はじめに
前回は実際にデータ処理基盤を構築し、シナリオに基づいた検証を実施しました。その結果、データ量が1日分と30日分の場合では、Spark 1.6よりもSpark 2.0の方が確かに高速に処理を実行できることを確認しました。
しかしデータ量が365日分の場合、Spark 2.0では処理時間が著しく増大し、Spark 1.6ではジョブが失敗してしまいました。今回は、なぜこのような結果になったのか、その原因を考察し対策を施します。
処理時間が増大した原因の考察
Sparkのデータ処理プロセス
処理時間の増大という性能問題を解決するには、その問題が発生している箇所と処理過程を特定する必要があります。そのため、まずはSparkのデータ処理の概要を解説します(図1)。
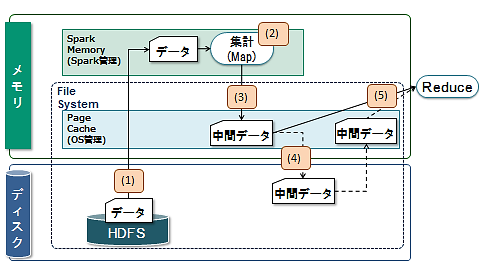
図1:シャッフル処理プロセスの概要
Sparkでは、Map処理からReduce処理へ遷移する際に中間データを生成・出力します。その処理を「シャッフル」と呼びます。このとき、中間データはファイル出力されるため「シャッフルファイル」とも呼ばれます。
図1の処理を順序に沿って解説します。
- HDFSから処理対象の消費電力量データをメモリ上に読み出します。このとき、Sparkが管理する領域にデータを読み出します。
- 読み出したデータをメモリ上で集計処理します。
- 処理後、中間データ(シャッフルファイル)をファイル出力しますが、ディスクへ書き込む前にメモリ上のOSが管理するページキャッシュ領域に書き込みます。
- その後、中間データをまとめてディスクへ非同期に書き込みます。
- 中間データはReduce処理が始まるときに読み出されます。中間データがページキャッシュに残っていればページキャッシュから、残っていなければディスクから読み出し、Reduce処理を実行します。
