Akka Clusterで超レジリエンスを手に入れる(その2)
前回に引き続き、Akka Clusterを利用した耐障害性を備えたシステムの構築について解説する。
2017年8月1日 10:00
前回に引き続き、Akkaのクラスタリング機能を使って、障害が起こることを前提にした耐障害性の高いシステムを構築する方法を、解説します。
- Akkaで構築する分散システム
- クラスタリング
- クラスタメンバーのライフサイクル
- 障害の検知(前回はここまで)
- ルータ
- Cluster Shardingによるアクターの分散
- Akka Persistenceによる状態の永続化
ルータ
クラスタ内で作業を分散させるにはルータを使用します。ルータはクラスタ内のメンバーの状態を認識し、メッセージを振り分けます。メンバーがunreachableになったり離脱したりすると自動的にルータから登録解除され、新しいメンバーが参加したりunreachableから回復したりすると、その設定に応じてルータの振り分け先として追加されます。
ルータの振り分けは連載の4回目で紹介したように、actorSelectionを使って送信先アクターのパスを指定するGroupと、子アクターに送信するPoolの2種類が存在します。クラスタ内のノードには、その機能や役割によってロールを設定でき、GroupのアクターをactorSelectionで選択する場合に、特定のロールのみを対象にできます。
Cluster Sharding によるアクターの分散
クラウド上に小さくローンチしたあなたのサービスがユーザーの支持を得ることに成功し、その利用者はどんどん増えてきています。ビジネスとしては大変喜ばしいことですが、システムとしてはユーザー数の増加に合わせて処理能力を向上させていかなければなりません。無限にスケールアップできれば問題ありませんが、その限界はすぐに来ることでしょう。そして、サーバを増やし負荷分散をすることになるでしょう。
しかし、サーバに状態を持たせるステートフルな従来型アプリケーションは、スケールアウトによる負荷分散が困難です。一台だったサーバが二台になると、クライアントがアクセスするたびに異なるサーバに振り分けられてしまい、「前回アクセスしたときの状態を知ることができないこと」が発生し得るからです。
この問題の対策としては、すべてのサーバに同じ状態を持つか、毎回同じサーバに振り分けるという2通りの方法が考えられます。前者の場合、状態をサーバ間でレプリケートするためのコストは必要ですが、処理がどのサーバに振り分けられても安心です。どのサーバにも同じ状態を保持しているので、障害が発生した場合も状態を失うこともありません。
しかし、サービスの利用者が10倍、20倍…… とさらに増加し、サーバをどんどん増やしていくと、全ユーザーの状態をメモリ上に保持しなければならないため、メモリを逼迫することになります。これでは、スケーラビリティがあるとはいい難い状況です。データベース等に永続化することでこの問題を回避できますが、そうすると今度はデータベースアクセスが頻繁に発生し、負荷が集中することになるでしょう。性能劣化に不満を覚えたユーザーを手放してしまうことになるかもしれません。
では、後者の場合はどうでしょうか? 同じユーザーからのアクセスが必ず同じサーバに振り分けられれば、サーバは自身が担当するユーザーの状態を保持するだけで済みます。メモリ逼迫の心配もありませんし、データベースにアクセスせず状態を得ることができるので、高いレスポンスも期待できます。
