はじめに
ビッグデータ向けの処理基盤として「Apache Spark」(以降、Spark)が注目を集めています。Sparkは世界中で利用が進んでおり、アメリカのUberやAirbnb、イギリスのSpotifyといった企業から、CIAなどの政府機関まで広く利用されています。
Sparkにはストリームデータを処理する「Spark Streaming」というコンポーネントがあります。本連載では、Spark Streamingとその他のOSSを組み合わせたストリームデータ処理システムを構築し、その性能検証結果を紹介していきます。
Sparkは複数のコンポーネントで構成されており、Spark Streamingはその1つです。Spark Streamingについて説明する前に、まずSparkおよびSparkと関連の深いHadoopについて説明します。
Hadoopとは
情報システムでは、日々多くの各種業務ログやWebログ、オフィス文書、メール等のデータが生み出されています。加えて、近年はIoT(Internet of Things)への注目の高まりから、様々なセンサー機器でデータが生成されるようになり、情報システムが扱うデータは大規模化しています。
このデータ量の増加に伴って従来のバッチ処理に時間がかかり、予定時間に完了しないという事態が発生しています。そこでビッグデータ向けのバッチ処理基盤として「Hadoop」に注目が集まり、利用されるケースが多くなってきています。
Hadoopは構造データや非構造データを含む大量のデータを入力として、収集蓄積、加工、マイニングや分析、可視化や活用などを高速に実施する処理基盤です(図1)。Hadoopは「MapReduce」と呼ばれる処理で入力データを分割して並列分散処理(Map)し、その結果を集約(Reduce)して出力データを生成します。