(4)の中間データがディスクへ非同期に書き込まれるとき、その中間データはメモリ容量に空きがあればページキャッシュに残ります。空きがない場合は即時にディスクへ書き込まれ、中間データはページキャッシュに残りません。つまり、中間データ出力時にメモリ容量に空きがない場合、中間データはReduce処理が始まるときにディスクから読み出されます。
性能問題発生個所の特定
検証結果は図2に示す通りでした。365日分のデータを処理すると、Spark 2.0では処理時間が著しく増大し、Spark 1.6ではジョブが失敗してしまいました。まずはこの理由を考察します。
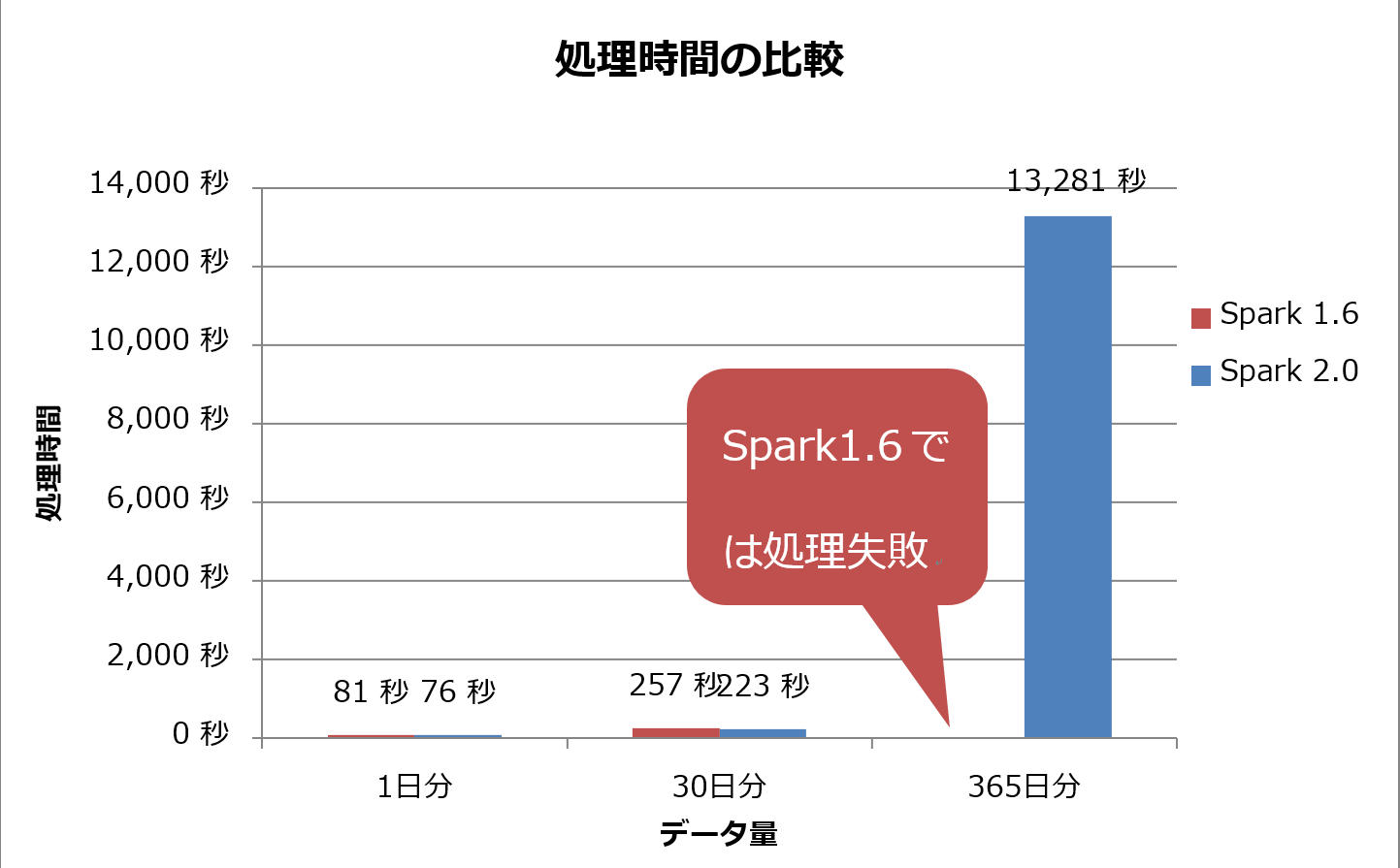
図2:Spark 2.0とSpark 1.6のデータ処理時間(再掲)
まず、Spark 2.0でデータ処理中のWorkerノードのディスクI/O量を時系列に表したチャートを図3に示します。Root ReadおよびRoot WriteはOSのインストール先であるRootディスクに対する読み込み/書き込みのアクセス、Data1 Read/Write~Data8 Read/WriteはHDFSに割り当てたディスクそれぞれに対する読み込み/書き込みのアクセスです。
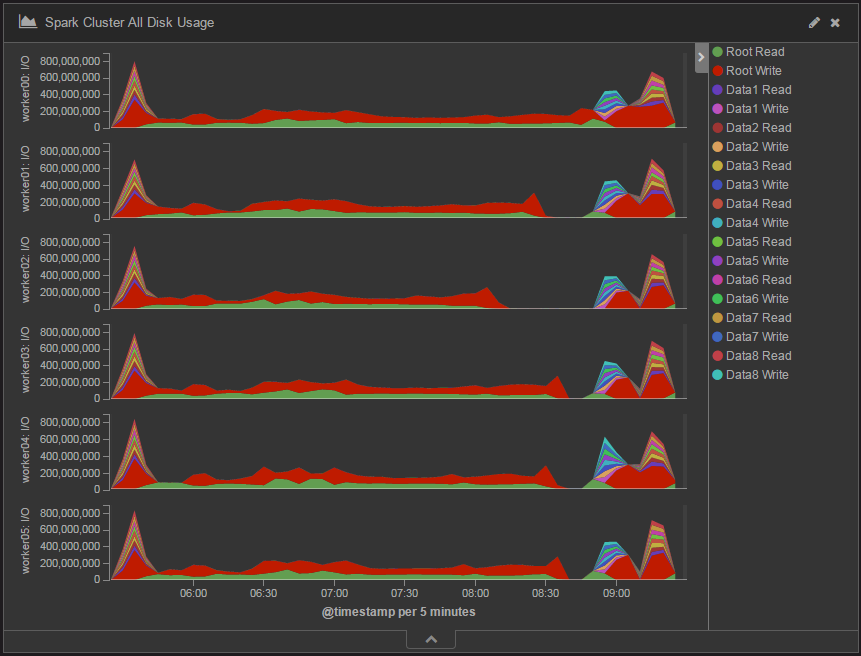
図3:Spark 2.0における365日分のデータを処理したときのディスクI/O量の変化
このチャートを見ると、各WorkerノードでRoot ReadとRoot Writeが大半を占めています。一方、Data1 Read~Data8 ReadおよびData1 Write~Data8 Writeは処理開始時のデータ読み込み時と処理終了時のデータ書き込み時しか行われていないことが分かります。
