CNDT2020シリーズ:ヤフージャパンのインフラを支えるゼットラボが語るKubernetesストレージの深い話
ゼットラボの坂下氏によるKubernetesのストレージの深い話が行われたセッションを紹介する。
2021年1月8日 12:19
今回は、ゼットラボ株式会社の坂下幸徳氏によるKubernetesのストレージに関する技術的に深い内容のセッションを紹介する。ゼットラボはヤフージャパンのグループ会社としてヤフーのインフラだけではなく、クラウドネイティブなシステムに関する技術開発を行う企業だ。またセッションを行った坂下氏は、前職で日立製作所の研究所に所属していたシニアエンジニアだ。
このセッションではKubernetesのストレージに関するかなり細かい内容のセッションとなったが、このセッションを理解するためには、坂下氏が寄稿したKubernetesのストレージに関する以下の記事を参照すると良いだろう。
参考:詳解KubernetesにおけるPersistentVolume
またこのセッションで扱われるVolume Expansionなどについては、以下の記事に細かな解説が記載されているので参考にされたい。
坂下氏自身もこのセッションが相当に細かい内容であるということを認識しているのは、「中級者」というタグが付けられていることからもわかる。このセッションは初心者がすぐに理解できるという内容ではなく、ある程度Kubernetesを使っているエンジニアに向けた内容だ。特にCSI(Container Storage Interface)がKubernetes 1.13で登場した以降に出てきた新機能の一部を紹介していることから、以前のバージョンを知っているエンジニアにとって、その違いを知るという意味でも価値がある。また、直近のKubernetesだけを知っているエンジニアにとっても、新機能の詳細な解説として意味があるだろう。