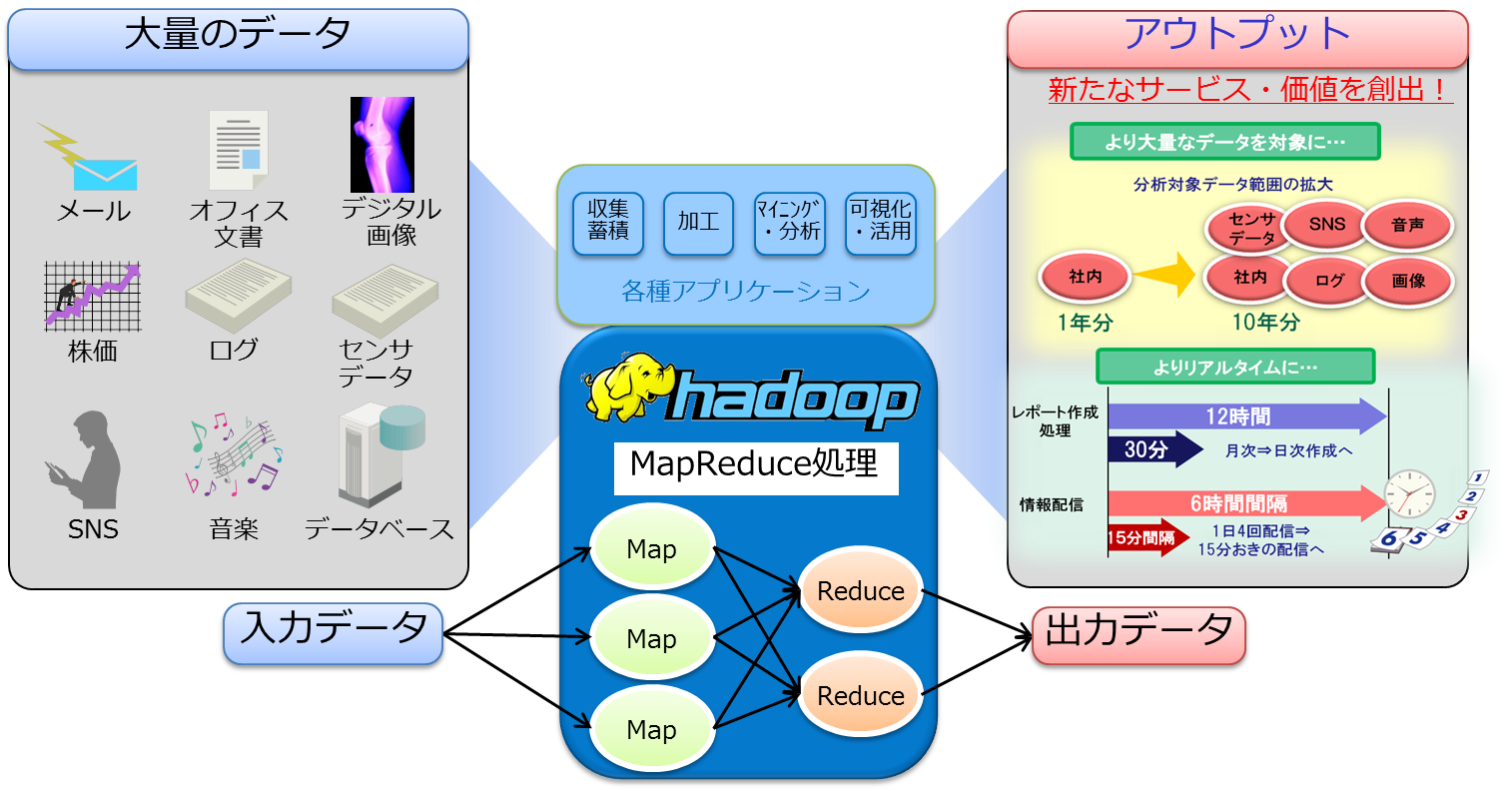
図1:Hadoopの概要
現在主流となっている2.x系のHadoopは、以下のコンポーネントから構成されます。
- MapReduce:バッチ処理の並列分散処理フレームワーク
- YARN (Yet Another Resource Negotiator):クラスタリソース管理
- HDFS (Hadoop Distributed File System):分散ファイルシステム
複数台のマシンで構成されるクラスタ上にHDFSが分散ファイルシステムを構築し、YARNがクラスタのCPU、メモリなどのリソースを管理します。そしてYARN上でバッチ処理の並列分散処理フレームワークであるMapReduceが動作します(図2)。
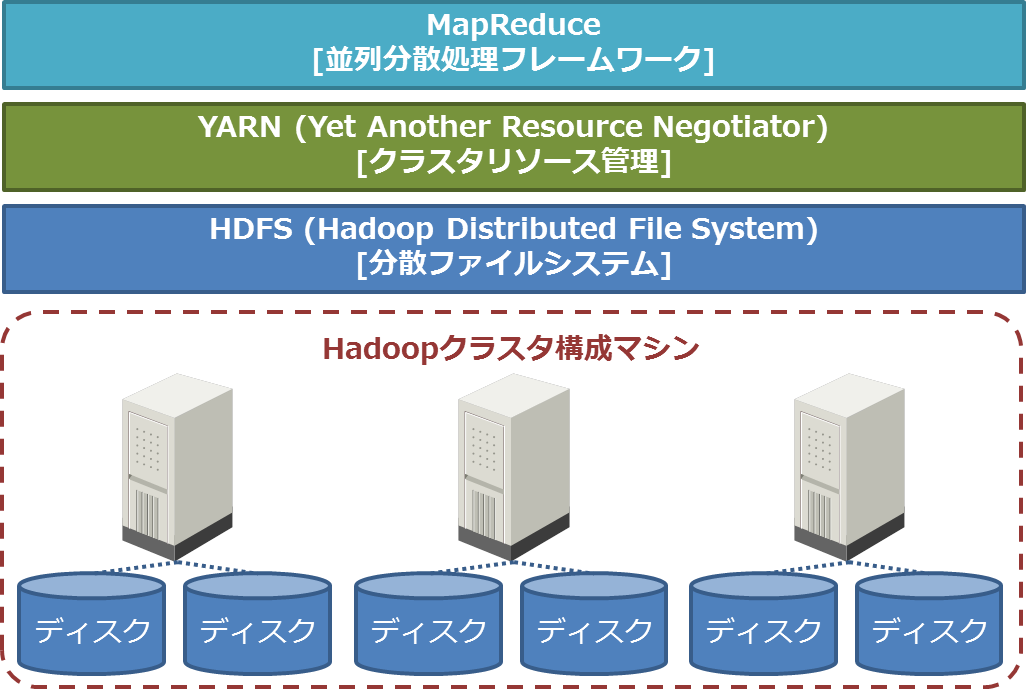
図2:Hadoopクラスタの構成
Hadoopは大量データを分割処理し、発生するディスクI/Oを並列化することでスループットを高めています。しかし、大量の入力データに対してMapReduce処理とHDFSを介したディスク書き込み/読み出しを繰り返して処理することから、全体でディスクI/Oコストが高くなるという課題があります(図3)。そのため、多段のMapReduce処理が必要な複雑な業務のジョブや、データを繰り返し利用する機械学習では、ディスクI/Oが増えて処理に時間がかかります。また、低レイテンシを求める処理(インタラクティブなクエリ処理、ストリームデータ処理など)にも向いていません。
