Akka Streamsで実装するリアクティブストリーム
今回と次回の2回に分けて、Akka Streamsを使って実装するリアクティブストリームについて解説する。
2018年3月7日 6:10
はじめに
前回と前々回の2回で、Akkaでレジリエントなシステムを構築するためにAkka Clusterを使ってクラスタを組む方法を紹介しました。単に処理能力の向上を目的に並列化/分散化の手段としてAkkaを利用するだけでなく、障害に強く可用性の高いシステムを構築するための手段としても有効であることがおわかりいただけたでしょう。
今回と次回の2回に分けて、連続して発生し続けるデータを処理する「ストリーム処理」をAkkaで実現する方法を紹介します。Akkaではストリーム処理を実装する拡張機能として、「Akka Streams」が提供されています。Akka StreamsはJava 9の新機能として注目される「リアクティブストリーム」を実装したライブラリです。最初に リアクティブストリームを説明したあと、Akka Streamsについて、基本要素から順を追って以下の流れで説明していきます。
- リアクティブストリームとは
- Akka Streamsとは
- Akka Streamsの基本要素
- バックプレッシャー
- もうひとつの出力値
- エラー処理
- グラフとアクター(以降、次回記事で説明します)
- 複雑なグラフ
- バッファー
リアクティブストリームとは
リアクティブストリーム(Reactive Streams)は、ノンブロッキングなバックプレッシャーを備えた非同期ストリーム処理の標準です。非同期ストリーム処理を実現するライブラリや言語はさまざまですが、それらのインターフェイスを標準化し、扱いやすくしたものです。まずは、「非同期ストリーム処理」「バックプレッシャー」「ノンブロッキング」といった言葉が聞きなれない方のために、順に説明します。
非同期ストリーム処理
非同期ストリーム処理とは、ストリームデータを非同期にさばく処理を指します。ではストリームデータとはいったいどんなデータなのでしょうか? たとえば、Webシステムでユーザーが画面に入力した内容がPOSTされ、入力されたひとかたまりのデータセットやアップロードされるファイルのように明確な終わりのあるデータではなく、際限なく流れ続けるデータがストリームデータです。ストリーム(Stream)は直訳すると「小川」を意味します。小川を絶え間なく流れ続ける水をイメージしてください。その水は決まった水路を流れ、ゆったりと流れる時もあれば、水量が増え勢いよく流れることもあります。たとえば、多くのユーザーに利用されているTwitterのツイートは、まさにストリームデータです。Twitterのタイムラインを眺めていると、次々にフォローしたユーザーのツイートが流れ、完全に止まることはないことでしょう。他にも、皆さんが構築したシステムが出力するログ、あるいはモバイル・IoTデバイスから飛んでくる位置情報もこれに該当します。ビッグデータ処理が取り沙汰される昨今、溜め込んだデータをバッチ的に処理するだけでなく、ストリーム処理で、よりリアルタイムに分析・監視し、よりデータの価値を高めビジネスを加速することが求められています。
バックプレッシャー
大雨で上流から勢いよく小川に流れてきた水は、下流で溢れることなく海まで流れ着くのでしょうか? データの流れも同様で、これはデータストリーム処理にとって非常に対処困難かつ重大な問題です。そこで、この問題に対処し下流で水が溢れないよう流れを調整する機構がバックプレッシャーです。どのような機構なのかは、後ほど紹介します。
ノンブロッキング
ノンブロッキングは、「Play Frameworkのリアクティブ」の項でも説明しましたが、スレッドをブロッキングしないため、リソース効率の良い方式です。
これで、リアクティブストリームがどんなものかイメージできたことでしょう。このあと、より具体的に説明しますので、ぼんやりとイメージできていれば問題ありません。
Akka Streamsとは
リアクティブストリームは、Java SE9で「java.util.concurrent.Flow」インターフェイスとして提供されており、利用するには実装が必要です。自ら実装するのも可能ですし、さまざまなライブラリで実装されているものを利用することもできます。Akka Streamsはそれらの実装のひとつで、ストリーム処理に必要な機能やバックプレッシャーを提供しています。そしてAkka開発者は、この標準仕様の策定に強く携わっているため、その実装はより信頼できるものと言えるでしょう。
Akka Streamsの基本要素
処理ステージとグラフ
ストリームデータは、複数の処理ブロックで構成する一連の処理フローを流れます。Akka Streamsでは、各処理ブロックを「処理ステージ」、ストリームデータが流れる道筋となる一連の処理フローを「グラフ」と呼びます。処理ステージは独自に定義できるほか、Akka Streamsが提供する定義済みの処理ステージを利用することもできます。定義済み処理ステージには、要素の変換を行うmapや要素をフィルタリングするフィルター(filter)、さらには複数の入力を1つにするマージ(merge)や、1つの入力から複数の出力を行うブロードキャスト(broadcast)などがあります。その他の定義済み処理ステージの説明は、Akka公式ドキュメントで確認できます。グラフを構成する処理ステージは、ソース(Source)、シンク(Sink)フロー(Flow)の3つの種類に分類されます。
ソース(Source)
1つの出力を持つ処理ステージ。下流の処理ステージがデータ要素を受け取る準備ができているときに出力します。定義済み処理ステージとしてfromIterator、fromFutureなどがあります。
シンク(Sink)
1つの入力を持つ処理ステージ。ストリームの上流に対してデータ要素を要求し受け入れます。受け入れ速度によっては、上流の処理ステージを遅らせる可能性があります。定義済み処理ステージとしてforeach、foldなどがあります。
フロー(Flow)
1つの入力と出力を持つ処理ステージ。上流と下流を接続し、データ要素を変換します。定義済み処理ステージとしてmap、filterなどがあります。

