はじめに
前回は、データ分析の高度化ステップ(図1)について解説しました。今回は、この中の第2ステップ「定型的な分析」と第3ステップ「非定型な分析」の違いについて、もう少し詳しく解説します。

図1:データ分析の高度化ステップ【出典】ITR
PDCAサイクルとデータ分析
企業における意思決定を含めた業務フローはPDCAサイクルで表わすことができます。Plan、Do、Check、Actというサイクルを回すことで、企業の意思決定と実行を合理的に行なうことができます。意思決定は、企業のトップが行なうものから現場に近いものまで、階層的に行なわれます。
企業のトップは、より戦略的な意思決定を行ないますが、一般的なPDCA サイクルは、経営戦略や経営計画の立案(Plan)、事業部門への指示と実行(Do)、月次などの経営会議でのモニタリングと問題点の分析の指示(Check)、問題点の分析と問題点を修正するための意思決定と指示(Act)というような流れになっています。一方、現場に近い部門のPDCA サイクルは、全社の戦略に沿った部門別の計画立案(Plan)、部門での業務実行(Do)、日々のモニタリング(Check)、問題点の分析と上位階層への報告や修正(Act)というような流れになります(図2)。
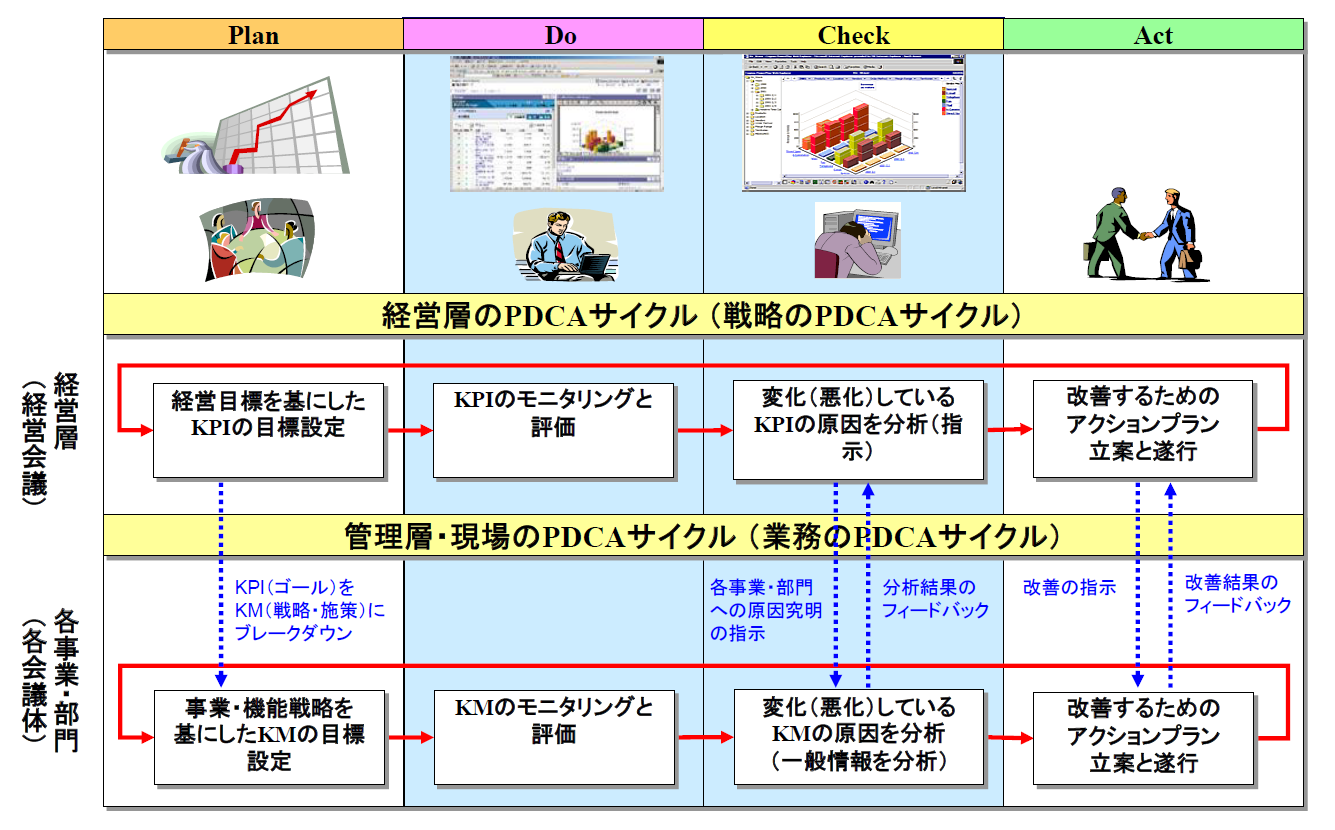
図2:企業におけるPDCAサイクル【出典】ITR