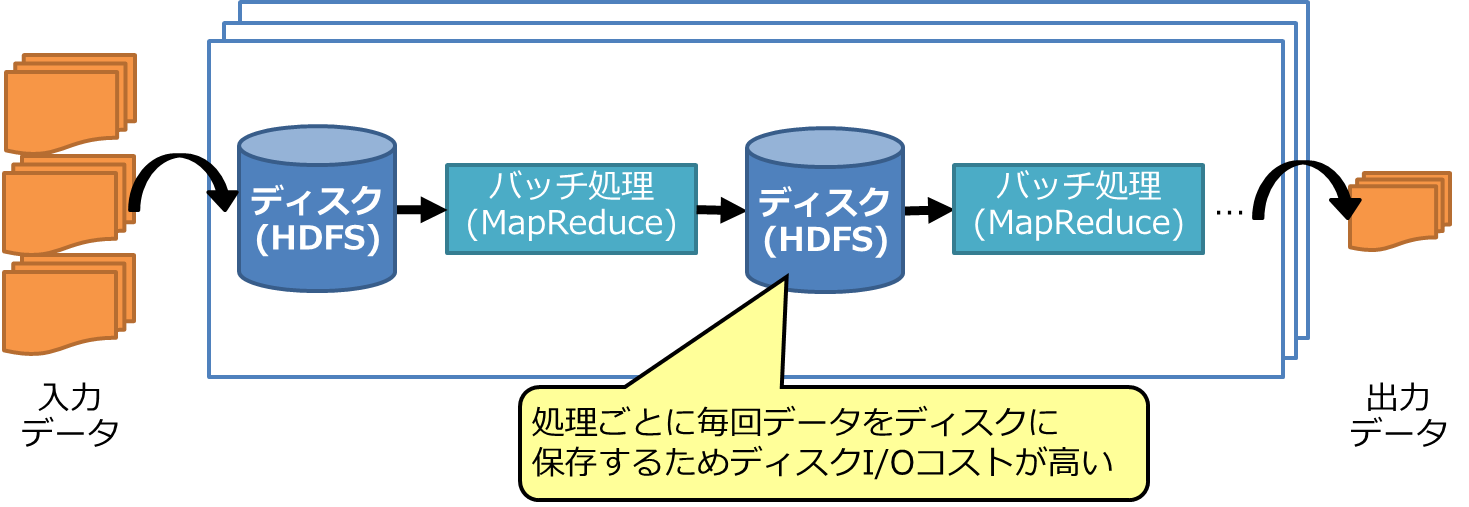
図3:Hadoop (MapReduce)で困ること
Sparkとは
このようなHadoopの課題を解決する手段として、インメモリでデータを処理するSparkが注目を集めています。Sparkはメモリ上でデータを処理するため、処理中に毎回ディスクI/Oが発生するHadoopと比べて高速に動作します。またSparkは既存のHadoopクラスタ(YARN)上でそのまま動作させることができます。
Sparkでは、入力データを「RDD(Resilient Distributed Dataset)」と呼ばれる分散データ配列(コレクション)として扱い、RDDに対する変換処理を実装することで様々なデータ処理を可能にします。
図4にRDDの変換処理の流れを示します。Sparkでは1つのデータソースから読み込んだデータを1つのRDDとして扱います。1つのRDDは複数のパーティションに分割され、1パーティションを1タスクが変換処理します。このタスクがSparkクラスタ内の各ノードに分散配置され、並列で変換処理が行われます。
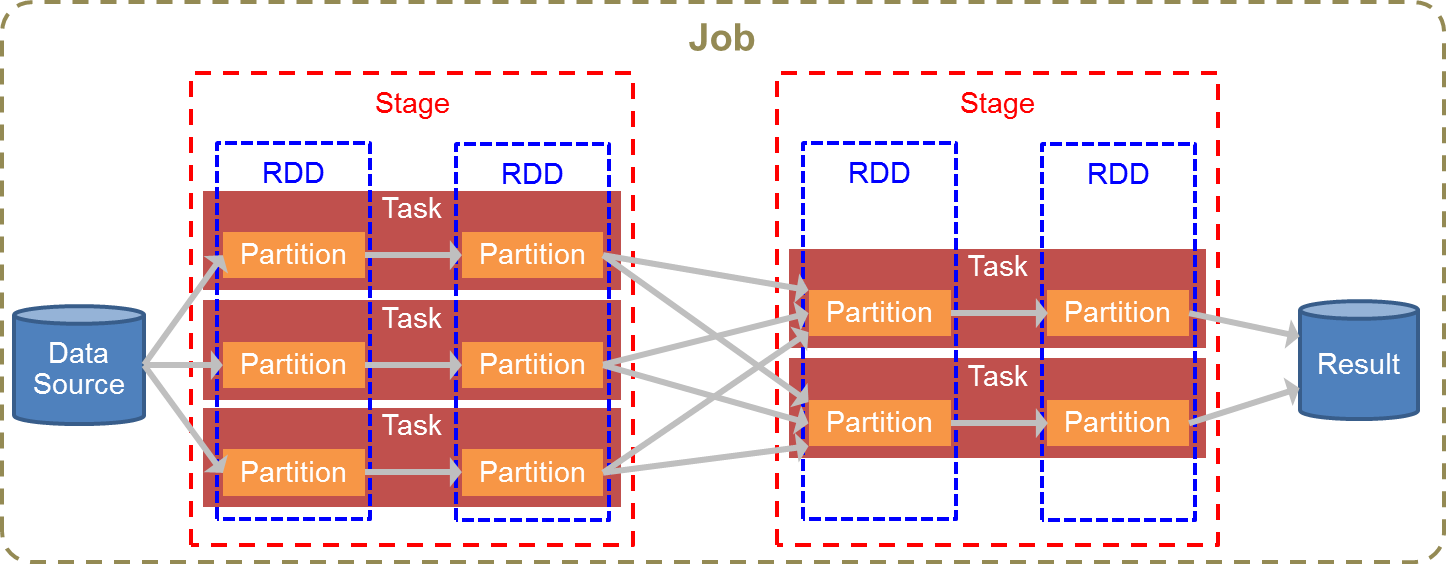
図4:RDDの変換処理の流れ
各タスク内ではシャッフル(パーティションをまたがるデータの交換)を伴わない変換処理が行われます。シャッフルが必要になった時点でそのタスクは終了し、シャッフル後は新しいタスクで処理が行われます。シャッフルが不要な範囲の連続したRDDの変換をまとめて「ステージ」と呼び、シャッフルによりステージが区切られます。ステージ内の全タスクが完了しないと、次のステージに進むことはできません。
