CNDT2020シリーズ:メルペイのマイクロサービスの現状をSREが解説
メルペイのマイクロサービスをSREの高木氏が解説。選択を排除したマイクロサービスの課題とは?
2021年1月5日 8:16
今回はメルペイのマイクロサービスに関する詳細を紹介する。これはメルペイのSRE(Site Reliability Engineering)のマネージャー、高木潤一郎氏のセッションによるセッションだ。高木氏はメルカリのインフラチームを立ち上げ、SREのエンジニアリングマネージャーかつテクニカルリードとして技術的な部分をリードするエンジニアである。2019年のCloudNative Days Tokyoでベストスピーカーに選ばれたセッションを担当された経験を持ち、GCPを最大限に活用したマイクロサービスの実装でも知られている。
セッションの動画は以下から参照できる。なおセッション自体が開始されるのは17分を過ぎた辺りなので、そこまでスキップすることをお勧めする。

メルペイのマイクロサービスを解説する高木氏
高木氏のプレゼンテーションは、メルペイの概要から始まった。ここではメルペイがサービスインした2019年2月から2020年9月の約1年半で、マイクロサービスの数は60に達し、700万人が利用するサービスとなったことを紹介した。約1年前のプレゼンテーションでは「マイクロサービスは40、ユーザーは200万人」と紹介されていたことを考えると、急速に拡大していることがわかる。
参考:CloudNative Days Tokyo 2019:メルペイのマイクロサービス化の目的とは?
アーキテクチャーは変わらずにGoogle Cloud Platform(GCP)に特化したものになっており、GoogleのマネージドKubernetesであるGKEにすべてのサービスが実装されている形だ。

メルペイのアーキテクチャーはすべてGCP上に実装
そして開発を加速するためメルカリ、メルペイで共通のプラットフォームとなるマイクロサービスプラットフォームを開発し、利用していると解説した。いわゆる社内のエンジニアがすぐにKubernetesのインフラストラクチャーを利用できるようにするためにX-as-a-Serviceの形でテンプレート化されていることを説明した。リソースの管理はTerraform、CDにはSpinnaker、データベースはCloud Spannerというポートフォリオだ。

GCP上の共通基盤を利用
またマイクロサービス自体はレイヤー構造として構成され、クライアントからのリクエストはAPI Gateway→API Serviceを経てバックエンドのビジネスロジックに通信されることを解説した。

分割されたマイクロサービス
例として挙げたNFCによる決済も、API GatewayからNFCのAPIを経てNFCサービス→決済処理と分割されているという。
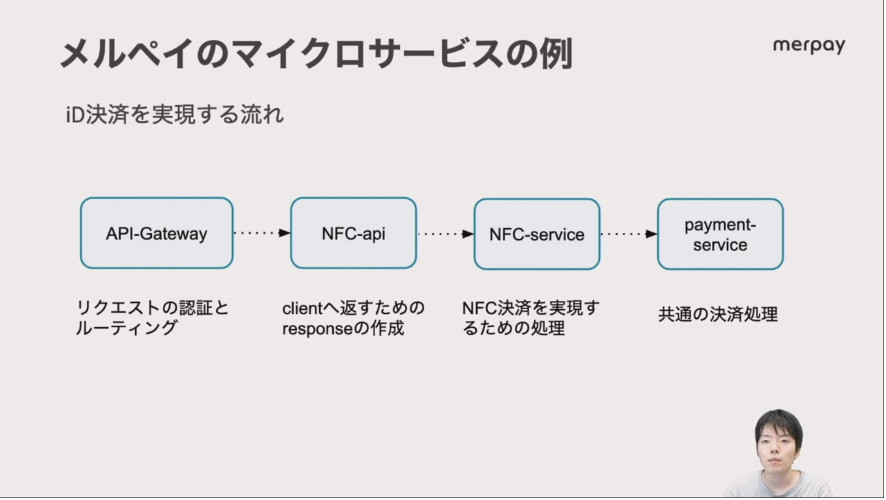
NFC決済の例
そして組織についても言及し、各機能を実装するProduct開発チームと共通のインフラストラクチャーのためのチームとに分かれていることを紹介した。インフラストラクチャーのためのチームにはSREやアーキテクト、そしてデータ分析、機械学習などのドメインスペシフィックなソフトウェアが挙げられる。

