第3段階:エミュレーターで動かしてみる。
第3段階:エミュレーターで動かしてみる。
まずはWordCountプログラムをjarファイルにまとめなければなりません。
1. クラスあるいはパッケージを右クリックして、”Export…”をクリックします。
2. “Java”→”JAR file”を選択し、”Next”をクリックします。
3. JARファイルの出力先を指定します。ここでは"C:\work\maniax.jar"としました。
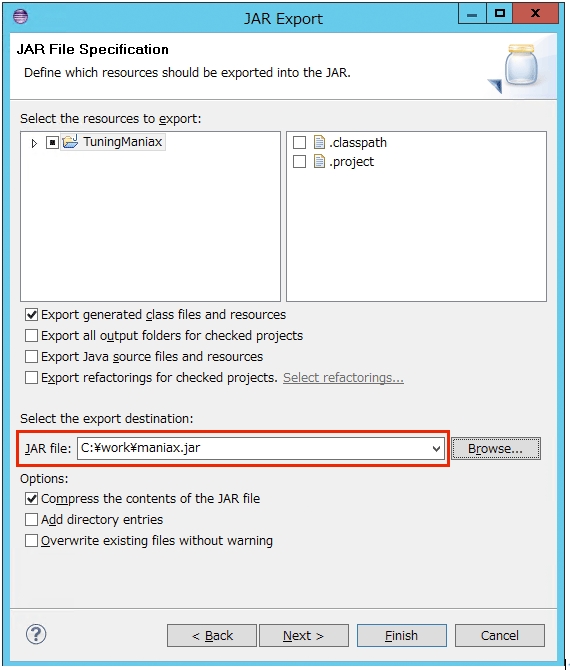
4. “Finish”をクリックします。
これで、JARファイルが出力できましたので、”Hadoop Command Line”で実行してみましょう。
1. デスクトップの”Hadoop Command Line”アイコンをクリックして、HDInsight Emulator用のコマンドプロンプトを出してください。
2. 入力ファイルは、先ほど事務局のBLOBストレージからコピーしたものを使いましょう。所在を確認してみます。
c:\work>hadoop fs -lsr /examples/logs/2014*
-rw-r--r-- 1 ksasaki supergroup 104491633 2014-04-25 15:28 /examples/logs/20140101-m-00000
-rw-r--r-- 1 ksasaki supergroup 105489682 2014-04-25 15:28 /examples/logs/20140101-m-00001
<以下略>ありますね。
3. 次のコマンドを実行します。とりあえずのテストですから、入力ファイルは一つだけとします。結果は/out/test1へ出力してみます。
hadoop jar JARファイル名 org.apache.hadoop.examples.UriCount /examples/logs/20140101-m-00000 /out/test1これで、ジョブの実行が始まるはずです。
4. ジョブが完了したら、出力ファイルを確認してみます。
c:\work>hadoop fs -ls /out/test1
Found 3 items
-rw-r--r-- 1 ksasaki supergroup 0 2014-04-25 23:35 /out/test1/_SUCCESS
drwxr-xr-x - ksasaki supergroup 0 2014-04-25 23:34 /out/test1/_logs
-rw-r--r-- 1 ksasaki supergroup 5235601 2014-04-25 23:35 /out/test1/part-r-00000_SUCCESSというのは、ジョブが正常に完了したことを示すフラグファイルです。
part-r-00000がReducerの出力した結果ファイルです。内容を確認してみましょう。全部出力すると多すぎるので、-tailコマンドを使って最後だけ見てみます。
c:\work>hadoop fs -tail /out/test1/part-r-00000
/xref/org/apache/hadoop/metrics2/MetricHistogram.html 11
/xref/overview-summary.html 9
/xref/stylesheet.css 13
/yoko/index.html 11
/~jim/projects.html 9URIと、その出現回数がカウントされていますね!