このPDCAサイクルの中のDoフェーズで行われるのが「定型的な分析」、Checkフェーズで行われるのが「非定型な分析」です。
Doフェーズで行われる「定型的な分析」
PDCAサイクルのDoフェーズは、計画に基づいて行動を起こすフェーズです。多くの社員が日々何気なく行なっている業務は、このフェーズにあたると言えるでしょう。この場面に、データの活用はどのように関わってくるのでしょうか。
企業がさまざまな活動を行なえば、その活動履歴が業務システムに蓄積されていきます。その履歴データからパフォーマンスを計測し、動向をモニタリング(監視)することが、このフェーズにおけるデータの活用方法です。例えば、販売活動の結果は販売システムに登録・蓄積されていき、これらを日々集計し、状況を都度確認することで、売上が予定通りに上がっているかどうかが分かります。
状況を都度確認する理由は、確実に目標値に到達するためにタイムリーに軌道修正を行なう必要があるからです。目標にまったく届かなったことが業績評価の段階で判明しても対処のしようがありません。何らかの異常が認められたら、状況の評価と分析を行なうCheckフェーズへと移り、手遅れになる前に対策を施し、軌道修正する必要があります。つまり、いかに素早くタイムリーに「問題の兆候」を発見できるかが、このフェーズで行われる「定型的な分析」に求められる重要なポイントとなります(図3)。
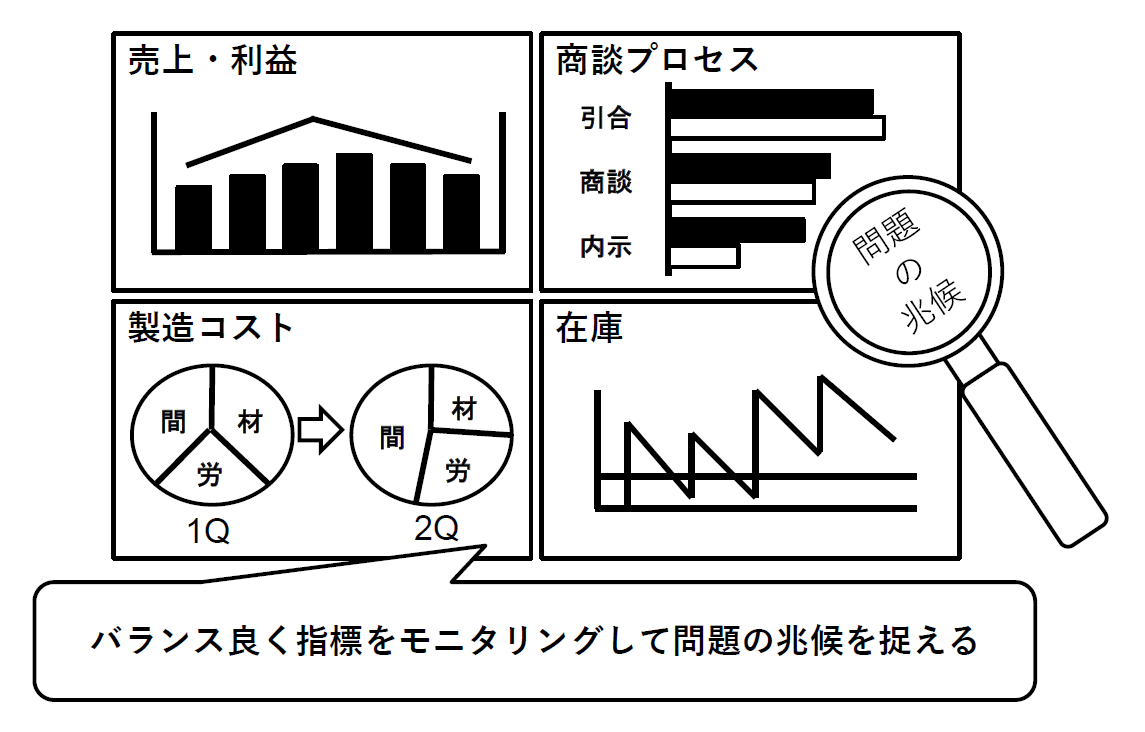
