Akka Streamsで実装するリアクティブストリーム(その2)
前回に引き続き、Akka Streamsを使って実装するリアクティブストリームについて解説する。
2018年3月13日 6:00
前回に引き続き、連続して発生し続けるデータを処理する「ストリーム処理」をAkkaで実現する方法を紹介します。
- リアクティブストリームとは
- Akka Streamsとは
- Akka Streamsの基本要素
- バックプレッシャー
- もうひとつの出力値
- エラー処理(前回はここまで)
- グラフとアクター
- 複雑なグラフ
- バッファー
グラフとアクター
Akka Streamsでストリーム処理を実装すると、グラフ実行時にActorMaterializerがグラフをアクターへと変換しますので、メッセージを送るなどのアクターに対する直接的な操作は必要ありません。では、アクターがどのような単位で生成され、データが流れていくのかを見ていきましょう。
オペレーター融合
Akka Streamsでは処理ステージごとにアクターを生成しメッセージのやり取りを行うのではなく、グラフ内の複数の処理ステージを1つのアクター上で実行します。これにより、要素をスレッド間で受け渡しするオーバーヘッドを削減します。1つのアクター上に融合した処理ステージはお互いが並列に実行されることなく、1つのCPUコアで逐次的に実行されます。このように1つのアクター上で同期的に処理し、不必要な非同期境界を取り除くことを「オペレーター融合」と呼びます。
別々のアクターで処理したい場合は、asyncメソッドを使って非同期境界を設けます。ソースやシンク、フローをasyncメソッドで区切ると、その前後は異なるアクターで処理されるようになります。

非同期境界で区切られたグラフ
上図のようにソース、シンクに加え、2つのフローを作成し、フロー間に非同期境界を設けます。
リスト1:asyncメソッドによる非同期境界の設定
// ソースを生成
val source = Source(1 to 5)
// シンクを生成
val sink = Sink.foreach[Int](e => println(s"$e ~> sink"))
// フローを生成
val flow1 = Flow[Int].map { e =>
println(s"$e ~> flow1")
e
}
val flow2 = Flow[Int].map { e =>
println(s"$e ~> flow2")
e
}
// RunnableGraphを生成
val runnableGraph = source.via(flow1).async.via(flow2).toMat(sink)(Keep.right)
上記のリストのように、RunnableGraph生成時にflow1とflow2の間でasyncを呼び出しました。これにより、flow1とflow2は別々のアクターで実行されることになります。非同期境界を設けなかった場合と設けた場合で実行結果を比較してみましょう。
リスト2:非同期境界を設けなかった場合の実行結果
[info] 1 ~> flow1
[info] 1 ~> flow2
[info] 1 ~> sink
[info] 2 ~> flow1
[info] 2 ~> flow2
[info] 2 ~> sink
[info] 3 ~> flow1
[info] 3 ~> flow2
[info] 3 ~> sink
<以下同様に続く>
リスト3:非同期境界を設けた場合の実行結果
[info] 1 ~> flow1
[info] 2 ~> flow1
[info] 3 ~> flow1
[info] 1 ~> flow2
[info] 4 ~> flow1
[info] 1 ~> sink
[info] 5 ~> flow1
[info] 2 ~> flow2
[info] 2 ~> sink
[info] 3 ~> flow2
[info] 3 ~> sink
