はじめに
3-shakeのSreake事業部でインターンとして活動している小林(@moz-sec)です。第13回目の今回は、KubernetesのAPIトラフィックアナライザである「kubeshark」について紹介します。
kubesharkは、KubernetesのPod、Node、Clusterを出入りするすべてのトラフィックをキャプチャし、リアルタイムで可視化するツールです。

kubesharkとは
kubesharkは、WiresharkをKubernetesのためにカスタマイズしたツールです。kubesharkを使うことでトラフィックの分析が可能になり、インシデントの迅速な解決を支援します。
また、REST、GraphQL、gRPC、Redis、Kafka、RabbitMQ(AMQP)、DNSなどといった幅広いプロトコルをサポートしています。
ノード数が4台以下のクラスターであれば無料で利用できますが、それ以上の場合はライセンスが必要です。ライセンスについては、こちらをご覧ください。
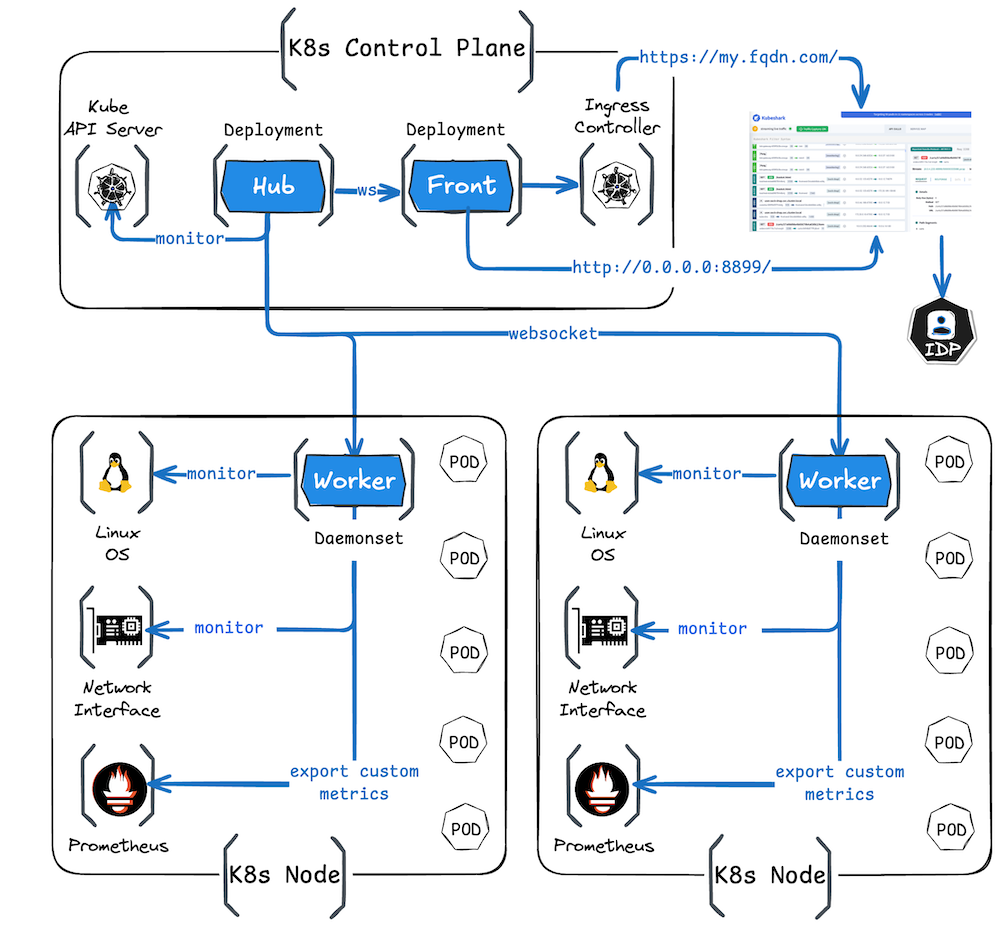
kubesharkの仕組みとしては、Helmを使用してworker 、hub、frontの各Podを作成し、分析する際にはfront Podにアクセスします。workerはDaemonSetとしてデプロイされ、そこでキャプチャしたデータをhubに転送して1つのストリームに統合し、frontで可視化します。
