Akka Clusterで超レジリエンスを手に入れる
今回と次回のに2回に分けて、Akka Clusterを利用した耐障害性を備えたシステムの構築について解説する。
2017年7月10日 0:00
はじめに
前回は、リアクティブシステムのメッセージ駆動を実現する分散・並行処理ツールキット「Akka」を紹介しました。アクターモデルを実装したAkkaにより、並行処理や分散処理をシンプルに実装でき、障害に強いシステムを構築できることがおわかりいただけたと思います。
昨今のクラウドブームにより分散システムに必要な基盤構築は手軽になってきましたが、パブリッククラウドは100%の可用性が保証されたものではなく、ダウンすることもあります。さらに、サーバの台数が増えれば障害点も増えることになり、障害の可能性は高まります。このような基盤の上に構築されるアプリケーションに求められるのは、サーバが落ちることを前提に作られることです。今回と次回の2回にわけて、Akkaのクラスタリング機能を使って、障害が起こることを前提にした耐障害性の高いシステムを構築する方法を、以下の流れで解説していきたいと思います。
- Akkaで構築する分散システム
- クラスタリング
- クラスタメンバーのライフサイクル
- 障害の検知
- ルータ
- Cluster Shardingによるアクターの分散
- Akka Persistenceによる状態の永続化
Akkaで構築する分散システム
前回の「メッセージの振り分け」で、Akkaはルータを介してアクターからアクターへのメッセージ送信を行うことで、様々な振り分けができることを紹介しました。さらに、位置透過性という特徴を備えているため、送信先のアクターは送信元アクターと異なるサーバに配置されていても同じようにメッセージを送信できました。しかし、ユーザーからのリクエストによる負荷や障害に対してより柔軟に反応するためには、分散アプリケーションで使用するノード数を柔軟に増減する必要があります。そこでAkkaが提供するクラスタリング機能である「Akka Cluster」を利用することで、この問題に対処できます。
Akka Clusterで複数のノードにアクターを分散させ、ノード間でメッセージのやり取りを行い、負荷分散させることやノード障害時にシステム全体を危険に晒すことなく動作させ続けることで、ユーザーに対して高いレスポンスを維持し続けるリアクティブシステムを構築できます。では、どのようにして、以下に挙げた機能を実現するのでしょうか?
- 単一障害点を最小化するのか?
- できるだけ早く、できるだけ正確に障害を検知して回復させるか?
- アクターの状態を障害時に失うことなく回復させるか?
- 一部のノードに負荷が偏らないようにアクターを平準化させるか?、ノード障害のあとはどうか?
- 複数あるノードから自身の状態を持つアクターにメッセージを振り分けるか?
その疑問に対して順に解説していきます。Akka Clusterを中心にCluster Sharding、Akka Persistence、Cluster Singleton、Distributed Data…… などの強力なAkkaのエコシステムが、どのように実現しているのかを理解していただけるはずです。
クラスタリング
クラスタは複数のコンピュータやアプリケーションをひとまとまりにしたシステムで、一つの大きなシステムとして利用できます。これにより一台のコンピュータでは実現できないような大きな負荷に耐えうる処理能力や、いつ起こるかわからない障害に対する耐性を得ることができます。クラスタに参加する各コンピュータやアプリケーションを「ノード」と呼び、複数のノードでグループメンバーシップを構成します。
Akkaではノードはネットワーク内で通信する一つのアプリケーションです。ネットワーク内の接続ポイントとなり、分散システムの一部分となります。複数のノードを一台のサーバ上で動作させることもできますし、異なるサーバに分散して動作させることもできます(ホスト名:ポート:UIDで識別)。ノードはクラスタ内の論理的なメンバーで、動的にメンバーシップに(1)参加したり、(2)離脱したりできます。クラスタ内のコンバージェンス(収束)やメンバーの状態遷移は、リーダーが管理します。
クラスタのメンバーは(3)ハートビートを送り合うことでお互いの生存確認をし、「Failure Detector」と呼ばれる障害検出機構によってメンバーの障害を検出します。そして障害のあったノードを切り離して別のノードに処理を委譲させられるため、(4)クラスタ内の一つのノードに障害が発生した時も、残りのノードでシステムは稼働し続けることができます。
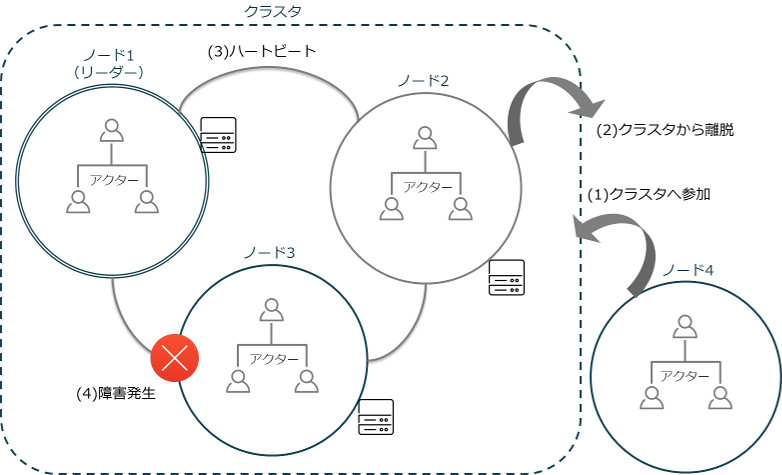
Akka Clusterのイメージ
ノードはクラスタのメンバー、クラスタはノードのグループでクラスタにはリーダーがいました。次に、リーダーのふるまいとともにノードがどのような状態を持つのかを見ていきましょう。
