BigQueryでビッグデータを解析する
BigQueryとはBigQueryは、Google Cloud Platformで提供されるビッグデータ解析プラットフォームです。1PB(ペタバイト)あるいは10億行といった膨大なデータに対して、集計・分析処理を極めて高速に実行できます。処理はSQL風のクエリ言語で記述します。処理対象のデータは、
2015年8月27日 19:55
BigQueryとは
BigQueryは、Google Cloud Platformで提供されるビッグデータ解析プラットフォームです。1PB(ペタバイト)あるいは10億行といった膨大なデータに対して、集計・分析処理を極めて高速に実行できます。処理はSQL風のクエリ言語で記述します。
処理対象のデータは、リレーショナルデータベース(RDB)と同様に「テーブル」としてBigQueryに保持されます。つまり、事前にデータ構造をスキーマとして定義しておき、それに沿ったデータが独立したレコードとして登録されます。
BigQueryの特徴のひとつは、内部的にカラム指向データ構造を持っているという点です。一般的なRDBは、性質の異なるカラムを並べ、1件のレコードをひとまとまりとして格納するレコード指向データ構造です。それに対してBigQueryでは、レコードを分解し、カラムごとに格納します。
カラム指向データ構造には、性質の同じデータをまとめることにより圧縮効率が高まる他、クエリに対し必要なカラムにのみアクセスできるため、データアクセスが最小限ですむという利点があります。実際、BigQueryの料金はアクセスしたカラムのデータ量に応じて発生するので、これは重要な点です。以下の表に、BigQueryの料金体系についてまとめます。
表1:BigQueryの料金体系
| リソース | 料金 |
|---|---|
| データのインポート | 無料 |