workerにはSnifferコンテナとTracerコンテナの2つが含まれます。SnifferコンテナはAF_PACKETまたはeBPFを使用してパケットキャプチャを行い、TracerコンテナはeBPFを使用してユーザ空間とカーネル空間をトレースします。TLSで暗号化されたトラフィックについてはOpenSSLやGoのcrypt/tlsパッケージの特定の関数をフックして、暗号化前のデータをキャプチャします。
基本的な使い方
kubesharkのインストール方法は、CLIとHelmの2通りがあります。本記事では、CLIでの使い方について解説します。筆者の環境はMacBookであるため、Homebrewでkubeshark CLIをインストールします。
$ brew install kubeshark今回はkindを使ってクラスタを構築し、GuestbookとBookinfoアプリケーションをguestbookおよびbookinfo Namespaceにデプロイしました。kindについては第6回をご覧ください。
kubeshark tapを実行することでトラフィックのキャプチャが開始されます。その後、ブラウザで http://127.0.0.1:8899 にアクセスするとダッシュボードが表示されます。
$ kubeshark tap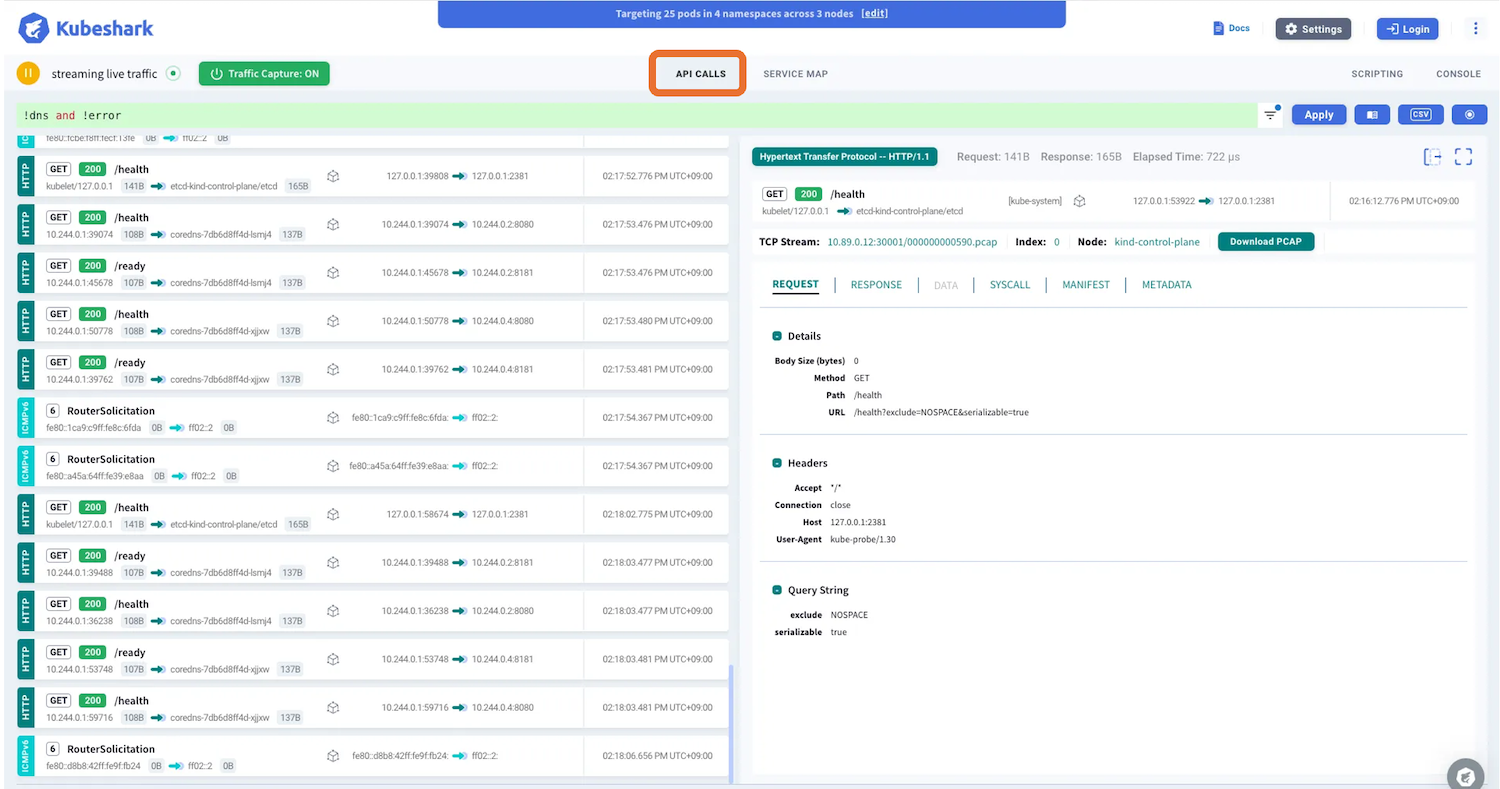
ダッシュボードには、API CALLSとSERVICE MAPの2つのセクションがあります。
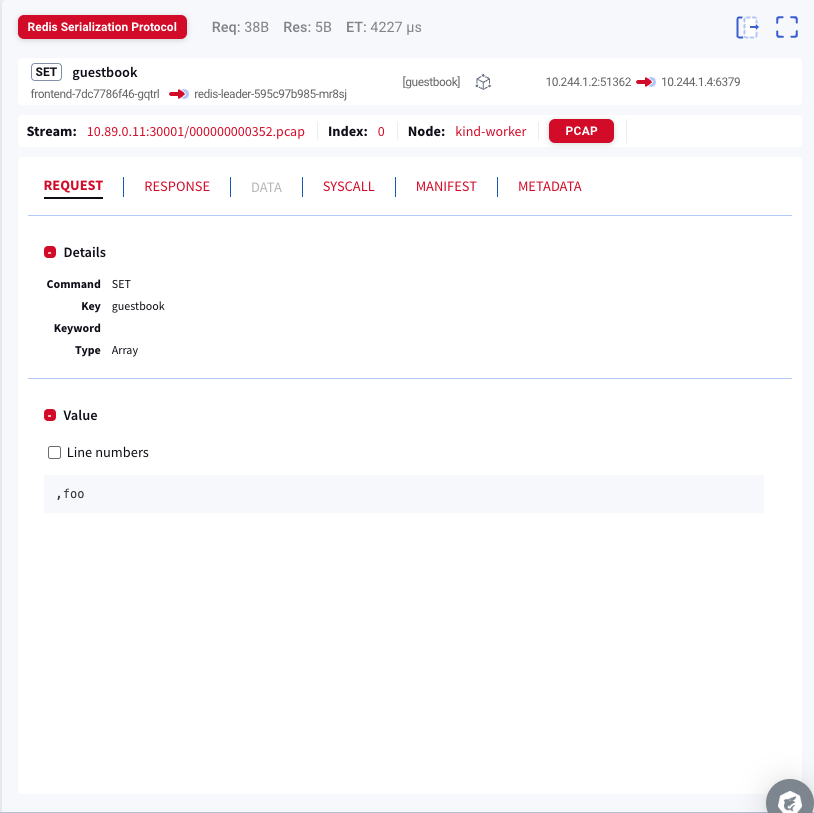