クラスタメンバーのライフサイクル
クラスタのメンバーであるノードは、クラスタの状況により状態を変えていきますので、どのようなライフサイクルを過ごすか、その様子を見ていきましょう。
クラスタへの参加はjoinアクションから始まります。joinアクションによりクラスタへ参加しようとするとメンバーの状態はjoiningとなります。新しいノードが参加しようとしていることをクラスタ内のすべてのノードが認識すると、リーダーはそのメンバーの状態をupに変更します。この際、メンバーはゴシッププロトコルを使用して互いに状況を通知し合います。全メンバーが全メンバーの状態を知り合意することを、コンバージェンス(収束)と呼びます。ゴシップコンバージェンスが取れたときに、リーダーが状態を変更します。これを「リーダーアクション」と呼びます。これで正式に新しいノードがクラスタに参加したことになります。
ノードをクラスタから安全に離脱させたい場合は、leaveアクションによってleaving状態に遷移させます。リーダーがleavingのノードを見つけるとexiting状態に遷移させます。ノードがexitingであることをクラスタ内のすべてのノードが認識すると、リーダーはクラスタからノードを削除しremovedとします。これもリーダーアクションの一つです。
メンバーのライフサイクル
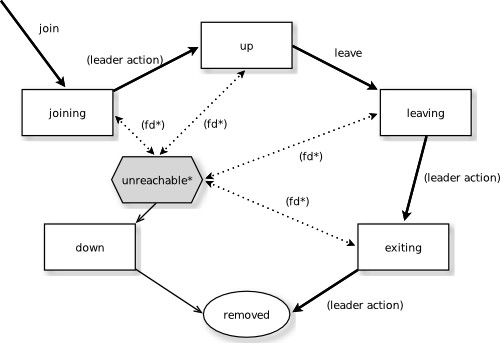
クラスターのメンバーのライフサイクル
http://doc.akka.io/docs/akka/current/scala/common/cluster.htmlより引用
障害の検知
すべてのノードが安定して稼働していれば、ノードのライフサイクルは以上ですべてですが、ノードには障害がつきものです。ノードを監視する「Failure Detector」が障害を検知すると、そのノードはunreachableとしてマークされます(上図内fd*の矢印)。これはノードの状態の一つではなく、通信できないことを示すフラグが立てられたことを表しています。通信可能であることを検知できればフラグは落とされ、ノードは元の状態に戻ります。unreachableなノードをクラスタから離脱させたい場合は、downアクションによってdown状態に遷移させると、リーダーによってクラスタからノードが削除されremovedとなります。
ノードがunreachableになり一定時間を経過すると自動的にダウンさせるauto-down機能もありますが、ダウンしたノードに存在するアクターを回復させる機能(後ほど紹介します)との併用によってシステムの一貫性を失う危険性があるため、本番環境ではauto-down機能は利用しないようにしましょう。
joiningからupへの遷移のようなリーダーアクションには、ゴシップコンバージェンスが必要でした。しかし、クラスタの中にunreachableなメンバーがいたとするとどうなるでしょうか? unreachableなメンバーとは会話できないので、メンバーの状態に関する合意もできません。こういった場合に備え、「allow-weakly-up-members」というオプションが用意されています。このオプションをonにするとjoiningのノードはweakly upに遷移され、仮up状態にできます。weakly upのメンバーは、unreachableなメンバーが通信可能になるかdown状態になり、ゴシップコンバージェンスに成功すると正式にup状態に遷移します。
メンバーのライフサイクル(weakly up=onの場合)
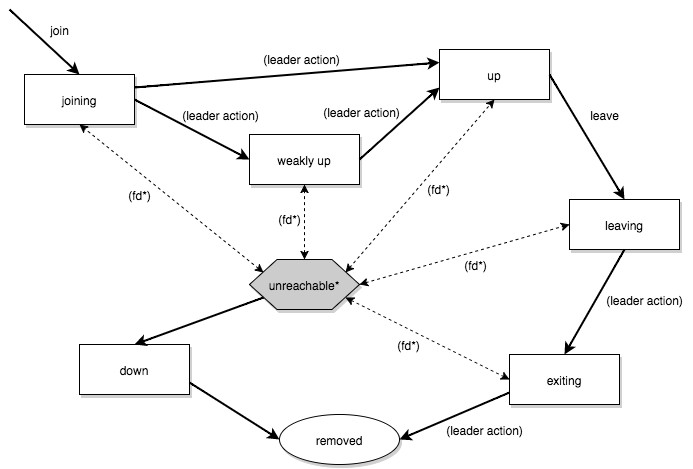
weakly up=onにした場合のライフサイクル
http://doc.akka.io/docs/akka/current/scala/common/cluster.htmlより引用
ここまで紹介したメンバーの状態を整理すると次のようになります。
クラスターのメンバーの状態
| 状態 | 説明 |
|---|---|
| joining | クラスタに参加するときの一時的な状態 |
| weakly up | unreachableなメンバー以外のメンバー間でクラスタ参加の合意がとれた仮up状態 (akka.cluster.allow-weakly-up-membersが「on」の場合のみ有効) |
| up | 正常に動作している状態 |
| leaving / exiting | 正常に離脱させるときの状態 |
| down | ダウン状態としてマーキングされており、クラスタデシジョンに加わらない |
| removed | クラスタから離脱している状態 |
| (unreachable) | 状態の一つではなく、通信できないことを示すフラグが立っている |
- この記事のキーワード
この記事をシェアしてください
関連記事
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