| データのエクスポート | 無料 |
| ストレージ | 1GBあたり$0.020/月 |
| クエリ(月ごとに1TBの無料利用枠あり) | アクセスしたデータ量1TBあたり$5 |
| Streaming Insert | 200MBあたり$0.01 |
BigQueryへのレコード登録のためのアップロード、あるいは処理結果のダウンロードといったトラフィックについては無料です。またBigQueryに格納したデータ量に基づく料金は、1GBにつき$0.02/月で、Google Cloud StorageのDRAストレージと同等となっています。クエリに基づく料金は、前述したとおりアクセスしたカラムのデータ量1TBあたり$5で、テーブル全体のデータ量とは関係ありません。Streaming Insertはデータのアップロード方法によって発生しうる料金ですが、のちほど詳しく解説いたします。
また、大規模・長時間に渡る処理については、あらかじめ問い合わせの上契約することで、70%のコストダウンが可能です。詳しくは公式ページ(https://cloud.google.com/bigquery/?hl=ja)を参照してください。
BigQueryを体験する
それでは、BigQueryの利用方法や料金体系について確認するため、実際に使用してみましょう。他のGoogle Cloud Platformのサービスと同じく、BigQueryにもコマンドラインツールでの操作、APIでの操作、Web UIでの操作が提供されています。ここではWeb UIからBigQueryを使用してみます。
BigQueryのテーブルはプロジェクトの配下に作成しますので、プロジェクトを選び、プロジェクトダッシュボードに移動します。ここで左カラムの下部から[ビッグデータ > BigQuery]と選択するか、右の画面から[BigQueryを試す]をクリックすると、Big QueryのWeb UIが表れます。