1つ目のAPI CALLSでは左側にTCPストリームやUDPデータグラムごとのトラフィックが表示され、選択した項目に応じて右側にリクエストやレスポンス、パケットデータやシステムコールなどが表示されます。表示される情報はプロトコルによって異なります。例えば、HTTPやRedisの場合はリクエストやレスポンス、システムコールの詳細を確認できます。
ICMPではリクエストやレスポンスは表示されず、データのみが確認できます。
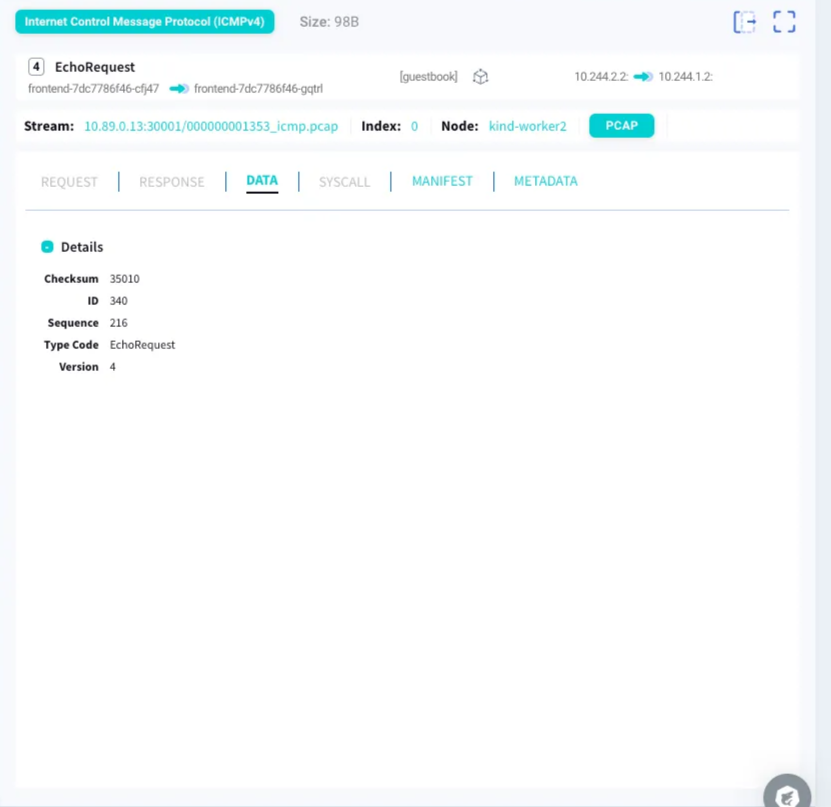
kubeshark tapを[Control]キー+[C]キーで終了した場合はセッションが切れるため、再度ダッシュボードを開くにはkubeshark proxyを実行します。
$ kubeshark tap
^C
$ kubeshark proxy3ノードでクラスタを構築している場合、kubesharkをデプロイすると以下のようになります。
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
kubeshark-front-cbc6484f9-892x8 1/1 Running 0 1m17s
kubeshark-hub-64b6fc94b5-4w4pr 1/1 Running 0 1m17s
kubeshark-worker-daemon-set-6bt8h 2/2 Running 0 1m17s
kubeshark-worker-daemon-set-9nsqp 2/2 Running 0 1m17s
