はじめに
前回で紹介した「統計的な分析」が行われる「ビッグデータ解析」分野においては、「非定型な分析」で使われるものとは異なったテクノロジーが必要となります。データウェアハウスとは異なる構造を持つデータレイクや、RDBMSとは異なる種類のNoSQLデータベースがその例です。これらのテクノロジーのうち、今回はデータレイクとNoSQLデータベースについて解説します。
データレイクとは
「統計的な分析」の対象となるビッグデータを処理するため、データベースには、今まで以上に大量かつリアルタイムに発生する数値データを蓄積することが求められるようになったため、従来の「非定型な分析」に使われるデータウェアハウスでは対応できなくなりました。
第3回で説明したとおり、データウェアハウスでは多次元分析を可能にするためにスタースキーマ構造を持ちますが、スタースキーマでは情報が高度に正規化されるため、ディメンションの数やジョインの数が増えて、検索の際にシステム的な負荷が増大します。
また、マスターレコード(ディメンションレコード)の追加の際に必要となる、サロゲートキーの付加をはじめとするマスターの一貫性を保証するための「マスターメンテナンス処理」が極めて複雑で、頻繁にマスターレコードの変更が発生する場合は、メンテナンス処理が追い付かなくなるリスクがあります。
同様に、業務システムで発生する明細データはいったん集約した後、ファクトテーブルに保存する必要があるため、リアルタイム性を保証するのが難しくなります。
ビッグデータの場合、スタースキーマのこれらの特性(弱点)が顕著に現れるため、ビッグデータのような莫大なデータを処理するには、データベースにはスタースキーマと異なるデータ構造を持つ「大福帳スキーマ」が使われます(図1)。

図1:スタースキーマと大福帳スキーマ【出典】ITR
大福帳スキーマは、もともとERP分野で発生した考え方で、通常業務システムにしか存在しない明細レコードをすべてそのまま格納する仕組みです。そのため、大福帳スキーマで構成されたデータウェアハウスは「オペレーショナル(業務用の)データウェアハウス」と呼ばれますが、ビッグデータ解析の分野では、これを「データレイク」と呼び、データウェアハウスとは明確に区別しています。
データレイクの大福帳スキーマでは正規化も集約も行わないため、マスターの一貫性は保証されず、全体のデータ量もコントロールできません。その代わりに、短時間で膨大に発生する明細レコードをリアルタイムで格納でき、マスターのメンテナンスで処理が停滞することもありません。
ビッグデータの特徴の1つとして挙げられる「非構造化」データは、一般的に(可変長の)テキスト、画像、音声、動画といった非数値データを意味しますが、データベース構造の分類においては、スタースキーマのように明確なスキーマ構造を持つものを「構造化」データ、大福帳スキーマのように明確なスキーマ構造を持たないものを「非構造化」データと呼ぶ場合があります。
NoSQLデータベースとKVS
データウェアハウスとデータレイクでは、データベース構造だけでなく、使われるデータベース技術も異なります。大福帳スキーマのように明確なスキーマ構造を持たないデータデータ構造では、テーブル間のリレーションを持つ必要がなく、RDBMSのような高い機能は要求されず、むしろ単純な書き込み/読み込みの高速化や並列処理における直線的なスケーラビリティが優先されます。このような要求を満たすデータベースとしてビッグデータ解析でよく利用されるのが「NoSQLデータベース」の1つである「KVS(キー・バリュー・ストア)」です。
「NoSQLデータベース」とは本来、データベース言語である「SQL」を使用しないデータベースの総称ですが、現在ではRDBMSとは異なる非リレーショナル型の構造を持つデータベースの総称となっています。
NoSQLデータベースの一種であるKVSは、保存したいデータ(Value)にラベル(Key)を付けて、ValueとKeyのペアで保存します。保存したデータは、Keyを指定して対応するValueを取り出すという方法を取ります。また、KVSはKeyの値に応じてデータを格納するサーバを変えることで、複数のサーバにデータを分散配置できます。その結果、短時間で大量に増加するようなデータでも、サーバ数を増やすことでサーバ群全体のパフォーマンスを向上させること(スケールアウト)で対応できます。