Akka Streamsの3つの基本要素
RunnableGraph
ソースとシンクを繋ぐと、実行可能(runnable)なグラフができあがります。ソースとシンクの間にはフローを挟むことができ、両端がソースとシンクに接続されている実行可能な一連の処理を「RunnableGraph」といいます。

実行可能なグラフ
ソースとフローを繋げると、そのフローは1つの出力を持つことになり新たなソースとなります。また、シンクとフローを繋げると、そのフローは1つの入力を持つことになり新たなシンクとなります。フローとフローを繋げると、入力と出力を1つずつ持つ新たなフローとなります。

ソースとフローを繋げる

シンクとフローを繋げる
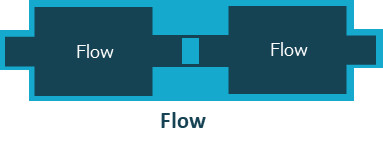
フローとフローを繋げる
ストリーム処理を実行するにはRunnableGraphが必要です。最もシンプルなRunnableGraphは、定義したソースとシンクを繋ぐだけで作成できます。
リスト1:ソースとシンクを繋いで実行(run)
import akka.actor.ActorSystem
import akka.stream.ActorMaterializer
import akka.stream.scaladsl._
// ----- グラフの定義 -----
// ソースの作成
val source = Source(1 to 10)
// シンクの作成
val sink = Sink.foreach[Int](e => println(s"element=$e"))
// ソースをシンクに繋いでRunnableGraphを作成
val runnableGraph = source.toMat(sink)(Keep.right)
// ----- グラフの実行 -----
// アクターシステムの生成
implicit val system = ActorSystem("simple-stream")
implicit val materializer = ActorMaterializer()
// RunnableGraphの実行
val result = runnableGraph.run()
// アクターシステムの終了
implicit val executionContext = system.dispatcher
result.onComplete(_ => system.terminate())
このようにAkka Streamsには、グラフの定義とグラフの実行という2つのステップが存在します。
- グラフの定義1:ソースを作る
- 1から10の数値を下流に流すシンプルなSourceを作成
- グラフの定義2:シンクを作る
- 上流から流れてきたデータ要素をコンソールへ出力するSinkを作成
- グラフの定義3:ソースとシンクを繋げる
- toMatメソッドでソースとシンクを繋げRunnableGraphを作成
- グラフの実行
- グラフを実行してマテリアライズされたインスタンスを返す
最初の3つのステップで定義し作成したRunnableGraphは、実行されるまでデータが流れません。runメソッドを呼び出すことによりグラフが実行されデータが流れます。では、これはどういった環境で実行されているのでしょうか? 実行環境は抽象化されており、それを具現化するのが「マテリアライザー」です。ソースコードをよく見ると実行前にActorMaterializerというマテリアライザーが暗黙(implicit)のスコープに定義されています。これはrunメソッドを呼び出すときに暗黙の引数として必要となるためで、runメソッドを呼び出すと、このActorMaterializerを使って実行されます。ActorMaterializerは、その名のとおりアクターを使用するため、ActorSystemが必要です。
ActorMaterializerがグラフを実行するときに、RunnableGraphをAkkaのアクターに変換します。作成したRunnableGraphは何度でも実行でき、実行するたびに新しいアクターで処理されます。とてもシンプルですが、これだけでAkkaのアクターを使ったストリーム処理を実行できます。
Akka Streamsには、ソースからショートカットで実行するメソッドも提供されています。先ほどのような処理はrunForeachメソッドを使うことで、グラフの作成と定義を1行で表現することもできます。このような実行可能(runnable)でないグラフを実行するメソッドはrunForeach以外にも存在し、実行を意味するrunで始まる名称が付けられています。
リスト2:ショートカットメソッドによるグラフの実行
Source(1 to 10).runForeach(println)
バックプレッシャー
リアクティブストリームでは、上流からデータをパブリッシュ(発行)するパブリッシャーと、下流でデータをサブスクライブ(購読)するサブスクライバーとの間で、バックプレッシャープロトコルによる通信を定義しています。

