TFXを使った機械学習パイプラインの構築(実装編その3)
連載の6回目となる今回は、前回に引き続きTFXを使ってKubeflow上で動かす機械学習パイプラインを構築していきます。
2022年2月25日 6:00
はじめに
前回は、TFXを使った機械学習パイプラインの構築のうち、「モデル学習」と「チューニング」で利用するTFXコンポーネント解説や実装を行いました。「実装編」の3回目である今回は、前回作成したモデルの検証と出力で利用するTFXコンポーネントの解説や実装を行い、モデル開発のパイプラインを完成させます。
機械学習パイプラインの構築(ハンズオン)
本稿では、機械学習パイプラインのうち「モデル作成」の最後のステップとなる「モデル検証」と「学習済みモデル」の出力について解説します。

図1:機械学習パイプラインの各ステップとコンポーネント
赤枠の部分が本稿の範囲となり、黒枠の部分は実装済みであることが前提となります。前回作成したモデルを検証するステップとパイプラインの最終的な成果物となるモデルを出力する処理をパイプラインに組み込んでいきます。
解説の流れ
「モデル検証」のステップと「学習済みモデル」の出力で利用するTFXコンポーネントについて、実装例を交えて解説します。
- モデル検証:Evaluatorコンポーネントを使ってモデル検証ステップの解説と実装を行います。ここでは、モデルの評価指標やEvaluatorコンポーネントで利用できるTensorFlow Model Analysis(以下、TFMA)というモデル分析ツールの使い方も併せて解説します
- 学習済みモデルの出力:Pusherコンポーネントを使って、学習済みモデルを保存する場所にアップロード(プッシュ)します
機械学習パイプライン構築の進め方
前回と同様に、TFXの「インタラクティブパイプライン」という機能を利用し、TFXコンポーネントの実行結果を確認しながら段階的に実装を進めていきます。以降、解説で用いるコード例を上から順番にJupyter notebookのセルに入力し実行していくことで、機械学習パイプラインの構築が進んでいきます。
事前準備
前回利用したノートブックサーバーおよびPython3のノートブック(.ipynb)ファイルを引き続き利用します。
モデル検証
EvaluatorというTFXコンポーネントを使って、モデル検証のステップを機械学習パイプラインに組み込む方法について解説します。
- Evaluatorとは
Evaluatorはモデル検証を行うTFXコンポーネントです。TFMAを内包しているため、モデルの予測値を評価データ上で評価することや詳細なモデル分析ができます - モデル検証のステップで行うモデルの評価と分析
モデル検証のステップでは、学習済みのモデルを本番環境にデプロイする前にその性能を複数の指標で評価したり、モデル分析ツールを使って多角的にモデルの性能を分析したりします。
前回解説したように、モデル学習やハイパーパラメータを調整する時もモデルの性能を評価する指標を確認しながら進めますが、その際には指標の一つである正解率(Accuracy)を使うことが多いでしょう。しかしながら、単一の指標では評価用のデータ全体に対する平均的な性能を表すため、本質的な詳細を把握できないことがあります。例えば本連載で扱っているような人々に関するデータを扱う場合、次のような点を考慮する必要があるでしょう。
- 性別によって予測結果の偏りはないか(本連載で扱っているデータの場合、性別によって年収が5万ドル未満と予測される結果の割合に大きな偏りがないか)
- 年齢によって予測精度に大きな差異はでていないか
これらの点が考慮できていないモデルを利用してしまうと、人々に不公平な体験をさせたり、意図しない差別的な振る舞いを生じさせたりする可能性があります。評価用のデータ全体の平均的な性能と併せて、複数の指標を使ってモデルの公平性(バイアス)に関しても性別や年齢などの属性・グループごとにスライスして注意深く分析します。そして、問題ないことが確認できて初めて本番環境にデプロイできます。