kubeshark-worker-daemon-set-hbzl8 2/2 Running 0 1m17sダッシュボードではKFL(Kubeshark Filtering Language)でフィルタリングして表示できます。これはWiresharkのディスプレイフィルターに似た機能で、キャプチャ自体はすべてのトラフィックに対して行い、表示する際にフィルタリングが行われます。
デフォルトでは!dns and !errorのフィルターが適用されており、例えば、!dns and !error and dst.namespace == "bookinfo"と記述することでbookinfo Namespaceのトラフィックのみ表示できます。
2つ目のService MapではPodやService間の接続、帯域幅、プロトコルをグラフで視覚的に表示できます。
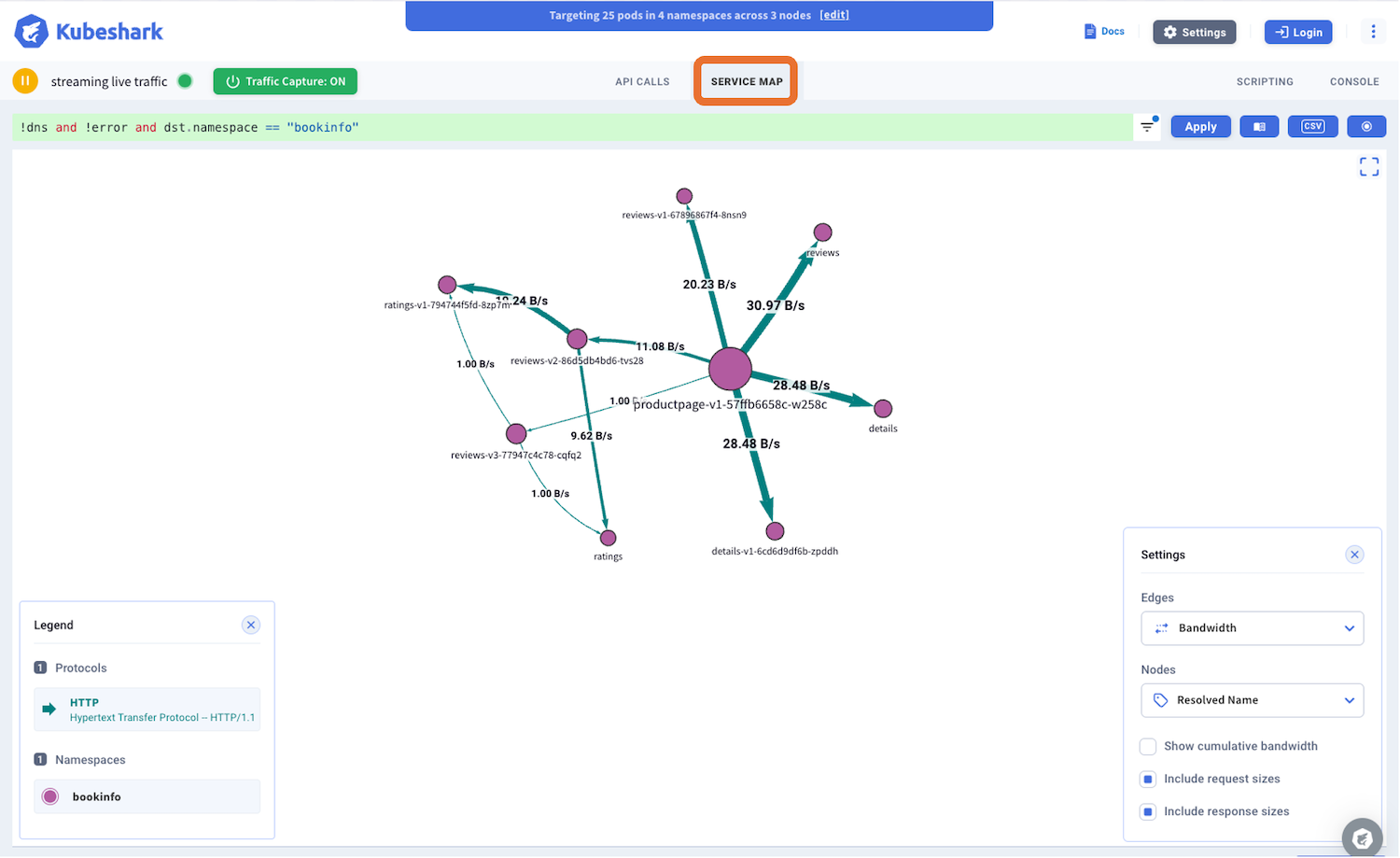
kubesharkを停止するにはkubeshark cleanを実行します。このコマンドにより、Helmを使用してworker、hub、frontの各Podが削除されます。
$ kubeshark cleanキャプチャフィルター
kubesharkが使用するCPU、メモリ、ストレージの消費量は処理するトラフィック量に比例するため、フィルタリングして特定のトラフィックのみをキャプチャすることはリソース管理の観点で重要です。
KFLを用いたフィルタリングは表示するパケットを絞り込むだけであり、キャプチャするパケットの量には影響しません。そのため、この方法ではリソース消費量は変わりません。
