直されていることなどにも触れた。

オブザーバビリティとは何か?
またオブザーバビリティとSLOの関係について、オブザーバビリティソリューションを提供するベンチャー企業であるHoneycombのブログ記事を引用して紹介し、SLOを導入することでオブザーバビリティの成熟度が高まり、結果としてシステムを構築運用するエンジニアと顧客の双方をハッピーにすることができると図を用いて説明した。
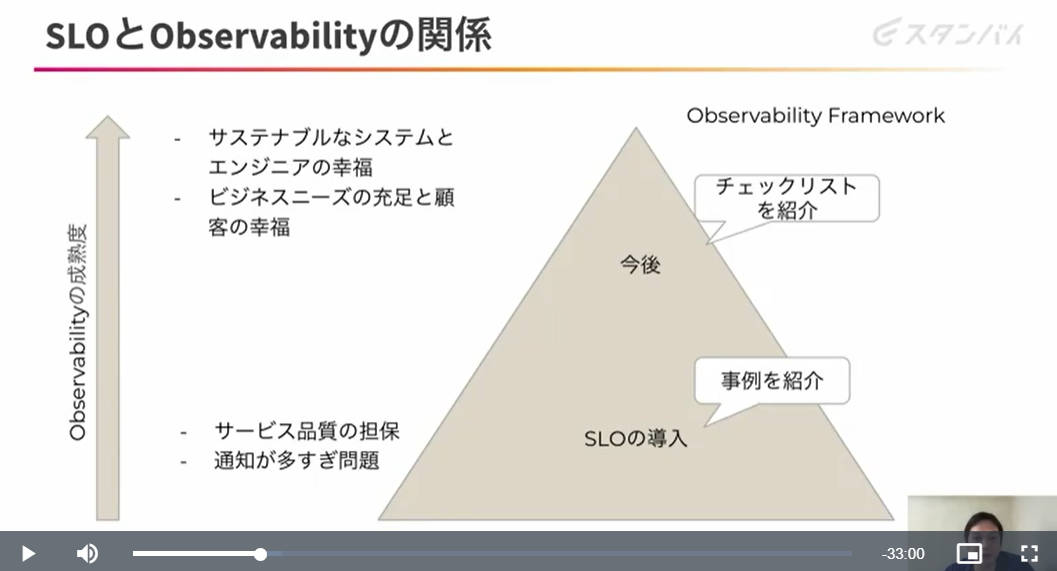
オブザーバビリティの成熟度とエンジニアと顧客が幸せになる関係
ここでスタンバイの事業の解説及びAWS上に実装されているシステムの概略を説明した。
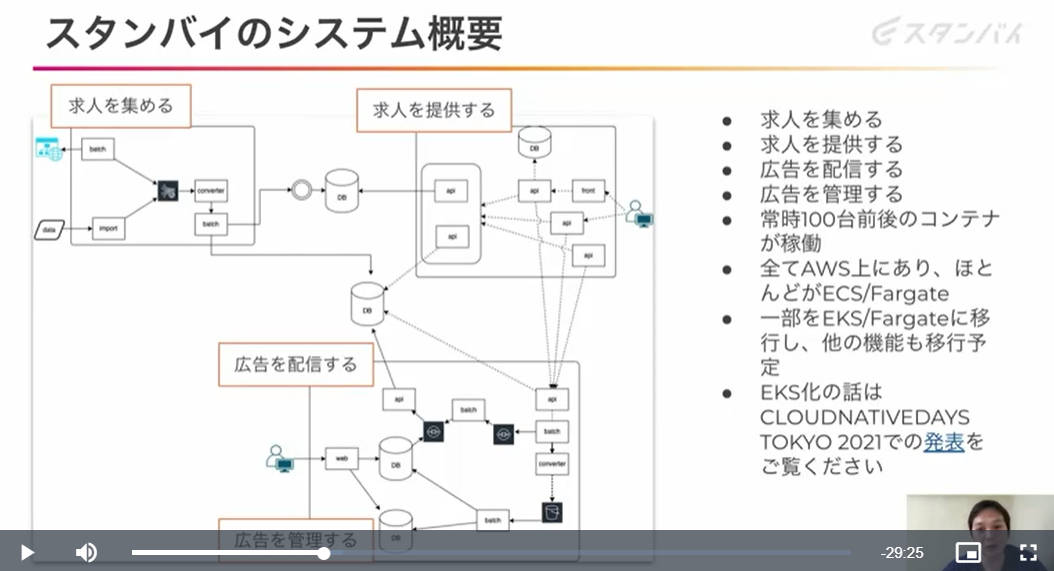
AWSに実装されているスタンバイのシステム
AWS上に構築された求人向けエンジンと広告配信システムは2014年頃から存在していたとして、ECS及びサーバーレスのコンテナ実行環境であるFargateで実装されていることを紹介した。さらに一部のシステムはAWSのKubernetesのマネージドサービスであるEKSにも移行されているという。
ここでSLOを実現するためにGoogleが始めたエラーバジェットについても言及し、その仕組がスタンバイ社内においても使われていることを紹介した。このエラーバジェットとは「機能の開発と信頼性の向上の間でエンジニアリングチームが費やす時間の優先度のバランスを取るためのツール」とGoogleのブログで紹介されている。機能開発と運用の信頼性をバランスさせるために、どこまで異常を許容できるかを開発者と運用担当者が確認するために数値だ。スタンバイでは開発のスプリントが水曜日始まりであることに合わせて、水曜日から起算して翌火曜日までのエラー数をエラーバジェットとしているという。またエラーバジェットを使い切ってしまった場合(つまり想定した以上に対象アプリケーションがエラーを発生して停止してしまった場合)には、新規の機能開発を中止して信頼性回復(つまり原因究明と修正)を行うこと、緊急の場合は個別に判断するが必ず振り返り(ポストモーテム)を関係するチーム全員で行うことなどが定められたと説明した。当初のルールは、このように決められた。
ここで「Nines don't matter if users aren't happy」というこれもHoneycombのブログのキャチコピーを引用して「稼働率がどんなに上がっても(99.99%のように)ユーザーがハッピーでないなら意味がない」というのがこのセッションで一番覚えてもらいたいことだと説明した。

