モバイル、ソーシャル、クラウド、ビッグデータといった第3のプラットフォーム(3rd Platform)の登場とともに、デジタルビジネスの新たな展開やワークスタイルの変化、それに伴う、IT基盤の変化がもたらされています。本稿では、こうしたビジネスの変化に対応した、ネットワークインフラの最近の動向とブロケードの取り組みについて紹介します。
ダイナミックなビジネスの創出
「ビジネスに貢献するIT」という言葉は使い古された感がありますが、今でもユーザから提示される、要望の多いものの1つです。この「ビジネスに貢献する」という部分をコストダウンと捉え、IT基盤のうちサーバーやデスクトップを仮想化して統合を実践している企業は、日本でも企業の55%を越えています。サーバーやクライアントの物理的な数を削減可能な仮想化技術は、ITシステムのTCOのコスト低減に大きく寄与します。
しかし、コスダウン以外ではどうでしょうか。ビジネスシステムは静的なものではありません。IDCが唱えている第3のプラットフォーム(3rd Platform)の時代においては、ビッグデータ分析、クラウドを使用したビジネスシステムがダイナミックに生成され、リアル・オプション的な発想がIT基盤に採り入れられ、採算に載らないものは、即時に破棄されます。また分析が高スループットで実現できることにより、リアルタイム経営が実現し、コスト低減が行えますし、顧客状況を改善することで、売上向上や顧客満足度の向上が可能になります。多くのユーザは、このようなことを可能にする、柔軟なITプラットフォームをプラットフォーマに要求しています。
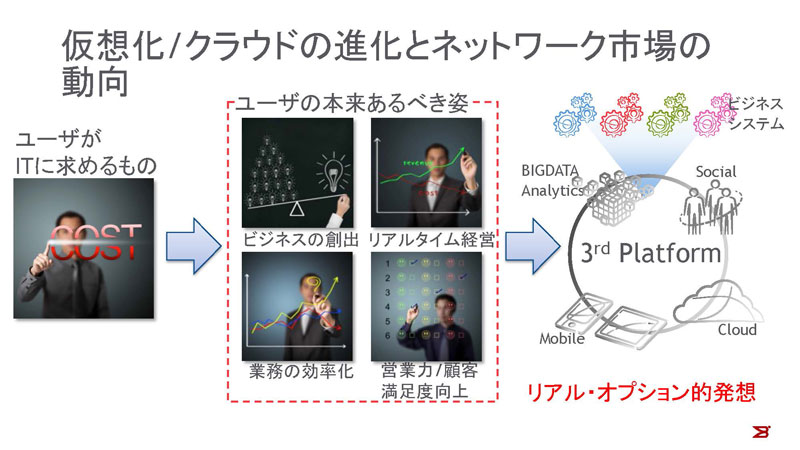
図1:仮想化/クラウドの進化とネットワーク市場の動向
SDN時代におけるファブリックの必要性と課題
リアル・オプション的な発想を採り入れたIT基盤では、状況に応じてプロジェクトユーザのビジネスを、動的かつ即時に生成・破棄する必要があるため、リソースを柔軟に伸縮可能なクラウドコンピューティングが必須です。今日のクラウドは、数万ノードで構成されることも珍しくはありません。たとえば、Microsoft Azureでは1リージョンにつき50万台以上のサーバーが配備されています。複数のゾーンから構成されることを考えても、単一のゾーンは1万台を越えるスケールの構成になります。このような、大規模コンピュートクラスタというリソースプールの構築には、2つの方法が採られています。
オンデマンドなITインフラへのアプローチ方法
大規模リソースプールの構築方法の1つは、汎用のサーバーにプロセッサ、メモリ、ストレージを搭載し、プールを拡張していく、Hyper Convergedシステムのアプローチです。このアプローチは、同じ構成要素を使った拡張ができるため、コスト面、運用面でのアドバンテージがあります。汎用IaaS基盤のように、ワークロードが平均的にコンピュートノードに対して小さく、ワークロードの質が決まらないような場合に最適です。もう1つのアプローチは、リソース単位でシステムを拡張していく、Fabric Based Computingのアプローチです。