今回の集計処理で扱うデータは約1.3TB(レコード数36億5,000万件)で、かなりの分量があります。処理内容にもよりますが、一般に処理するデータ量が多いほど中間データ(シャッフルファイル)量も多くなります。これはシャッフルファイル出力先に初期設定されているRootディスクにI/Oが集中しているためと考えられます。
次に、データ処理中のWorkerノードのCPU使用率を時系列に表したチャートを図4に示します。CPU使用率の大半はI/O Wait、つまりディスクアクセス待ちで占められています。一方、Sparkの処理を表すUserは、ほぼ処理開始時と終了時にしかCPUを使用していません。
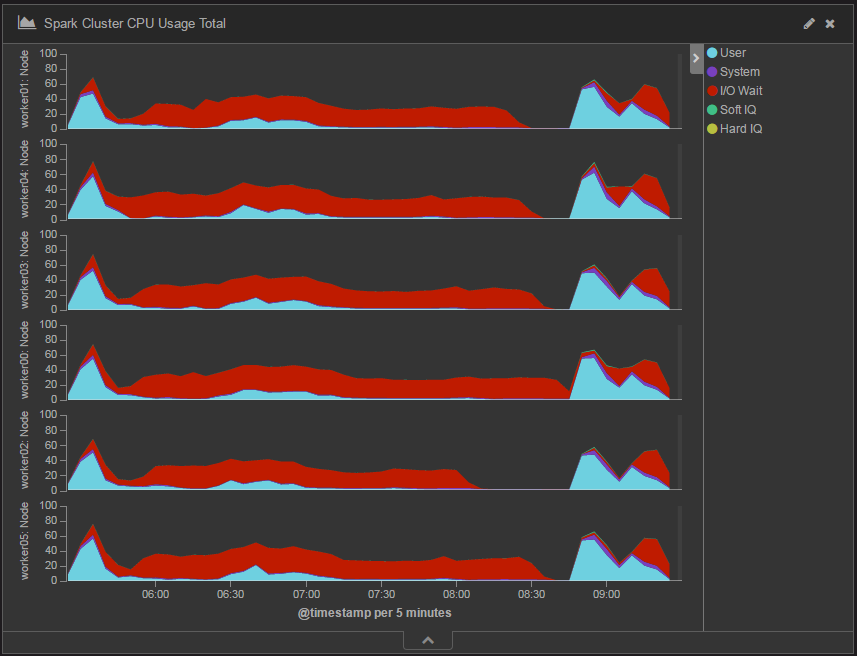
図4:Spark 2.0における365日分のデータを処理したときのCPU使用率の変化
以上をまとめると、365日分のデータを集計処理するとき、データ処理基盤では次のような事象が発生していたことが分かります。
- シャッフルファイル出力先に設定されているRootディスクへのアクセスが集中している
- CPUはディスクアクセス待ちに多く費やされている
推察される原因
Sparkのデータ処理の挙動とデータ処理基盤で発生した事象とを考慮すると、次のことが言えます。
- 365日分のデータを処理する場合は、1日分と30日分のデータを処理する場合に比べて非常に多くの中間データ(シャッフルファイル)が出力された
- シャッフルファイルが多く出力されたことでページキャッシュ(メモリ)の空き容量がなくなり、シャッフルファイルはディスクへ即時に書き込まれた
- Reduce処理開始時に多量のシャッフルファイルをディスクから読み込んだために、処理時間の多くをディスクアクセスに費やした
このことから、シャッフルファイルの読み書きによるディスクアクセスが性能上のボトルネックになっていると考えられます。
シャッフル処理に関する性能向上策
チューニングの概要
