CloudNative Days Tokyo 2023から、WasmのクラウドネイティブやAI推論での利用を解説
CloudNative Days Tokyo 2023から、Wasmを利用したAI推論のユースケースを解説したセッションを紹介する。
2024年1月29日 6:00
2023年12月11日、12日の両日にオンラインとリアルのハイブリッド形式で開催されたCloudNative Days Tokyo 2023のキーノートから、Michael Yuan氏による、Wasm(WebAssembly)の概要と、そのクラウドネイティブでのユースケース、そしてLLM(Large Language Models、大規模言語モデル)による生成AIへの応用についてのセッションを紹介する。

セッションを担当したMichael Yuan氏
タイトルは「Wasm is becoming the runtime for LLMs」。なおYuan氏は、CNCF(Cloud Native Computing Foundation)のサンドボックスプロジェクトになっている、Wasmランタイム「WasmEdge」プロジェクトの創設者だ。
Wasmはブラウザーで始まりサーバーサイドの技術に
Wasmはもともと、CやC++のアプリケーションをコンパイルしたバイナリをWebブラウザーで動かすためのランタイムとして生まれた。JavaScriptなどとは違い、CやC++からコンパイルされたバイナリは環境をクラッシュさせる可能性があるために、環境から分離されて動く一種のコンテナとして設計されたのが特徴だ。
このことにより、Wasmはブラウザーからサーバーサイドの技術に広がった。これはかつて、ブラウザーの技術として作られたJava VMがサーバーサイドの技術になったのと同じ道だ。
一方クラウドは、仮想マシンでワークロードを動かすAmazon EC2から始まり、やがて仮想マシンより軽量なコンテナを動かすようになった。そして、コンテナより軽量にワークロードを動かすのがWasmだ、というのがYuan氏の主張するところだ。
Yuan氏はWasmの特徴の中でも、「非常に軽量」と「OSやハードウェアの違いを超えてポータブル」という2点を強調する。

クラウドネイティブなランタイムとしてのWasm
1点めの「非常に軽量」については、2つの事例が紹介された。まず、Redisのキーバリューストアを読み書きするWebアプリケーションを、Rustとhyperで開発した例だ。コンテナで開発すると600MB以上になるところを、Wasmでは0.7MB(700KB)におさまったという。このサイズであれば、Raspberry Piや車載機器などのIoTデバイスでも動く。
もう1つの例は、PostgreSQLのCRUD操作ができるクライアントで、こちらはWasmで800KBのサイズだ。起動もミリ秒単位と高速で、この起動速度であれば必要なときだけ起動するようにしてリソースの消費を防げる。

コンテナと比べてWasmは非常に軽量となる
OSやCPU、アクセラレーターの違いを超えて1つのバイナリが動く
2点めの「OSやハードウェアの違いを超えてポータブル」という特性が必要となる背景として、2020年にGoogleやスタンフォード大学の研究者が発表した論文「There's plenty of room at the Top: What will drive computer performance after Moore's law?」が紹介された。
論文タイトルは1950年代に技術のナノスケール化を予見したリチャード・ファインマンの論文「There's Plenty of Room at the Bottom」をもじったもの。下位層である回路の微細化が限界となりつつある中で、パフォーマンスのためには上位層であるソフトウェアの改善が重要になるという主張だ。具体的には、JavaやPythonではなく、CやRustを使って、CPUのAVX命令やGPUなどを駆使することになる。

性能向上を担うのは半導体の微細化からソフトウェアの改善へ
そのためのコンピューティングプラットフォームは現在多様化している。CPUは、IntelとAMDだけでなく、Apple Siliconを始めとするARMや、RISC-Vなども考慮する必要がある。さらに、CPUの世代による機能の違いもある。
Wasmでは、こうしたCPUの違いや、OSの違いなどを越えて、ポータビリティを得られるとYuan氏。仮想マシンでも同様の恩恵は得られるが、エミュレーションとなるためパフォーマンスのペナルティがある。
さらにYuan氏が強調するのが、NVIDIAのGPUや、Apple Silicon、ARMのNPU、GoogleのTPUといったアクセラレーターの違いを超えられることだ。
これにより、開発者がMacBookやWindowsのノートPC上でコンパイルしたバイナリが、エッジデバイスから、サーバー、パブリッククラウドまで、プロセッサーやOSの違いを越えて動くというわけだ。