アジェンダとして挙げたのはユーザー視点でのVolumeに関する機能3点、そして管理者視点からの機能2点となる。

このセッションのアジェンダ。ユーザー向けと管理者向けと分けて解説
最初に取り上げたのは「Volume Expansion」だ。これはKubernetesのPersistentVolumeのサイズを増やす機能だ。ここではPersistentVolume、PersistentVolumeClaim、StorageClassについては特に説明がなされなかった。ThinkITに掲載されている坂下氏の記事では、「PersistentVolume(PV)とStorageClass(SC)はすべてのネームスペースで共通のリソース、PersistentVolumeClaim(PVC)はユーザーの定義したネームスペースごとのリソースである」と説明があるように、PVCで宣言されたリソースに従って共有のストレージからボリュームが切り出されて使えるようになり、そのサイズを増やすための機能がVolume Expansionとなる。これはKubernetes 1.16からベータとして登場した機能だという。

PVのサイズを増やすVolume Expansion
そのためにはPVCの定義ファイルであるマニフェストを変更する必要があり、その手順についても解説が行われた。ここではkubectlのPatchコマンドを使って変更している。
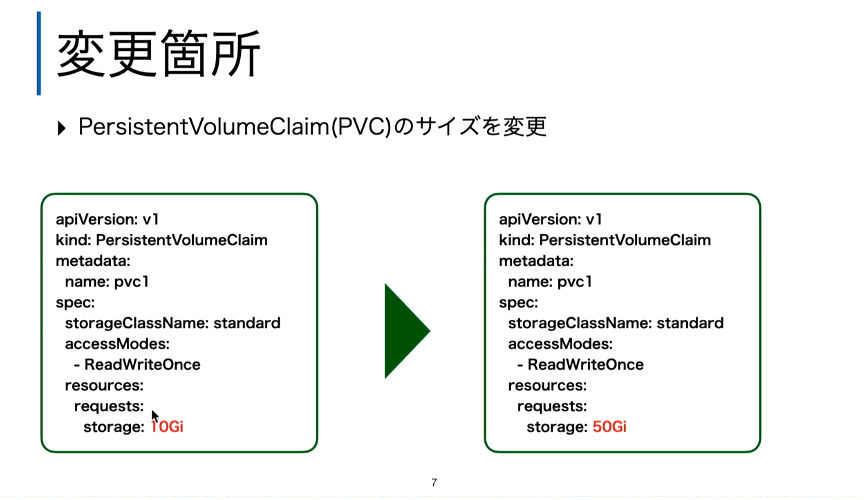
