はじめに
前回まで、データ分析の高度化ステップ(図1)の第3段階「非定型な分析」までを説明してきました。今回からは、データ分析の高度化ステップの第4段階である「統計的な分析」について解説していきます。
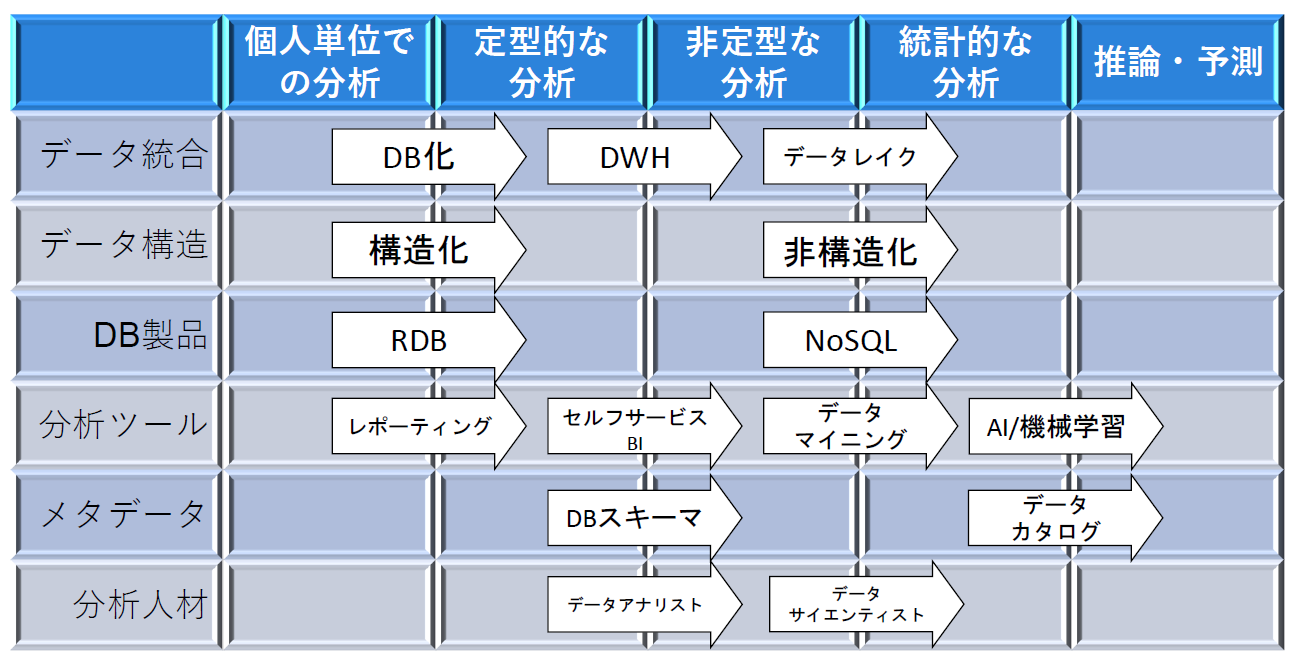
図1:データ分析の高度化ステップ【出典】ITR
「統計的な分析」とデータサイエンティスト
「統計的な分析」では、「非定型な分析」よりも、より複合的なデータの活用が求められます。PDCAサイクルのCHECKフェーズで行われる「非定型な分析」では、この数字はこうなるはずだというあるべき値が存在し、それとズレが生じた場合に「分析軸」を中心に掘り下げることで、ズレを生んだ要因を見つけ出して検証する(確認する)ということがポイントでした。
一方、「統計的な分析」でのデータ分析は、問題・課題への対処策のヒントを得るために、参考になりそうな未知の関係・傾向などをさまざまなデータから探して検証(確認)し、対処策の実行につなげる、ということがポイントになります。単純に数字の大小やズレを頼りに分析を進めるわけではないので、何を拠り所にデータを探索するかは、分析者みずからが設定する必要があります。つまり「非定型な分析」以上に自由度も難易度も高いといえ、データの分析者には自らの業務(分析対象)に対する深い理解に基づいた仮説構築力と、大量のデータを効率良く扱うための環境・手法が求められることになります(図2)。