WasmならOS、CPU、アクセラレーターの違いを意識しないで済む
ここまでがWasmの概要だ。
クラウドネイティブでのユースケース
続いてYuan氏はクラウドネイティブでのWasmのユースケースを紹介した。
まずは、マイクロサービスやサーバーレスファンクションで、コンテナを置き換える形だ。
次が、ストリームデータのファンクション。これは、ネットワークプロキシやメッセージキューなどのデータの流れる部分にWasmを組み込んでデータを処理するものだ。最近ではすでにWasmをサポートする製品が多くあるという。
また、大きなシステムで機能拡張を実現するために、Wasmによりプラグイン機構を提供することもあるという。
そのほか、ブロックチェーンのスマートコントラクト(ブロックチェーン上で特定の条件で実行されるプログラム)でもWasmが使われる。
そして最後が、今回のタイトルにもあるようにAIの推論のユースケースだ。

Wasmの広範なユースケースから本セッションではAIの推論に注目
Wasmは現在、コンテナの形式の一つとして、KubernetesやDocker、Podmanが対応している。そのため、Linuxコンテナと同じようにWasmを管理できる。
またCNCFは、さまざまなOSSプロジェクトを展望するCloud Native Landscapeにおいて、2023年から「Wasm」カテゴリーを設けた。ランタイムレベルからフレームワークレベルまで、GitHubのスターを百万ぐらい集めるプロジェクトが並んでいるという。そのため、ここに行けばWasmの現実世界のユースケースが見られる。

CNCFランドスケープのWasmカテゴリーはすでに百花繚乱と言える
AIアプリケーションをCやC++で書いてWasmで動かす
そしてタイトルどおりのWasmでAI推論を動かす話だ。「これがWasmの能力を示すのにいいショーケースだ」とYuan氏は言う。
AIでモデルの作成や、モデルを使った推論の実行には、Pythonを使うことが多い。しかし、Pythonの機械学習ライブラリであるPyTorchのコンテナイメージは、ベーシックなもので約3GB、CUDA対応のもので6GBのサイズがある。そしてPyTorchの中核となる部分はC++で書かれていることから、「PythonはCのとても高コスト(very expensive)なフレームワークだ」とYuan氏は主張する。
Pythonは高コストなフレームワーク?
ではCやC++でアプリケーションを書いて動かせばいいかというと、そこにも問題はある。なぜならCやC++からコンパイルしたコードはポータブルではないからで、ポータビリティのためにコンテナに入れようとしてもそのためにCやC++のツールチェーンも入れるとそれなりに大きく(数百MBオーダー)なってしまう。

C/C++によるアプリケーション作成にも問題点が
そこで、AI推論のアプリケーションをCやC++で書いてWasm形式にコンパイルし、それを一種のコンテナとしてWasmランタイムで動かすというのが、Yuan氏の提案するアプローチだ。
WasmではファイルやネットワークなどシステムとのインターフェイスがWASI(WebAssembly System Interface)として定められている。そして、機械学習で使う機能のAPIも、WASI-NNとしてW3Cで標準化中だ。WASI-NNのAPIを呼び出したあと、実際にCPUやGPU、TPUの機能を使う部分は、その下のライブラリに任される。これにより、APIを境に、DevOpsのDev(開発者)はその上を、Ops(運用者)はその下を担当するように分業できる。

Wasmを用いた手法
ここでYuan氏は、WasmEdgeを使ってLLaMAのモデルを使った対話型生成AIを動かす例を、実際に壇上でデモした。デモにあたってYuan氏は、まず自分のMacBookのWi-Fiをオフにして、ローカルで動くところを示した。