なお、データソースからのデータ読み込みから最終的な結果の出力までを「ジョブ」と呼びます。
また、Sparkを構成するコンポーネントを表1に示します。Sparkには並列分散処理のエンジンに当たる「Spark Core」と用途別のライブラリ群があります。
表1:Sparkのコンポーネント
| コンポーネント | 役割 |
|---|---|
| Spark Core | RDDの処理などSparkの基本機能を提供 |
| Spark SQL | 構造データにSQLを利用するためのAPIを提供 |
| Spark Streaming | マイクロバッチ方式によるストリームデータ処理機能を提供 |
| GraphX | グラフ構造データを処理するためのAPIを提供 |
| MLlib | 様々な機械学習アルゴリズムを使用するためのAPIを提供 |
なお、SparkはHadoop(MapReduce)の代替技術と見ることもできますが、一般的には共存して利用されるものと考えるべきです。メモリに乗り切らない巨大データを扱う場合や部分的にデータ消失などが発生して事前にデータ整形が必要な場合にHadoopでデータを一度加工・整形し、その後、Sparkで高速に処理すべきデータを繰り返し分析することが多いです(図5)。
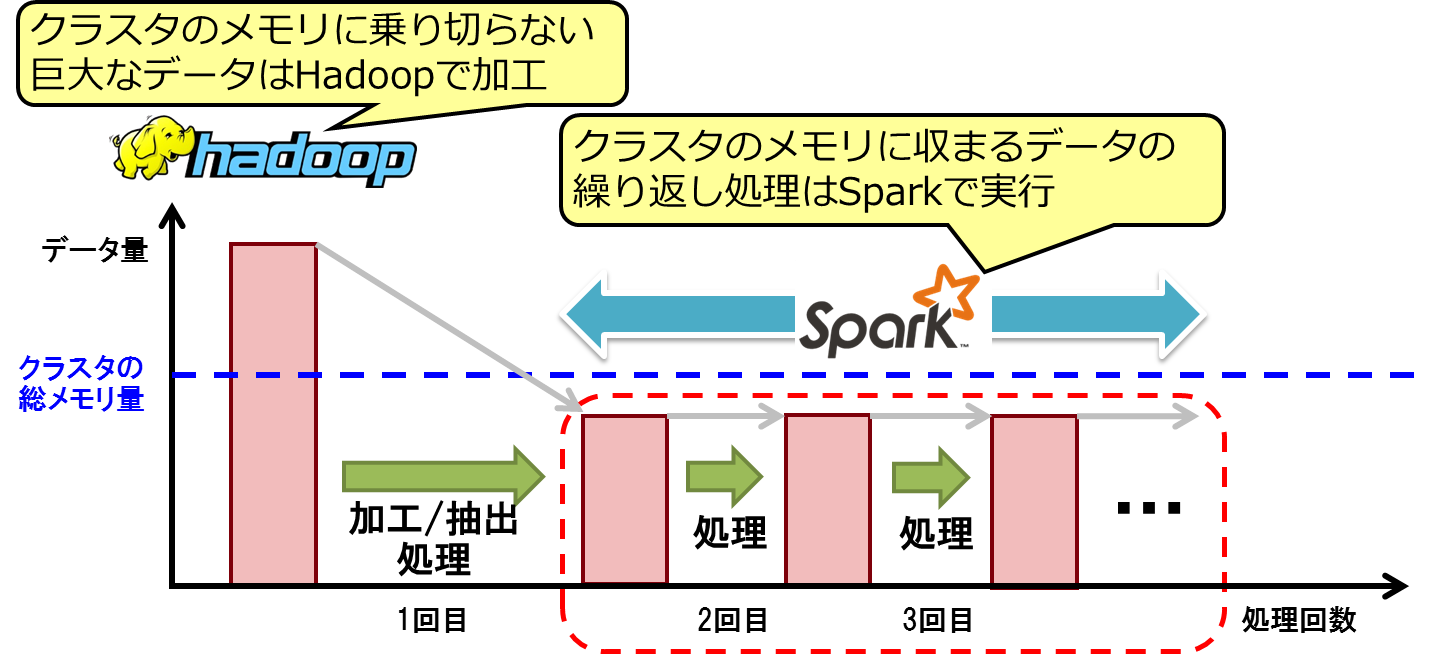
図5:HadoopとSparkの組み合せ方