シャッフル処理の性能向上策の一例として、表1に示すものが考えられます。
表1:シャッフル処理性能向上のための対策一覧
| # | 対策方針 | 実現方法 |
|---|---|---|
| 1 | シャッフルファイル出力の性能(スループット)を向上させる | シャッフルファイル出力専用のディスクを新たに追加する |
| 2 | HDFSが既に利用しているディスクをシャッフルファイル出力先ディスクとしても共用する | |
| 3 | シャッフルファイル出力先にSSD等の高性能な媒体を割り当てる | |
| 4 | メモリのページキャッシュ領域にシャッフルファイルをすべて収める | Workerノード数を増やしてクラスタ全体のメモリ容量を増やす(スケールアウト) |
| 5 | Workerノードに搭載したメモリを物理的に増強する |
本検証では、既にHDFSが使用しているディスクをシャッフルファイル出力先としても共用する対策をとりました(表1#2)。この設定はYARNのパラメータ設定ファイルyarn-site.xmlに記述します。
表2:シャッフルファイル出力先追加のためのYARNパラメータ設定値一覧
| # | 設定項目 | 設定値 | パラメータ名 |
|---|---|---|---|
| 1 | シャッフルファイル出力先 | file:///hadoop/yarn/node-manager/local, file:///data/1, file:///data/2, file:///data/3, file:///data/4, file:///data/5, file:///data/6, file:///data/7, file:///data/8 | yarn.nodemanager.local-dirs |