[info] 4 ~> flow2
[info] 4 ~> sink
[info] 5 ~> flow2
[info] 5 ~> sink
非同期境界を設けなかった場合は、1つのデータ要素がソースからシンクに流れ着くまで処理されたあと、2つ目のデータ要素を処理しています。これに対して非同期境界を設けた場合は、1つのデータ要素の処理が終わるのを待たずしてflow2の処理がflow1の処理と非同期に実行されていることがわかります。
オペレーター融合は、マテリアライズ時に行われます。これを無効化したい場合は、akka.stream.materializer.autofusing=offオプションを指定します。この場合は、手動で処理ステージを融合することもできます。
複雑なグラフ
ここまでは一直線に流れるグラフを見てきましたが、ストリーム処理で扱うグラフにはもう少し複雑なものもあるでしょう。Akka Streamsでは複数の入力を持つ処理ステージや、複数の出力を持つ処理ステージも提供されています。複数の入力をファンイン、出力をファンアウトといいます。
ファンアウトとファンイン
Akka Streamsが提供するファンアウトとファンインをいくつか紹介します。
ファンアウト
ファンアウトの例
| 処理ステージ | ふるまい |
|---|---|
| Broadcast | 入力要素を複数の出力先すべてに出力 |
| Balance | 入力要素を複数ある出力先のいずれかの出力先に出力 |
| UnZip | 入力要素をタプルで受け取り2つに分割して出力 |
| UnzipWith | 入力要素に対して複数(最大20)の戻り値をもつ関数を適用した結果を出力 |
ファンイン
ファンインの例
| 処理ステージ | ふるまい |
|---|---|
| Merge | 複数の入力をマージ。すべての入力をランダムに取り出し1つの出力先に出力 |
| MergePreferred | 複数の入力をマージ。1つの入力を優先して選択し出力 |
| MergePrioritized | 複数の入力をマージ。優先順位に応じて選択し出力 |
| Zip | 2つの入力をタプルに束ねて出力 |
| ZipWith | 複数の入力に対して1つ戻り値をもつ関数を適用し出力 |
| Concat | 最初の入力ポートからの要素をすべて出力後、次の入力ポートの要素を出力 |
これらを利用することで、入出力が複数あるような複雑なグラフも定義できます。Akka Streamsが提供するその他のファンアウト/ファンインは、Akka公式サイトで確認できます。
グラフDSL
グラフは、グラフDSLを使用して記述することもできます。グラフDSLはGraphDSL.Builderを使用し、viaメソッドの代わりにデータが流れることを示す矢印のような~>を使って複数のグラフコンポーネントをつなげることでグラフを作成します。
たとえば、複数の出力先を持つファンアウトとして「Balance」で処理を3つに分岐し、ファンインとして「Merge」で1つに合流するグラフを考えてみます。
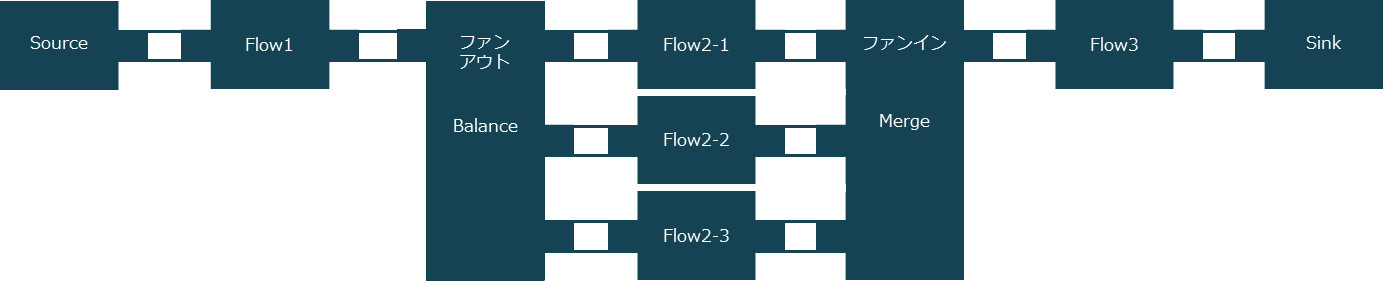
ファンアウト/ファンインを用いたグラフ
グラフDSLを使うと、ソースコードも図と同じように表現できます。どこで分岐し、どこでマージしているかなど、グラフの全体像が一目でわかります。
リスト4:グラフDSLで記述したグラフ
source ~> flow1 ~> balance ~> flow2_1 ~> merge ~> flow3 ~> sink
balance ~> flow2_2 ~> merge
balance ~> flow2_3 ~> merge
各グラフコンポーネントの定義を含めたソースコードは、次のようになります。
リスト5:RunnableGraphの生成
// RunnableGraphの生成
val runnableGraph: RunnableGraph[NotUsed] =