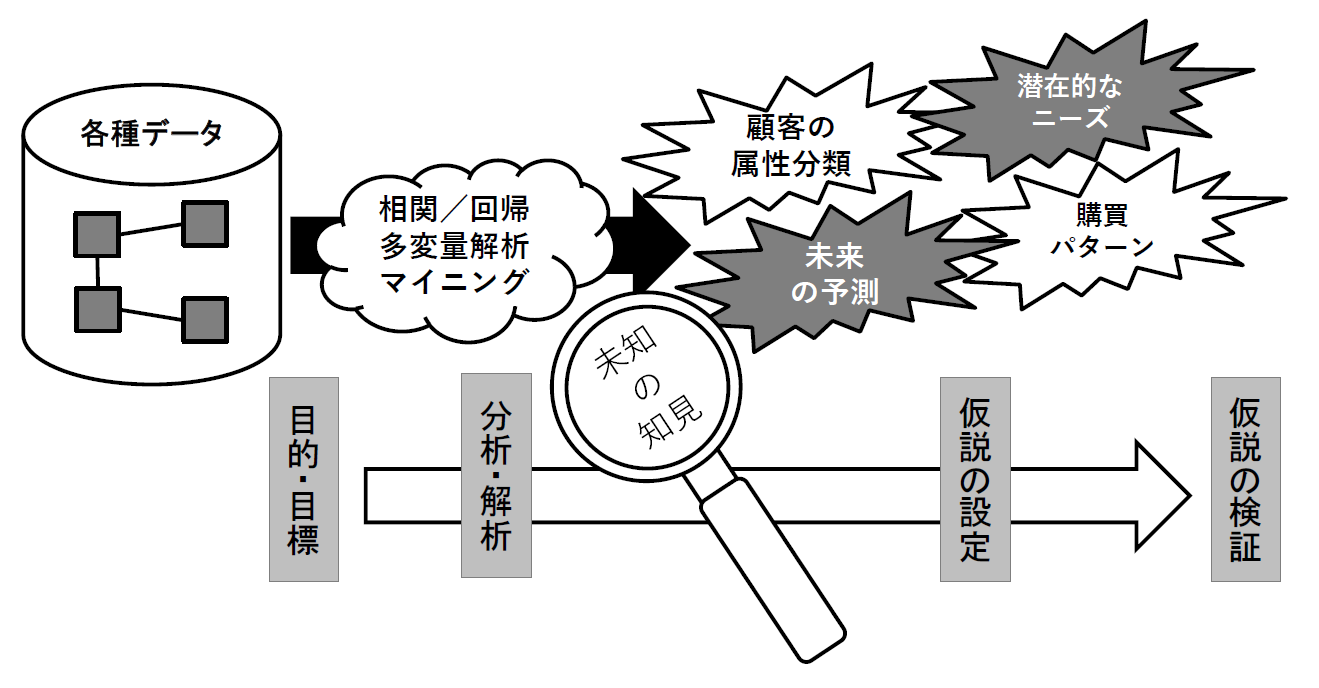
図2:「統計的な分析」におけるデータ分析のイメージ【出典】ITR
「統計的な分析」を行うデータ分析者は、データサイエンティストと呼ばれます。データサイエンティストは、一般的に統計解析の専門家と考えられていますが、それだけでは不十分で、業務(分析対象)に対する深い理解が求められます。また、大量のデータを効率良く扱うための環境であるデータマイニングツールを使いこなすスキルも求められます。
統計解析手法
「統計的な分析」ではさまざまな統計解析手法が使われますが、その代表的なものをいくつか紹介します。
相関分析
一方が変化すると他方もそれに応じて変化する関係を「相関関係」と言います。この相関関係に関する分析は、統計解析を行なううえで重要なベースとなっています。相関分析でデータの可視化に使われるのが「散布図」です。散布図は2項目の数値データを平面にプロットしたもので、数値項目間(摂取カロリーと血圧、年平均気温と年間降水量など)の関係を見るのに適しています(図3)。
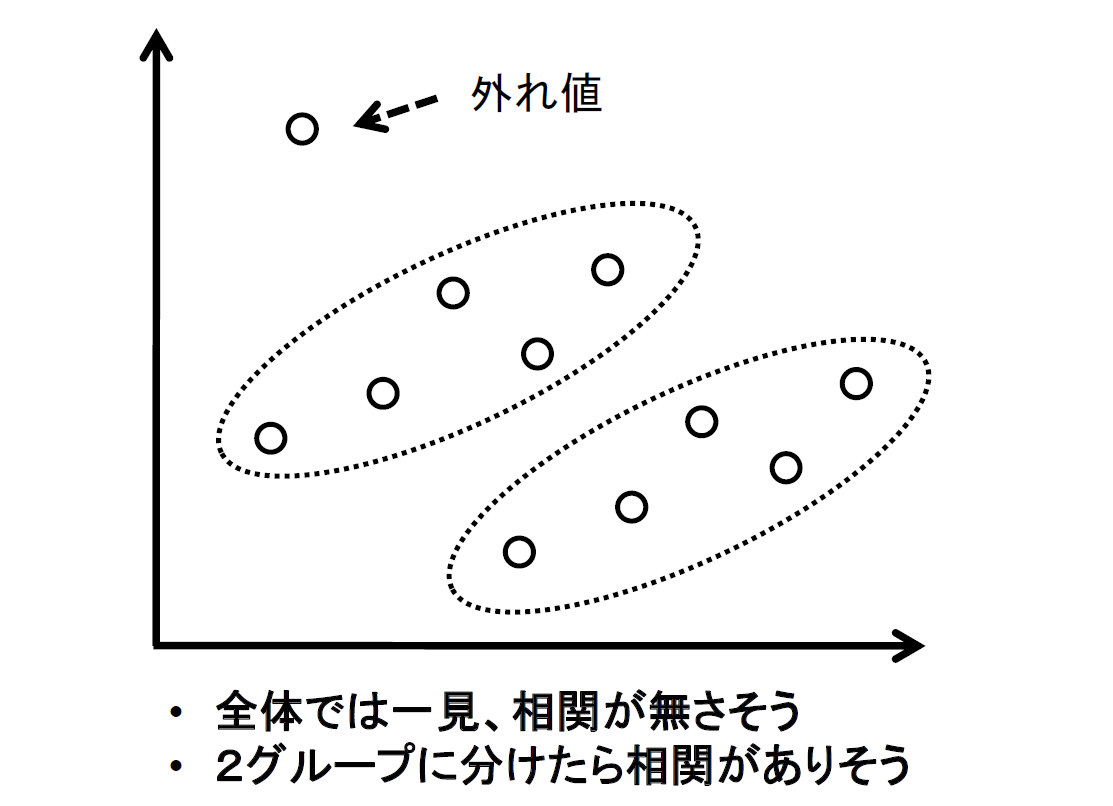
図3:散布図の意義【出典】ITR
相関関係があるかどうかをてっとり早く見るために、まず散布図を描くというのはよくあることです。散布図を作成する意義には、次のようなものがあります。