シャッフルファイル出力先に指定する値は、Workerノードのファイルパスです。一般にOSインストール先と同じローカルディスク(Rootディスク)上のパスを指定するので、本検証では表2の設定値(file:///hadoop/yarn/node-manager/local)を設定していました。
これに加えて、新たにシャッフルファイルの出力先としてWorkerノード1台あたりディスク8台を追加します(表2のfile:///data/1~file:///data/8)。新たに追加したディスク8台は既にHDFSでも使用しているディスクなので、HDFSとシャッフルファイル出力の用途で共用します。ちなみに、Workerノード1台あたりのRootディスクは2台ですが、RAID0を構築しているのでOSからRootディスクは1台に見えています。
シャッフルファイル出力先ディスク追加後の検証結果
HDFSが既に利用しているディスクを共用するチューニング(表1#2)を施して、シャッフルファイル出力先ディスクを追加した状態で再度処理時間を計測しました。Spark 2.0での結果を図5に示します。365日分データの集計処理において、ディスク追加後は追加前に比べて約3.6倍の性能向上が見られます。
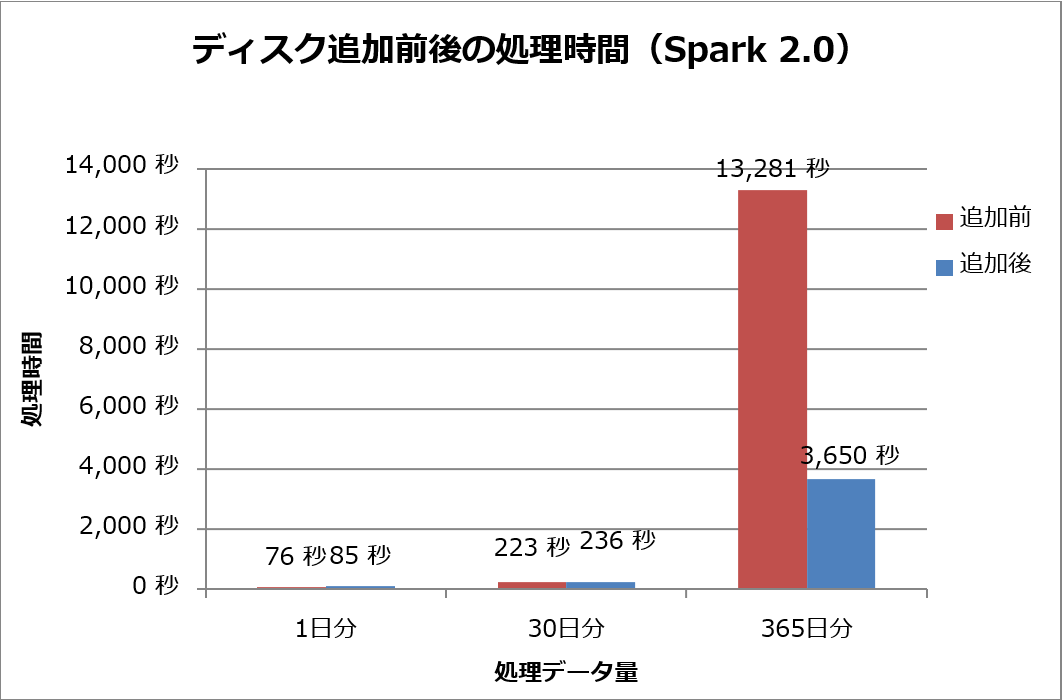
図5:シャッフルファイル出力先ディスク追加前後の処理時間(Spark 2.0)
Spark 1.6での結果を図6に示します。365日分のデータ処理のとき、シャッフルファイル出力先ディスク追加前は処理が完了せず失敗していましたが、追加後は処理が完了しています。
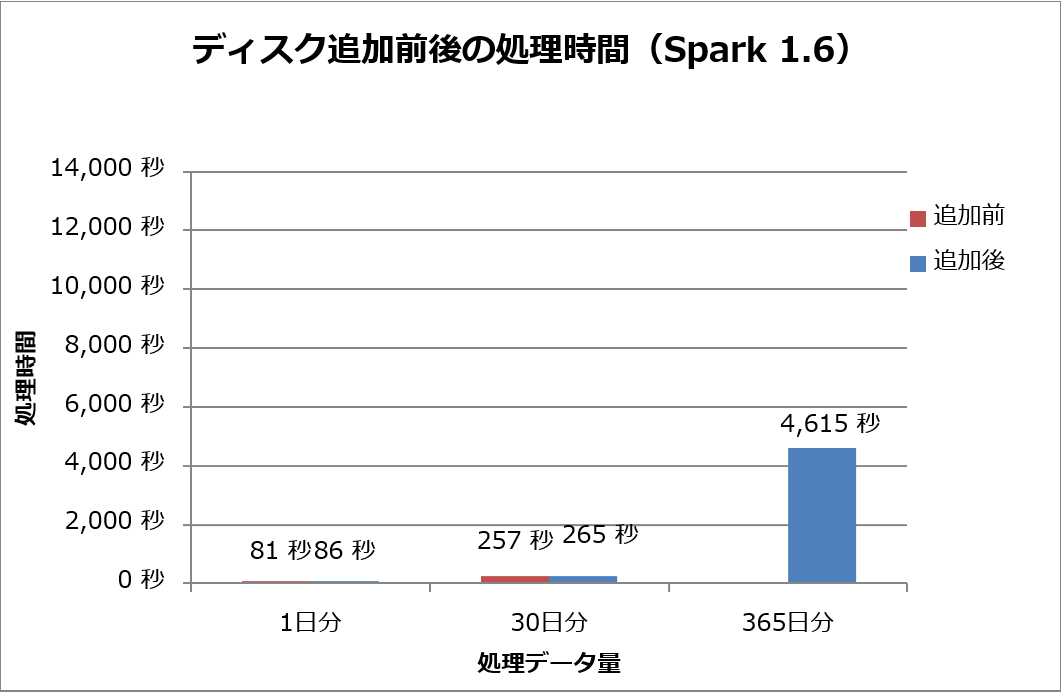
図6:シャッフルファイル出力先のディスク追加前後の処理時間(Spark 1.6)