では次に、「TOP10の集計」をしてみましょうか。
第4段階:TOP10の集計
これを実現するには、Reducerを改造する必要があります。そのためにまず、MapperからReducerへと至るデータの流れを再確認しましょう。
今、解析対象のログファイルに、”/foo”というURIが3回、”/bar”が2回、”/baz”が4回含まれているとしましょう。
Mapperは受け取ったレコードを処理した結果、次のようなkey-valueペアを出力します。
{/foo => 1}
{/bar => 1}
{/baz => 1}
{/foo => 1}
{/baz => 1}
{/bar => 1}
{/baz => 1}
{/foo => 1}
{/baz => 1}Mapperの出力を受け取ったHadoopはこれを、キーでソート・集約し、Reducerのreduceを呼び出します。イメージとしては次のような感じです。
reduce({/foo => [1,1,1]})
reduce({/bar => [1,1]})
reduce({/baz => [1,1,1,1]})※この時、同じキーを持つ値はまとめて一度のreduce呼び出しで処理されます。
WordCountの場合、キーごとの数値列を全部足し込んで出力するだけです。値の比較が不要ですから、極めてシンプルです。
「TOP10の集計」をする場合は、「どのキー(Uri)はいくつあった」というのを全部覚えておいて、最後の上位10エントリを抽出する必要があるので、一手間増えます。
どこに「一手間」を記述すべきなのか、Reducer実行の流れを疑似コードで見てみましょう。このような3段階の処理になっていて、それぞれをオーバーライドできるようになっています。Template Methodパターンですね。
setup(context);
while(hasMoreKeys){ reduce(key, values);}
cleanup(context);となれば、
- reduceメソッドに「Uriごとの出現回数を全部覚えておく」処理を追加し、
- cleanupメソッドで「TOP10の集計」をする。
という感じが良さそうですね。
やってみましょう。
まず、reduceメソッドに関しては、次のように変更します。
- 複数回のreduce呼び出しにわたって、Uriとその出現回数を保持しておくHashMapをフィールド”uris”として追加。
- reduceメソッド内では、context.writeを呼び出さない。
結果として、reduceメソッドは以下のようにシンプルになりました。
private HashMap<String, Integer> uris = new HashMap<String, Integer>();
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
uris.put(key.toString(), sum);
}次に、集計処理を実装すべく、cleanupメソッドをオーバーライドします。実行すべき処理は、
- urisフィールドを、値の降順にソート。
- ソート結果の先頭10件を出力(context.write)
という二つだけなのですが、Comparator#compareをオーバーライドする処理等で少し長ったらしくなっていますね…
@Override
protected void cleanup(Context context) throws IOException,
InterruptedException {
List<Entry<String, Integer>> l
= new ArrayList<Entry<String, Integer>>(uris.entrySet());
Collections.sort(l, new Comparator<Entry<String, Integer>>() {
@Override
public int compare(Entry<String, Integer> o1,
Entry<String, Integer> o2) {
return o2.getValue().compareTo(o1.getValue());
}
});
Text key = new Text();
for (int i = 0; i < 10; i++) {
Entry<String, Integer> e = l.get(i);
key.set(e.getKey());
result.set(e.getValue());
context.write(key, result);
}
}これを、先ほどと同じようにHDInsight Emulatorで実行してみると、次のような結果が得られました。
/index.html 1023
/docs/r2.2.0/hadoop-yarn/hadoop-yarn-site/index.html 176
/docs/r2.2.0/hadoop-yarn/hadoop-yarn-site/WritingYarnApplications.html 170
/docs/r2.2.0/hadoop-yarn/hadoop-yarn-site/MapredAppMasterRest.html 169
/docs/r2.2.0/hadoop-yarn/hadoop-yarn-site/WebServicesIntro.html 153
/docs/r2.2.0/hadoop-yarn/hadoop-yarn-site/YARN.html 152
/docs/r2.2.0/hadoop-yarn/hadoop-yarn-site/WebApplicationProxy.html 151
/docs/r2.2.0/hadoop-yarn/hadoop-yarn-site/ResourceManagerRest.html 146
/docs/r2.2.0/hadoop-yarn/hadoop-yarn-site/NodeManagerRest.html 146
/docs/r2.2.0/hadoop-auth/images/logos/maven-feather.png 133アクセス数の多い順に10件、出力できましたね!
本物のHDInsightで動かすには?
エミュレーターではなく、Azure上のHDInsightで動かす方法は、前回の記事で説明したサンプルプログラムの実行方法と同じです。EclipseからエクスポートしたJARファイルを、HDInsightで使用するBLOBストレージへ配置したうえで、ジョブを実行してください。
工夫のしどころは?
さて、全員「Azure上のHDInsight」という同じ土俵で戦う今回のTuningManiax、ライバルに差を付けるためにはどんな工夫の余地があるのでしょうか。考えられるポイントをいくつか挙げておきます。
- 複数の問題を一度のジョブで処理する。
- 今回、問題は3つあります。個別に3回のジョブとして実行しても良いですが、うまくまとめて一つのジョブとして実行することも可能かもしれませんね。
- Combinerを組み込む。
- Mapperが出力したkey-valueペア群は、Reducerに渡される前に大規模なソート・集約処理が行われます。この処理負荷を軽減するための”Combiner”と呼ばれるクラスを定義することが可能です。
- Hadoopの実行時パラメータの調整。
- Mapperの数やJVMのヒープサイズなど、変更可能な設定項目はいくつもありそうです…
ここには書きませんが他にも工夫ポイントはありますよ!ぜひ、いろいろ試して高速なMapReduce処理を実現してください!
【関連リンク】
- この記事のキーワード
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