図3:Do フェーズにおける「定型的な分析」のイメージ【出典】ITR
このようなDoフェーズの「定型的な分析」のニーズには、Excelなどによる個人単位での分析では対応できません。したがって、この段階に到達するためには、Excelや複数の業務システムに散在するデータからモニタリングに必要なデータを収集し、整理された構造化データとしてデータベース化しなければなりません。このデータベースとして、通常はRDBMSが使用されます。
Checkフェーズで行われる「非定型な分析」
PDCAサイクルのCheckフェーズは、実行した結果について評価し、結果に至った理由を分析するフェーズです。計画を立て、それを実行に移した後は、その結果を十分に評価・分析し、改善につなげる必要があります。しかし、それはなかなか容易ではなく、きちんと行なわれていないことも少なくありません。このCheckフェーズにおいて、データ分析はどのように関わってくるのでしょうか。
データを見る上でのフレームワーク(指標や切り口)には、基本的にDoフェーズで定義したものを利用できます。しかし、Doフェーズが定型のフォーマットでサマリレベルの現象を捉えるのが中心であったのに対し、Checkフェーズでは捉えた現象をより深く掘り下げていくことが求められます。結果に至った要因がどこにあるのかアタリを付け、それが本当に要因なのか検証することまでを行ないます。
分析を行なう上では、サマリレベルのデータに分析軸を加えて内訳を見たり、ほかの分析軸に切り換えたり、複数の分析軸を重ねたりといった「非定型な分析」が要求されます(図4)。

図4:Checkフェーズにおける「非定型な分析」のイメージ【出典】ITR
多次元分析
Checkフェーズにおける「非定型な分析」で使われる分析手法が多次元分析です。多次元分析は、ピボット分析、あるいはOLAP分析と呼ばれることもあります。
多次元分析を理解する上では、いくつか押さえておくべきキーワードがあります。
- 次元と階層
- 軸の入れ替えによる動的な集計
- スライシング
- ドリルダウン&ドリルアップ
ここからは、これらのキーワードについて順番に説明します。
次元と階層
次元とは分析軸を指し、データを分析する前に適切な分析軸が何であるかを定義しておくことが重要です。必要な分析軸が揃っていないと、それ以上数値を掘り下げることができません。逆に、余分な分析軸があると集計パフォーマンスの低下や操作上の混乱を招きます。分析したい数値項目(売上、原価、利益、在庫など)ごとに過不足のない分析軸を検討することは、自社のビジネスを理解することにほかなりません。
さらに、各分析軸に適切な階層を設定する必要もあります。例えば、時間軸であれば「年→四半期→月→日」、組織軸であれば「事業本部→事業部→部→課」といったものです。階層を設定するということは、集計の順番を固定化するということです。ユーザーは、特に意識しなくてもこの階層順に掘り下げることになります。階層の順序を入れ替えて集計する必要がある場合(担当→顧客、顧客→顧客など)は、それを別の分析軸として定義することになります(図5)。