一方、Spark 2.0、Spark 1.6共に1日分および30日分のデータ量のとき、ディスク追加後では5~10%程度処理時間が増加しました。その処理時間の比較を図7に示します。処理データ量が1日分、30日分の処理結果は前回の「パラメータ設定」で紹介した設定での結果です。365日分の処理結果は今回の「チューニングの概要」で解説したシャッフルファイル出力先ディスクをHDFSと共用して追加した設定での結果です。
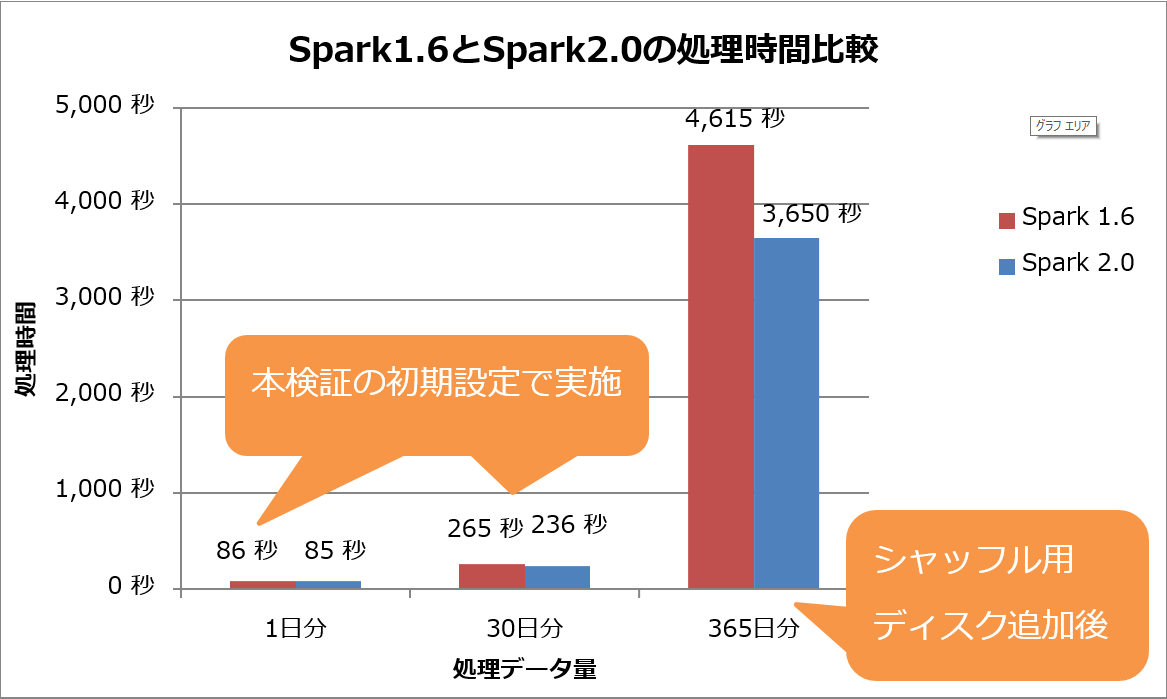
図7:Spark 1.6とSpark 2.0での処理時間比較の結果
この結果では、Spark 2.0はSpark 1.6よりも処理データ量が1日分の場合は約1%、30日分の場合は約11%、365日分の場合は約20%高速であることを確認しました。
チューニング効果の確認
Spark 2.0におけるシャッフル用ディスク追加後のデータ処理時のディスクI/O量の変化を時系列で表したチャートを図8に示します。全ディスクでほぼ均等に読み込み/書き込みが行われていることが分かります。また、各WorkerノードのディスクI/O量もシャッフル用ディスク追加前は200MB/秒程度(図3)だったのに対し、追加後は1,000MB/秒程度で推移しスループットが向上しています。
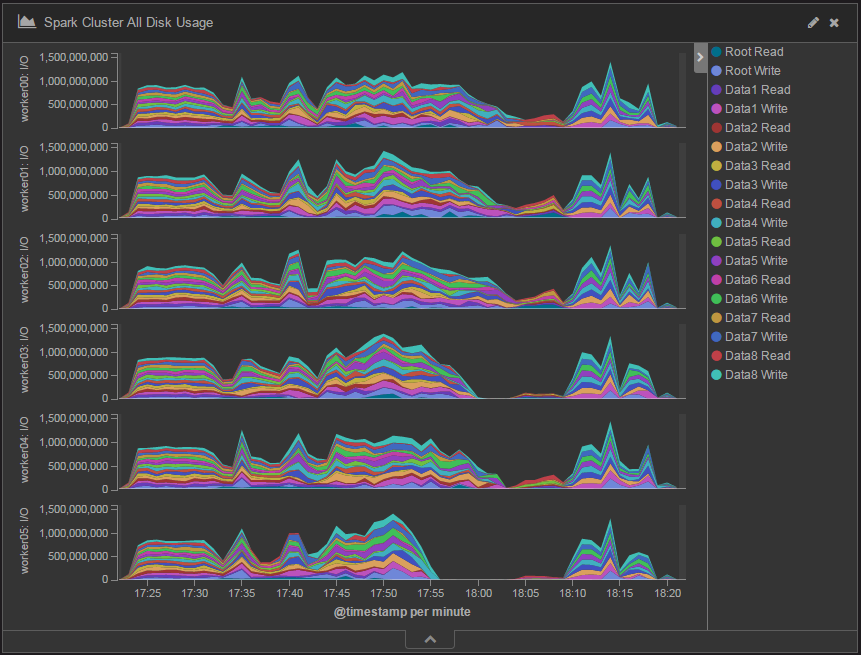
図8:Spark 2.0における365日分のデータを処理したときのディスクI/O量の変化(ディスク追加後)
データ処理時のCPU使用率の推移を図9に示します。シャッフル用ディスク追加前(図4)と比べてI/O WaitつまりディスクI/O待ちが占める割合は低下している一方で、UserつまりSparkの処理が占める割合が大幅に増加しています。
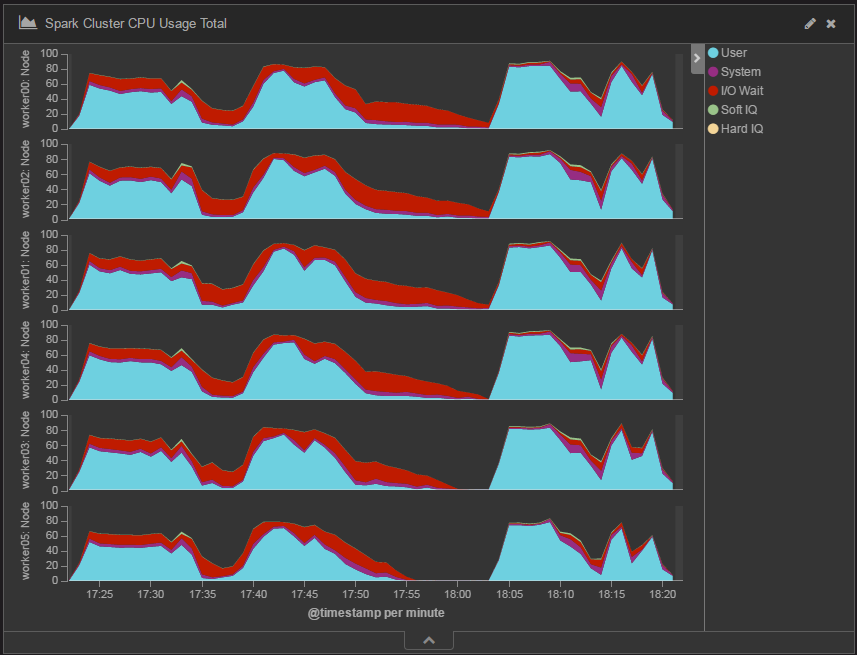
図9:Spark 2.0における365日分のデータを処理したときのCPU使用率の変化語(ディスク追加後)