Hyper Convergedシステムは、Nutanix社の製品やVMware EVO:RAILのような形で実現しています。一方、今日のFabric based Computingは、Hyper Convergedの変形として実現しています。特殊な形態としてはIntelのリファレンススイッチとして実現されようとしています。
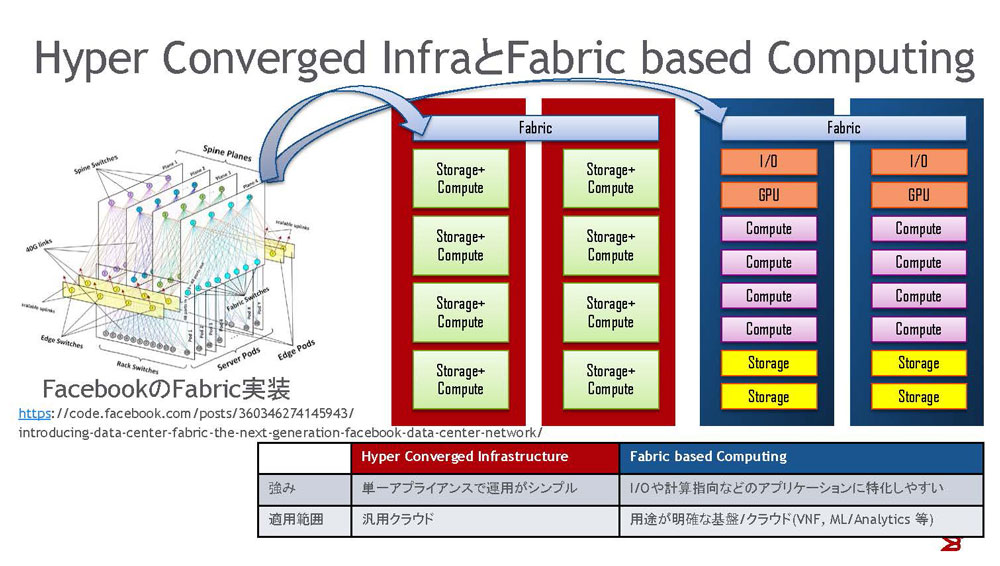
図2:Hyper Converged InfraとFabric based Computing
ファブリックによるインフラのメリット
ワークロードが限定できないクラウドでは、End-to-Endでオーバーサブスクリプション(全ポートの帯域幅の総量がスイッチングファブリックの容量を超えている状況)のない、ネットワーク構成が必須です。そのため、FacebookでもAmazon Web Servicesでも、Microsoftにおいても、ファブリックを構成しています。一般的なネットワーク構成では、Active-Activeで構成できるアップリンクに制限があるため、アップリンクの帯域がボトルネックになりやすい問題があり、これが、クラウドプロバイダのデータセンターネットワークで、ファブリック技術が多く利用されている理由です。
ファブリックを構成する技術としては、L2ファブリックやフルメッシュトポロジ環境でルーティングプロトコルとオーバーレイ技術を利用した、L3ファブリックがあります。
L2ファブリック
2011年頃からブロケードやシスコなどのメーカーから、L2ファブリック技術を使った製品が登場しいてきました。L2でファブリックを構成する利点は、ユーザにとっては接続されるコンピュートノードの所属するネットワークが、ルーティングされることなくファブリック全体で利用できるため、ワークロードがファブリック内の位置をまったく意識しないことです。また、設計者の観点では、トポロジやネットワークの設計をしなくてもL2情報をベースに自律的にファブリックが構成でき、かつ、ファブリック内ルーティングプロトコルを利用したECMP(Equal Cost Multi Path)を実現し、広帯域も実現できるところも大きな利点です。
一方、L2処理に起因する制限もあります。現状では、ブロードキャスト処理やマルチキャスト処理の実現のために、特定のスイッチのリソースが使われるため、処理能力を越える大きさのファブリックにはできません。現実的にはTRILLやSPBベースのファブリックでは、ファブリック当たり数十台から100台程度の大きさになります。
L3ファブリック
