今回は、PostgreSQL 9.5(以下、9.5)で実装された以下2つの機能について、実際に動かしながら紹介します。
- Block Range Indexes(BRIN)の実装
- wal_compressionパラメータの追加
Block Range Indexes(BRIN)の実装
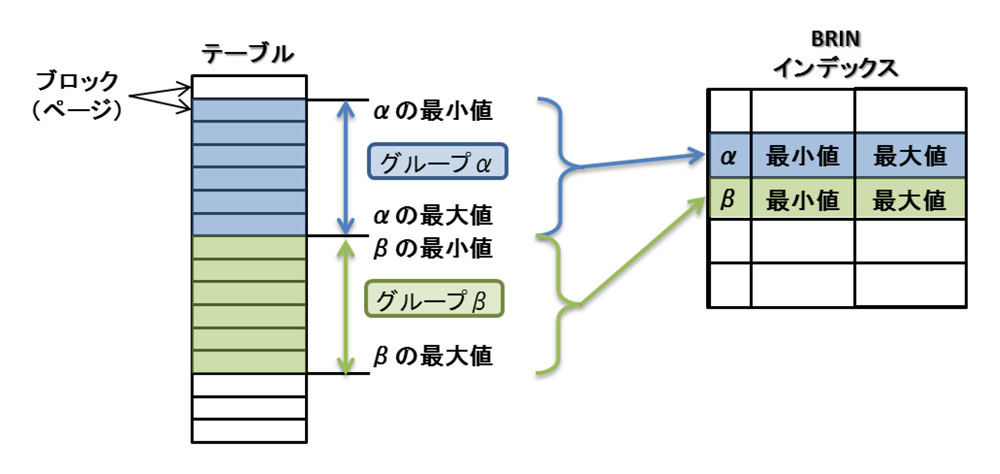
9.5から「Block Range Indexes(BRIN)」と呼ばれる新しいインデックスが実装されました。例えばDWH(Data Ware House)システムで扱われるような巨大なテーブルを検索する際に効果を発揮します。BRINインデックス(公式ドキュメントでは「BRIN Indexes」と呼称)は、物理的に隣接するブロック(ページ)の集合を1つのグループとし、それら各グループの値の範囲(最小値と最大値)を保持しています(図1)。これにより検索時の走査範囲を絞り込むことができるため、走査範囲が広くなりがちな巨大なテーブルほど高い効果が得られます。
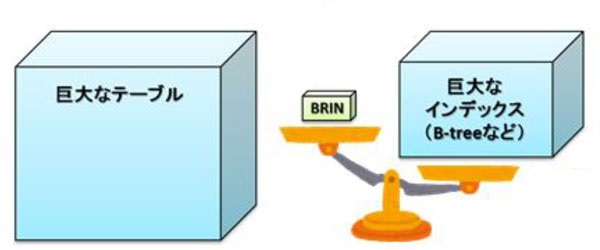
巨大なテーブルにデフォルトのB-treeインデックスを定義すると、多くの場合にそのインデックスサイズも巨大になる傾向があります。これはB-treeインデックスがテーブルの行ごとの情報を保持していることに起因します。一方、BRINインデックスは主にグループ化した対象の範囲情報を保持するだけであるため、一般的にBRINインデックスのサイズはB-treeインデックスのサイズよりも小さくなります(図2)。そして、インデックスのサイズが小さくなることで、次のような効果が期待できます。
- インデックスが素早くキャッシュに乗り、インデックス自体の走査時間も短くなるため、プランニングや検索処理の性能が向上する
- インデックスの再定義など、メンテナンスの所要時間が短くなる
- 物理領域に占める割合が低減される
- インデックスのサイズが小さくなることで、キャッシュの利用効率が上がる
以下のデータを保有するorder_lineテーブルを用いて、BRINインデックスとB-treeインデックスのサイズを比較してみます。
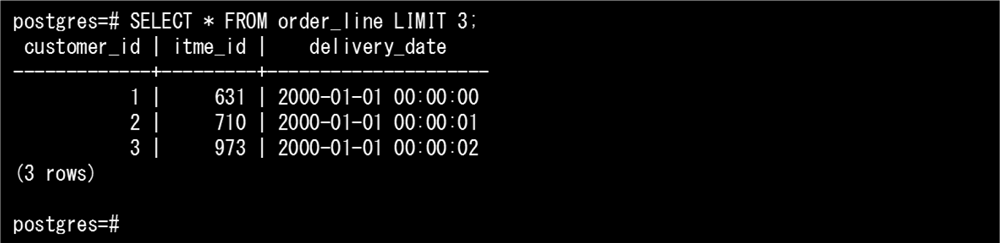