- 分類問題における主な評価指標
モデル検証のステップでは、最初に評価指標の選択から行います。今回のような2値(年収が5万ドルを超えるか否かの2値)の分類では、主に次の指標でモデルを評価します - Accuracy(正解率)
モデル学習時やチューニング時に使用したAccuracy(正解率)は正解したサンプル数を全体のサンプル数で割ることで求められます
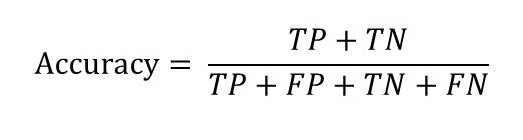
Accuracy
計算式に示す指標は次のとおりです。
| 指標 | 説明 |
|---|---|
| TP(TruePositives) | 真陽性。正解ラベルと予測がともに正(1)だったもの |
| FP(FalsePositives) | 偽陽性。正解ラベルが負(0)なのに正と予測してしまったもの |
| TN(TrueNegatives) | 真陰性。正解ラベルと予測がともに負だったもの |
| FN(FalseNegatives) | 偽陰性。正解ラベルが正なのに負と予測してしまったもの |
これらの指標は次のように混同行列として示すことができます。
| 混同行列 | 予測 | ||
| 正 | 負 | ||
| 正解ラベル | 正 | TP | FN |
| 負 | FP | TN | |
- Precision(適合率)
Precision(適合率)は予測結果が正であったサンプルのうち、どれだけ正しく予測できたかを示す指標です。
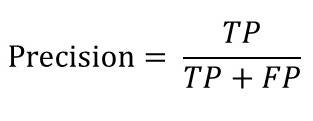
Precision
- Recall(再現率)
Recall(再現率)は正のラベルを持つ正解データのうち、どれだけモデルが正と予測できたかを示す指標です。
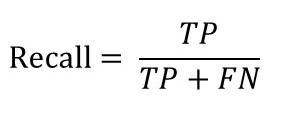
Recall
- F1Score(F1値)
F1ScoreはPrecisionとRecallの調和平均で求められます。PrecisionとRecallはトレードオフの関係になるので、その2つの調和平均を取ることで、統一的にモデルの性能を評価する指標です。
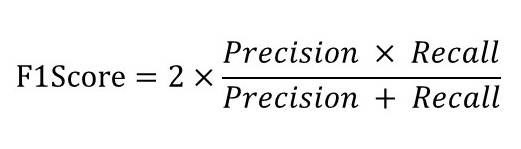
F1Score
- ROC-AUC
モデルの性能を示す他の指標として、ROC-AUCがあります。ROCは、TPR(True Positive Rate:真陽性率)とFPR(False Positive Rate:偽陽性率)に対してカットオフ値を変えながらプロットした曲線です。
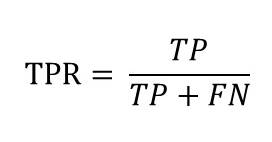
TPR

FPR
カットオフ値とは、モデルが出力する予測結果を正または負に割り当てるときの判断(例:0.5以上であれば正、未満であれば負という判断)に使う値です。そのカットオフ値を0から1の範囲で少しずつずらして、TPR, FPRを求めていきます。図2-1は前回「モデル学習」のステップで作成したモデルのROCをプロットした図です。
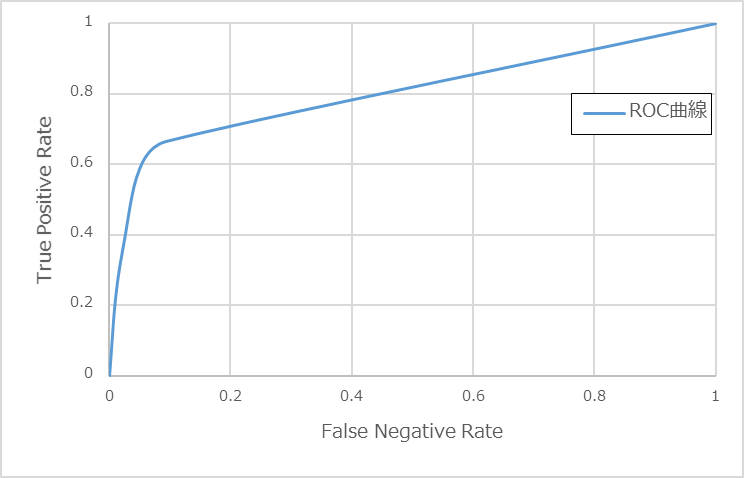
図2-1:ROC曲線
AUCは、図2-1でプロットした曲線の下の部分の面積を示しており、モデルの良し悪しの評価で利用します。AUCは0から1までの値をとり、1に近づくほど良く、0.5はランダムになっていることを意味します。
Evaluatorではこれらの指標を利用して評価用のデータ全体やスライスしたデータに対するモデルの性能を評価します。
それでは、Evaluatorの定義を記述します。Evaluatorでは主に次の入力を必要とします。