ローカルでLLMを動かすデモ
Wi-FiをオフにしたMacBookでデモを実施
ターミナル上で動かした対話型生成AIに、Yuan氏はその場で「Where is the capital of the US?(USの首都は?)」という質問を入力。すると、期待どおり、ワシントンD.C.であるという文章が返ってきた。
続いて「What about Japan?(では日本は?)」と入力すると、会話の流れを理解して、東京であるという文章が返った。さらに「Can you plan a 2-day trip for me there?(そこに行く2日間の旅を計画してもらえますか?)」と入力すると、東京の旅行プランが返ってきた。
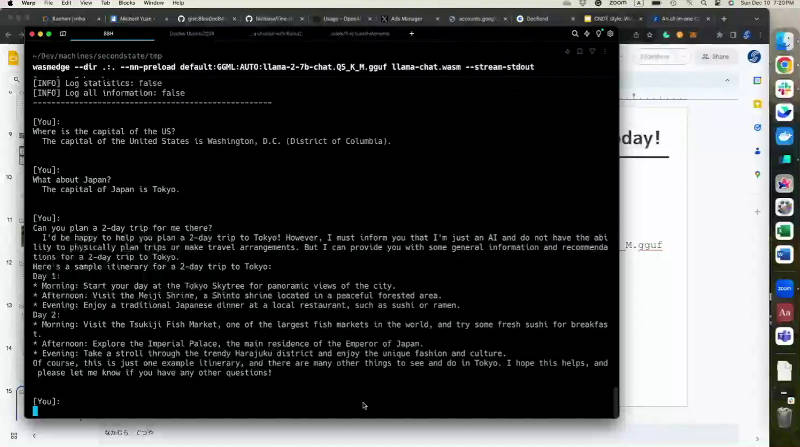
個人用のMacBookでAIが機能しているようだ
Wasm(WebAssembly)はその名から、Webの、特にブラウザーの技術というイメージもまだある。しかし開発の発展により、サーバーサイドへ、特にKubernetesなどのクラウドネイティブへと広がっている。
中でもAIのようなコンピュートにヘビーなワークロードを、Wasmで高効率かつポータブルに動かすというのは、まだ実験的ではあるが、一つの可能性となりそうだ。そして、実際にWasmEdgeによりローカルで生成AIアプリケーションが動くようすがデモで示されたことに、説得力を感じた。
- この記事のキーワード
この記事をシェアしてください
関連記事
Cloud Native Wasm Dayから大規模言語モデルをWasmで実行するデモを解説するセッションを紹介
2024年2月8日 6:00
WasmCon 2023からLLMをWASMで実装するセッションを紹介
2023年12月1日 6:00
KubeCon China 2024から、ローカルでLLMを実行するSecond Stateのセッションを紹介
2024年11月8日 9:01
KubeCon Europe 2025、エッジでAIを実行するKubeEdge Sednaのセッションを紹介
2025年5月29日 6:00
WASMを実行するためのランタイム、wasmCloudがCNCFのサンドボックスに
2021年9月2日 6:00
次世代クラウド基盤「Wasm」の可能性と課題を探る
2024年11月5日 9:06
バックナンバー
この記事の筆者

筆者の人気記事
使って分かった国産クラウド「K5」のメリットとは
2018年1月31日 6:30
初めてでも安心! OCIチュートリアルを活用して、MySQLのマネージド・データベース・サービスを体験してみよう
2021年4月21日 12:39
Dockerを理解するための8つの軸
2015年7月29日 22:00
Dockerの誤解と神話。識者が語るDockerの使いどころとは? Docker座談会(前編)
2016年2月22日 0:00
【イベントリポート:Red Hat Summit: Connect | Japan 2022】クラウドネイティブ開発の進展を追い風に存在感を増すRed Hatの「オープンハイブリッドクラウド」とは
2022年11月10日 8:45
Kubernetes、PaaS、Serverlessのどれを選ぶのか? 機能比較と使い分けのポイント
2018年5月23日 6:30
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