インデックスを作成するorder_lineテーブルのdelivery_date列には、1秒間隔のタイムスタンプ型のデータが昇順に約6,300万件(約2.6GB)格納されています。データは昇順にロードされており、物理的にも整列されている状態です。このdelivery_date列にインデックスを定義します。BRINインデックスは通常のインデックスと同様にCREATE INDEX文で定義できます。

B-treeインデックスの定義方法は以下のようになります。なお、インデックスのタイプを指定しない場合はデフォルトでB-treeインデックスが作成されます。

インデックス作成後、pg_relation_size()システム管理関数を利用して取得したインデックスサイズの比較結果が図3です。
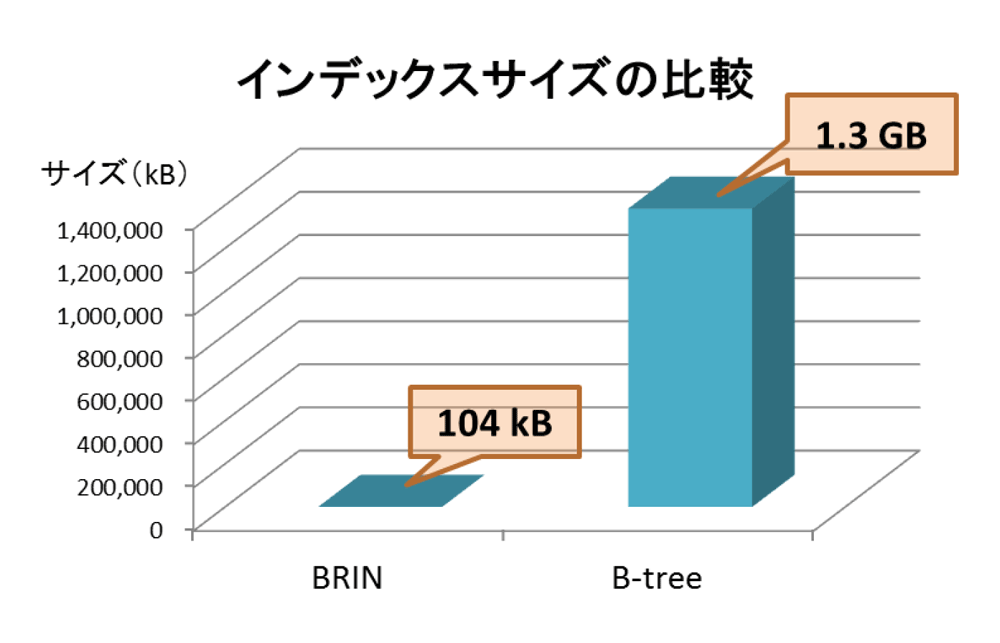
B-treeインデックスはorder_lineテーブル(2.6GB)の半分ほどのサイズになるのに対し、BRINインデックスはそれよりも遥かに小さいサイズとなります(参考情報として、本記事の検証環境ではそれぞれのインデックスの定義時間はB-treeインデックスが約282秒、BRINインデックスが約105秒という結果となりました)。
続いてorder_lineテーブルにANALYZEを実施後、EXPLAIN ANALYZE文で実行計画と実行時間を確認します。下記はBRINインデックスを用いた場合の実行計画と実行時間です。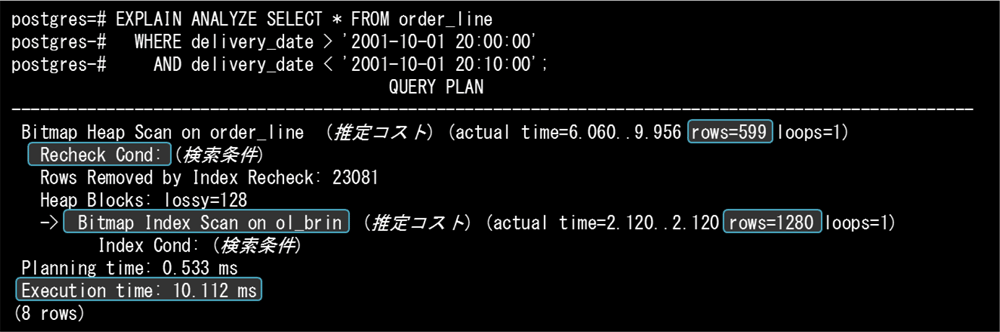
この例では、ol_brin BRINインデックスを利用してビットマップ・インデックス・スキャンで対象行を取得しています。ここで上記スキャンのactual rows(実際の取得行)が1,280行であることに注目してください。最終的に取得したい件数は599件ですが、それよりも多くの行を取得しています。これは、BRINインデックスが「グループの最大値と最小値」という範囲で対象行を絞り込み、検証対象外の行も含めてグループ範囲内のすべての行を取得していることに起因します。このため、BRINインデックスを利用して検索した後に検索条件を再チェック(Recheck Cond)し、最終的に合致するタプルを絞り込んでいます。