図1:BigQueryトップ画面
左側にある[COMPOSE QUERY]というボタンをクリックすると、クエリの入力画面が表れます(図2)。
図2:BigQueryクエリ画面
ここにSQL風のクエリを記述すれば、結果が得られます。このプロジェクトにはまだデータを登録していませんが、BigQueryではサンプルデータが用意してあるため、クエリを体験することができます。左下の「publicdata:samples」をクリックし、wikipediaを選んでみましょう(図3)。
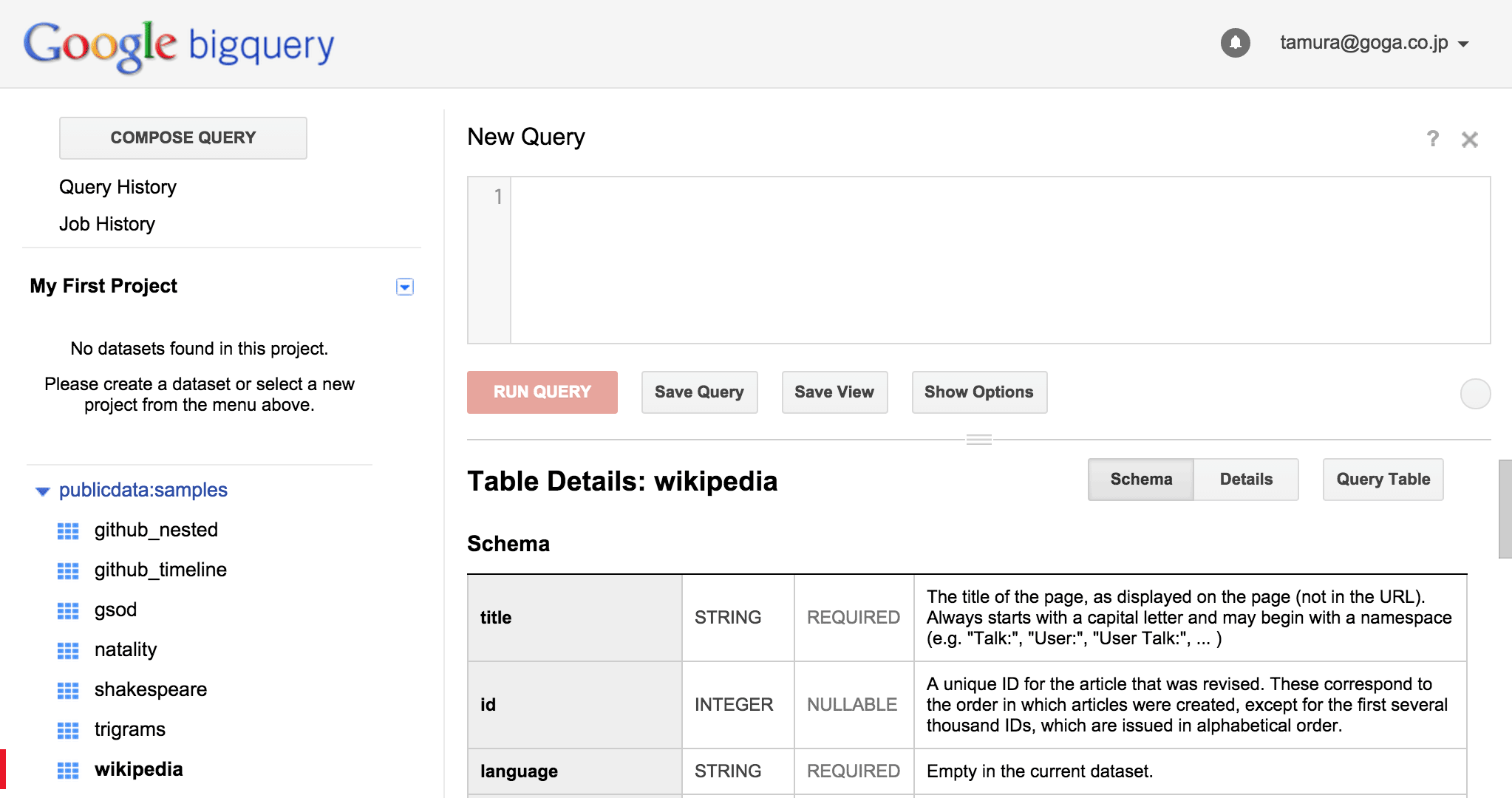
図3:サンプルデータからWikipediaスキーマを選択
クエリ入力フォームの下でテーブルの詳細が確認できます。titleというカラムがあるので、まずはこれを利用してレコードの数を数えてみましょう。
SELECT COUNT(title) FROM publicdata:samples.wikipedia;
と入力し、[RUN QUERY]を押し、少し待つと下部に結果が表示されます(図4)。
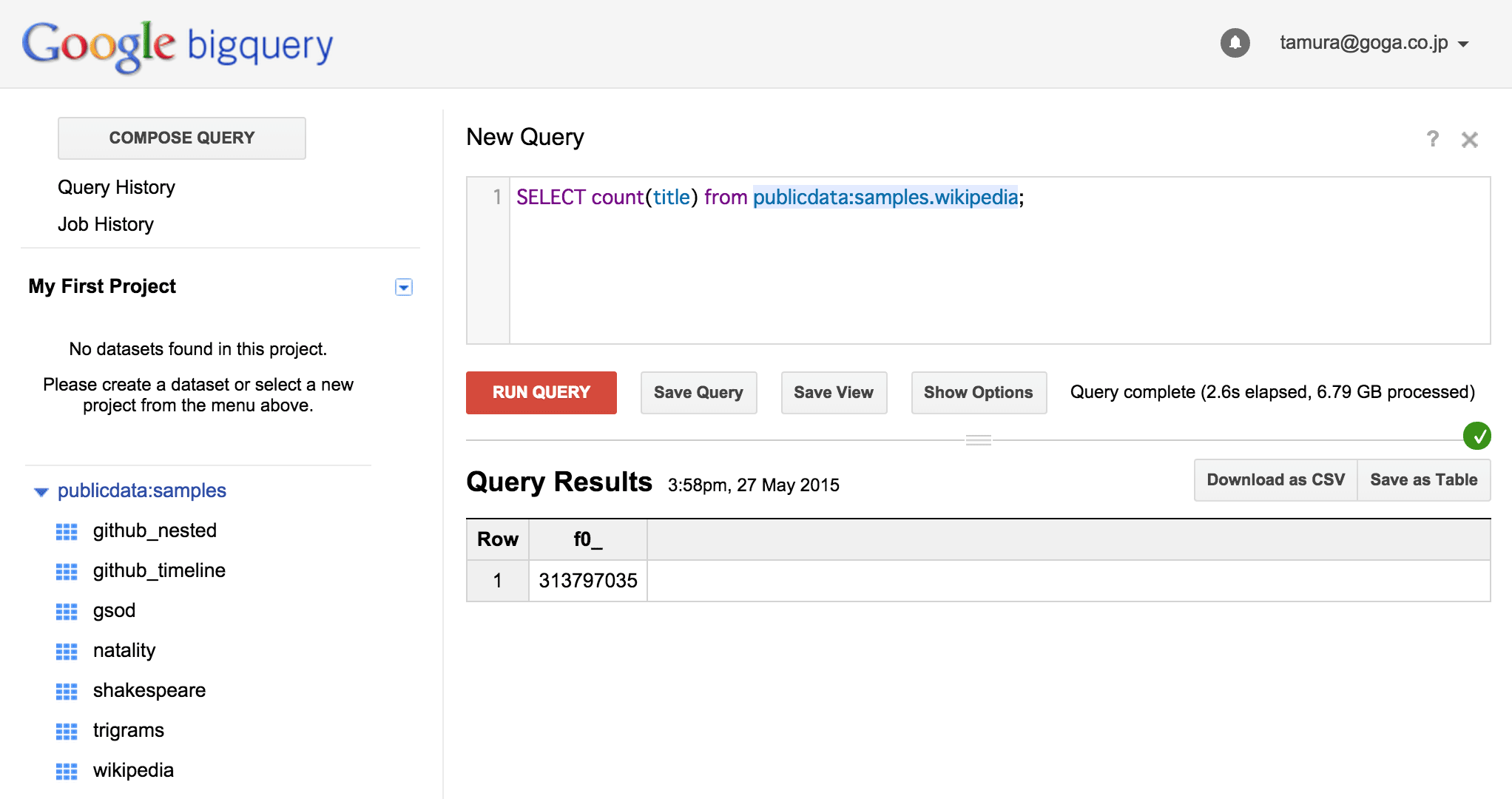
図4:クエリの実行結果が表示される
「f0_」の項がCOUNTの結果で、このテーブルには3億レコードほど含まれていることがわかります。また[Show Options]ボタンの右に「Query complete (2.6s elapsed, 6.79 GB processed)」と表示されています。これは前述のクエリに対し処理時間は2.6秒、アクセスしたデータ量(今回の場合titleカラム全体の量)が6.79GBという意味です。
それでは、クエリの条件を変えるとどうなるでしょうか?