2つに分かれたメルカリ/メルペイのIT部門
専門的に機能を開発するチームと共通部分、特別な領域のチームを縦横に分けて交差させる形で開発と運用を実現している。
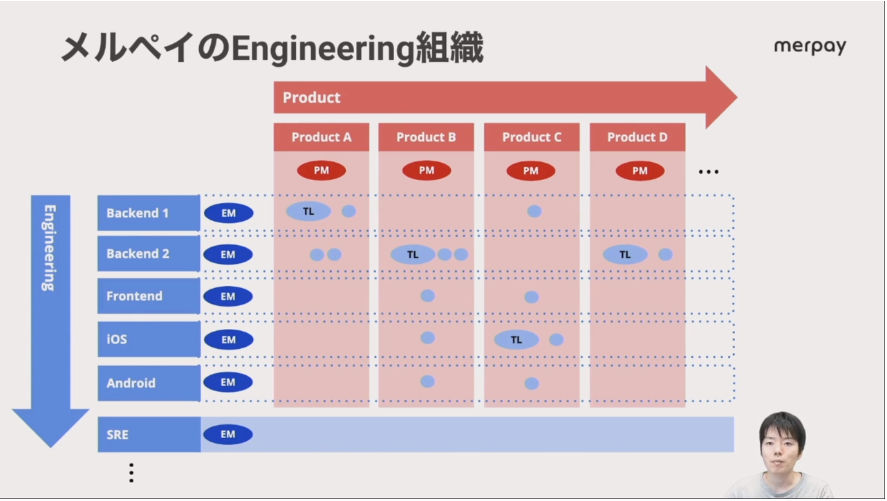
縦横でマトリックス的に構成されたチーム構成
ドメインの開発と共通部分を分けて構成されているのがポイントだが、それ以上に大きいのが、プロダクト(ここでは「メルペイに存在する機能」ととらえても良いだろう)を開発するチームは開発が終わった後も運用チームとしてそのまま担当するという部分だ。だからこの図表にあるPMはProduct Manager、TLはTechLead、そしてバックエンドもフロントエンドもスマートフォンのアプリのデベロッパーも同じチームとして運用を担当するということを意味している。
そしてマイクロサービスが増えると運用の対象となる要素(アプリケーション、データベース、ログなど)が増えることで、運用がさらに難しくなることを紹介した。
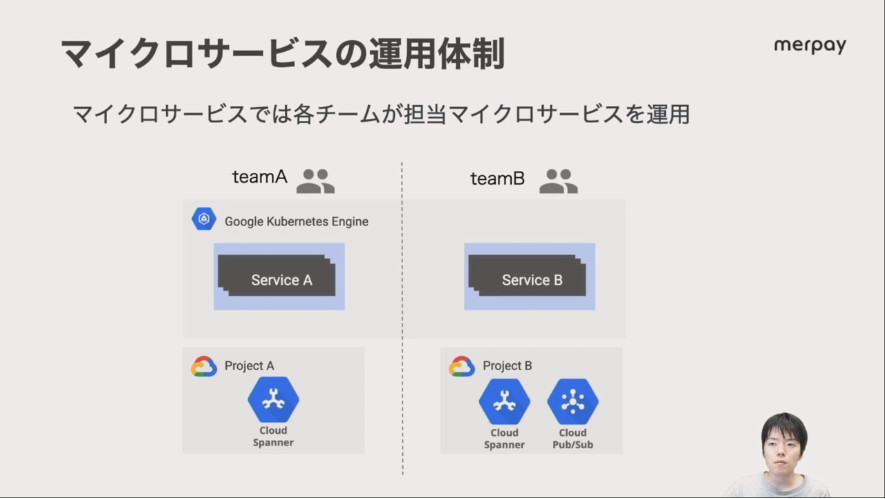
開発チームがそのままマイクロサービスの運用も担当
またマイクロサービスの開発の際に注視するポイントとして、SLO(Service Level Objectives)とObservabilityを挙げた。

マイクロサービスの運用時のポイントはSLOとObservability
これらのSLO、Observabilityの概要を紹介した後に、その実装として紹介したのが、Datadogを使った監視体制のスライドだ。クラウドネイティブなシステムの可視化に必須と言われるログ、メトリクス、トレーシングをすべてDatadogに寄せて監視し、アラートはSlackやPagerDutyなどでチームに伝達するという仕組みだ。
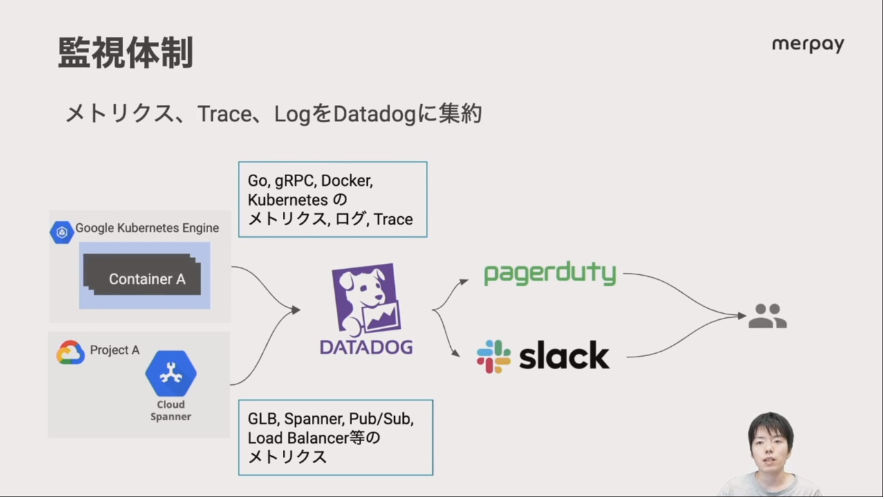
Datadogが監視のバックボーン
以上で概要の説明を終え、続いては実際にシステムを開発・運用してきたメルペイでの苦労と改善点と題したプレゼンテーションとなった。