Sparkが効果を発揮する一般的な条件を表2に示します。Sparkはインメモリで処理を行うため、システム投資対効果を考慮するとTBクラスまでのデータ量に適しています。処理内容はバッチ処理(インメモリで処理可能なデータ量の範囲で)や機械学習などの繰り返し処理に適しています。
また、Spark Streamingはマイクロバッチ方式で動作するため、1秒間隔以上のニアリアルタイムな処理にも適しています。一方、1秒間隔以下のデータ処理が必要なケースではSparkよりも他の手段を利用すべきです。
表2:Sparkが効果を発揮する一般的な条件
| 観点 | 指標 |
|---|---|
| データ量 | TBオーダー未満 |
| レイテンシ | 秒オーダー以上 |
| 処理内容 | バッチ処理(インメモリ化)、繰り返し処理、ニアリアルタイム処理 |
Spark Streamingとは
本連載で検証するSpark Streamingは、マイクロバッチ方式によるストリームデータ処理機能を提供します。マイクロバッチとは、数秒から数分ほどの短い間隔(ニアリアルタイム)で繰り返しバッチ処理を行うものです。
Spark Streamingでは、流れてきたデータを一定時間ごとに区切ってRDDとして扱い、時系列に並んだRDDを「DStream(Discretized Stream:離散ストリーム)」というデータ形式にします。このDStreamに対して一定時間ごとにバッチ処理を行うことで、擬似的なストリームデータ処理を実現します。図6はバッチ実行間隔が1分の場合のDStreamのイメージです。
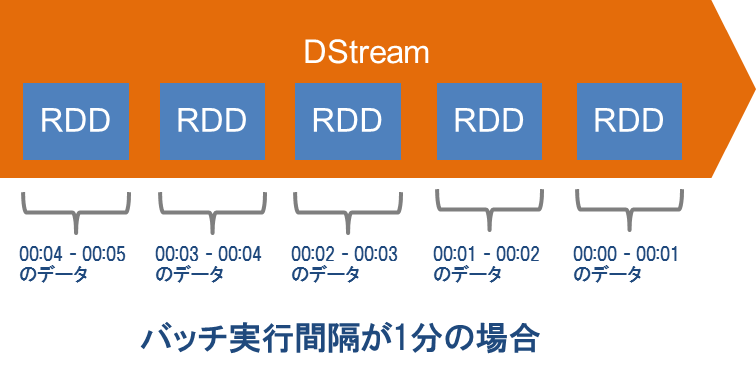
図6:DStream のイメージ