SELECT title FROM publicdata:samples.wikipedia LIMIT 5;
と入力し、titleカラムの先頭5件を取得してみましょう(図5)。
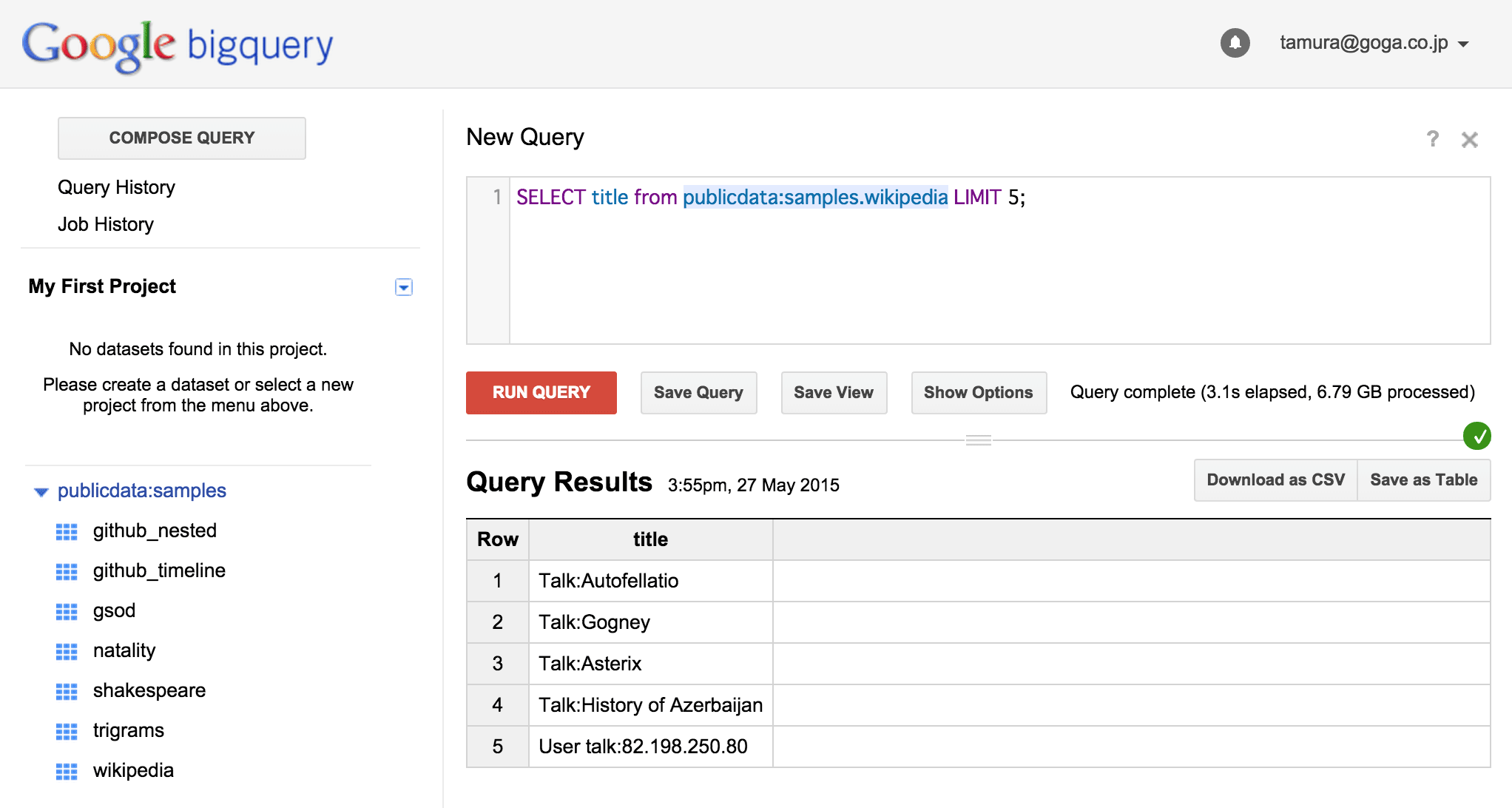
図5:取得するデータを先頭の5件に限っても、データ量は変わらない
5件のtitleの他、「Query complete (3.1s elapsed, 6.79 GB processed)」と表示されました。6.79GBの部分は、前述のクエリと同じです。このように、BigQueryでは条件によらず、クエリに表れたカラムのデータすべてにアクセスします。基本的に、クエリの条件によってアクセス範囲を狭めることはできないため、大規模データ処理のためのクエリを試行錯誤する段階では、小さなテーブルを別途用意すると良いでしょう。
ただし、場合によっては「Table Decorator」という機能によりアクセス範囲を制限することも可能です。これについては後述します。
- この記事のキーワード
この記事をシェアしてください
関連記事
Google Driveと Cloud DatastoreのデータをBigQueryで使用する
2015年5月8日 18:05
PostgreSQLのログをFluentdで収集する
2014年10月4日 0:30
Railsでデータベースを扱うためのライブラリActive Recordについて学んでみた
2015年2月18日 18:00
MySQL Workbenchを使ってデータモデリングを学んでみよう
2014年1月14日 20:00
MySQL 5.6での機能強化点(その1) - パフォーマンスと使い勝手を大きく向上
2013年11月19日 20:00
リスト・プロパティを含むエンティティの永続化
2010年12月9日 20:00
バックナンバー
この記事の筆者

Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