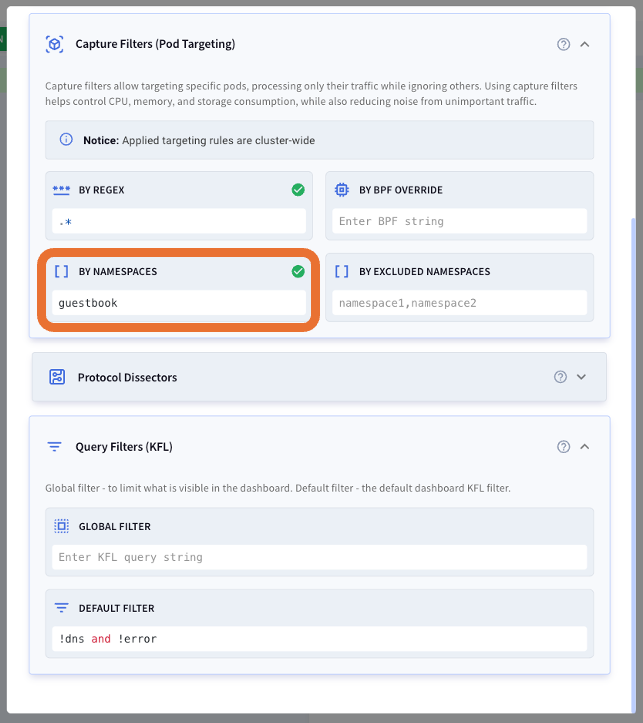
一方キャプチャフィルターでは、キャプチャするパケット自体をフィルタリングするためリソース消費量を削減できます。キャプチャフィルタではPodやNamespaceでトラフィックを絞り込むことができます。
実際にguestbook Namespaceに絞ってキャプチャを行なってみます。
下図はフィルタリング前とフィルタリング後のキャプチャ状況を比較したものです。フィルタリング後は、キャプチャ対象となるPodの数が減少していることが確認できます。
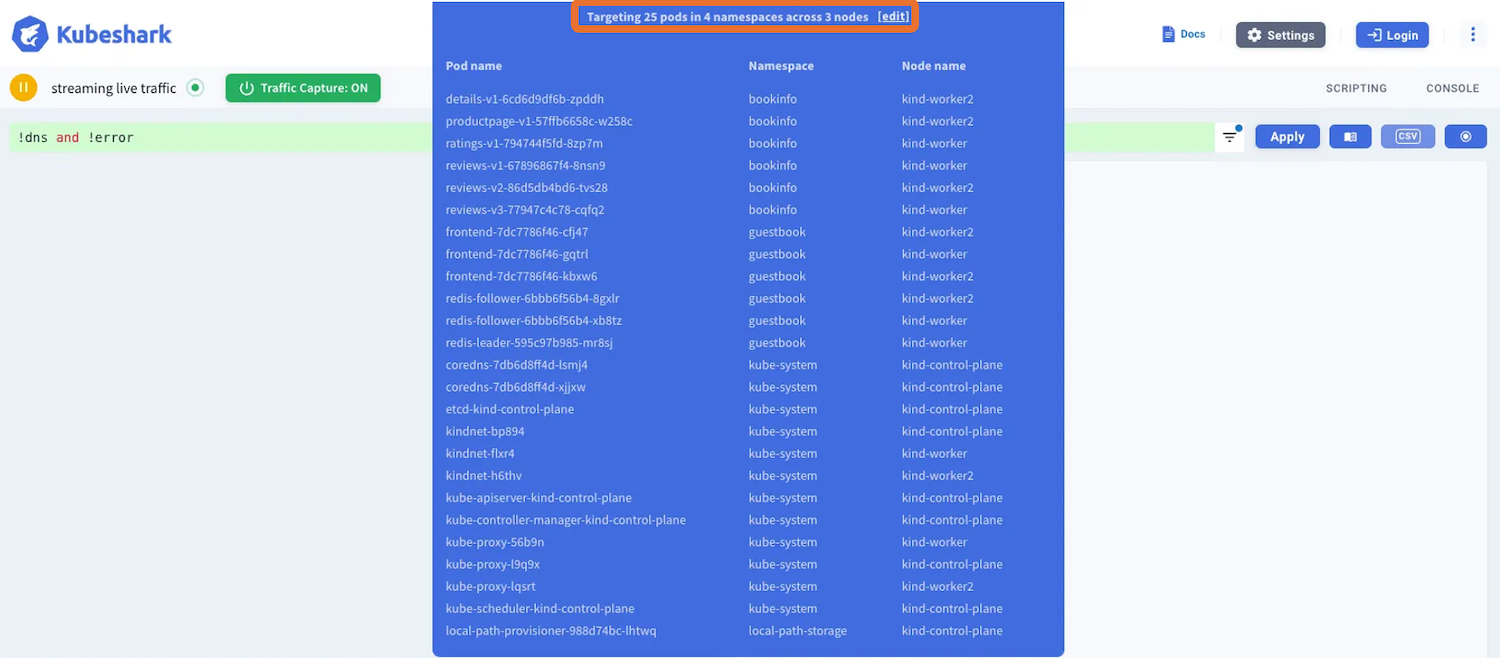

KFLはWiresharkのディスプレイフィルター、キャプチャフィルターはWiresharkのBPFによるフィルタリングに似たもので、フィルタリングする箇所が異なることに注意が必要です。
pcapファイルの取得
pcapファイルは2通りの方法で取得できます。TLS通信の場合でも復号された状態で出力されます。ただし、pcapファイルとして保存する場合はPodやService、NamespaceといったKubernetesのコンテキスト情報は保存されません。
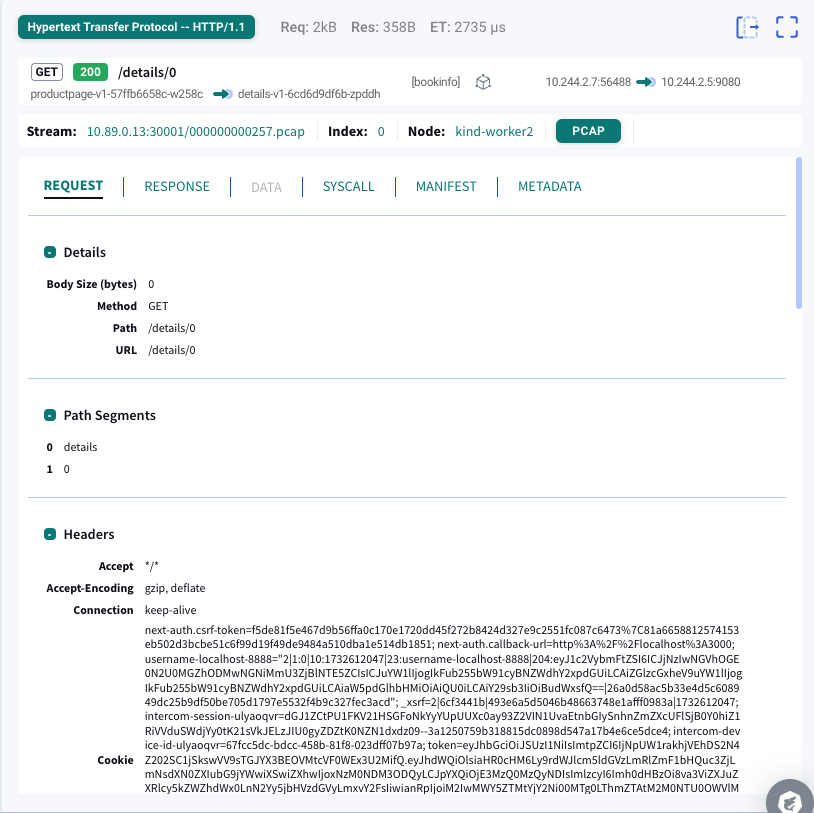
1つ目は、特定のトラフィックを保存する方法です。これはダッシュボード上でDownload PCAPをクリックすることで取得できます。

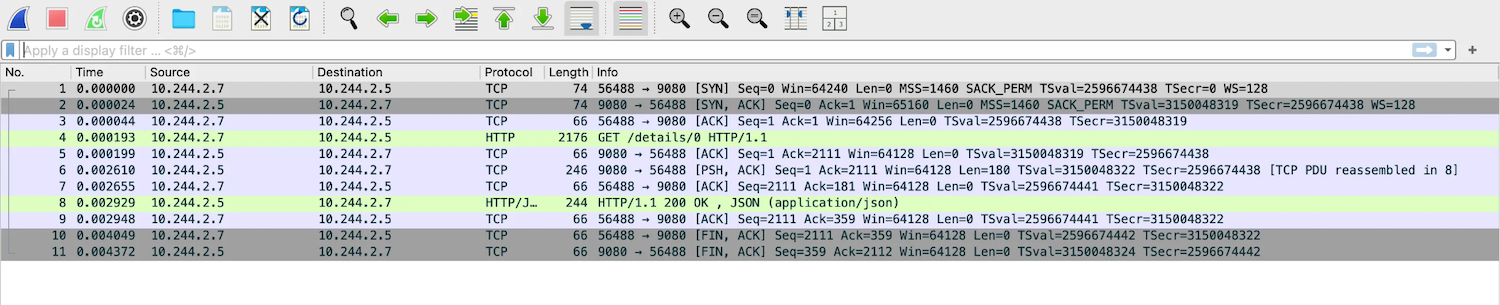