マニフェストの中の該当部分を赤字で表示
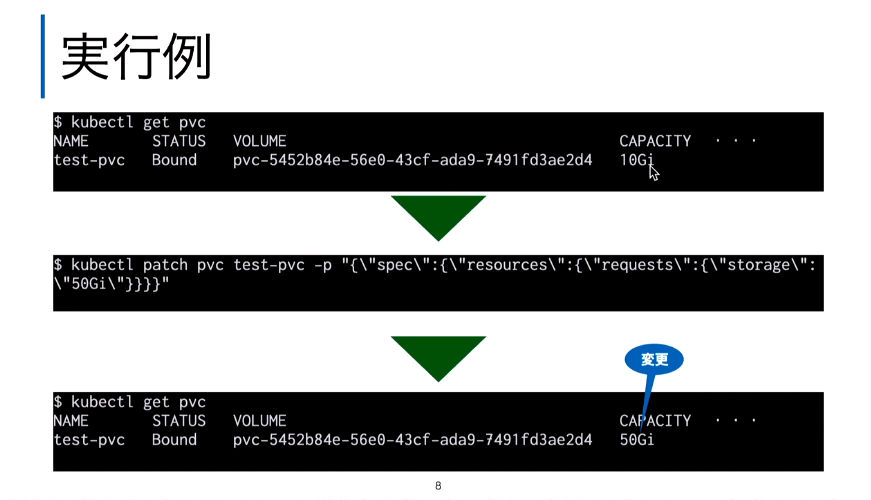
kubectlで直接変更
しかしStatefullSetでは変更にマニフェストを上書きするような方法では変更ができないとして、対処方法を紹介した。ここでは2つの方法が紹介されたが、どちらもGitOps的な運用を目指すのであれば、避けるべき方法論となる。GitOpsがすべての構成情報をGit上に存在させ、それをKubernetesに実装する方法論なのであれば、kubectlコマンドを使わないのが善だろう。

Volume Expansionのまとめ。サイズ拡大は最終手段であると認識
次に解説されたのはSnapshot機能だ。これもKubernetes 1.17でベータとなった新機能だ。
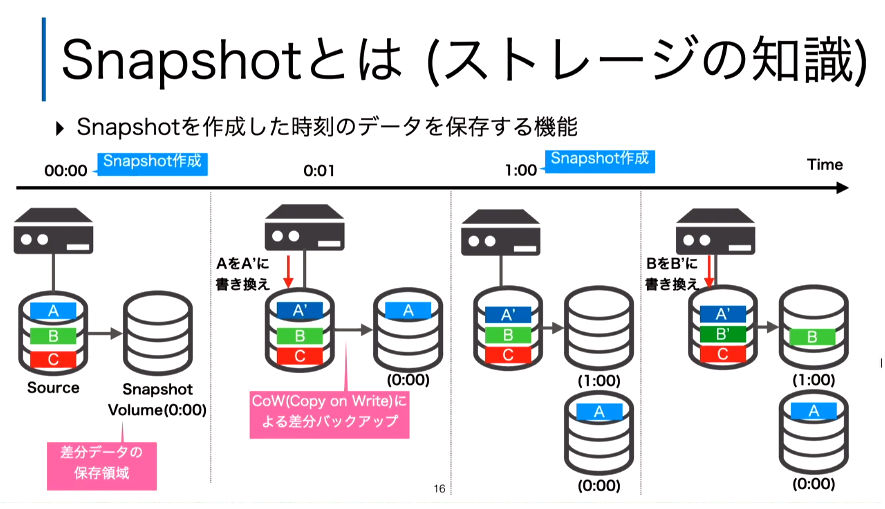
Snapshotの基本を解説
ここではSnapshotの基本を解説。ある時点でのデータを基本に、変更部分だけを別のボリュームに書き出して、後からその時点のデータに戻れるようにする機能だ。

KubernetesにおけるSnapshotの概要
ここに「宣言的なプラットフォーム」であるKubernetesの特徴が表されていると言えるだろう。VolumeSnapshotリソースが作成されることでSnapshotが実行され、実体となる差分のデータ(VolumeSnapshotContentが作成されると解説した。
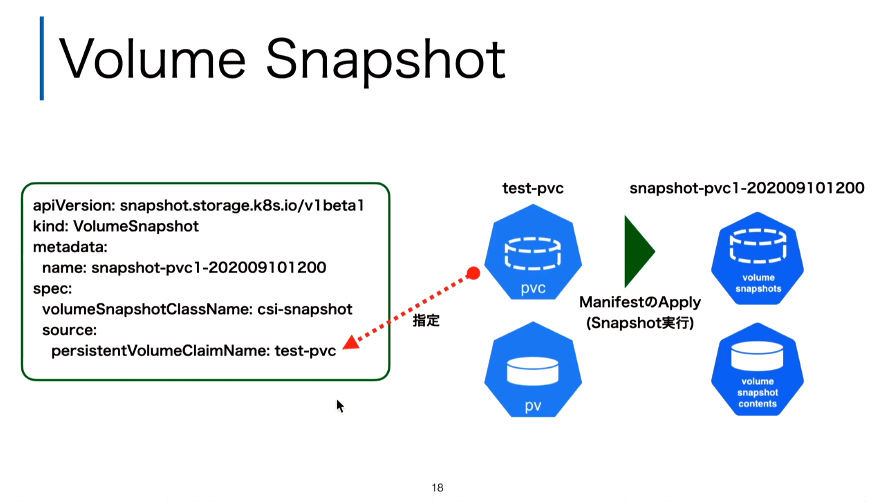
マニフェストで指定されたSnapshotが作成されるようす