これを実現するために、AkkaにはCluster Shardingという機能があります。Cluster Shardingにより、ユーザーの識別子とその状態を持つアクターは一ヶ所にのみ存在し、メッセージの送り主は送り先のアクターがどのサーバにいるのかという物理的な位置を気にする必要がありません。
メッセージの振り分け
では、クライアントから送られたメッセージはどのように振り分けられるのでしょうか? 一意に識別する識別子を持つアクターを「エンティティ」と呼びます。AkkaのCluster Shardingではエンティティをシャードというグループで管理し、シャードを複数のノードに分散させます。
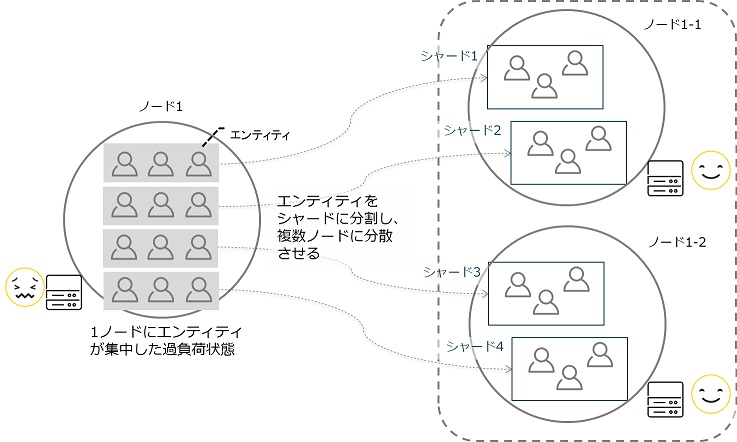
エンティティをシャードに分割し、複数ノードに分散
そのため、エンティティに送信されるメッセージは、どのシャードに振り分けられるべきかを知る必要があります。振り分けは、ノードごとに存在するShardRegionと呼ばれるアクターが担います。エンティティはシャードと呼ばれる塊でグルーピングして管理されており、(1)ShardRegionがメッセージを受け取ると、(2)シャードの調整役であるShardCoordinatorにシャードの位置を質問します。(3)ShardCoordinatorは、目的のシャードがどのShardRegion(ノード)に存在するかを回答します。こうして、(5)メッセージは目的のシャード、目的のエンティティに届けられます。
もし、目的のシャードが別のShardRegionに存在している場合は、(4)そのShardRegion(ノード)に転送され、同様に目的のシャード、目的のアクターに届けられることになります。ShardRegionはシャードの位置を知るためにShardCoordinatorに問い合せする必要がありますが、一度その位置を知ると、それ以降はShardCoordinatorに問い合わせることなく、即座に目的のシャードにメッセージを届けることができます。
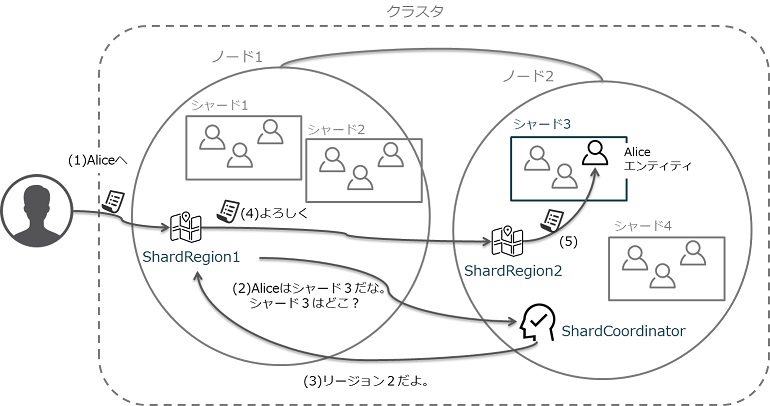
エンティティの位置を知るための仕組み
シャードの割り当てを決定するShardCoordinatorはクラスタ内で一つのみ存在すべきですので、クラスタシングルトンパターンを実装したAkkaのクラスタシングルトンを使用しています。クラスタシングルトンは、クラスタ内のノード間、または特定ロールのノード間で一つのシングルトンアクターインスタンスを管理してくれます。
シャードをどのShardRegionに配置するかは、シャードのアロケーション戦略に定義されています。その戦略に従い、ShardCoordinatorはシャードをリバランス、つまり別のノードへ移動させます。これにより、ノードごとのシャード数の偏りを最小限にし、サーバごとの負荷を平準化できます。これはシステムの負荷が増大し、ノードを追加したときに非常に有効です。一般にロードバランサで分散させると新たに加わったユーザーは新しいノードに振り分けられますが、すでに利用中のユーザーは同じノードに使い続けることになるので、なかなか負荷が軽減されません。これに対して、Akkaのクラスタシャーディングは、ノードが追加されるとシャードがリバランスされますので、負荷が平準化されシステム全体の安定を取り戻すことができます。
