なぜPinterestはGBDTからニューラルネットに移行したのか?
写真共有サービスのPinterestのエンジニアが、自社の「お勧め」写真選択の仕組みをニューラルネットに切り替えた際のチャレンジについて語る。
2017年12月25日 11:45
オライリー開催のAI Conferenceシリーズの第2弾として、インターネットの画像をシェアするサービスであるPinterestの事例セッション、「Escaping the forest, falling into the net:The winding path of Pinterest’s migration from GBDT to neural nets」を紹介する。
登壇したのは元Google ResearchのエンジニアであるDerek Cheng氏と、元AmazonのソフトウェアエンジニアXiaofung Chen氏だ。それぞれAIの利用に関しては先進的な企業からPinterestに移ってきたエンジニアである。特にCheng氏は、Google ResearchでサーチのパーソナライゼーションとGoogle Playなどでのレコメンデーションを開発していたという経歴の持ち主だ。
タイトルを訳せば、「森から抜け出してネットに捕まった。GBDTからニューラルネットにマイグレーションしたPinterestの曲がりくねった道」とでもいったところか。つまりPineterestのサービスがGBDT(Gradient Boosting Decision Tree)という手法から、TensorFlowを使ったニューラルネットに切り替えた、というトピックについて解説するというものだ。

登壇するDerek Cheng氏。後ろに見えるのが後半のプレゼンを担当したChen氏
まずCheng氏がPinterestの概要を解説し、ユーザーが主に滞在する「ホームフィード」と呼ばれるページについて、その特徴を言及した。PCユーザーであればすぐに理解できることだが、Pinterestはインターネットにあふれる様々な画像や写真などを、ユーザー自身の興味に従って「ピンを押す」ことで収集するサービスだ。

Pinの説明
具体的に言えば、猫が好きな人であれば、「Cat」という単語で検索して表示された画像に次々にPinを押すことで、自分なりのコレクションを作ることができる。またブラウザーのExtensionをインストールすれば、他のサイトを閲覧している時に好きなイメージデータをPinすることができる。つまり好きな画像のスクラップブックを作って、それをサイト上で共有するサービスだ。
ここでCheng氏は、ホームフィードはアクティブなユーザーの大多数、70%が使うページであり、その品質はユーザーのエンゲージメントと広告の収入にも大いに影響することを紹介した。

ホームフィードの概要
ホームフィードは、Pinterestの中で最初に機械学習が使われたページである。そしてユーザーがPinterestのサイトを訪れた時に、「自分のデータと過去に押したPinの属性に従ってどのような画像が表示されているのか?」によって、ユーザーの滞在時間やPinを押す回数、検索などの利用が変化するという。そのためPinterestは、ホームフィードの品質を上げることを最大の課題として取り組んできたということを紹介した。なお、ユーザーとPinの組み合わせから発生する予測、つまり「どのユーザーにどの画像を見せるか?」は一日に200B+、つまり2000億回以上発生する計算処理になるという。この数字だけを見ても、Pinterestにとって「ホームフィードで何を見せるのか?」が非常に重要な問題であることは理解できる。
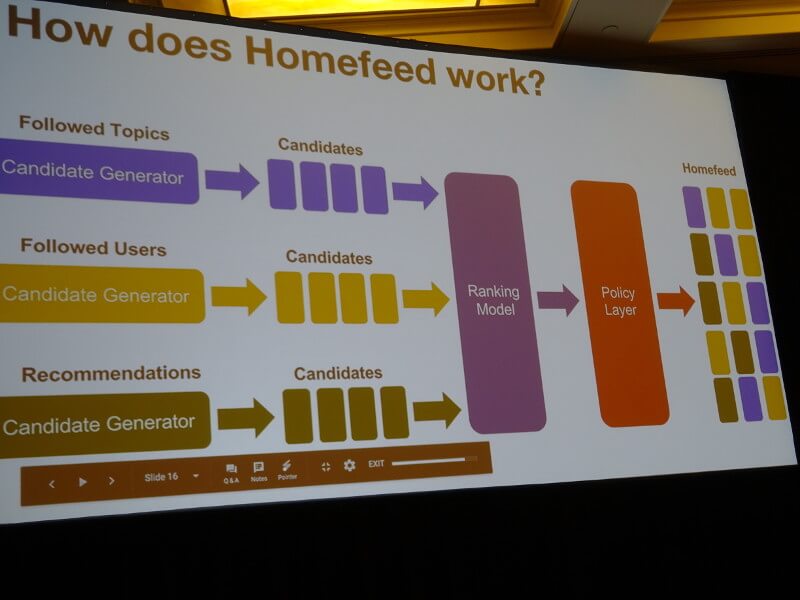
ホームフィードの作られ方
ホームフィードはFollowed Topics(そのユーザーがフォローしているトピック)と、Followed Users(そのユーザーがフォローしているユーザー)、さらにRecommendations、つまりシステムからのレコメンドの組み合わせから成り立っている。それをRanking ModelとPolicy Layerという2つのプロセスが処理することで、ユーザーごとに表示される複数の画像や広告が決定されるのだ。