- どんな関係かを視覚的に捉えることができる
- 外れ値(異常値)を発見できる
- データの集団を異なるグループに分けられる可能性がある
散布図を利用すると相関関係の有無を視覚的に把握できますが、相関関係は相関係数(r)により、その強弱と方向を定量的に示すことができます。相関係数には次の性質があります(図4)。
- -1≦ r ≦ 1である
- r が1 に近いほど正の相関が強く、-1に近いほど負の相関が強い
- r が0 に近いときは、両変数間には相関がない(無相関)
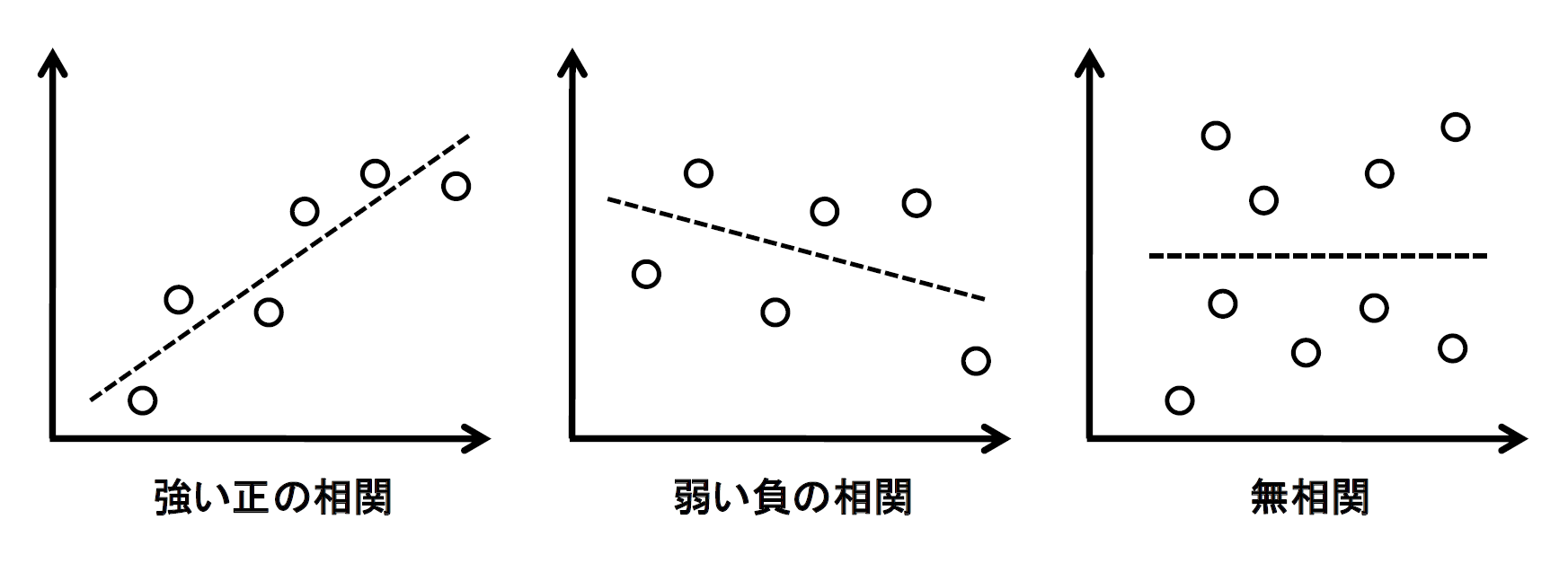
図4:散布図と相関関係【出典】ITR
ここでは相関係数の算出方法などは省略しますが、その絶対値が0.7~1.0で強い相関がある、0.4~0.7でやや相関がある、0~0.4でほとんど相関がない、といった見方をしますが、しきい値はデータの性質や分析の目的によって異なりますので注意が必要です。
回帰分析
回帰分析は、相関の中に因果関係を含めて考えるものです。相関分析の主な目的は、両変数間の関連の度合いを相関係数で評価することですが、回帰分析の主な目的は、両変数間の数的関係を回帰直線で表わし、あるx(説明変数)が指定されたときにy(目的変数)がいくつになるかを求める(推定あるいは予測する)ことです(図5)。