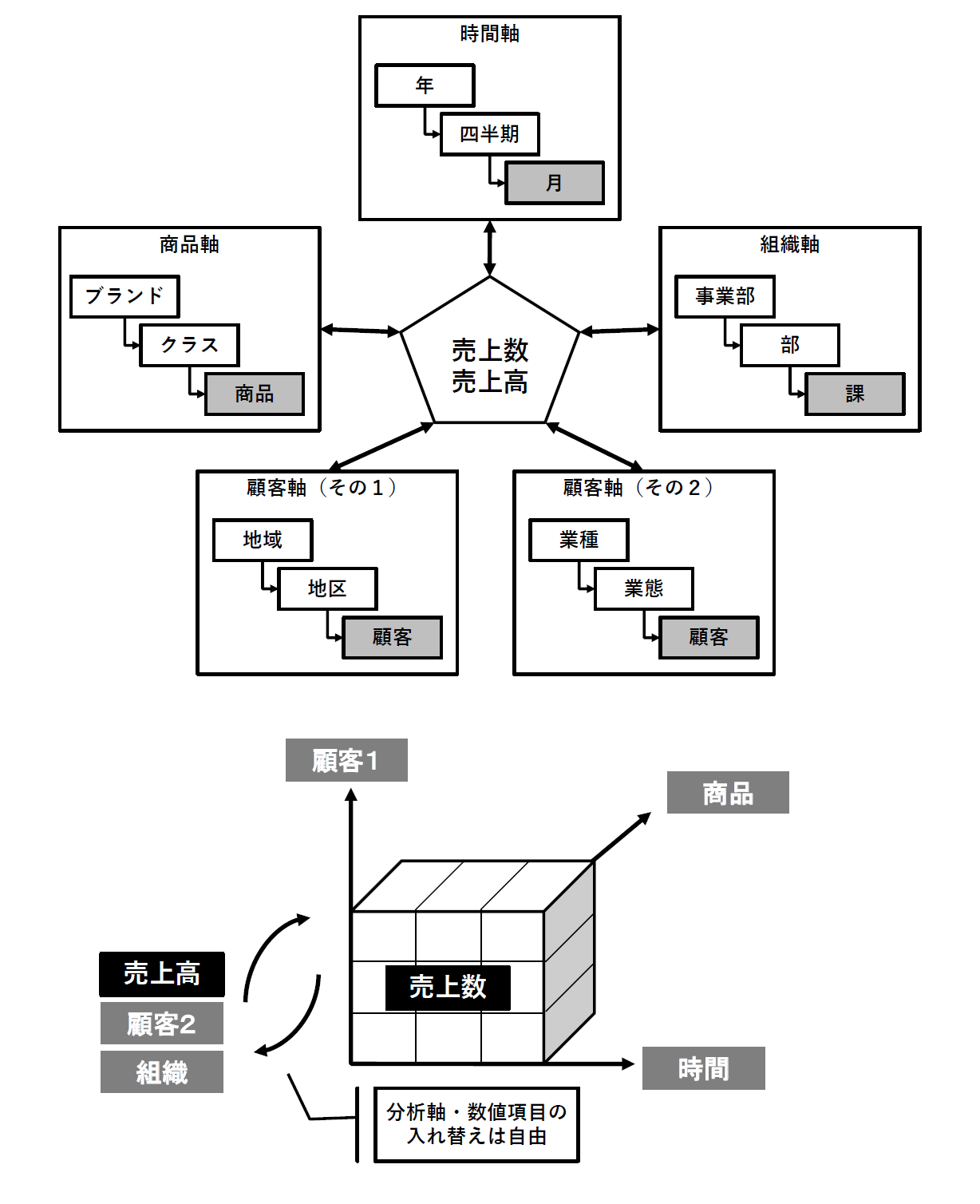
図5:データモデルとデータの集計イメージ【出典】ITR
このように、階層を持った次元とそれらで切り分けて見る数値項目の組み合わせからデータモデルを事前に組み立てることで、多次元分析における柔軟な集計が可能となります。
軸の入れ替えによる動的な集計
多次元分析の特徴的な操作と言えば、複数の分析軸を柔軟に入れ替えることです。これにより、さまざまな集計表を動的に作成できます。2つ以上の分析軸を縦・横に配置して集計を行なうことをクロス集計と言います。多次元分析では「奥行」にも分析軸を設定できますが、この奥行はフィルター条件として活躍します(次項で説明)。この軸・数値の組み合わせ、レイアウトの組み立て方(縦・横・奥行への配置)によって、そのパターンは無数にできることになります(図6)。
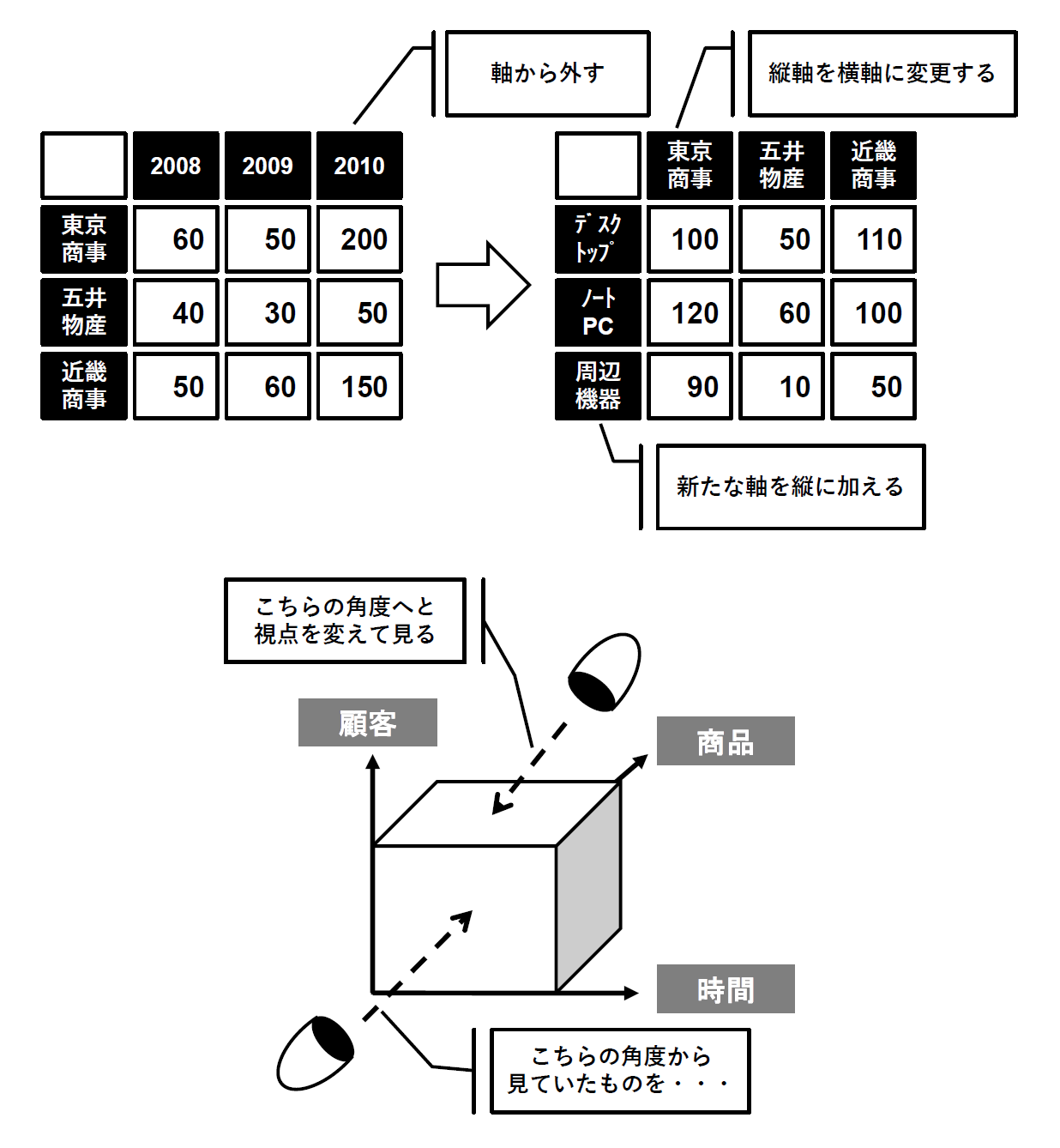
図6:軸の入れ替え【出典】ITR
スライシング
集計表を作る際に、奥行を変えることをスライシングと言います。データのかたまりをある切り口で切り出して集計を見ることから、野菜などをスライスする様子になぞらえてこのように呼ばれます。具体的な操作としては、フィルター条件に任意の分析軸を設定し、さらにその分析軸内のメンバーを指定することでデータを絞り込みます(図7)。