L3ファブリックは、ECMPをL3技術で実現するファブリックです。ワークロード間の通信はVXLANやGREでカプセル化されるため、L3のECMPが機能しますし、ブロードキャストの課題も基盤側とは切り離されるのも利点です。クラウドのネットワークアーキテクトは、BGPなどを利用したネットワークの設計を行うだけでいいのが一番の特徴です。また、Spine(下記参照)からToR(Top of Rack)まで、標準技術で構成できることも利点に挙げられます。一方、L3を利用するということはネットワークを設計、設定する必要があります。これはL2の場合との大きな違いです。これからL3ファブリックの改善を要するポイントとしては、オーバーレイ、アンダーレイネットワークを統合的に管理できる仕組みがあります。ネットワークのプロビジョニングを行うときに物理ネットワークの帯域を知らずに行うと、オーバープロビジョニングしてしまい、適切なサービスレベルを維持できません。また、オーバーレイが前提であるため、ファブリックに接続されるシステムが仮想化されたワークロードでない場合、アプリケーション側で仮想スイッチのオーバーレイエンドポイントと同様の処理を行う必要があります。これはL3ファブリックの非常に重要な特性です。
Spine and Leaf Architecture
L2ファブリック型のネットワークでは、Spine(背骨)スイッチとLeaf(枝葉)スイッチの役割を分けることで、2階層のネットワークを構築します。Spineスイッチには、サーバーなどのノードは接続せず、トラフィックを効率的に転送することに専念させ、Leafスイッチにサーバーやルーターなどのノードを接続します。スイッチの役割を分担することで、帯域が必要な場合はSpineスイッチを追加し、ノードの収容台数を増やしたい場合は、Leafスイッチを増設します。
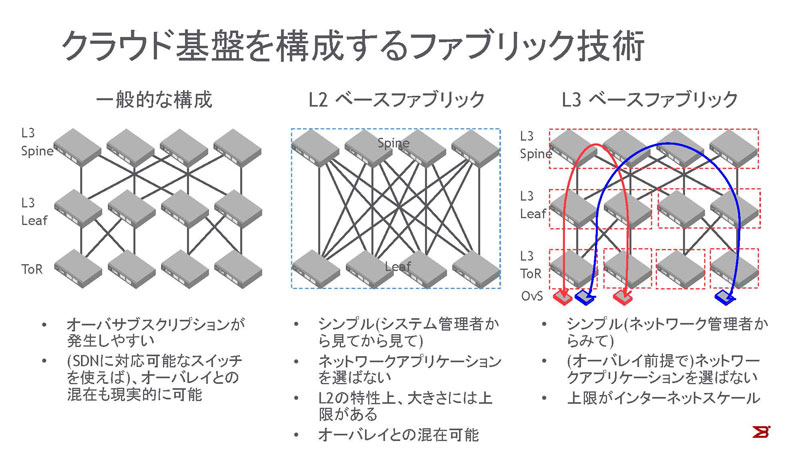
図3:クラウド基盤を構成するファブリック技術
クラウド環境で活用できる仮想ファンクション
L2ファブリック、L3ファブリックのいずれも場合においても、今日ではSDN対応が図られています。もしユーザが仮想スイッチを構成する場合、オーバーレイ終端の設定をオペレータとユーザのどちらがどのように行うのかが問題になりますが、SDNに対応していれば、たとえばOpenStackから仮想ネットワークの構成を自動で行うことができるので、トンネルの終端の構成で悩むことも少なくなります。ただし、物理ファブリックとオーバーレイは、特定のベンダーの製品を除いては連携していません。オーバーレイを使えば物理ネットワークを気にする必要はなくなりますが、それは物理ネットワークの自動化は別に実装するということを意味します。一方、ファブリックでは仮想化を意識したSDNを実装していますが、オーバーレイとシームレスな連携を実現したものはまだありません。
L2かL3かにかかわらず、ファブリックさえ構成すれば、ユーザが使用する仮想ファンクションとしてのルーター、ロードバランサなどは、ソフトウェアアプライアンスで構築できます。今日ではソフトウェアルーターでもギガビットを越えるスループットのトラフィックを扱うことができます。また、ソフトウェアでネットワークファンクションを実現することで、Software Define Datacenterが実現でき、即時のデプロイ、破棄が可能となります。IntelのDataplane Development Kitなどのフレームワークを使用して、データプレーンを純粋なソフトウェアで記述する代わりに、オープンなAPIを規定したうえで特定のファンクションをハードウェアでアクセラレーションする、Open Dataplaneのような取り組みも行われています。