Spark 2.0、Spark 1.6は共に1日分および30日分のデータ処理時間が5%から10%程度増加するという結果を得ています。これは次のような理由によると考えられます。
1日分および30日分のデータ処理では、メモリの空き容量に余裕がありシャッフルファイルがページキャッシュ領域に収まるため、書き込み先ディスクが増えることによる性能改善効果は少ないと考えられます。一方、今回の対策ではシャッフルファイルの出力先ディスクとHDFS用ディスクを共有したため、ページキャッシュ上のシャッフルファイルが非同期にHDFS用ディスクに書き込まれることでHDFS用ディスクのI/Oのオーバヘッドが増えたことが性能低下の一因と考えられます。
以上のことから、365日分のデータの処理のようにシャッフルファイルがページキャッシュ領域に収まらない場合は、HDFSに割り当てたディスクをシャッフル用にも割り当て共用することで処理性能を向上できるといえます。しかし1日分および30日分のデータ処理のように、シャッフルファイルがページキャッシュ領域に収まる場合は、逆に処理性能を低下させてしまいます。
性能検証の振り返り
バッチ処理におけるSpark 2.0の実際の性能
本検証でSpark 2.0はSpark 1.6比で約20%の性能向上が確認できました。しかしSpark 2.0のリリースノートでは「2倍から10倍の処理性能向上」と記載されています。このギャップは本検証に前回の「処理内容」で解説した多段の処理を含んでいることに起因しています。Sparkではデータの結合(JOIN)処理が発生するとその度にシャッフル処理を実行し、シャッフルファイルの出力とディスクアクセスが頻発します。その結果、HDFSからの処理データ読み出しと合わせたディスクアクセスが処理時間の大半を占めるため、性能向上の度合いは高くないことが分かりました。