またSnapshotの方法として元のVolumeとSnapshotの関係には2種類があり、元のVolumeを消せるかどうか?に関してはマニュアルなどでは確認できないと言う自身の経験から出たコメントもあった。「やってみて確認するしかない」というのは、正に中級者向けであると言えよう。
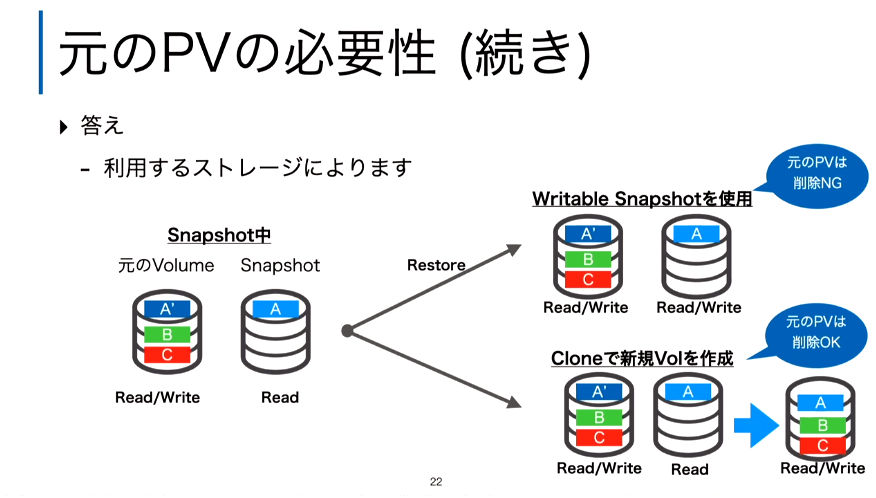
Snapshotと元のVolumeの関係は検証するしかないとコメント
次はClone機能の解説だ。ここではSnapshotの解説でもすでに出てきたCloneの機能を詳細に解説し、Nodeで実行されるデータの複製ではなく、「ストレージデバイスの中で完結するデータ複製機能である」と語った。
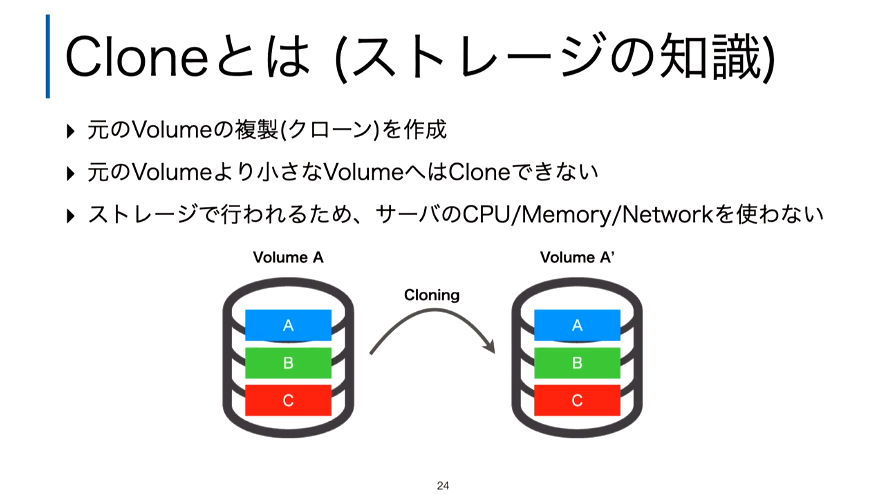
Clone機能の解説
ここでもマニフェストとしてPVCの定義の中にどのPVCからの複製を行うのかを定義し、それをApplyすることでクローンが実行されることを解説した。
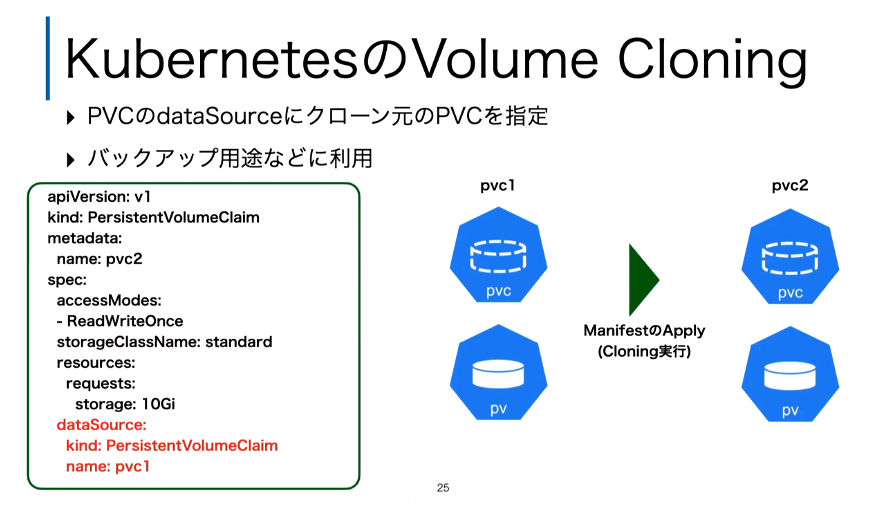
マニフェストをApplyするとクローンが実行される
例としてMySQLを使うStatefullSetのプロセスが、ソースとなるPVCから新しいPVCにクローンされるようすをスライドで解説した。
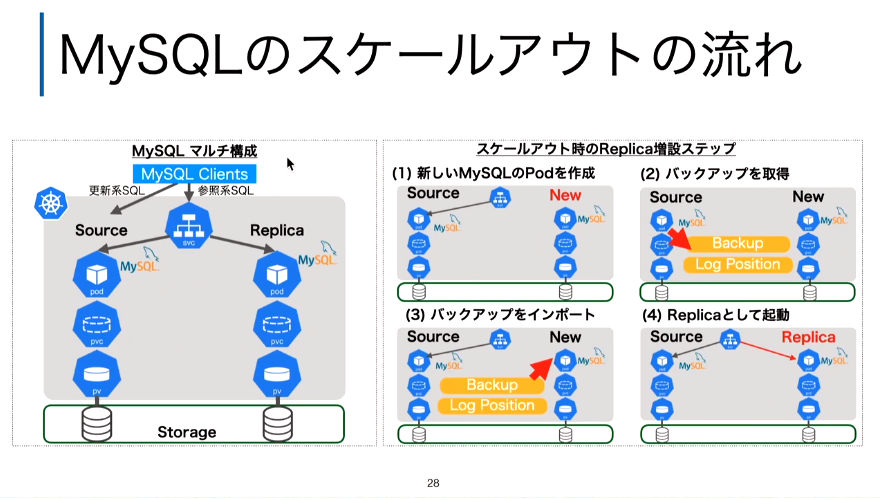
MySQLのReplicaを作成する手順。これはクローンではないことに注意
ここでReplicaの作り方に3つの方法があることを説明し、その中でもクローンがサーバーを経由しないということを強調した。