パブリッシュとサブスクライブ
サブスクライバーの処理速度を上回るスピードでパブリッシャーがデータを送り続けると、サブスクライバーに処理待ちデータがどんどん蓄積され、最終的にはバッファーがオーバーフローしてしまいます。
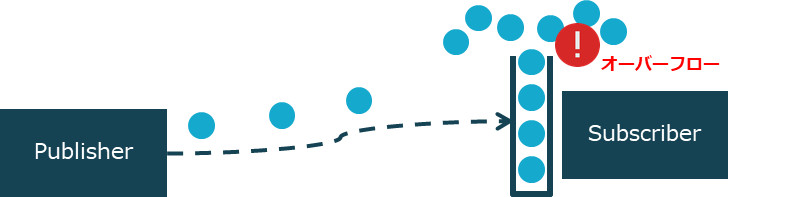
バッファーオーバーフロー
このオーバーフローの問題に対する解決策がバックプレッシャーです。バックプレッシャープロトコルには、下流のサブスクライバーが受信してバッファリングできる要素の数が定義されています。バックプレッシャーは、サブスクライバーが処理できる以上の要素を、パブリッシャーがパブリッシュしないことを保証します。
この仕組みは、サブスクライバーが自身の処理できるスピードでパブリッシャーから要素を引き出すので、「プルベースのバックプレッシャー」と呼びます。プルベースのバックプレッシャーは、パブリッシャーがサブスクライバーのオーバーフローを恐れて「100%オーバーフローしない控えめなスピードでデータを流す」といった配慮も必要なくなります(プル要求があったときにデータを渡すだけでよいのですから)。その結果、限られたメモリーで最大限に性能を発揮できます。たとえると、上司が部下の能力以上のタスクを依頼することで部下がオーバーフローしてしまうことを恐れるあまり、依頼を遠慮するのではなく、部下が自身の状況に合わせてタスクを引き取って行くので、チームのベロシティ(生産性)は最大限になるのです。有限メモリーで最大限のパフォーマンスを発揮できるこのようなアーキテクチャは、大量データのバッチ処理などにも有効です。
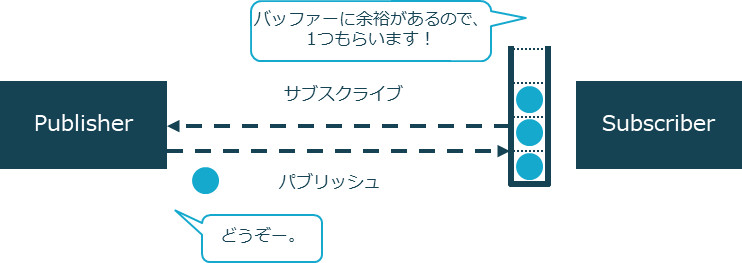
バックプレッシャー
複数の処理ステージが連なるグラフでは、下流でバックプレッシャーがかかるとさらに上流へと伝播します。このため、バックプレッシャーにより中間のパブリッシャーにデータが滞留し、オーバーフローが発生するということはありません。上司から依頼されたタスクを部下に引き取ってもらえず、中間管理職がオーバーフローすると大変です。上司と中間管理職の間にもバックプレッシャーは伝播しますので、中間管理職がプルしないのにタスクが降ってくることはありません。
Akka Streamsは、リアクティブストリームとして標準化されているこのバックプレッシャープロトコルを実装しています。パブリッシュ・サブスクライブは直接利用するAPIではなく、リアクティブストリームの実装のための低レベルな定義です。Akka Streamsはこのインターフェイスを直接公開していないため、我々は前述したソース、フロー、シンクを使って実装します。各処理ステージがどのように接続されているかなど、グラフの内容に応じてサブスクライバーがパブリッシャーをサブスクライブするようにします。これを行うのがActorMaterializerです。Akka Streamsを使うと、バックプレッシャーを明示的に記述する必要はなく、各処理ステージで自動的に構築・処理されます。
- この記事のキーワード
この記事をシェアしてください
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