RunnableGraph.fromGraph(GraphDSL.create() {
implicit builder: GraphDSL.Builder[NotUsed] =>
import GraphDSL.Implicits._
// ソース/シンク
val source = Source(1 to 5)
val sink = Sink.foreach(println)
// ファンアウト/ファンイン
val balance = builder.add(Balance[String](3))
val merge = builder.add(Merge[String](3))
// フロー
val flow1 = Flow[Int].map(e => s"$e ~> flow1")
val flow2_1 = Flow[String].map(e => s"$e ~> flow2-1")
val flow2_2 = Flow[String].map(e => s"$e ~> flow2-2")
val flow2_3 = Flow[String].map(e => s"$e ~> flow2-3")
val flow3 = Flow[String].map(e => s"$e ~> flow3")
// グラフ
source ~> flow1 ~> balance ~> flow2_1 ~> merge ~> flow3 ~> sink
balance ~> flow2_2 ~> merge
balance ~> flow2_3 ~> merge
ClosedShape
})
// グラフの実行
runnableGraph.run()
これはデータが流れてきた経路を、シンクでコンソール出力するグラフです。
リスト6:実行結果
[info] 1 ~> flow1 ~> flow2-1 ~> flow3
[info] 2 ~> flow1 ~> flow2-2 ~> flow3
[info] 3 ~> flow1 ~> flow2-3 ~> flow3
[info] 4 ~> flow1 ~> flow2-1 ~> flow3
[info] 5 ~> flow1 ~> flow2-2 ~> flow3
GraphDSL.create()で生成したグラフを、RunnableGraph.fromGraphでRunnableGraphへ変換します。グラフはこれまでどおり、ソース、シンクとグラフを定義します。リスト5のように、flow2の部分はflow2-1、flow2-2、flow2-3の3つのフローに分散させ、その後1つに束ねる必要がありますので、GraphDSL.Builderを使ってグラフにBalanceノードとMergeノードをそれぞれ追加します。そして、これらを~>で繋げるとグラフが完成します。最後にグラフが閉じられていることを示すClosedShapeを返します。これはソースで始まりシンクで終わるという形で、グラフが完結していることを示しています。シンクが接続されておらずソースとなる場合はSourceShape、ソースが接続されておらずシンクとなる場合はSinkShapeを返し、どちらも接続されていない場合はフローとなるのでFlowShapeを返します。
バッファー
ファンアウトやファンインを使うことで、グラフコンポーネントの入力や出力を複数定義し、複雑なグラフを構築できることがわかりました。では、その中に処理速度の異なるグラフが混在するとどうなるでしょうか?
たとえば、ソースが1秒間に5件のメッセージを発行し、処理速度の異なる2つの出力先(下図のSlow FlowとFast Flow)にファンアウトするグラフがあるとします。出力先のSlow Flowは1秒間に1件、Fast Flowは1秒間に5件の仕事をこなします。グラフコンポーネントが並行に処理できるように非同期境界を設けます。
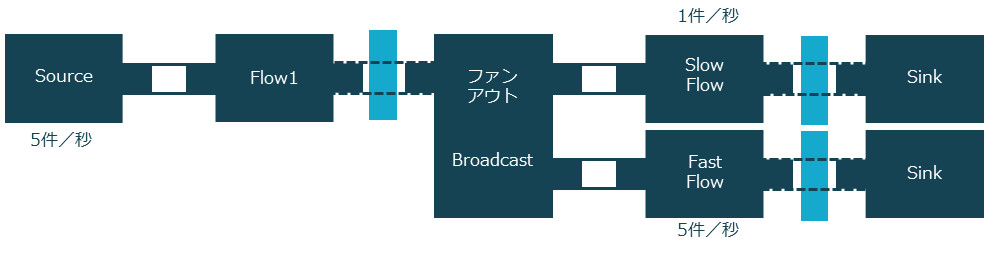
処理速度の異なるフロー