ShardCoordinatorの持つシャードの位置情報は非常に重要であり、障害が発生したときもその情報を失わず復旧できなければなりません。そのため、クラスタ内のノード間でデータを複製するAkka Distributed Dataを使用し、一部のノードで障害が発生してもそのデータを失うことのないよう複製しています。ShardCoordinatorが配置されたノードがダウンしたときには、Akka Distributed Dataにより複製されたデータから、シャードの位置情報とともに新しいShardCoordinatorのシングルトンアクターに回復できます。
注意点として、新しいシャードにメッセージを送るときはその位置を知るためにShardCoordinatorへの往復が必要となる点が挙げられます。当然、これは少なからずレイテンシになりますし、シャードのリバランスもレイテンシが発生することになります。従って、アクターをグルーピングするシャードの粒度は細かくしすぎないようにする、といった調整が必要です。
Akka Persistenceによる状態の永続化
すべてのサーバにすべてのユーザーの状態を保持していれば、一台のサーバがダウンしても他のサーバが同じ状態を持っているので、その状態を失うことはありません。しかしCluster Shardingの場合、エンティティは一ヶ所にしか存在しません。単一障害点を最小化するというモチベーションでAkka Clusterを紹介しましたが、状態をもつエンティティが一ヶ所にしか存在しないとなると、それは単一障害点となってしまうでしょうか? 安心してください。当該ノードに障害が発生した際、そのアクターはクラスタ内の別のノードで復元できます。そして、単にアクターを再起動するだけではその状態を失うことになりますが、Akka PersistenceというAkkaの永続化機構を利用して状態を永続化しておくことで、アクターの状態を失うこともありません。
Akka Persistenceによる永続化は、状態を更新していくのではなく、変更の内容を「イベント」という形で保存することで実現されています。つまりアップデートはなくインサートオンリーですので、処理効率がよくスケールしやすく、レプリケーションも効率的に行うことができます。アクターがクラッシュした後、その状態は保存したイベントをリプレイすることで別のノードに回復されます。一定間隔でスナップショットを取得しておくことで、回復時間を短縮することも可能です。
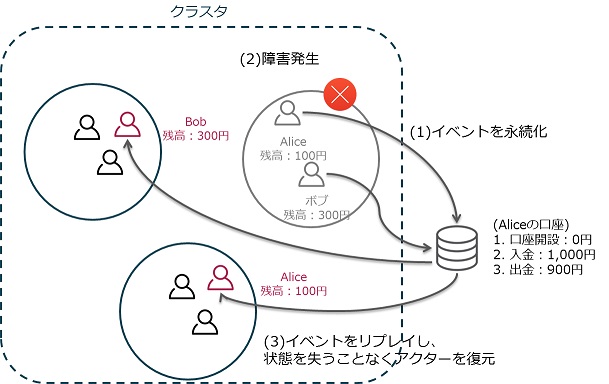
Akka Persistenceによるアクター回復の仕組み
これはイベントソーシングという仕組みで、永続化アクターは(1)コマンドを受け取ると(2)実行可否を判定するための検証を実施し、実行可能だった場合は、コマンドの結果を示すイベントを生成します。(3)イベントは永続化され、永続化に成功すると(4)アクターの状態を変更するという流れになります。アクターの回復は永続化した実行可能なイベントがリプレイされるので、失敗することはありません。

イベントソーシング
Akka Persistenceはこのイベントソーシングをサポートしており、PersistentActorトレイトをミックスインしたアクターを実装することで、容易に適用できます。永続化機能はデフォルトではファイルシステムに書き込むLevelDBジャーナルプラグインが用意されていますが、別のプラグインを利用することで他のデータソースにも対応できます。Akkaのモジュールとしては、オープンソースの分散データベース管理システムであるApache Cassandraのプラグイン(Cassandra Plugins for Akka Persistence)が提供されています。Cassandraは、クラスタノード間でデータをレプリケートするスケーラブルで可用性の高いデータベースです。Cassandraにアクターの状態を格納することで、データベースクラスタとAkka Clusterの両方のノードに障害が発生しても、状態を失うことはありません。その他にも、Akkaのコミュニティプロジェクトページでプラグインが公開されています。