現在、企業が管理するデータの多くがRDBに格納されており、既存のバッチ処理の多くが多段の集約処理を含んでいるものと思われます。このようなバッチ処理を単純にSparkで実行した場合、本検証のように大幅な業務の処理性能向上は期待できないと思われます。一方、機械学習のようにデータ結合が不要でメモリ上で繰り返し処理される場合には、さらなる処理性能向上が期待できます。
Sparkの性能向上のためにすべきこと
シャッフルファイルも含むすべてのデータがメモリ(ページキャッシュ領域)に収まるとき、最も処理性能を発揮できると言えます。そのためには十分なメモリ容量をクラスタに搭載することが求められます。
シャッフルファイルがメモリに収まらないとき、シャッフルファイル出力先ディスクをHDFS用ディスクと共用して増設するというチューニングにより約3.6倍の性能改善を確認しました。ただしこのチューニングはHDFSのディスクアクセス性能を低下させるため、すべてのデータがメモリに収まる場合と比べて処理性能は低くなります。クラスタのメモリ容量が十分でない場合には、チューニングだけでなくSparkを使うかどうかを含めて慎重に判断する必要があります。
おわりに
今回は、前回の検証で発覚した問題の原因を特定し対策を施しました。Sparkがシャッフルファイルを出力する処理が原因箇所であり、対策としてSparkのシャッフルファイル出力先ディスクを追加したところ、ジョブは失敗することなく処理完了し、最大で約3.6倍の性能向上が見られました。また、この結果からSpark 2.0はSpark 1.6に比べて約20%高い性能を発揮していることが分かりました。
次回は、今回紹介した以外のSparkに関わるさまざまなパラメータチューニングを施し、本検証における最適なクラスタ構成・設定を示します。
- この記事のキーワード
この記事をシェアしてください
関連記事
バックナンバー
この記事の筆者
筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