次に、B-treeインデックスを用いた場合の実行計画と実行時間です。
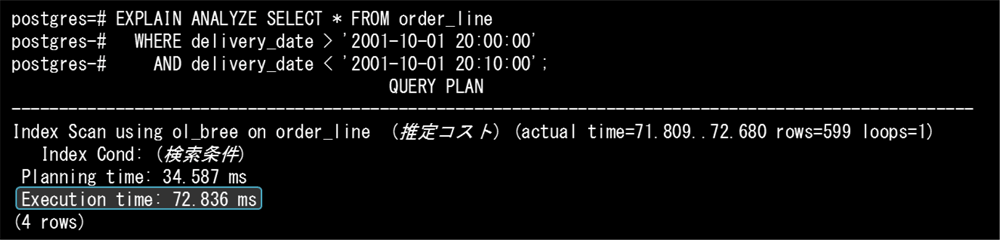
ここでBRINインデックスとB-treeインデックスのExecution time(実行時間)を比較すると、BRINインデックスの所要時間の方が短くなっていることがわかります。これは走査範囲を絞り込んだことによる効果と、冒頭に紹介したインデックスのサイズが小さくなったことによる影響と考えられます。
ここまでの動作確認でBRINインデックスの優位性が確認できました。ただし、今回は巨大テーブルへのアクセスでキャッシュが有効に活用できていない状況を想定し、あえてキャッシュに載らない初回検索時の所要時間を比較しました。このため、キャッシュが有効に活用できている状態では巨大テーブルでもB-treeインデックスのほうが検索時間が短くなり得ることに注意してください。
wal_compressionパラメータの追加
9.5のパラメータに「wal_compression」が追加されました。このパラメータを有効にすると(デフォルトでは無効)、ディスクに書き込まれるWAL(トランザクション・ログ)の量を低減させることができます(図4)。full_page_writesパラメータが有効(デフォルトは有効)になっていると復旧時の完全性を高めるため、チェックポイント後に変更されたページは初回のみ当該ページのすべての内容(フルページ・イメージ)をWALに書き出します。そのときにwal_compressionが有効になっていると、そのフルページ・イメージが圧縮され、実際に書き出されるWALの量が減少するという仕組みです。このためwal_compressionを有効にすると、例えばWALを書き出しているディスクの性能が低いときやWALを利用したレプリケーション(ログシッピング)時のネットワークリソースの消費が多いとき、またはWALアーカイビング時の格納領域の空きが少ないときなどに処理性能や運用コストの改善が見込めます。