ここで注目すべきは、ソースがデータを発行するスピードより、Slow Flowの処理スピードのほうが遅いということです。こういったケースでは、バックプレッシャーにより速度が調整されるということは、すでに説明しました。Akka Streamsでは、自身が処理できるスピードでサブスクライバーがパブリッシャーから要素を引き出す、プルベースのバックプレッシャーが働きます。このバックプレッシャーは、中間のフローがオーバーフローすることなく上流まで伝播します。
つまり、このグラフはファンアウトにより、2つのシンクが存在しますが、上流から流れるデータのスピードが調整され、両方のフローが遅いフローのスピードで処理されることになります。このグラフのソースコードは、次のようになります。
リスト7:RunnableGraphの生成
val runnableGraph =
RunnableGraph.fromGraph(GraphDSL.create() {
implicit builder =>
import GraphDSL.Implicits._
// 1秒間に5件のデータを流すソース
val source = Source(1 to 15).throttle(elements = 5, per = 1.second, maximumBurst = 1, mode = ThrottleMode.shaping)
val sink: Sink[String, Future[Done]] = Sink.foreach[String](println)
// 2つの出力にブロードキャスト
val broadcast = builder.add(Broadcast[Int](2))
// 非同期境界
val flow = Flow[Int].async
// 遅いフロー:1秒間に1件のデータを処理
val slowFlow = Flow[Int].map{e =>
Thread.sleep(1000)
s" slow $e"
}.async
// 速いフロー:1秒間に5件のデータを処理
val fastFlow = Flow[Int].map{e =>
Thread.sleep(200)
s"fast $e"
}.async
// グラフ
source ~> flow ~> broadcast ~> slowFlow ~> sink
broadcast ~> fastFlow ~> sink
ClosedShape
})
runnableGraph.run()
ソースがデータを発行する速度を一定にするために throttleメソッドを使います。throttleメソッドは、データのスピードを時間あたりに流れるデータ件数により指定できます。ここでは、5件(第1引数)を1秒間(第2引数)に流すように指定しました。非同期境界を設けるとその前後が異なるアクターで処理されるので、メッセージの送受信が発生し受信したメッセージがメールボックスに格納されます。このメールボックスがバッファーとなり、バックプレッシャーの伝播を緩和し処理スピードが平準化されます。このサイズは、以下の方法で調整できます。デフォルトでは16ですが、ここでは、バックプレッシャーの様子をわかりやすくするため、バッファーサイズを1に設定します。
リスト8:バッファーサイズの指定
implicit val materializer = ActorMaterializer(
ActorMaterializerSettings(system)
.withInputBuffer(initialSize = 1, maxSize = 1))
実行結果は次のようになります。
リスト9:実行結果
[info] fast 1
[info] fast 2
[info] slow 1
[info] fast 3
[info] slow 2
[info] fast 4
[info] slow 3
<以下同様に続く>