- 「データ分割」のステップで出力した評価用データ
- 前回「チューニング」のステップで作成した学習済みモデル
- Evaluatorの設定
Evaluatorの設定では、モデル評価時に利用するラベルの項目名や評価指標、モデル分析時にデータをスライスするための仕様を設定します。
slices = [tfma.SlicingSpec(),
tfma.SlicingSpec(feature_keys=['gender_0_xf']),
tfma.SlicingSpec(feature_keys=['age_xf'])
]
eval_config = tfma.EvalConfig(
model_specs = [tfma.ModelSpec(
label_key='income_xf',
preprocessing_function_names=['transform_features']
)],
slicing_specs = slices,
metrics_specs = [
tfma.MetricsSpec(metrics=[
tfma.MetricConfig(class_name='ExampleCount'), #サンプル数
tfma.MetricConfig(class_name='Precision'),
tfma.MetricConfig(class_name='Recall'),
tfma.MetricConfig(class_name='F1Score'),
tfma.MetricConfig(class_name='AUC'),
tfma.MetricConfig(class_name='FalsePositives'),
tfma.MetricConfig(class_name='TruePositives'),
tfma.MetricConfig(class_name='FalseNegatives'),
tfma.MetricConfig(class_name='TrueNegatives')
])
]
)
次にEvaluatorコンポーネントを実行します。
evaluator = tfx.components.Evaluator(
examples = example_gen.outputs['examples'],
model = trainer.outputs['model'],
eval_config = eval_config)
context.run(evaluator)
図2-2:Evaluatorの実行結果
Evaluatorコンポーネントの実行が完了するとTFMAで結果を確認できるようになります。なお、Jupyter notebookでTFMAを使用する場合は、ノートブック拡張機能をインストールして有効化する必要があります。
# ノートブック拡張機能をインストール
!jupyter nbextension enable --py widgetsnbextension
!jupyter nbextension install --py --symlink tensorflow_model_analysis --user
!jupyter nbextension enable --py tensorflow_model_analysis
# Evaluator の結果を TFMA に読み込み
eval_result = evaluator.outputs['evaluation'].get()[0].uri
tfma_result = tfma.load_eval_result(eval_result)
- TFMAでモデルの精度評価
まずは評価用データ全体に対する精度評価の結果を表示します。
tfma.view.render_slicing_metrics(tfma_result, slicing_spec=slices[0])