「9をどれだけ並べてもユーザーがハッピーにならないなら意味がない」
ここからは具体的にこれまでのSLOの計測および監視方法、アラートの処理フローなどを説明した。これは当初の内容であるとして、いわば使用前/使用後を語る際の使用前の内容となる。

当初のSLO運用ルールにどんな課題が表出したのかを説明
アラートには各チームが協力して対応する、エラーバジェットは定期ミーティングで報告する、エラーバジェットが枯渇した場合はリリース禁止などの要点が、実際の運用においては問題点となったことを説明している。

エラーバジェットの運用にも問題点が明らかに
またSLOの定義と監視についても、KibanaとDatadog、Slack、Confluenceなどが活用されており、それぞれのツールは良いものの運用時には使い分けや欲しい情報がどこにあるのかを探す手間などが問題となったと説明。

ツールの運用にも問題が顕在化した
ここまでで当初のスタンバイのオブザーバビリティに関する問題点を整理したのが、次のスライドだ。

スタンバイ社のオブザーバビリティの問題点
これを解決するためにエラーバジェットはローリングウィンドウで起算日を設けないこと、SLOのオーナーを1チームとすること、SLOの作成もチームに任せることなどの変更を行ったと説明した。

SLO運用ルールの改善点
他にもアラートが発生した際のフローを見直し、「なるべく早く必要な人間がアクションを起こす」ことができるようになったと説明した。
ここではKibanaなどで行っていた可視化をすべてDatadogに統合して、観測の可視化、アラートからの対応、インシデント管理、ポストモーテムの実施までをDatadogのサービスを使って一気通貫で行えるように変更したことを説明した。
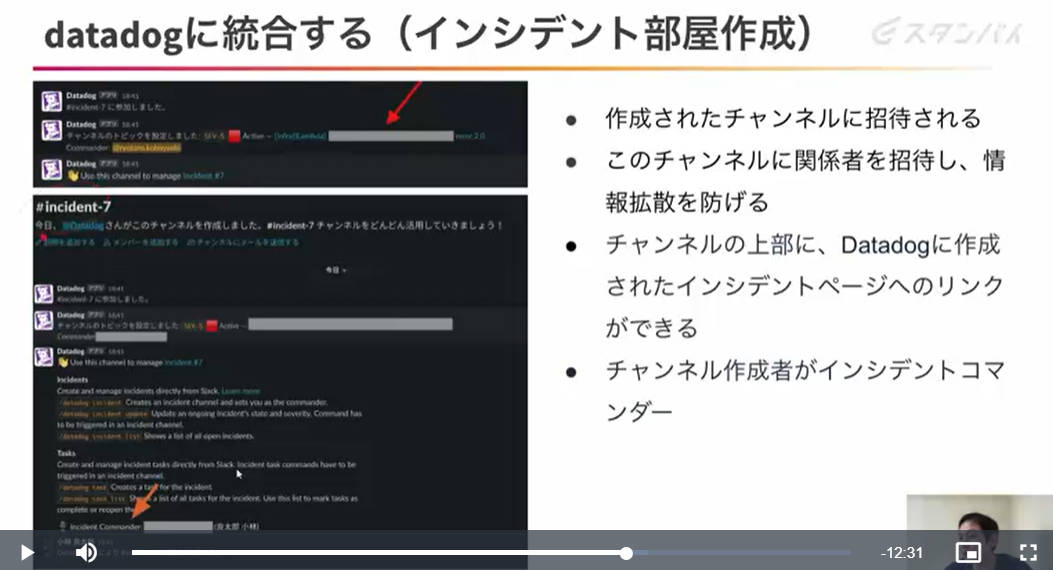
Datadogを使って関係者への連絡、インシデント管理、ポストモーテムまでを行う
当初のフローや役割分担を運用時の課題解決のために変更したことを当事者として説明した小林氏は、「今後の課題と目指すところ」というスライドを使って「SLOがある生活とは言っても単にエラーバジェットだけを見ることになってはいないか?」「他人が作った中身を知らないエラーバジェットだけを気にする生活に意味はあるのか?」「エラーと顧客のハッピーはどうやってバランスすればいいのか?」などの根源的な疑問を提示した。
またHoneycombのブログの「オブザーバビリティの成熟度」に立ち戻って「成熟度が低いとどういう現象に遭遇するのか?」を解説。ここでは単にシステムの中身の状況がわからないだけではなく、それによってどのようなことが起こるのかを解説した。

オブザーバビリティの成熟度が低いとシステムの回復性が損なわれる
ここでは単にシステムの状況だけではなく、システムに関与するエンジニアが疲弊することなどにも触れていることに注目したい。システムが信頼できないとエンジニアに発生する修復のための工数は飛躍的に増えてしまうことになる。