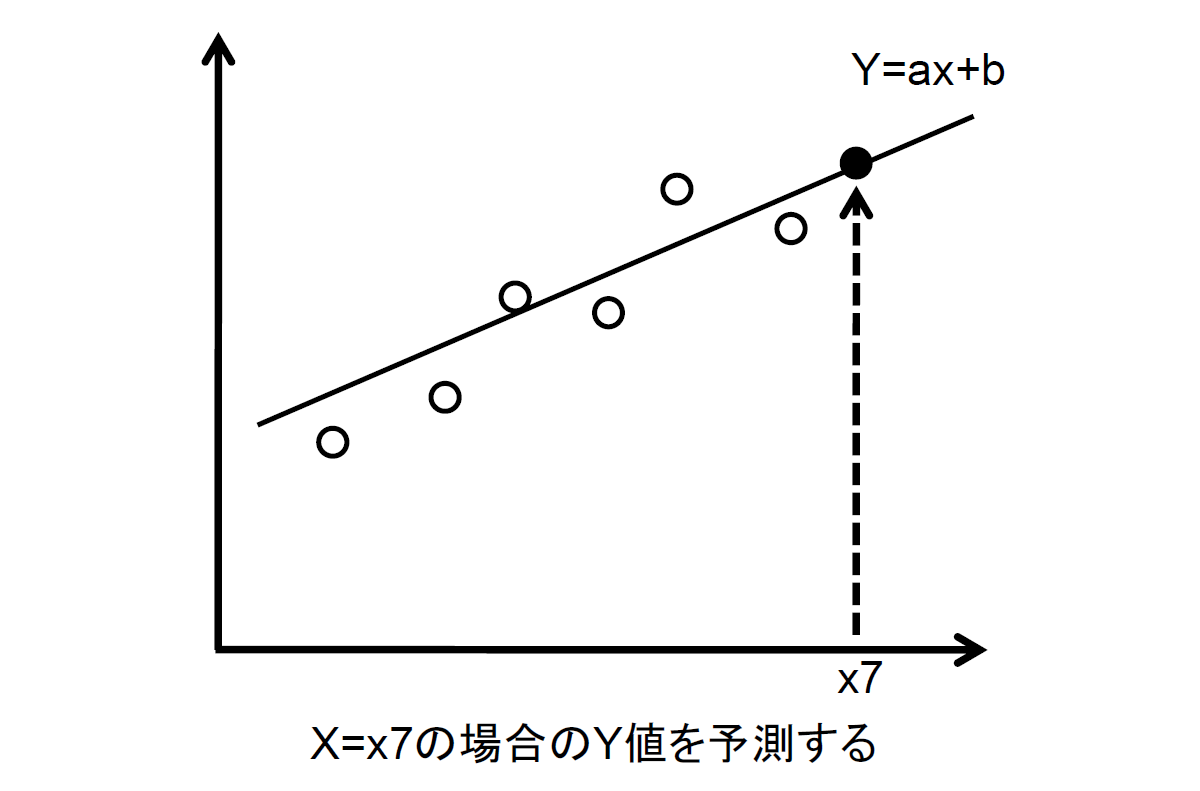
図5:回帰分析による予測【出典】ITR
因果関係は、Aという原因が元でBという結果が生じた場合に「AとBには因果関係がある」というもので、相関関係とは異なります。例えば「エグゼクティブはよくゴルフをする傾向にある」といった場合、エグゼクティブとゴルフをすることには相関関係(表面に現われる傾向)がありますが、ゴルフをしたことでエグゼクティブになったというわけではないので、「ゴルフをする→エグゼクティブになる」という因果関係は成立しません。
回帰直線を利用して予測をする場合は「相関係数が高いこと」「X → Y の因果関係が認められること」が前提になります。
多変量解析
先の相関分析も回帰分析も、2項目間での関係分析を例に説明しました。しかし、現在の社会や市場で見られるさまざまな現象は、多数の要因が絡み合って生じているものがほとんどです。したがって、それらを解き明かすことができなければ、新たなビジネスチャンスを生み出すことは難しいといえます。このような複雑な現象を解き明かす試みとして活用できるのが「多変量解析」(たへんりょうかいせき)です。