上図のように/details/0へのGETリクエストを指定すると、下図のようなキャプチャファイルが取得できます。この方法ではセッションごとにキャプチャデータを出力するため、分析が容易になるというメリットがあります。
2つ目は、すべてのトラフィックを保存する方法です。kubeshark pcapdumpコマンドを使用することですべてのノードのトラフィックをマージし、1つのpcapファイルとして出力できます。ただし、Wiresharkの下にあるPacketsセクションを見れば分かるように、膨大なパケット数になるため分析が難しくなるというデメリットもあります。
$ kubeshark pcapdump
Merged file created: node-kind-worker-worker-1-20241223-051606.pcap
$ open node-kind-worker-worker-1-20241223-051606.pcap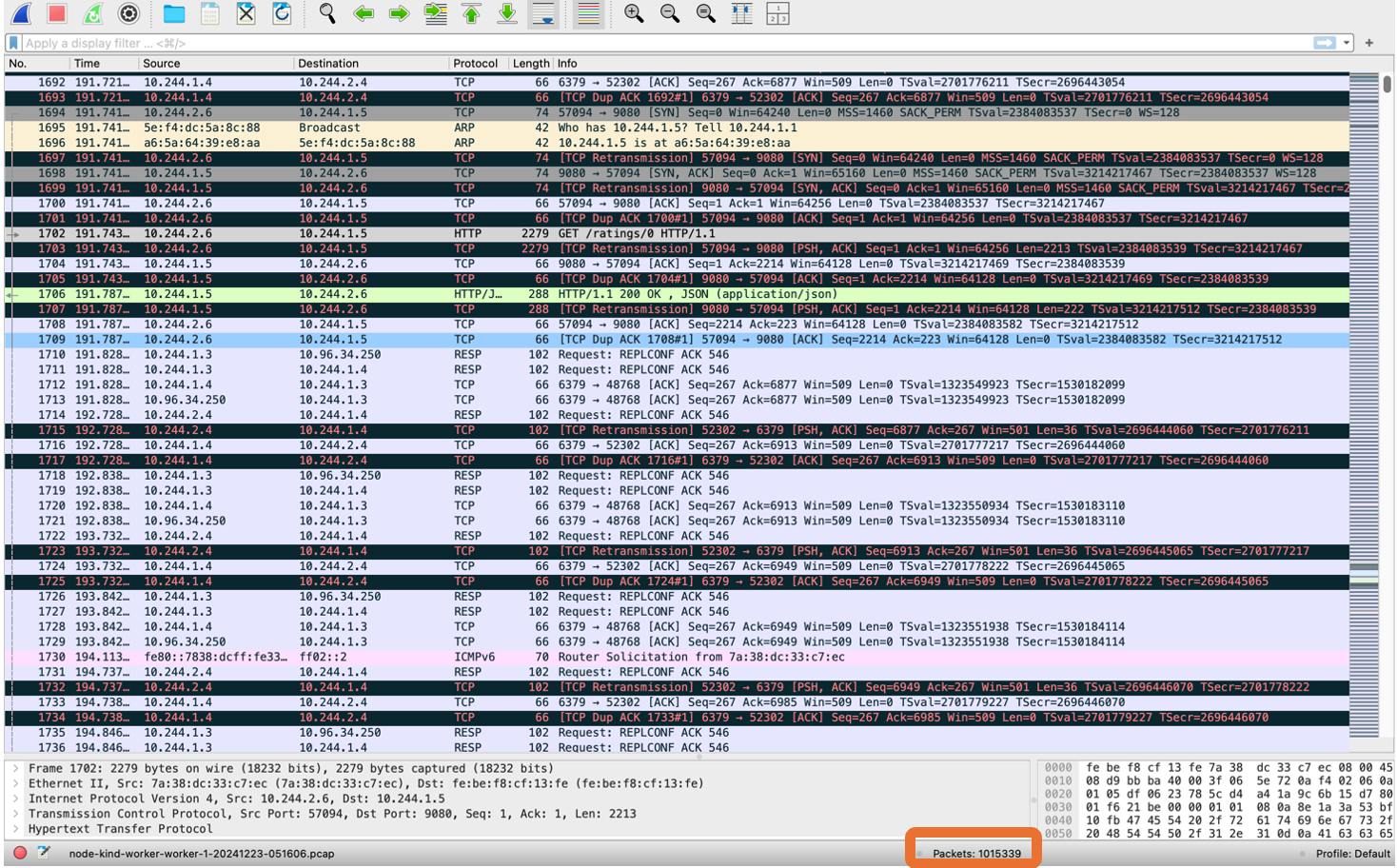
トラフィックの保存とオフライン分析
pcapファイルとしてローカルに保存するだけでなく、kubeshark上でトラフィックを保存して管理することもできます。また、スケジュールを指定したり、特定のイベントや行動に応じてトラフィックを記録したり、後から分析したりすることもできます。
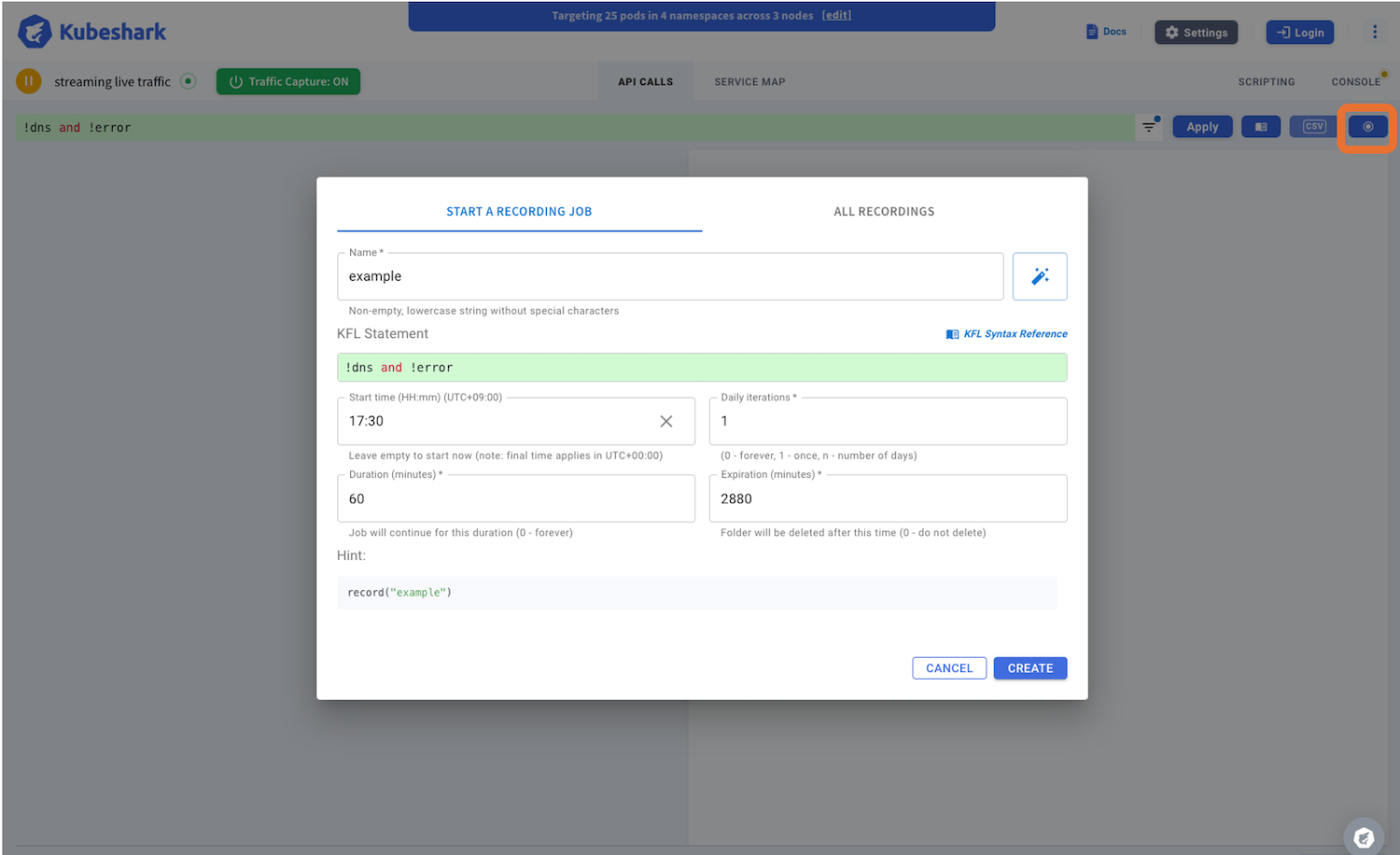