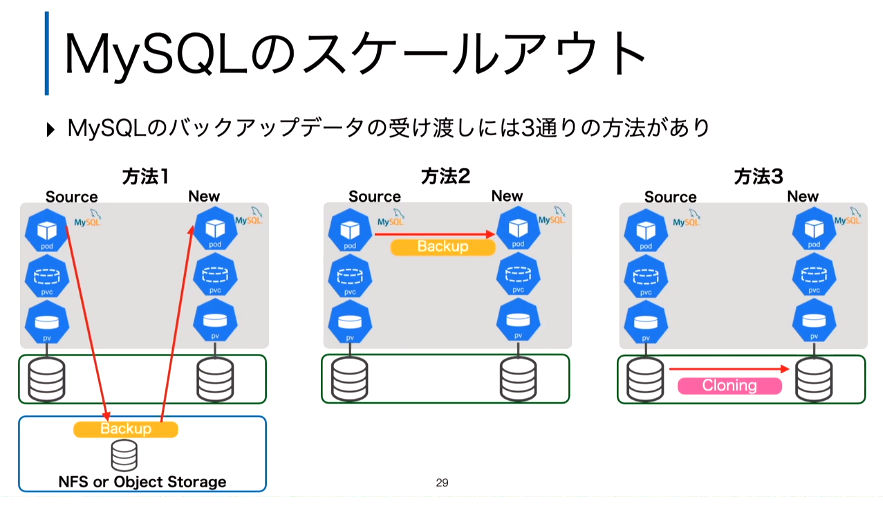
ストレージデバイス内で複製が行われるのがClone
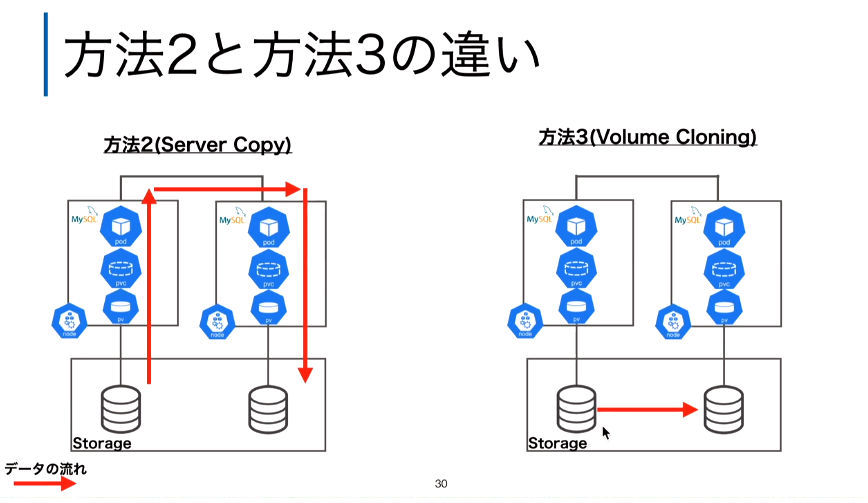
方法2と3の違い
この処理の違いにより、性能面でも大きな差が出るとして実際にベンチマークテストを行った結果が披露された。

レプリケーションとクローニングの性能評価を実施

レプリケーションでは20分、クローニングでは3分という違い
また性能面だけではなく実装としても、データ複製のタイミングが異なるためにデータの取り扱いには注意が必要だというのが次のスライドだ。
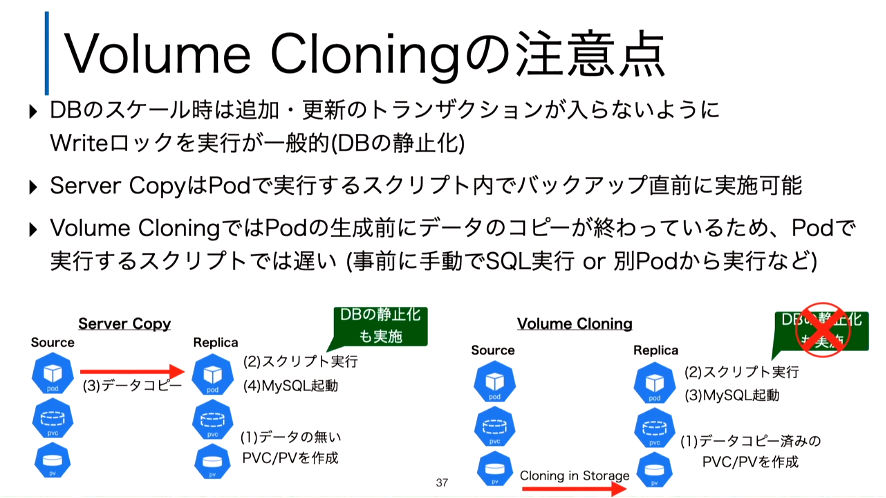
データが複製されるタイミングが違うことに注目
続いてTopologyの解説に移り、複数のNodeが存在するKubernetesクラスタにおいてAvailability Zone(AZ)を意識したストレージの扱いを解説した。これはKubernetes 1.17でGAとなった機能である。
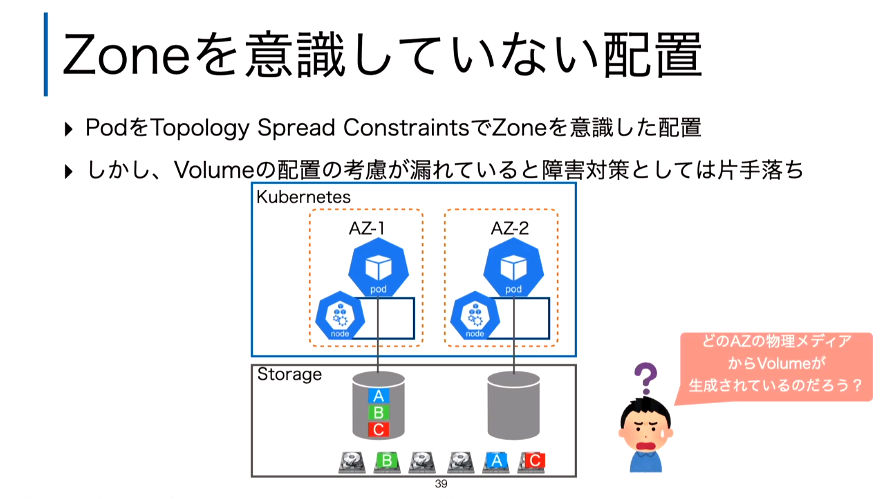
Topologyを使ってAZを意識して構成してもStorage内でのVolumeの配置が問題
このスライドではNodeの中でのAZを意識して構成したとしても、Podが利用するPVCの先に存在する実体としての物理ボリュームを指定することが必要だとしてStorageClassにおいてZoneを指定する例を解説した。
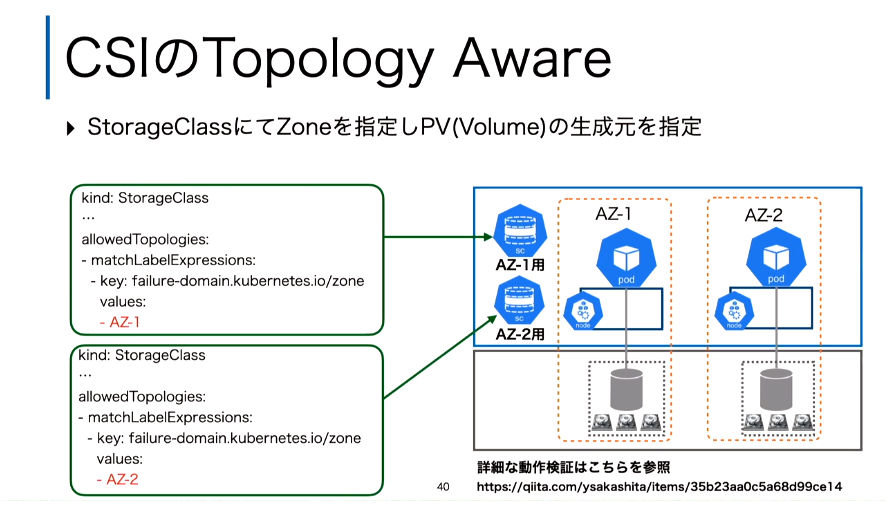
Topologyを利用可にした上でAZを指定することで物理的な位置を指定