Sparkを取りまくOSS
Sparkはあくまでビッグデータ向けの並列分散処理基盤であり、実際にシステムを構築する際はデータの収集や蓄積のために他のOSS(や商用製品)を組み合わせるのが一般的です。Sparkを取りまくビッグデータ関連OSSの例を図7に示します。
Sparkを取りまくOSSには類似した機能を提供するものが複数あり、それぞれ特徴に差異があります。そのため、ユースケースに合わせて適切なOSS(や商用製品)の組み合わせを見つける必要があります。
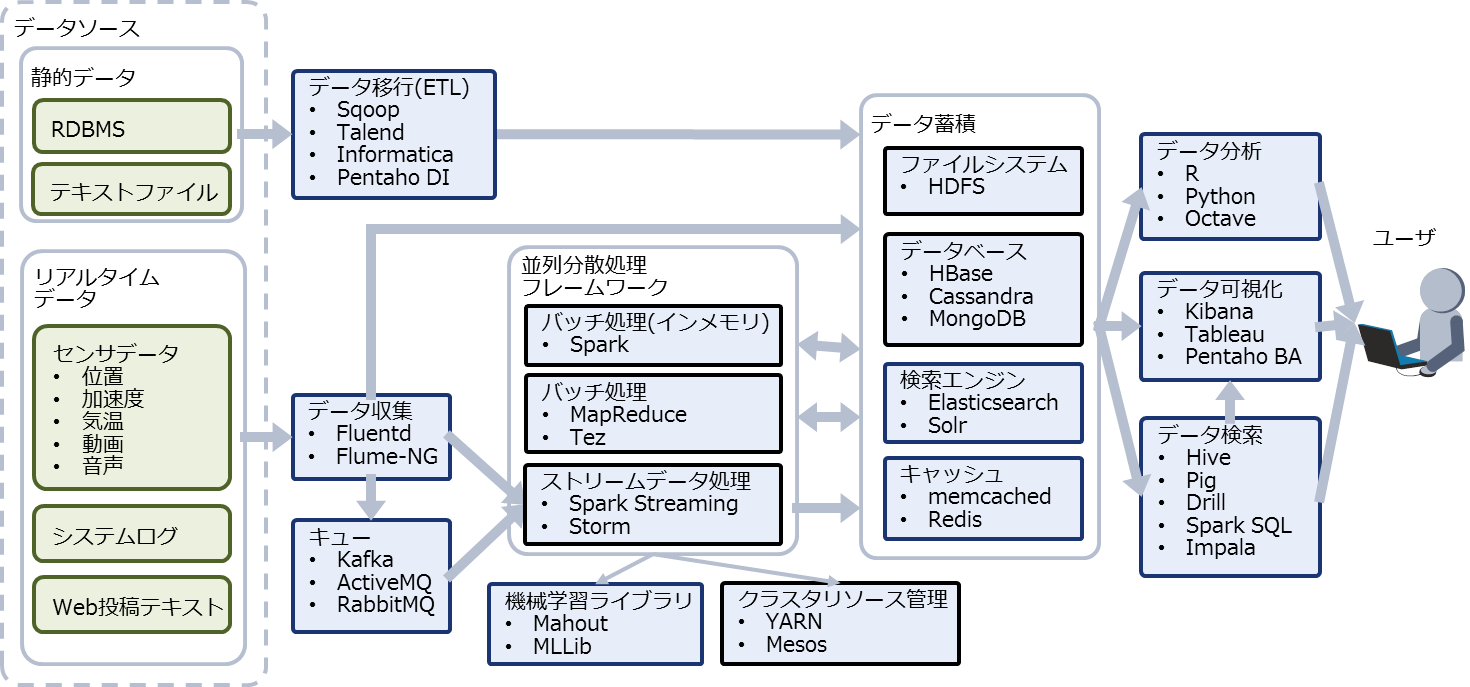
図7:Sparkを取りまくビッグデータ関連OSSの例
本連載の検証シナリオ
ユースケース
本連載では、Spark Streamingを中心としたOSSのユースケースとして、運動リズムに合った音楽を自動選曲する音楽配信サービスを想定します(図8)。本サービスの利用者は、歩く、走る、座る、階段を登るなどの運動状態に合わせてお気に入りの曲を聞くことができ、体と音楽の一体感を楽しみながら活動できます。
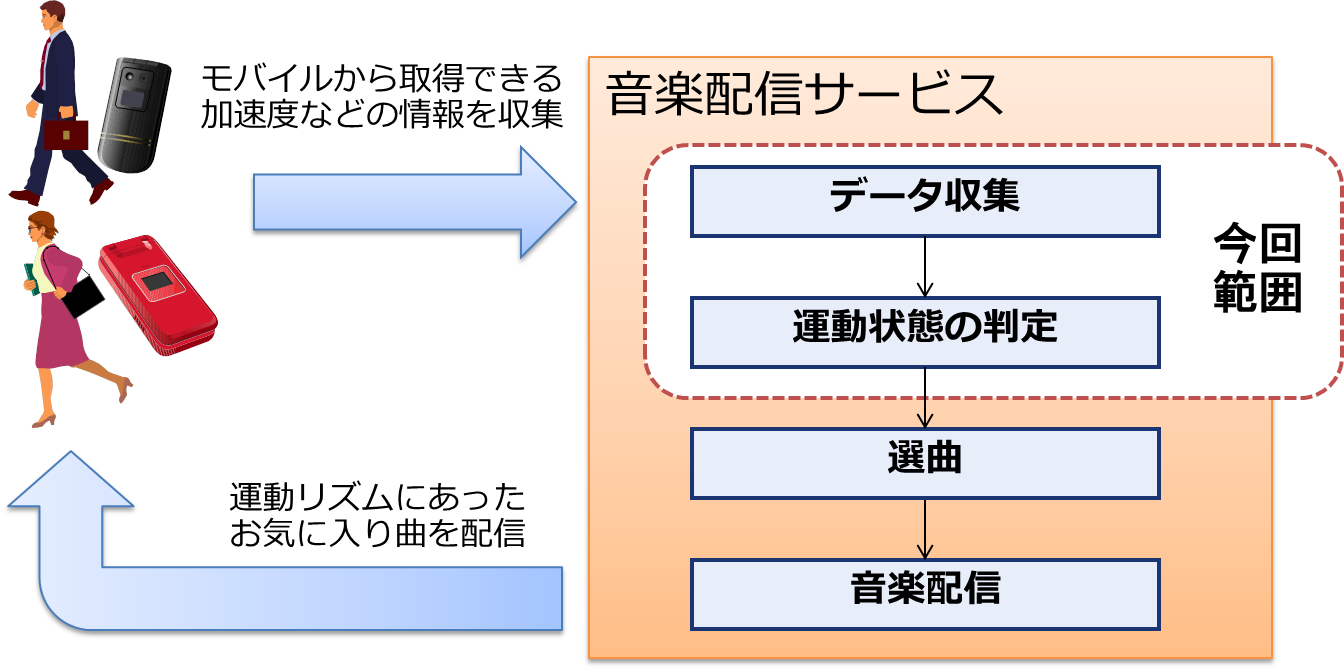
図8:検証シナリオ(音楽配信サービス)
本サービスを実装するシステムでは、モバイルから加速度などのデータを収集して対象者の動作を時々刻々と判定し、運動リズムが切り替わるタイミングを検知した際に新たな曲を選曲して配信します。評価対象とする処理範囲は、データ収集から動作判定までとします。
想定要件
このユースケースでは、以下の想定要件を設定しています。
- サービスの同時利用者数は10,000人とする
- 入力データは最低1秒間隔で音楽配信サービスに通知される