最後にまとめとして「重要なものは何か?」を常に意識する習慣を持つこと、ツールや環境を見直すことを継続すること、そして「システムに関わるエンジニアではなくユーザーが結果的にハッピーになっているか?」を意識することが重要だとしてセッションを終えた。

オブザーバビリティ改善のまとめ
新しいオブザーバビリティのシステムはオープンソースのKibanaから商用サービスのDatadogに統合したことで機能の連携が良くなり、結果的にインシデント管理、ポストモーテム管理などまで統合されていることにも注目するべきだろう。AWSを主体に使っているエンジニアには参考になる事例だろう。
なお途中で説明されたエラーバジェットの時系列における可視化の部分に利用されているKibanaのTimelion(タイムラインと発音するらしい)については以下を参照されたい。
関連記事
Observability Conference 2022、利用者目線のオブザーバビリティ実装をドコモのSREが解説
2022年6月21日 6:00
Observability Conference 2022から、サイボウズのオブザーバービリティ事例を紹介
2022年5月10日 6:00
CloudNative Days Tokyo 2023から、Yahoo! JAPANを支えるKaaS運用の安定化やトイル削減の取り組みを紹介
2024年3月11日 6:00
【CNDS2025】 数百万台のサーバーを守る仕組みを解き明かすマイクロソフトのSREとAIOpsの最新アプローチ
9月4日 6:00
Cloud Operator Days Tokyo 2021開催、New Relicとドコモのセッションを振り返る
2021年11月17日 6:00
CI/CD Conferenceレポート トレジャーデータのCI/CDのポイントはリリースリスクの最小化
2021年10月7日 6:00
バックナンバー
この記事の筆者

筆者の人気記事
SASEのCato Networks、CEOによるセミナーとインタビューを紹介
2020年4月16日 6:00
Rustのエコシステムの拡がりを感じるデスクトップアプリのためのツールキットTauriを紹介
2022年12月16日 6:00
Zabbix式オープンソースの秘密に迫る
1月31日 6:00
WebAssemblyとRustが作るサーバーレスの未来
2020年4月21日 6:00
エンタープライズLinuxを目指すSUSE、Red Hatとの違いを強調
2015年2月3日 19:00
RustとWASMで開発されKubernetesで実装されたデータストリームシステムFluvioを紹介
2022年12月23日 6:00
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
