より高速にするために
より高速にするために
MapReduceの基本的な処理の流れは以上の通りですが、ほかにもいくつか高速化のための仕組みがあります。
・combiner
mapタスクの結果は一時ファイルに書き出され、reduce実行ノードに引き渡されますが、ファイルへの書き出しやネットワーク越しの転送はボトルネックになりやすいため、その量は極力少なくした方がパフォーマンスが良くなります。
combinerは、そのような場合に使うもので、map側で実行するreducerと言ます。よって、典型的にはcombiner はreducerのプログラムと同じになります。combinerを使うことでmapとreduceの間で渡されるデータ量を減少させることが期待できます。
combinerで集約されたデータは、再度reducerで集約されることになります。なので、combinerは、そのようなことをしても結果が変わらない場合(例えば合計値を求めるなど)で、かつそうした方が実行時間的に有利になる場合に使うことになります。
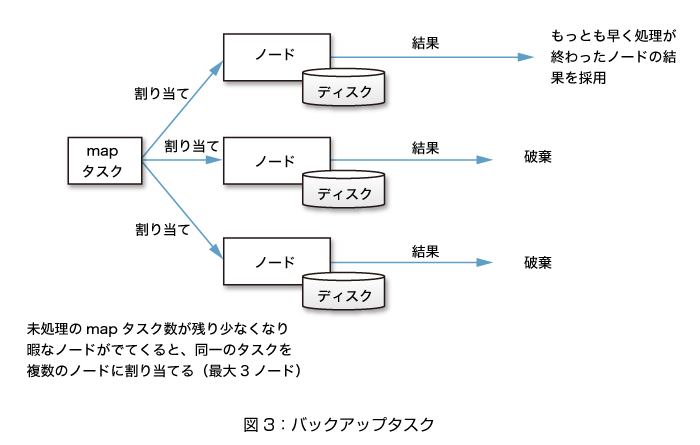
・バックアップタスク
多数のノードからなる分散システムでは、さまざまな理由により一部のノードの反応が遅くなってしまうということがあります(参考文献[1]では、ディスクの不調やノードの設定ミスなどが例として挙げられています)。
ノードの一台が極端に遅いと、MapReduceジョブ全体がその遅い一台に引っ張られてしまって全体の処理時間がのびてしまいます。これは望ましいことではありません。
そこで出てくるのがバックアップタスクという考え方です。実行中のタスクを、暇な別のノードにも割り当て、先に処理が終了した方の結果を採用する、というものです。
dddでは、同一のデータが必ず異なる3つのノードに複製されています。同じデータに対して同じタスクを適用すれば同じ結果になりますので、あるタスクを実行できるノードは3つあることになります。
通常、1つのタスクは、どれか1つのノードに割り当てられます。しかし、ジョブ全体の処理がおわりに近づくと暇なノードが出てくるため、その暇なノードにも同じタスクを割り当て、1つのタスクを複数のノードで実行させるのです。
こうすることにより、一部に遅いノードがあっても別のノードで処理できる可能性が増え、全体の処理時間が短縮されることがあります。
なお、dddではmapフェーズでのみバックアップタスクを割り当て、reduceについてはバックアップタスクの割り当てを行いません。
おわりに
連載後半では2回にわたり、IIJで開発したdddという分散システムを例にとって、分散キーバリューストアやMapReduceの仕組みについて説明しました。
クラウドコンピューティングのインフラには、必然的に大量のデータが集まってきます。その大量のデータを扱うために、スケーラビリティに優れた分散システムは、今後有力な選択肢になっていくと思われます。
一方で、分散技術を使ったデータベースは、「トランザクション処理に耐えるほどのデータ一貫性の保証は期待できない」という問題もあります。そのため、従来型のRDBMSも使われ続けることになるでしょう。
いずれにせよ、いろいろな技術を場合に応じてうまく使い分けるためには、その仕組みや特性を知っておいた方が良いことは言うまでもありません。本連載がその一助になれば幸いです。
【参考文献】
[1] 「MapReduce: Simplified Data Processing on Large Clusters(2004)」(http://labs.google.com/papers/mapreduce.html)(アクセス:2009.09)
[2] 「Hadoop MapReduce」(http://hadoop.apache.org/mapreduce/)(アクセス:2009.09)
関連記事
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