AZの応用としてDisaster Recoveryのためにストレージ製品を構成する例を2つ挙げ、Topologyを使う方法とストレージ製品が持つミラーリング/データレプリケーションを使う方法を紹介した。
最後のトピックは、ストレージのモニタリングについての解説だ。これはPrometheusを使ったメトリクス監視を例として解説され、Podの中のボリュームの記述、kubeletの記述、そしてNodeの中の記述がそれぞれ異なっているために、包括的なモニタリングができないという問題提起となった。
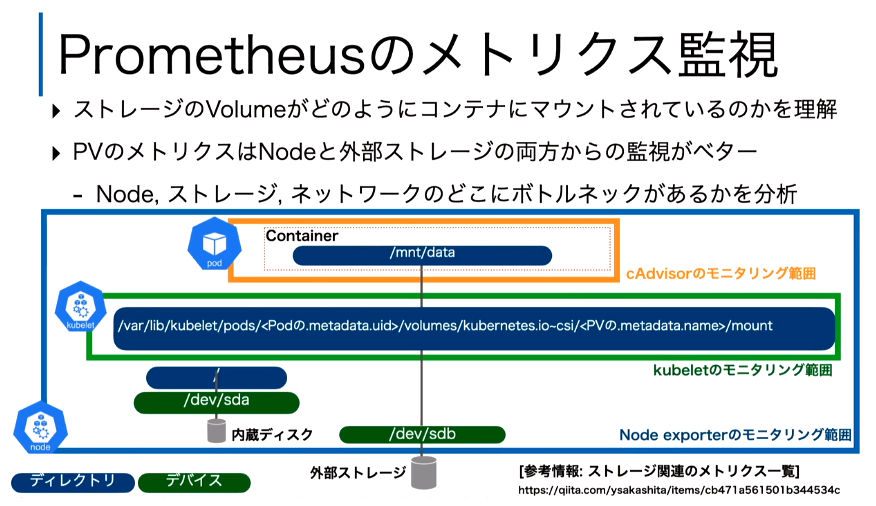
ストレージがどのようにマウントされているかを理解する必要がある
そしてユーザーが意識するべきPVC視点での性能監視においては、メトリクスが連結されていないために採取できる情報を加工する必要があるとして、ゼットラボとではそれを解決したことを解説した。

PVC単位で性能評価が出来ないという落とし穴
複数のデータを連結することで必要となるデータを見つけることが可能になったが、さらに落とし穴があったと説明した。

LVM(Logical Volume Manager)を使った場合等には連結できないことが判明
そのためにゼットラボが開発したのが、「textfile collector」というツールだ。これによってPVC視点での情報加工が可能になったという。

textfile collectorによって情報が連結できるようになった
坂下氏のセッションは以上だが、Volume Expansion、Volume Snapshot、Volume Cloning、Topology、MonitoringというKubernetesの最新情報を、実際に利用しながら得た知見を基に解説するセッションは貴重であると言える。
また坂下氏のコメントでも紹介されたサイボウズ株式会社のSREである森本健司氏によるセッションも、「Kubernetes配下のストレージをどうやって最適配置するのか?」という命題に対するユースケースとして注目すべきだろう。
これは「KubernetesでCephクラスタ用のストレージをどう管理するか 分割と配置の最適化への取り組み」というセッションでKubernetesのストレージのために利用しているRook、Cephの問題点とその解決のためのツールとしてのTopoLVMの詳細な解説となる。
- この記事のキーワード
この記事をシェアしてください
バックナンバー
この記事の筆者

筆者の人気記事
SASEのCato Networks、CEOによるセミナーとインタビューを紹介
2020年4月16日 6:00
Rustのエコシステムの拡がりを感じるデスクトップアプリのためのツールキットTauriを紹介
2022年12月16日 6:00
Zabbix式オープンソースの秘密に迫る
2025年1月31日 6:00
WebAssemblyとRustが作るサーバーレスの未来
2020年4月21日 6:00
三菱電機が設立したOSPOのメンバーにインタビュー。「インナーソース」を戦略的に使う背景とは?
2025年10月3日 6:00
エンタープライズLinuxを目指すSUSE、Red Hatとの違いを強調
2015年2月3日 19:00
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