マイクロサービス運用の苦労と改善点
まずは「マイクロサービスの数は増えたがエンジニアの数は増えていない」として、システムが複雑化していることを再度説明した。サービス間の連携、外部サービスとの連携などによって複雑さが増すのは、小さなビルディングブロックが組み合わさることで実装されるマイクロサービスの特徴だ。

マイクロサービスの複雑化が問題
ここからはマイクロサービスの開発と運用、それに組織の3つに領域を分けて、それぞれで発生した問題とそれに対する解決策について解説を行った。

問題点を開発、運用、組織に分けて解説
ここで注目すべき点は、マイクロサービスの開発をすべてのエンジニアが行えるようにプラットフォームを統一し、開発言語からデータベース、監視ツールまで共通化したことで、どのエンジニアでも社内のサービスの開発に素早く参加できるようにしてあることだ。それに加えて、開発を行ったエンジニアがそのままサービスインした自身のプロダクトを運用するという部分も特徴的だ。

開発エンジニアがそのまま運用まで行う

開発のプロセスの最後に運用がそのまま繋がる体制
アラートへの対応はもちろん、継続的な改善までを同じチームが行うことが前提となっている。これによって、ビジネスロジックを考え実装するスキルと詳細な運用までを行うスキルを兼ね備え、幅広い領域をカバーできるのがメルペイのエンジニアであるということになる。
メルペイのこの方針は、開発/運用者の負荷を高めているようにも思える。
実際、現状のデベロッパー(開発)とオペレータ(運用)という分業体制ではデベロッパーの負担が大きいため、プログラムの開発者とそれを実装する担当者(アプリケーションオペレータ)に役割を分担すべきという考え方もあるほどだ。これはAzureのMark Russinovich CTOが、Ignite 2019のセッションで披露したものだ。
参考:分散型アプリの開発と運用を分離するOAMとDapr、そしてKubernetes上の実装であるRudrとは?
筆者はこれを聞いた当時「現在のデベロッパーとオペレータの中間に新しい役割を置けるのはエンジニアが潤沢に存在する組織だけでは?」という疑問があった。実際にメルペイでは、デベロッパーがアプリケーションオペレータ、そしてインフラストラクチャーオペレータを兼ねていると思えば、このAzureの提案は妥当に見える。
メルペイとしては、幅広い業務内容を担うことにより高まる負荷について、Kubernetesをテンプレートとして利用できるマイクロサービスプラットフォームの提供や、専門チームによる共通課題の解決などで乗り切ろうとしていることを説明した。