イベントソーシングを適用することで、最新状態ではなく、ジャーナルを永続化しているため、過去の情報を得ることができ、その変更に対するユーザーの動きを分析するなど、ビジネス的な活用も見いだせるのではないでしょうか。しかし、イベントで情報が保管されていると参照しづらいという懸念事項もあります。この問題には、CQRS(Command and Query Responsibility Segregation:コマンドクエリ責務分離)というアーキテクチャが有効です。ここでは詳細な説明は控えますが、書き込み機能と読み込み機能をコマンドサイドとクエリサイドという形で分離させます。コマンドサイドはイベントソーシングで記録していき、非同期で、このイベントをクエリサイドに参照しやすい形式でデータを準備しておくことで、容易に参照できます。
なお、ShardCoordinatorの状態の保管に、Akka Persistenceを利用することもできます。
Akka Clusterのレジリエンス
Akka Clusterに加え、Cluster ShardingやAkka Persistenceを利用することで、クラスタの一部に障害が発生しても、上記の例のように元々3ノードで分散されていた処理を、残された正常な2ノードで機能を損なうことなく処理し続けられることがわかりました。しかし、残りのノードに障害が発生したらどうなるでしょうか。さらにアクセスが増えた場合時、残った2ノードでさばき切れるでしょうか。Akka Clusterは動的にノードを増やすことができるので、元の状態に戻しておきましょう。新たに1つのノードを追加することで、元の構成に戻すことができます。そして、AkkaのCluster Shardingはシャードのリバランスが可能なので、2つのノードに集中していた作業は、遅れて参加したノードを含めた3ノードに平準化され、負荷が集中して性能が劣化し続けることはありません。
ただし、ノード障害発生時は障害検知やアクターの回復作業により、障害が発生したノードに存在していたアクターには一時的にレイテンシが発生することがありますので、注意が必要です。特に、障害の検知においては、ネットワーク遅延や、GC(ガベージコレクション)による応答遅延などによる誤検知を防止するための考慮(クラスタから切り離すまでの猶予時間)が施されており、これがレイテンシの要因となります。これらは、システム構成(ノード数や配置など)や特性に応じて調整が可能です。
レジリエンスがもたらす危険
ノード障害に対して、新たなノードを立ち上げアクターを回復させるというレジリエントなシステムには危険も潜んでいます。
複数台のサーバを利用してクラスタを組むことが多いと思いますが、この場合、ネットワーク障害によりシステムが複数に分断される可能性があります。このとき、エンティティやシングルトンアクターが複数のノード群で同時に動き、データベースへの書き込み等を行うとデータの一貫性を失うことがあります。例えば、上述の口座からの出金処理でAliceエンティティが分断された2つのノード群に存在してしまい、一方のAliceの残高は900円で、もう一方は1,000円といった具合です。こういった状態を「スプリット・ブレイン」と呼びます。