- 動作の変化を判断した場合は5秒以内に選曲を行う
選択したOSS
ユースケースを実現するために選択したOSSは表3のとおりです。また、OSS間の接続に利用した連携ライブラリを表4に、各OSSの位置付けを図9に示します。
表3:選択したOSS
| # | 名称 | 説明 | バージョン |
|---|---|---|---|
| 1 | Spark | 並列分散処理フレームワーク | 1.6.0 ※1 |
| 2 | Spark Streaming | ストリームデータ処理用Sparkライブラリ | 1.6.0 ※1 |
| 3 | MLlib | 機械学習用Sparkライブラリ | 1.6.0 ※1 |
| 4 | YARN | Sparkクラスタ構成時のリソース管理 | 2.6.3 |
| 5 | HDFS | 分散ファイルシステム(YARNの前提ソフトウェア) | 2.6.3 |
| 6 | Kafka | データのキューイング | 0.9.0.0 ※2 |
| 7 | Elasticsearch | データの蓄積と検索 | 1.7.5 |
| 8 | Kibana | データの可視化 | 4.1.5 |
※1:Spark 1.6.0 Pre-built for Hadoop 2.6に同梱
※2:Spark 1.6.0がサポートするのはKafka 0.8.2.1だが、今回は最新版のKafka 0.9.0.0を使用
表4:OSS間の接続用ライブラリ
| # | 名称 | 説明 | バージョン |
|---|---|---|---|