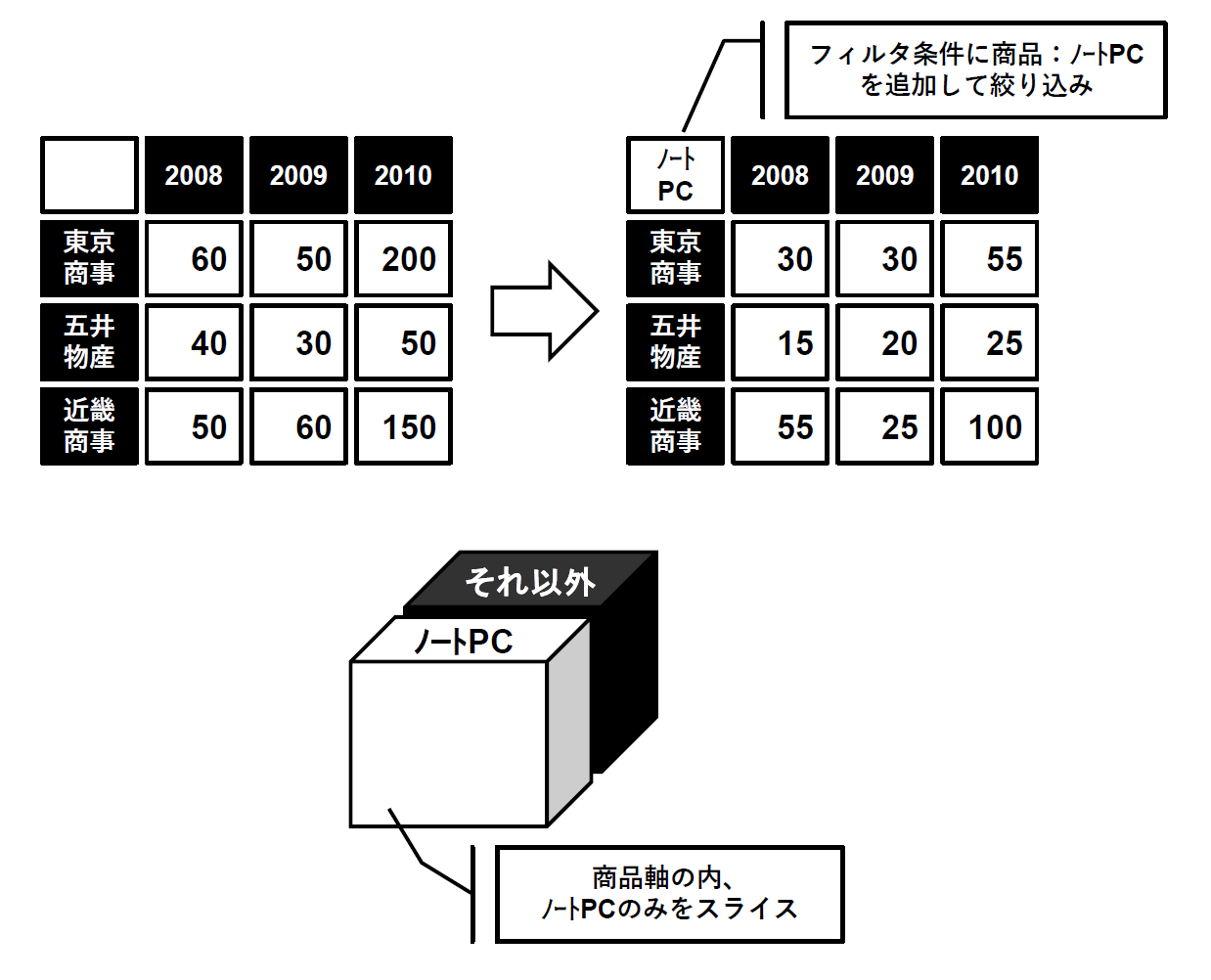
図7:スライシング【出典】ITR
ドリルダウン&ドリルアップ
ドリルダウンとは、集計値を掘り下げて見ることです。例えば、ある年度の売上が気になったとすると(例年とは大幅に数値が異なるなど)、それをその年度の四半期単位または月次に分割して見たり、商品軸や顧客軸などの分析軸を追加して売上の内訳を見たりすることができます。データの掘り下げ方には、先に述べたように分析軸を追加する方法と、分析軸に設定されている階層を上位から下位へ降りていくという方法の組み合わせがあります。
ドリルアップはドリルダウンの逆で、分割されている値をまとめていくことを指します。こちらは、分析軸の階層を下位から上位へ上がっていくか、分析軸を集計表から外すことで実現できます(図8)。
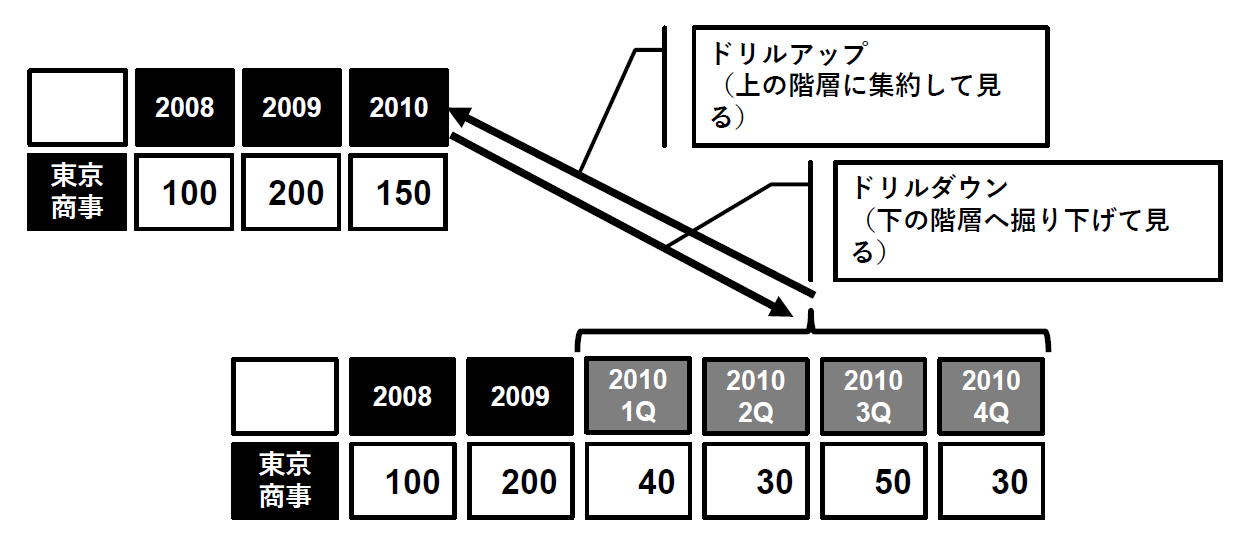
図8:ドリルアップ&ドリルダウン【出典】ITR
おわりに
Checkフェーズで行われる「非定型な分析」の分析手法としては、今回で解説した多次元分析が使用されますが、多次元分析を可能にするには、「定型的な分析」用に構築されたデータベースでは不十分です。