RDBMSと比較した場合のKVSの特徴は大きく2つに集約され、一方は短所となり、もう一方は長所となります。
1つ目の特徴は「SQLが使えない」ことです。これはRDBMSで実行されるような複雑な検索に対する大きな制約となります。具体的には、KVSではデータ検索にあたって、必ず「Row Key(RDBMSの主キーに相当)」の指定が必要となります。SQLのように、任意のカラムに対する条件指定での検索や複数のテーブルを結合することはできません。ただし、Row Keyの範囲を指定して対応するデータを順次取り出すこと、保存するデータ(Row)のデータ構造に基づいてRow Keyで指定されたRow内部での検索条件を付加することはできます。
もう1つの特徴は「分散処理に優れる」ことで、これはビッグデータ解析用途で使われるデータレイクにおいては大きな優位点となります。KVSは複数サーバにデータを分散保存するために、大量のデータをスケールアウト型で扱えます。このスケーラビリティの規模や耐障害性などが、異なるKVS間での差別化の大きな要素となっています。
それでは、代表的なKVSである「HBase」のデータ構造を見てみましょう。
HBaseは、Googleの分散データベース基盤「BigTable」を基に、OSSプロジェクトとして開発されました。HBaseでは、KeyとValueの対を「カラム」、Keyを「ラベル」、カラムの集合を「カラムファミリー」、そしてカラムファミリーの集合を「Row」と呼びます(図2)。
すべてのRowには「Row Key」が付与されており、同じ構造を持つRowの集合は「テーブル」と呼ばれます。大ざっぱに言うとHBaseのテーブルはRDBMSのテーブルに相当し、Row Keyは主キーに相当します。
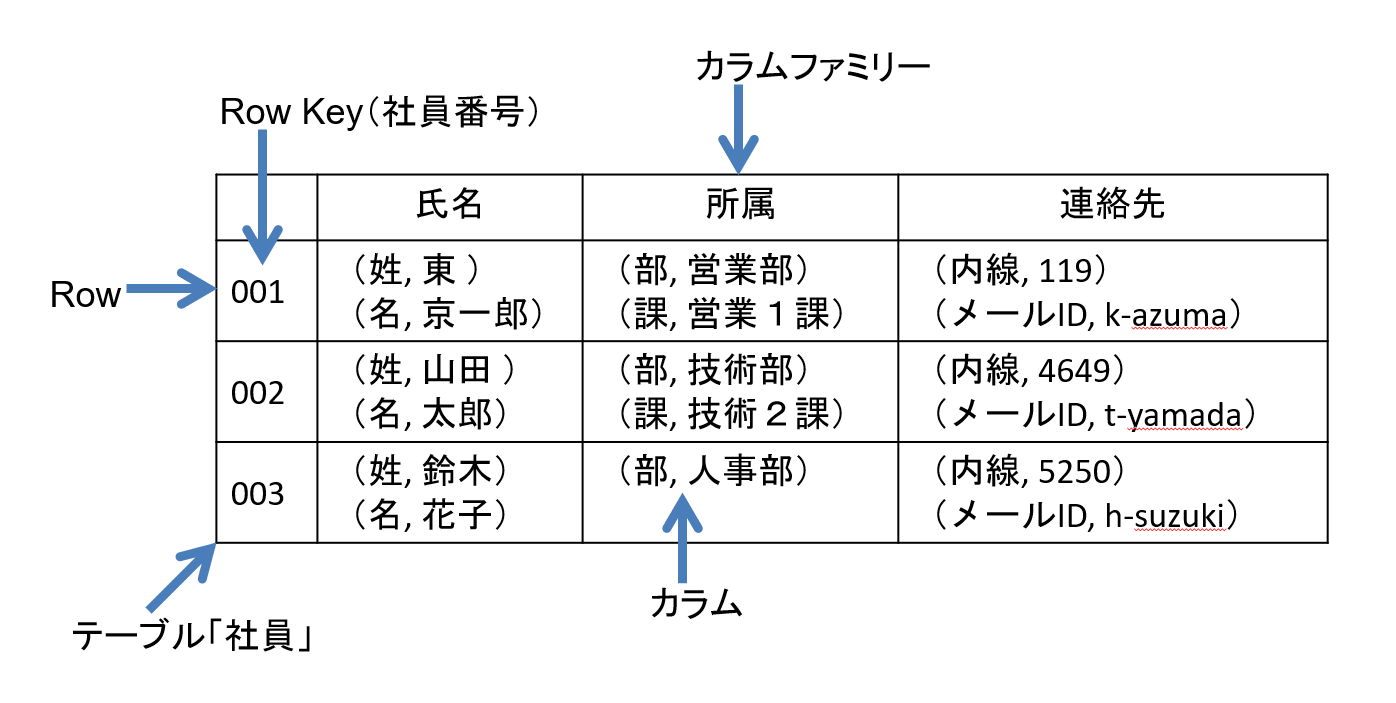
図2:HBaseのデータ構造の例【出典】ITR
社員「山田太郎」のメールアドレスを検索する場合を例に、HBase 上での検索手順を説明すると、次のようになります。
- テーブル「社員」を指定
- Row Key「002」を指定
- カラムファミリー「連絡先」を指定
- ラベル「内線」を指定
このように、分散処理に優れるKVSは、ビッグデータ解析におけるデータ格納先として最も有力な選択肢となっていますが、最近では、別の選択肢も増えてきています。
AWS、GCP、Azureといったパブリッククラウド上でビッグデータ解析を行う場合は、KVSではなくAmazon S3、Google Drive、OneDriveといったオンラインストレージ上にフラットファイルで格納するいった、より単純な方法をとるケースが増えています。
一方で、データガバナンスやセキュリティの問題から、テスト段階から実運用段階に移行するタイミングでRDBMSに移行するケースも出てきており、ひと口にデータレイクと言っても、物理的な実現方法は多様化しつつあります。
おわりに
今回は「統計的な分析」=「ビッグデータ解析」において新たに必要となるテクノロジーとして、データウェアハウスとは異なる構造を持つデータレイクと、RDBMSとは異なる種類のNoSQLデータベースについて解説しました。
次回は、引き続き新しいテクノジーとして「データカタログ」と「データ・プレパレーション・ツール」について解説します。
この記事をシェアしてください
関連記事
データ分析システムの全体像を理解する(6) 統計的な分析とデータマイニングツール
2021年5月13日 7:28
データ分析システムの全体像を理解する(4) レポーティングツールとセルフサービスBIツール
2021年3月17日 6:41
データ分析システムの全体像を理解する(1) データ分析の高度化ステップ
2020年12月17日 8:20
データマネジメントの基礎を学ぶ(4)データマネジメント高度化ステップ(後編)
2022年3月11日 6:30
データマネジメントの基礎を学ぶ(1)データマネジメントの全体像
2021年12月17日 16:31
HBase導入時の検討項目と推奨構成、および設計ノウハウ
2017年6月8日 0:15
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
