MapReduceプログラムの作成
MapReduceプログラムの作成
では、いよいよログファイル解析のMapReduceプログラムを書いてみましょう。前回の記事でEclipseをインストールしましたので、それを使って今回のお題の一つである
「アクセス数の多いURI: 上位10件」
を、抽出するプログラムを書いてみましょう。
全く0からプログラムを作るのも大変ですから、Hadoop-1.2.1に含まれるサンプル(WordCount.java)をベースに、改造を加えていく形にしたいと思います。
Hadoopのアーカイブファイルの入手
サンプルプログラムは、Hadoopの配布物一式に含まれています。下記のページを参照し、いずれかのミラーサイトからダウンロードしてください。
> http://www.apache.org/dyn/closer.cgi/hadoop/common/
私は、こちらのファイルをダウンロードしてみました。
> http://ftp.tsukuba.wide.ad.jp/software/apache/hadoop/common/hadoop-1.2.1/hadoop-1.2.1.tar.gz
※なお、hadoop-1.2.1-bin.tar.gzにはソースファイルが入っていませんのでご注意。
このファイルを、どこか適当なところに展開してください。私はC:\Users\ksasaki\Downloads\hadoop-1.2.1に展開しました。Windows環境での.tar.gzの展開には、7-ZIP等のツールやCygwinに含まれるGNU Tarを使うのが手軽かと思います。
EclipseにJavaプロジェクトを作成
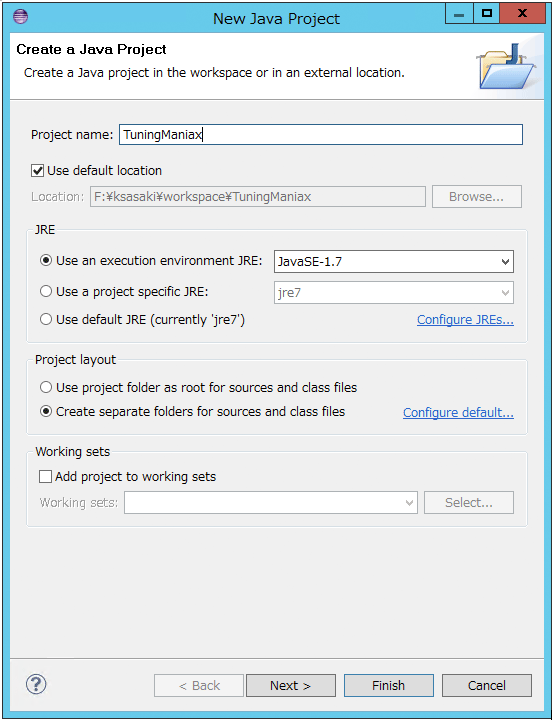
Eclipseを起動し、File→New→Java ProjectでJavaプロジェクトを一つ作ります。
※記事中の図をクリックすると拡大表示します(一部除く)。
初期状態ではプロジェクトは空っぽです。ここに、先ほど展開したhadoopのサンプルソースファイルをインポートしましょう。
1. ソースフォルダ”src”を右クリックして、”Import…”をクリックします。
2. “General”→”File System”をクリックして、”Next”をクリックします。
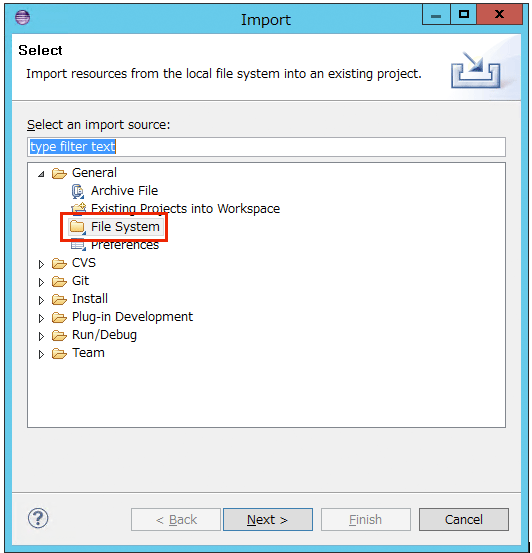
3. “From directory:”に、先ほど展開したhadoopアーカイブの”src/examples”フォルダを指定し、”examples”下の”org”をインポート対象としてチェックします。
最下層の”dancing”と”terasort”は不要なのでチェックを外します。
"Finish"をクリックします。
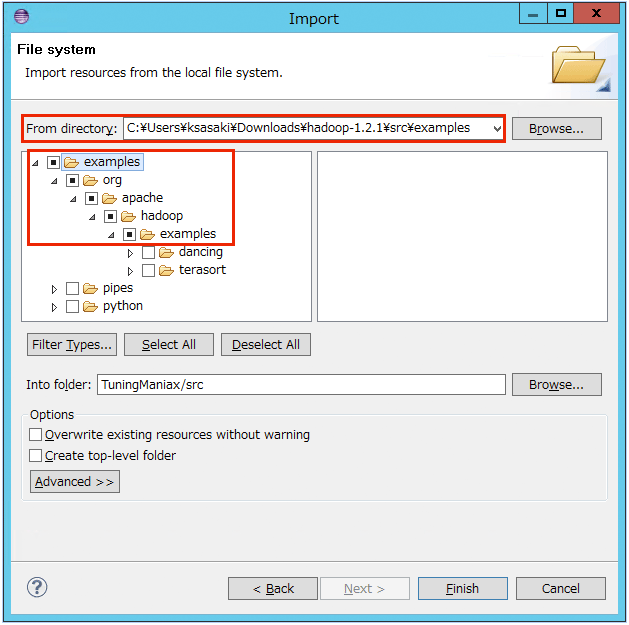
このようになりましたか?WorcCountクラスがあるのがわかると思います。
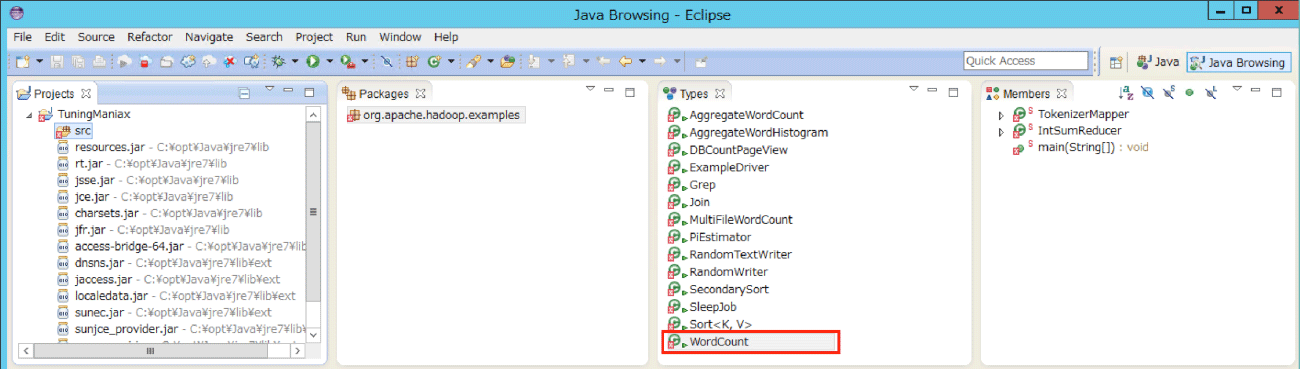
※私の好きなJava Browsingパースペクティブに切り替えてあります。
このパッケージにはたくさんのサンプルプログラムが含まれているのですが、わかりやすくするためにWordCount以外のクラスはひとまず削除してしまいましょう。すると、下図のようにすっきりとします。