多変量解析とは、3つ以上の項目間の関係を統計的に扱う手法のことを言います。ベースにあるのは2項目間の関係を解き明かす相関分析であり、これを複数の項目間にも当てはめ、その後の処理の違いでさまざまな分析・解釈と活用がなされています。その分析手法としては、重回帰分析、判別分析、クラスタ分析、主成分分析、因子分析などが挙げられます(図6)。
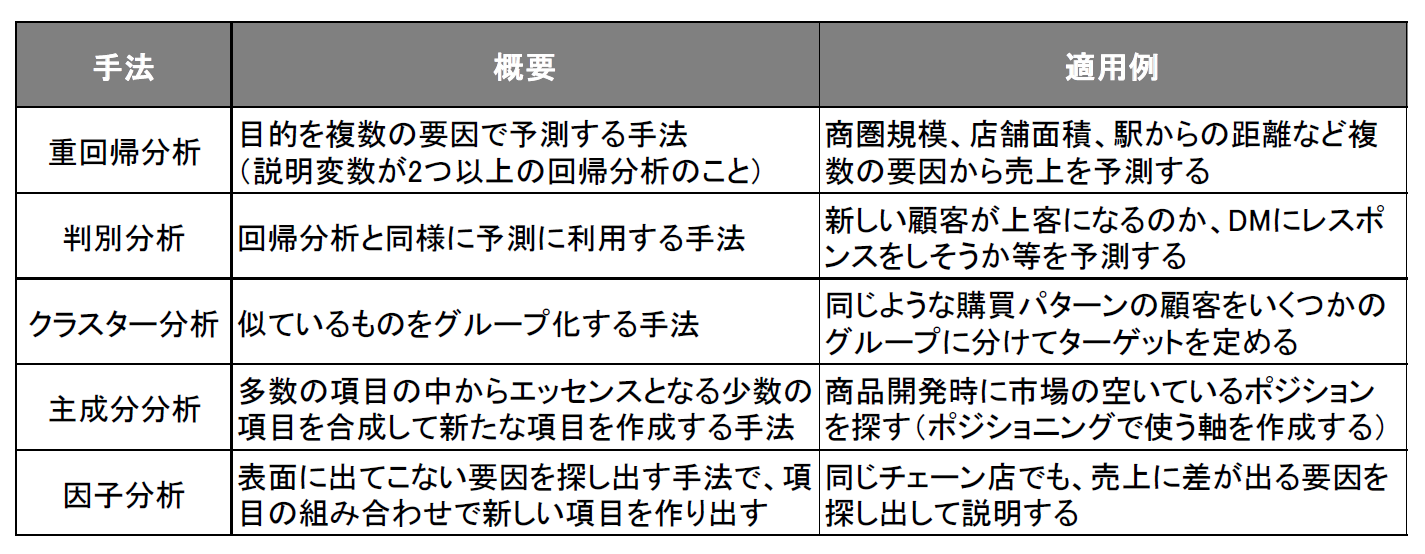
図6:多変量解析の手法【出典】ITR
データマイニングツール
「統計的な分析」において、データを解析し、その中に潜む項目間の相関関係やパターンなどを探し出す技術のことを「データマイニング」と言います。データマイニングは、個々の手法というよりも、多変量解析のような個々の手法を駆使してデータを解析する過程・技術の総称というべきものです。したがって、データマイニングツールと呼ばれるものの中には、多変量解析のような統計解析的手法、デシジョンツリーやニューラルネットワークなどの非統計解析的手法、そして外れ値の検知機能、グラフ機能などが装えられており、統合的なデータ分析環境と言えます。また、データマイニングツールは、大量のデータ、すなわちビッグデータを扱えることも前提になっています。
おわりに
データマイニングツールを使った「統計的な分析」は、以前まで医療分野における病因の推定、金融機関における信用リスクの計算といった限定的な分野で行われていましたが、近年ビッグデータの利活用が盛んになるにつれ、広範囲の分野で行われるようになりました。現在では「統計的な分析」=「ビッグデータ解析」といっても過言ではないと言えます。
この「ビッグデータ解析」においては、「非定型な分析」で使われるものとは異なったテクノロジーが必要となります。データウェアハウスとは異なる構造を持つデータレイクや、RDBMSとは異なる種類のNoSQLデータベースがその例です。次回は、これらの「統計的な分析」=「ビッグデータ解析」で使われるテクノロジーについて解説します。
この記事をシェアしてください
関連記事
データ分析システムの全体像を理解する(1) データ分析の高度化ステップ
2020年12月17日 8:20
AI/機械学習とデータ分析の関係を知る(1)データ分析業務と組織の現状
2021年8月4日 6:47
データ分析システムの全体像を理解する(7) データレイクとNoSQLデータベース
2021年6月4日 8:41
データ分析システムの全体像を理解する(4) レポーティングツールとセルフサービスBIツール
2021年3月17日 6:41
データ分析システムの全体像を理解する(5) 自由な分析環境とデータガバナンス強化を両立させる組織体制
2021年4月20日 7:48
データマネジメントの基礎を学ぶ(4)データマネジメント高度化ステップ(後編)
2022年3月11日 6:30
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