最新のハードウェアであれば、単にSDNで設定を自動化したり、フローの制御をするだけではなく、さまざまな機能のハードウェアオフロードも可能です。たとえば、代表的なオーバーレイ通信方式であるVXLANのカプセル化処理などを加速するNICは、すでに存在しています。
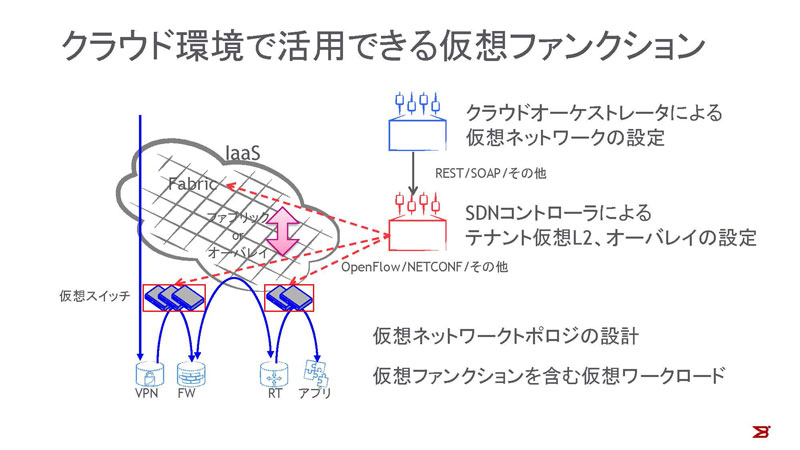
図4:クラウド環境で活用できる仮想ファンクション
将来のビジネス基盤での課題
第3のプラットフォーム(3rd Platform)以降の世代のプラットフォームは、今日のIT基盤とは大きく変わる可能性があります。必ずしもサーバーレベルの仮想化は使用されません。また、次世代のビッグデータの分析では、データを基盤のレベルで分離することはないでしょう。ストア自体はDHT(Distributed Hash Table:分散ハッシュテーブル)のような技術で分散しますが、可用性向上やMapReduceのような処理のために、全ノード間での大容量通信が発生します。一方、ストリームのリアルタイム処理のためには、処理ごとにノード群を固定的に構成し、メッセージ交換を行います。通信特性も、SQLクエリのような比較的小規模のトラフィックからRDMA(Remote Direct Memory Access)やストレージのような大きなブロック/ページサイズの通信までさまざまです。次世代のプラットフォームでは、機械学習の基となるデータはAnalyticsクラウドを利用し、ビジネスロジックはIaaSを使い、全体を制御することになります。
過去のさまざまな研究から、多くのノード構成の環境下で非常に大きなサブスクリプション比の通信が発生する場合、マイクロバーストやTCP Incast(注)などの問題が発生することが主張されています。このような状況下では、TCPの再送が最適に動作せず、スループットが劇的に下がることがあります。問題なのは、それがいつどこでどの程度の影響で発生するかを予想することが非常に困難なことです。
これらの3つの種類の基盤が、必ずしも同一のサービスプロバイダが提供するとは限りません。また、クラウド間やクラウド・エッジデバイス間のネットワークサービスも特定のキャリアに依存しないようになるでしょう。その場合、マルチクラウドかつデータセントリックなインフラを構築するには、Software Defined Infrastructureが必須になります。
このようにハードウェアベース、ソフトウェアベースの両基盤のCo-designが重要になってきます。
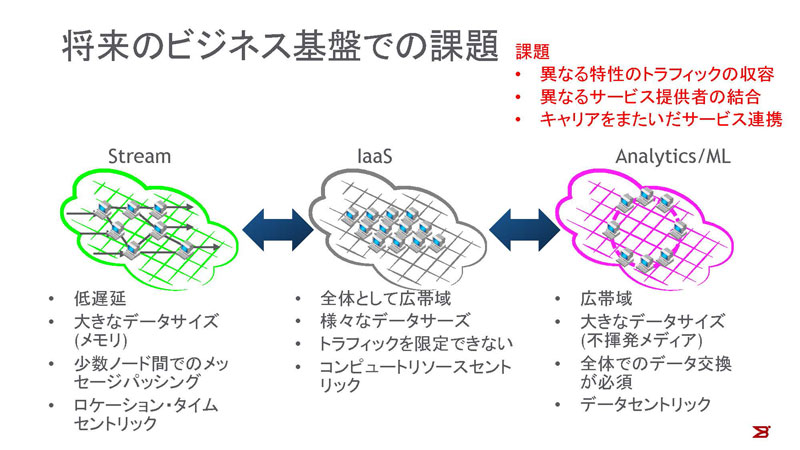
図5:将来のビジネス基盤での課題
バックナンバー
この記事の筆者
筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