クラスタメンバーの「障害の検知」でハートビートによる生存確認を用いて障害検知することを紹介しました。(1)クラスタがネットワーク障害により2つのノード群(ノード群A、Bとします)に分断される可能性があります。ノード群Aでは、ノード群Bのノード3へのハートビードは届かずunreachableとマーキングされ、ノード群Bでは、ノード群Aのノード1、2がunreachableとマーキングされます。(2)auto-down機能で一定時間経過後、unreachableなノードを自動的にダウンさせると、(3)このノードはクラスタから離脱したと認識し別のノードへ回復させます。(4)分断された2つのノード群で、それぞれがダウンしたノードの回復に成功すると、同じ識別子をもったエンティティが複数存在(Aliceが二人存在)したり、クラスタ内に唯一存在するはずのクラスタシングルトンアクターが複数存在したりすることで、システムとしての一貫性を失うことに繋がります。
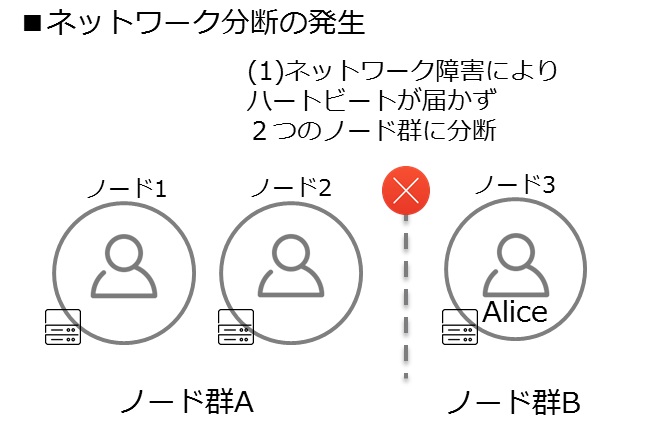
ネットワーク分断が発生(スプリット・ブレイン)
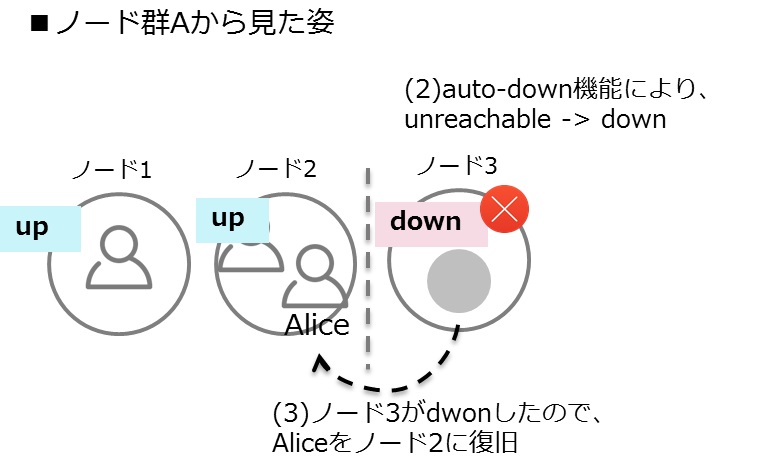
ノード群Aから見た姿
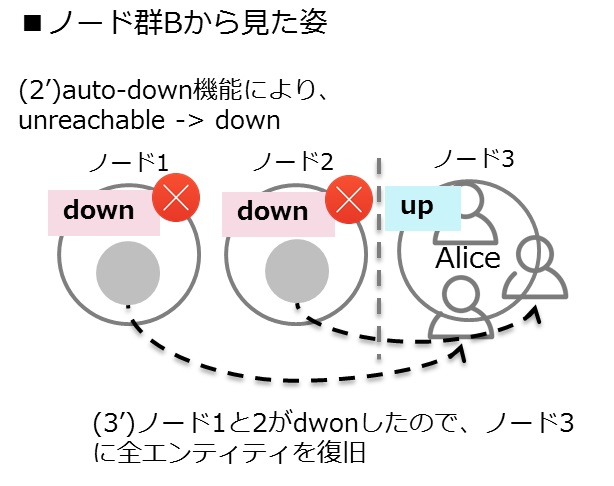
ノード群Bから見た姿
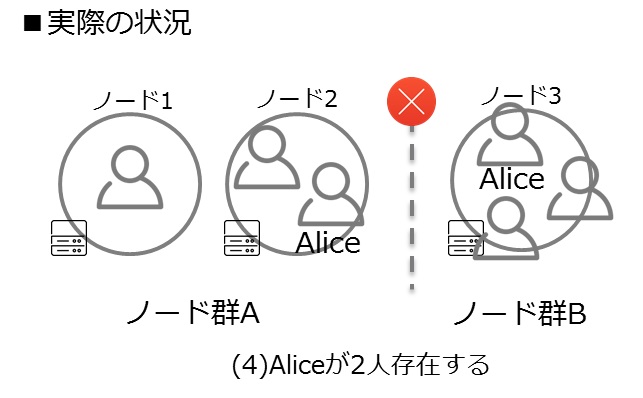
実際の状況
このスプリット・ブレインの問題に対処するためのSplit Brain Resolverという機能が、Lightbend Reactive Platformで提供されています。サブスクリプションの購入が必要となりますが、スプリット・ブレインの発生によるシステム不整合を防止する対策の手段として、Split Brain Resolverの適用を検討するとよいでしょう。予め定義したルールに基づき一方のノードがdownするので、エンティティやシングルトンアクターが複数存在し、システムに不整合を起こすことはありません。
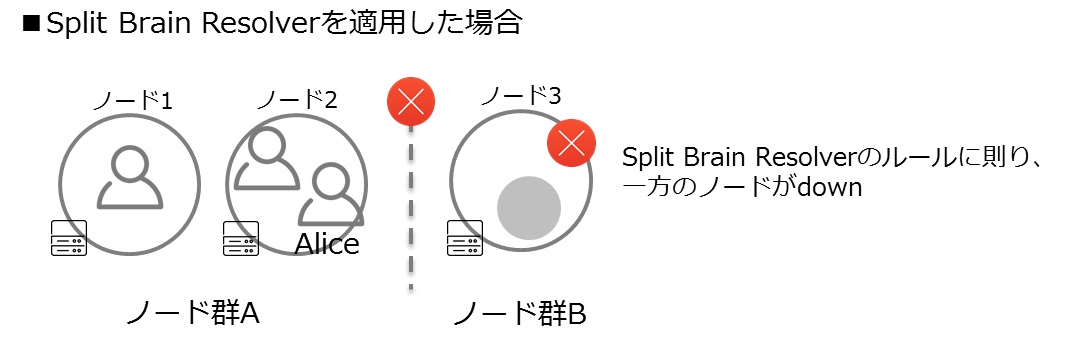
Split Brain Resolverを適用した場合
Akka Clusterの障害検知では、スプリット・ブレインの誤検知を回避するための猶予時間も設定可能なので、環境に合わせて調整し、相手側ノード群のdownを待ってアクターの回復処理を行うようにしましょう。
他にもシステムの一部で発生した障害の伝播を抑止するサーキットブレーカーなど、Akkaは障害に備えた様々な機能を提供しています。Akka Clusterに加えてこれらの機能をうまく活用し、障害を前提としたレジリエントなシステムを構築し、障害対応から開放され枕を高くして眠れるエンジニアライフを送りましょう。
おわりに
今回は、Akkaでクラスタを組んでレジリエントなシステムを構築する方法を紹介しました。実装レベルのさらに詳細な内容についてはAkkaの公式ドキュメントを御覧ください。なお、本ドキュメントは、Akka日本語化コミュニティにて鋭意翻訳中です。どなたでもご参加いただけますので、ご興味のある方はGitHub上のAkka日本語翻訳プロジェクトまでアクセスください。
参考資料
- この記事のキーワード
この記事をシェアしてください
関連記事
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