ダッシュボードの◉をクリックするとジョブ作成画面が開きます。ここでは17:30から60分間キャプチャし、exampleという名前で保存します。このジョブは1度だけ実行され、有効期限は2880分になっています。ストレージを節約するために有効期限が経過すると自動的に削除されます。
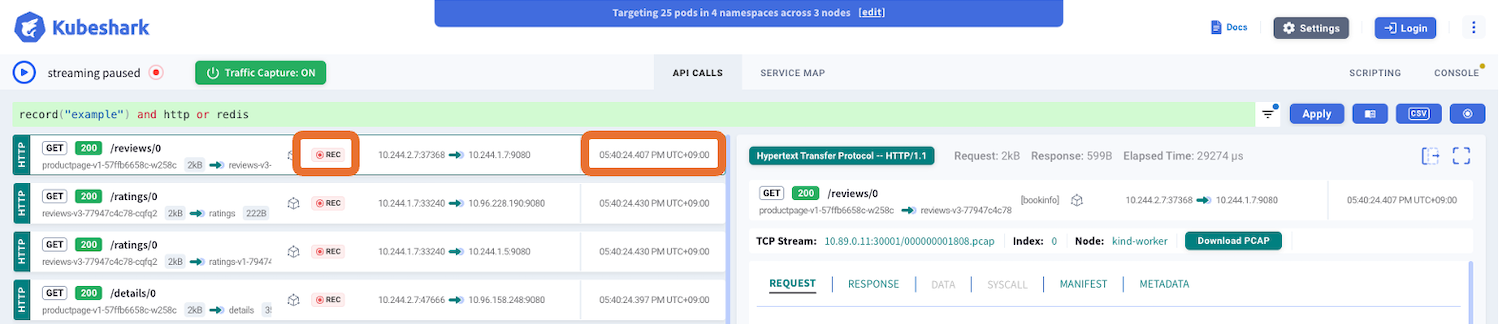
今回保存したデータは、KFLでrecord("example")と記述すると開くことができ、その中からhttpとredisのトラフィックのみを表示しています。これを表示しているのは07:10PMですが、TCPストリームに◉RECが表示されており、タイムスタンプが05:40PMであることが確認できます。
kubeshark上でトラフィックを記録しておくことで、pcapファイルとして保存する場合と比べてKubernetesのコンテキスト情報も保存できるというメリットがあります。
さらに、トラフィックはAWS S3やGoogle Cloud Storageなどのオブジェクトストレージにアップロードすることもでき、長期保存も可能です。
おわりに
今回は、kubesharkを利用してKubernetes環境でのトラフィックキャプチャと可視化の方法について解説しました。kubesharkはトラフィック分析に役立つツールで、特にインシデント対応やトラブルシューティングにおいて迅速かつ効果的な解決をサポートします。