非同期境界のバッファーサイズを1としたため、1件だけ要素がバッファリングされます。このため最初にFast Flowが続けて処理されていますが、それ以降は処理能力の異なる2つのフローが同じスピードで処理されているのがわかります(処理能力が異なるのにもかかわらず、交互にログが出力されています)。これは、バックプレッシャーにより、一番遅いフローであるSlow Flowにあわせて1秒間に1件のスピードで全体が流れているためです。
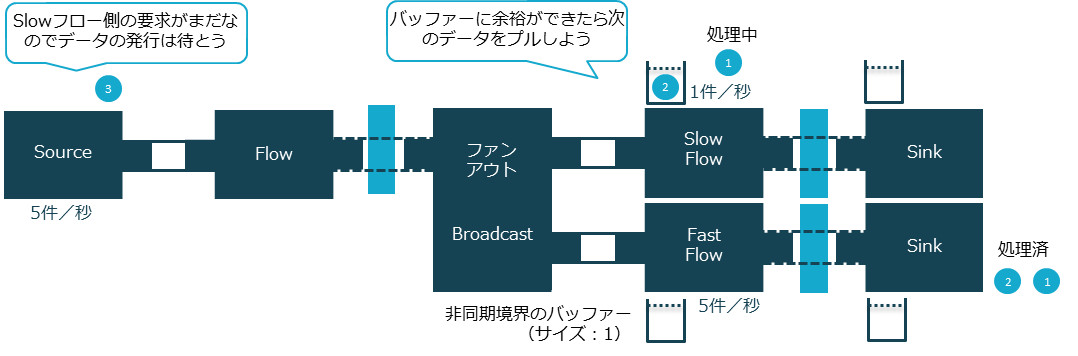
バックプレッシャーがかかっている様子
せっかくブロードキャストし2つのフローに分岐させたので、Fast Flowはどんどんデータを引き出し処理していきたいこともあるでしょう。こういった場合は、フロー間の任意の場所にバッファーを設けることができます。Slow Flow側にバッファーを設けると上流からどんどんデータを引き出し、さばききれない分はバッファリングしておくことで、Fast Flowへの遅延影響を緩和できます。この例のように、一時的に処理速度に差が出たとしてもバッファーを用いることによって Slow Flow の遅延がFast Flowへ影響するのを緩和できます。
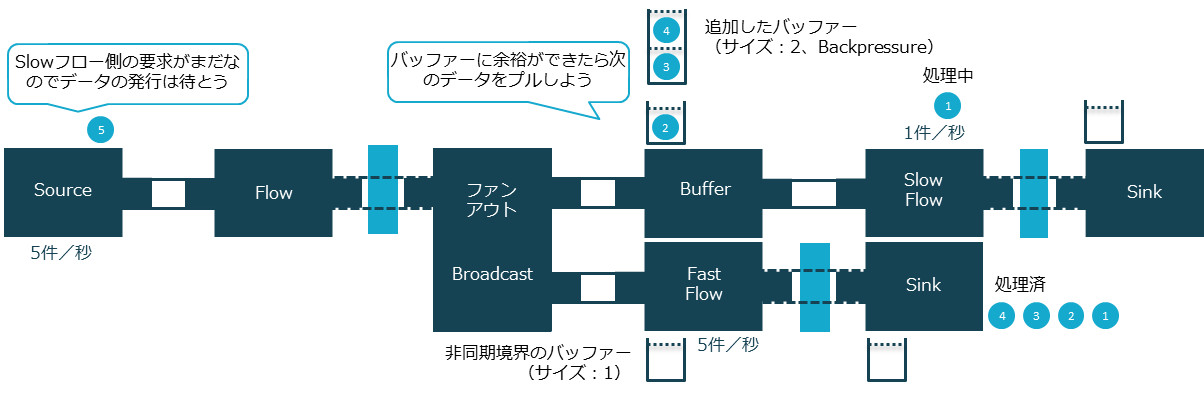
バッファーの追加
Slow Flowの直前に、サイズが2のバッファーを追加しました。
リスト10:グラフにbufferを追加
val buffer = Flow[Int].buffer(2, OverflowStrategy.backpressure)
source ~> flow ~> broadcast ~> buffer ~> slowFlow ~> sink
broadcast ~> fastFlow ~> sink
リスト11:実行結果
[info] fast 1
[info] fast 2
[info] fast 3
[info] fast 4
[info] slow 1
[info] fast 5
[info] slow 2
[info] fast 6
[info] slow 3
<以下同様に続く>
2件のバッファーを追加したので、先ほどの結果に比べて+2件、計4件分Fast Flowが最初に処理されるようになりました。おわかりのように、あとはこのバッファーサイズを調整するだけで、処理スピードの差分を吸収しFast Flowへの影響を緩和できます。しかしバッファー領域は有限ですので、オーバーフローに対する対策が必要になります。Akka Streamsはバッファーオーバーフローに対する戦略がいくつか定義されており、選択できます。上記の例ではOverflowStrategy.backpressureを指定することにより、バックプレッシャーを選択しました。このため、バッファーの上限を超えるとパブリッシャーからデータの引き出しを行わないため、遅延が発生しています(fast 5以降は交互にログが出力されていることから、Fast FlowとSlow Flowが同じスピードで流れていることがわかります)。以下の表のように、オーバーフロー戦略にはバックプレッシャー以外にも、処理内容に応じて要素を破棄したり、グラフ自体を失敗させる戦略を選択したりといったものがあります。
バッファーのオーバーフロー戦略
| 戦略 | 内容 |
|---|---|
| Backpressure | バックプレッシャーをかける (バッファーに余裕がある場合のみプルする) |
| DropNew | 新しい要素をバッファーに格納せず破棄 |
| DropTail | バッファー内の末端(最新)要素を破棄 |
| DropHead | バッファー内の先頭(最古)要素を破棄 |
| DropBuffer | バッファーを破棄 |
| Fail | グラフの実行を失敗させる |