| 1 | elasticsearch-spark | SparkがElasticsearchへデータ格納リクエストを発行 | Scalaバージョン: 2.10 ライブラリバージョン: 2.2.0 |
| 2 | spark-streaming-kafka | SparkがKafkaからデータを取得 | Scalaバージョン: 2.10 ライブラリバージョン: 1.6.0 |
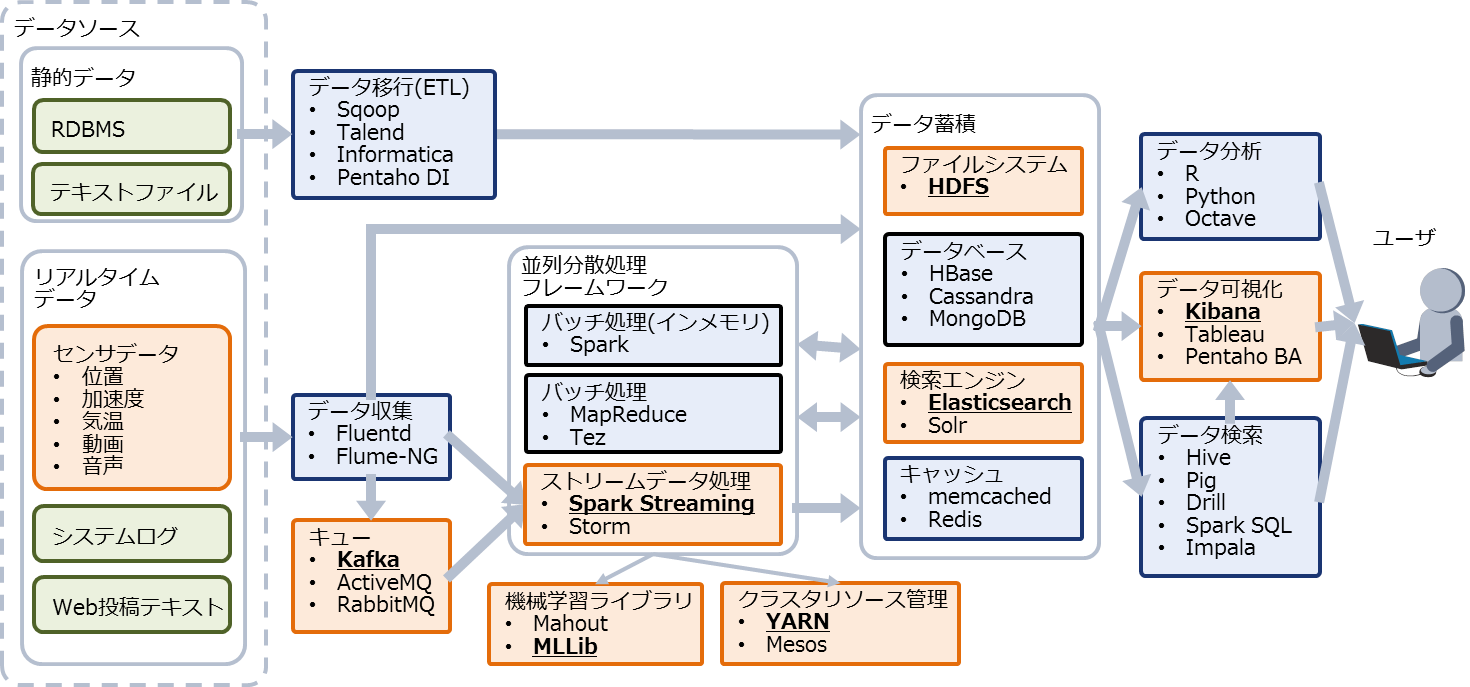
図9:選択したOSSの位置付け
システムの概要
システムの概要を図10に示します。データ収集サーバがモバイルから加速度などのデータを収集し、そのデータをキュー(Kafka)に蓄積します。Spark Streamingはキューに蓄積されたデータを取り出し、MLlibで学習済みのモデルを使用して運動状態を判定、その結果をElasticsearchに格納します。
また、サービスのシステム管理者が判定結果を確認するためにKibanaを使用します。Spark Streamingをクラスタ上で動作させるための基盤はYARNとHDFSです。
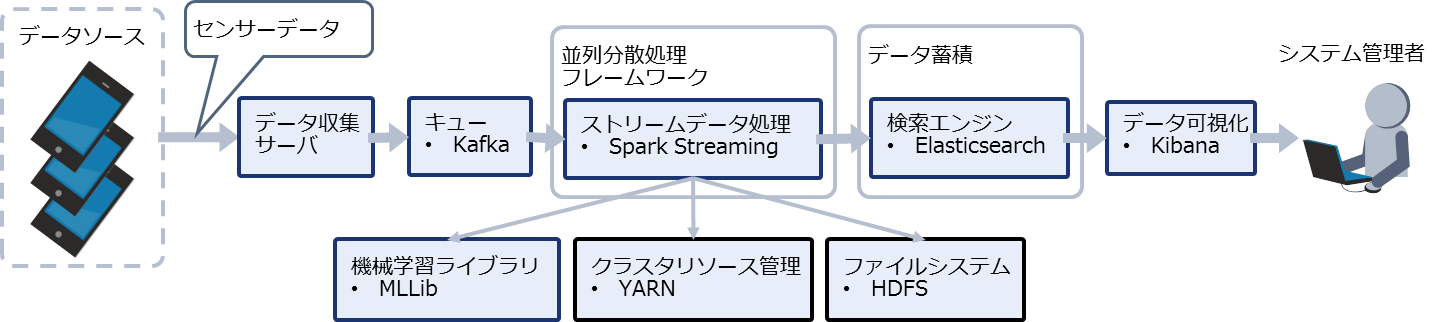
図10:構築するシステムの概要
おわりに
今回はSpark Streamingの概要と検証シナリオ、およびユースケースのシステム概要を解説しました。次回はシステムの詳細構成と選択したOSSの詳細、および検証の進め方を解説します。
- この記事のキーワード
この記事をシェアしてください
バックナンバー
この記事の筆者
筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