また、インポートしただけの状態では、JAR参照が足りずにコンパイルエラーが出ていますので、参照を追加します。
1. プロジェクトを右クリックして、”Properties”をクリックします。
2. “Java Build Path”→”Libraries”タブ→”Add External JARs”をクリックします。
3. 先ほど展開したhadoop-1.2.1.tar.gzに含まれていた、”hadoop-core-1.2.1.jar”と” commons-cli-1.2.jar”を選択して、「OK」をクリックします。

以上で、WordCountクラスがコンパイルできるようになったはずです。これを元にして、リクエストURIのトップ10を数えてみましょう。
第1段階:下準備
まずは、正しく動かすための下準備です。
WordCount#main()で、Job#setCombinerClass()を呼んでいる箇所がありますが、これをコメントアウトします。単純なワードカウントであれば、ReducerをそのままCombiner(中間集計処理)としても使えますが、最終的にトップ10の抽出処理を行う我々のReducerは、Combinerにはできません。

それから、クラス名あるいはパッケージ名を変えておきましょう。
org.apache.hadoop.examples.WordCount のままだと、Hadoop実行環境にもともと存在する同名クラスが優先されてしまい、自分で書いたクラスが実行されません。
ここでは、クラス名を”UriCount”にしてみました。

第2段階:Map処理の改造
入力ファイル(解析対象のログファイル)は、ある程度の大きさごとに「入力スプリット」に分割され、各入力スプリットがデータノードに割り当てられます。
各データノードでは、この入力スプリットから1行ずつ取り出しては、Mapperのmapメソッドに引き渡します。
Mapperは、TokenizerMapperというネスト型として定義されています。Mapメソッドをちょっと見てみましょう。

valueにログファイルの一行が入ってくるので、これを処理するわけです。WordCountでは、単純にStringTokenizerで単語に分割して、「単語名=1」というkey-valueペアをcontext.write()に渡しています。例えば、以下のような1行があったとすると、
Quick brown fox jumps over the lazy dog
このようなkey-valueペアが生成されるわけです。
| Key | Value |
|---|---|
| quick | 1 |
| brown | 1 |
| fox | 1 |
| jumps | 1 |
| over | 1 |
| the | 1 |
| lazy | 1 |
| dog | 1 |
我々が実装すべきURIカウントでは、すべての単語を数える必要はありませんから、
- 入力レコード(これは前述の通りタブ区切り)をバラしてURIフィールドを取り出す。
- そのURIをカウントアップする。
という簡単な処理で良さそうです。こんな感じでしょうか。
public void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
String[] fields = value.toString().split("\t");
// datetime, clientip, user, serverip, uri, timetaken, useragent
word.set(fields[4]);
context.write(word, one);
}# 変更点を最小にすべく”word”変数は名前を変えずにそのまま使っています。
さて、これでWordCount改めUriCountクラスは単語ではなくURIを数えるプログラムになったはずです。「TOP10の算出」処理をまだ実装していませんが、ひとまず動かしてみましょう。こんなとき便利なのが、手元で動くHDInsight Emulatorです。
- この記事のキーワード
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