「定型的な分析」用のデータベースには、モニタリング画面に表示するKPIやKMの計算に必要なデータがあれば十分ですが、多次元分析にはデータモデルに含まれるすべての次元と階層と関連付けられた数値項目データが必要となるため、多次元分析を可能にするためには、データウエアハウス(DWH)と呼ばれる大規模データベースを構築します。
また、多次元分析で行われる軸の入れ替え、スライス、ドリルダウン&ドリルアップといった操作を可能にするためには、スタースキーマと呼ばれる特別なデータベース構造を持たせる必要があります。次回は、このデータウエアハウス(DWH)とスタースキーマについて解説します。
この記事をシェアしてください
関連記事
データ分析システムの全体像を理解する(3) データウェアハウスとスタースキーマ
2021年2月10日 9:13
データ分析システムの全体像を理解する(8) データカタログとデータ・プレパレーション・ツール
2021年7月13日 6:30
AI/機械学習とデータ分析の関係を知る(3) 学習済みモデルによるデータ分析の効率化
2021年10月14日 6:30
AI/機械学習とデータ分析の関係を知る(2) シチズン・データ・サイエンティストの役割
2021年9月14日 6:30
データレイクとストリームデータ処理を理解する
2020年10月23日 6:30
創業期以降の成長戦略とファイナンスを考える
2024年11月27日 8:06
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