ホームフィードのチャレンジ
そして、そのホームフィードをより良くするためのチャレンジとして挙げられたのが、「Cold-Start」「Exploitation vs Exploration」「Localization」「Balancing among multiple objectives」であるという。最初のCold-Startは文字通り「属性を持たない、もしくは少ないユーザーに何を見せるのか?」と言う問題、Exploitation vs Explorationは「利益と冒険の相反する要素をどう組み合わせるか?」と言う問題、Localizationは国や言語に沿った調整の問題、そして最後のBalancing among multiple objectivesは「複数の目的をどう調整するか?」と言う問題だという。
それらの問題を解くためにPinterestが最初に選んだ手法が、GBDT(Gradient Boosted Decision Tree)だった。GBDTは日本語では「勾配ブースティング決定木」と呼ばれるもので、弱い学習器に決定木を用いたものを複数使う手法であり、Pinterestの場合は、700以上の要素、7層の決定木、350本の決定木の数、1決定木に対して255のノード、9万ノードなどといった数値が紹介された。

PinterestのGBDT例
GBDTの利点/欠点については、このスライドに集約されている。利点は「ノイズや例外に強く、自動的に各要素の特性を親子関係に従って学習することができる」と言ったところだろう。一方欠点として、「決定木の深さによってモデルが複雑になる」「関連が薄い要素を上手く使えない」「ユーザーの国や言語と言ったカテゴリーを一般化出来ない」「限られた要素と関連でのみ学習が効く」といったものが挙げられた。

Pinterestが考えるGBDTのPro/Con
ここからはChen氏にバトンタッチされ、GBDTから他の手法を選択せざるを得なくなった状況に関して、解説を行った。

GBDTからNNに乗り換えた背景
ここでは2つの要因が紹介された。まず、要素が増えるに従ってモデルを学習させる時間が増大してしまったこと、そして、要素間の関係を学習させるモデルのキャパシティが足らなくなったことの2つだ。そこでTensorFlowベースのニューラルネットを使うことにより、スケーラビリティとモデルのキャパシティ、さらに今後の拡張性を実現できたという。
また開発に取り掛かってからの経緯を紹介したが、インフラストラクチャーを作ったのが2016年9月、そこから毎月のようにリリースが行われていることが読み取れる。スライドでは「Long Journey」と題されているが、2017年5月には利用を始めているということは、開発開始から1年はかかっていないということだ。

Pinterestのニューラルネット開発プロジェクト
具体的にどのくらい数値が改善されたのか? について、定量的な情報は開示されなかったが、サービスのコアの部分に手を入れてビジネスにインパクトのある開発を行っていることは十分に見て取れたプレゼンテーションであった。
他のセッションでも見受けられたが、中国系のエンジニアが機械学習において大きな役割を果たしているということを感じたセッションでもあった。自社サービスにおいてレコメンデーションなどの機能を考えているエンジニアにとっては、刺激的な内容だったのではないだろうか。
- この記事のキーワード
この記事をシェアしてください
関連記事
バックナンバー
この記事の筆者

筆者の人気記事
SASEのCato Networks、CEOによるセミナーとインタビューを紹介
2020年4月16日 6:00
Rustのエコシステムの拡がりを感じるデスクトップアプリのためのツールキットTauriを紹介
2022年12月16日 6:00
Zabbix式オープンソースの秘密に迫る
2025年1月31日 6:00
WebAssemblyとRustが作るサーバーレスの未来
2020年4月21日 6:00
三菱電機が設立したOSPOのメンバーにインタビュー。「インナーソース」を戦略的に使う背景とは?
2025年10月3日 6:00
エンタープライズLinuxを目指すSUSE、Red Hatとの違いを強調
2015年2月3日 19:00
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