今回紹介した方法は特に小規模なクラスターやテスト環境での運用に適しており、リソース消費を最小限に抑えつつトラフィックの詳細な解析が可能です。kubesharkを利用することで各Podに入ってtcpdumpを実行する手間が省けるだけでなく、通常のパケットキャプチャツールでは得られないKubernetesコンテキストを含む詳細な情報も収集できます。
kubesharkを使って、Kubernetesクラスタのトラブルシューティングやパフォーマンス解析をさらに効率化してみてはいかがでしょうか。
【参考】
・インストール方法
・ディスプレイフィルタとキャプチャフィルタ
・pcapファイルの取得
・トラフィックの保存とオフライン分析
- この記事のキーワード
関連記事
「kind」でローカル環境にKubernetesクラスターを構築する
2024年8月28日 9:13
Kubernetesアプリケーションのモニタリングことはじめ
2021年10月22日 6:30
Oracle Cloud Hangout Cafe Season4 #4「Observability 再入門」(2021年9月8日開催)
2024年4月23日 6:30
「K8sGPT」の未来と生成AIを用いたKubernetes運用の最前線
2024年11月14日 9:28
「vCluster」で仮想Kubernetesクラスターを構築する
4月24日 6:30
Oracle Cloud Hangout Cafe Season5 #3「Kubernetes のセキュリティ」(2022年3月9日開催)
2023年4月18日 6:30
バックナンバー
この記事の筆者
筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