生産性を高めて負荷をしのぐ作戦?
また開発の際に、新機能を組み込んだマイクロサービスを新機能ごとにテストできないという問題に対しては、ヘッダーにどのサービス(新機能)向けのリクエストなのか?を追加し、それをバーチャルなサービスが新機能を組み込んだサービスに振り分けるという力技で凌いでいることを紹介した。
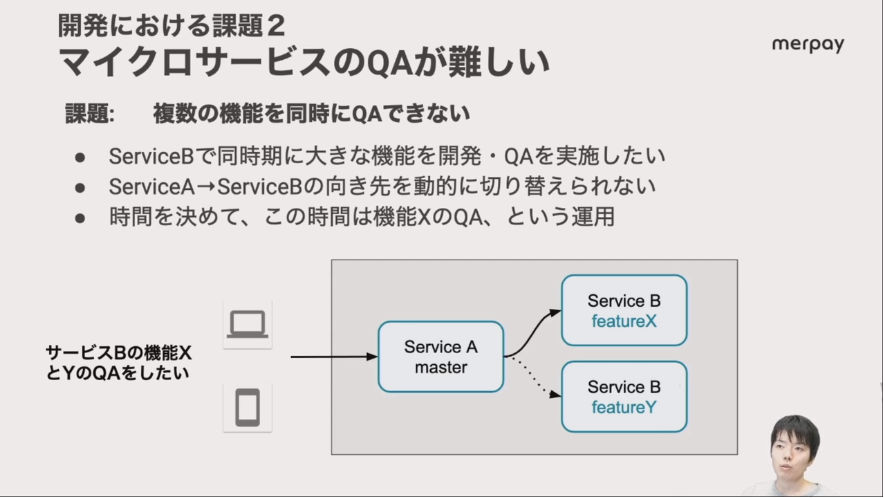
複数の新機能を同時にテストできない問題
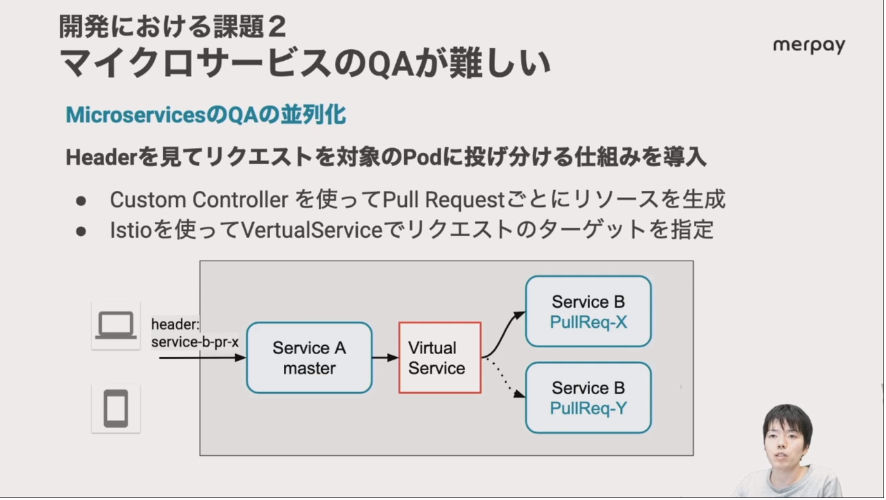
複数のインスタンスにリクエストを割り振るサービスを利用
これはクラウドネイティブなシステムでは、フィーチャーフラグを使って対応できるような問題に見えるが、どうだろう? ちなみにフィーチャーフラグについてはSaaSとして提供するベンチャー企業が存在する。
参考:フィーチャーフラグをサービスとして提供するLaunch Darkly
また運用面ではマイクロサービスの中で障害が起きた際の原因の切り分けが難しい、マイクロサービス全体の運用において信頼性を担保するのが難しい、そしてパブリッククラウドの利用におけるコストの高騰などの問題提起がなされた。
それぞれの解決策は地道なものが多く、やはりマイクロサービスの運用には多くの課題が予想されることを知らしめる効果があったのではないだろうか。
そして組織面の課題については、やはり同じチームで開発から運用まで行うことによって「運用疲れ」が発生するとして、エンジニアが希望すればローテーションを行える制度を用意したことなどを紹介した。

金融の知識と運用までが必要な体制

エンジニアのローテーションも可能に
またチームが拡大し、固定化することによってチーム毎の格差が発生しており、それを打開するためにチームを横断したミーティングやドキュメンテーションなどを推進していると説明した。
最後にまとめとしてマイクロサービスはやはり難しいこと、チーム間の連携が重要であることなどを示してセッションを終えた。

メルペイのマイクロサービスの運用のまとめ
まとめに「メルペイのマイクロサービスにはまだ課題がある」と明記していることからも分かるように、システムの改善や作り直しには終わりがないということが理解できる。高木氏の来年のプレゼンテーションも楽しみになってくると言えるだろう。「失敗はなるべく早く、一杯しろ」というのがシリコンバレーのマントラだが、メルペイが試行錯誤を繰り返してどこに辿り着くのか、引き続き注目したい。
この記事をシェアしてください
バックナンバー
この記事の筆者

筆者の人気記事
SASEのCato Networks、CEOによるセミナーとインタビューを紹介
2020年4月16日 6:00
Rustのエコシステムの拡がりを感じるデスクトップアプリのためのツールキットTauriを紹介
2022年12月16日 6:00
Zabbix式オープンソースの秘密に迫る
2025年1月31日 6:00
WebAssemblyとRustが作るサーバーレスの未来
2020年4月21日 6:00
三菱電機が設立したOSPOのメンバーにインタビュー。「インナーソース」を戦略的に使う背景とは?
2025年10月3日 6:00
エンタープライズLinuxを目指すSUSE、Red Hatとの違いを強調
2015年2月3日 19:00
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