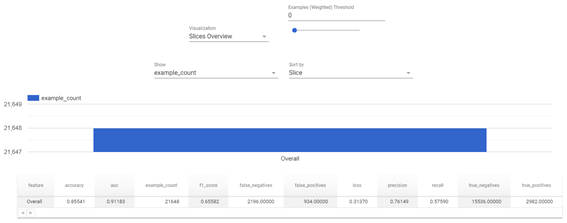
図2-3:TFMAによるモデル全体の分析結果
全体でみると、AUCが約0.91となっておりモデル精度は高く見えますが、Recallが約0.58と低いため、正解ラベルが正のデータに対して負と分類してしまう「偽陰性」の割合が多いことがわかります。実際にどのくらい負と分類してしまっているのかを次のように混同行列で確認してみます。
| 混同行列 | 予測 | 合計 | ||
| 正 | 負 | |||
| 正解ラベル | 正 | 2982 | 2196 | 5178 |
| 負 | 934 | 15536 | 16470 | |
| 合計 | 3916 | 17732 | 21648 | |
これは今回のデータセットが不均衡であることが大きな要因として考えらます。つまり、学習用のデータセットのラベルが正のデータより負のデータが多いため、負に分類する方向に傾いてしまったモデルになっていることがわかります。
次にモデルの公平性を確認するため、特徴量のグループごとにデータセットをスライスして確認します。まずは、性別の特徴量でスライスしてみます。
tfma.view.render_slicing_metrics(tfma_result, slicing_spec=slices[1])
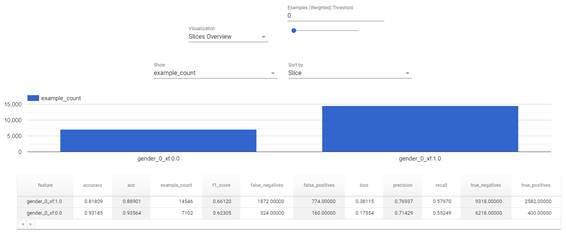
図2-4:性別でスライスしたTFMAの分析結果
性別の特徴量でスライスした結果、次のことがわかります。ここでは「性別によって予測結果の偏りはないか」を確認するためTPR(Recall)の値を確認します。
※「gender_0_xf: 1.0」が男性、「gender_0_xf:0.0」が女性
- 性別に依らずRecallは低い
- モデル全体の傾向と同じのため、性別による大きな偏りはない
次に年齢の特徴量でスライスします。
tfma.view.render_slicing_metrics(tfma_result, slicing_spec=slices[2])
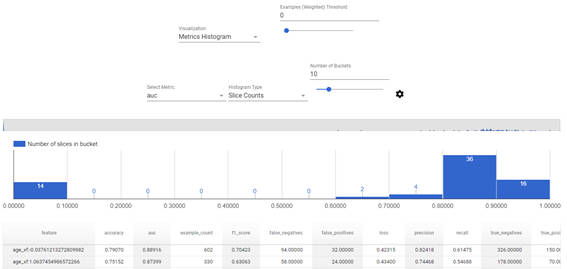
図2-5:年齢でスライスしたTFMAの分析結果
「Visualization」を「Metrics Histogram」に切り替えると評価結果の分布が可視化されます。「Select Metric」で表示する評価指数の切り替えや「Histogram Type」で表示する件数の切り替えができます。「Number of Buckets」では分布のバケット(どこまで細かく分けるか)が設定できます。
ここでは「年齢によって予測精度に大きな差異は出ていないか」を確認するために「Select Metric」をAUCに、「Histogram Type」をSlice Countsに切り替えます。結果を確認すると、ほとんど年齢のAUCは0.6以上となっていますが、14個の年齢についてはAUCが0ということがわかります。
グラフの下の表で評価結果の一覧を確認でき、項目名をクリックすることでソートも可能です。そのため、AUCについてソートすることでAUCが0だったデータについて確認してみます。
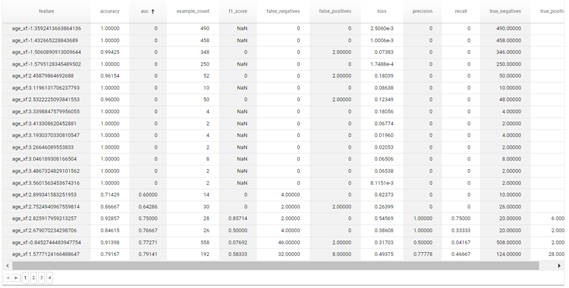
図2-6:年齢でスライスしたデータの詳細分析結果
実際の数値を見ると、AUCが0になっている年齢のデータについては、ほとんどを負と予測して正解しているだけのようです。正解率(Accuracy)は高くても実際に正しく予測できるのか、別の評価用データを使って評価する必要があるでしょう。
- この記事のキーワード
この記事をシェアしてください
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