それでは、wal_compressionで実際にどの程度WAL量が低減されるのか確認してみましょう。wal_compressionの設定はスーパーユーザ権限でいつでも変更できますが、今回はpostgresql.conf(設定ファイル)のwal_compressionパラメータをonに変更してからPostgreSQLを起動します。ここではPostgreSQL同梱のベンチマークツール「pgbench」を使用して、以下のように更新処理を発生させました。
- 初期化(テーブルやインデックスの作成、データのロードなど)
pgbench -i -s 100 - チェックポイントの実行
CHECKPOINT; - 更新前のトランザクションログの書き込み位置を取得
SELECT pg_current_xlog_location(); - ベンチマークの実行によりデータを更新
pgbench -t 40000 -c 4
このとき、合計4回のチェックポイントが発生 - 更新後のトランザクションログの書き込み位置を取得
SELECT pg_current_xlog_location(); - 更新前と更新後のトランザクションログの差分を取得
SELECT pg_xlog_location_diff('5.の結果','3.の結果');
図5は、6.pg_xlog_location_diff()により取得した更新前後のトランザクションログサイズの差分結果です。
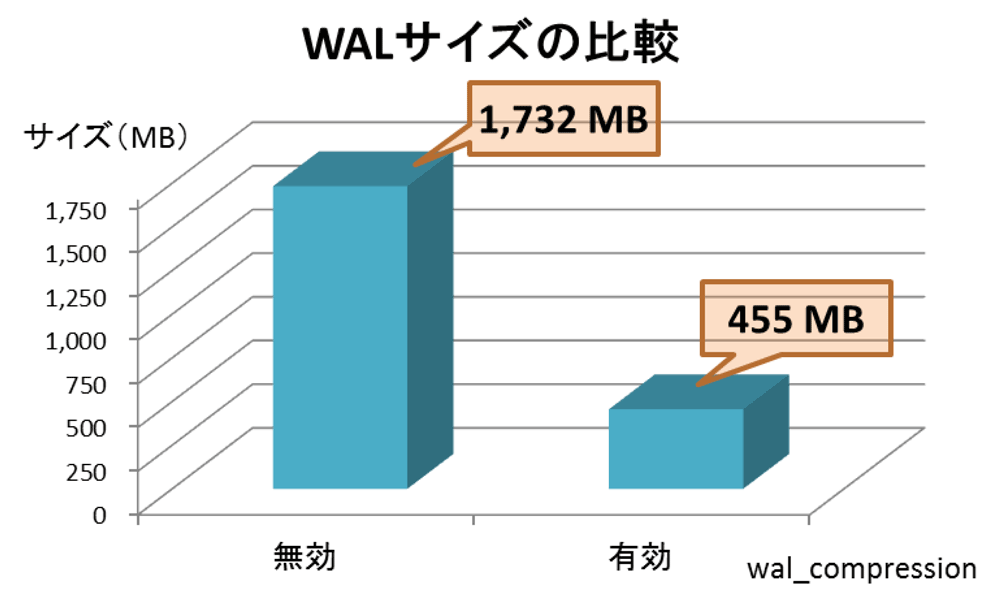
これにより、wal_compressionを有効にするとWALのサイズがおよそ1/4まで減少することが確認できました。ただし、圧縮処理にはCPUコストが伴うことも考慮してください。条件によっては処理性能が低下する恐れもあります。
今回のサンプルSQLはこちらからダウンロードできます。ぜひ、皆さんもお手元の環境で動作確認を実行してみてください。
今回は、処理性能に関連するBlock Range Indexes(BRIN)とwal_compressionパラメータについて紹介しました。次回は、PostgreSQLの利便性を高めるためのrow-level security control(RLS)とpg_rewindについて詳しく解説します。
- この記事のキーワード
バックナンバー
この記事の筆者
筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