Slow Flowですべてのデータを失うことなく処理することよりも、Fast Flowを遅延なく処理することの方が重要である場合、遅延なくデータを引き出し要素を破棄することで、オーバーフローを防ぐ戦略を取ることができます。たとえば、オーバーフロー戦略にDropNewを適用すると、バッファーがいっぱいでもデータを引き出し、引き出した新しいデータを破棄します。これにより、Slow Flowでデータを失うことと引き換えに、Fast Flowは遅延なく処理されます。
リスト12:オーバーフロー戦略をDropNewに設定
val buffer = Flow[Int].buffer(2, OverflowStrategy.dropNew)
bufferメソッドの第2引数にOverflowStrategy.dropNewを指定すると、実行結果は次のようになります。
リスト13:実行結果
[info] fast 1
[info] fast 2
[info] fast 3
[info] fast 4
[info] slow 1
[info] fast 5
[info] fast 6
[info] fast 7
[info] fast 8
[info] fast 9
[info] slow 2
[info] fast 10
[info] fast 11
[info] fast 12
[info] fast 13
[info] fast 14
[info] slow 3
[info] fast 15
[info] slow 4
[info] slow 6
[info] slow 11
このように、Fast Flowが遅延なく処理されました。しかしログをよく見ると、ソースからは1~15の数値を発行したにも関わらず、Slow Flowのデータが処理したのは「1、2、3、4、6、11」で、一部が欠落しているのがわかります。Slow Flowは1秒間に1つの要素しか処理できないのに5つの要素を引き出してしており、バッファーに入らないデータは破棄しているためです。
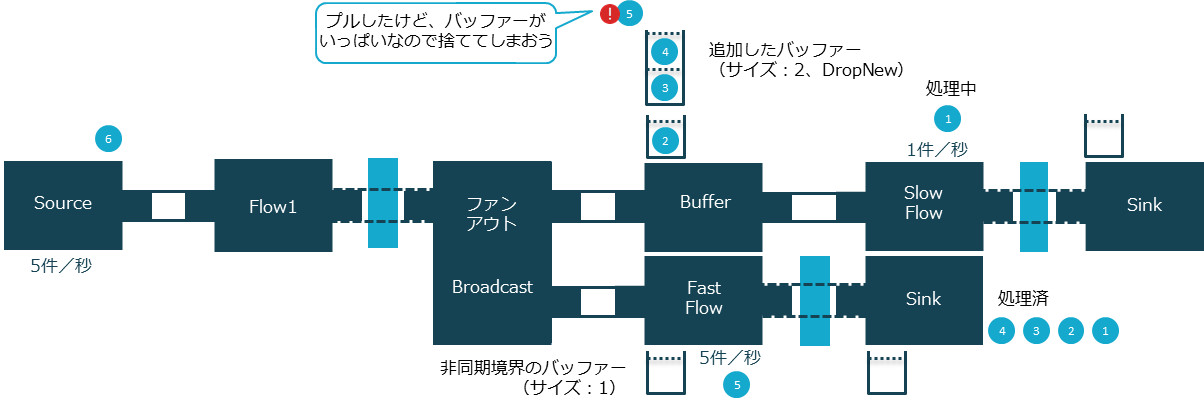
オーバーフロー戦略をDropNewにした場合
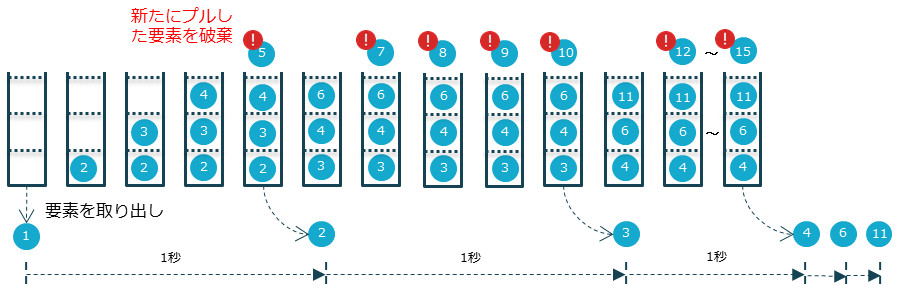
オーバーフローしそうになったときのバッファーのふるまい
バッファーがオーバーフローしそうになった際の戦略はDropNewを指定しましたので、バッファーがいっぱいの場合は新しい要素をバッファーに格納せず破棄します。DropNew以外にもDropTailやDropHeadなど処理に応じて選択できます。bufferメソッドに指定するオーバーフロー戦略を変更し、出力されるログを確認してください。戦略によって、破棄されるデータが異なることを確認できることでしょう。
その際、すべての非同期処理ステージに定義されているバッファー(ここでは1に設定)と、フローとして定義したbuffer(ここでは2に設定)は別領域であることに注意しましょう。DropBufferで破棄したり、DropHeadで最古の要素を破棄したりする対象は、フローとして定義したbufferのほうです。
このようにAkka Streamsは、非同期処理ステージに設けられているバッファー(デフォルト16)に加えて、フロー間にバッファーを設け、適切な戦略を選択することで、より洗練されたグラフを構築できます。
おわりに
今回はリアクティブストリームの実装であるAkka Streamsを使用して、Akkaで非同期ストリーム処理を実装する方法を紹介しました。リアクティブストリームのパブリッシュ・サブスクライブとその間のバックプレシャーを、Akka Streamsのソースとシンク、フローを用いて実装できることがおわかりいただけたでしょう。
Java 9の新機能として注目される「リアクティブストリーム」を利用する際の選択肢として、その実装であるAkka Streamsを検討してはいかがでしょうか。なお、本記事で紹介したサンプルコードはGitHub上で公開しています。
参考文献
- この記事のキーワード
この記事をシェアしてください
関連記事
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
