Kubeflowの構築
それでは、Kubeflowを構築していきます。本稿では、AWS(Amazon Web Service)が提供するマネージドサービスのAmazon Elastic Kubernetes Service(以下、EKS)上にKubeflowを構築していきます。
なおKubeflowは、オンプレミスのKubernetes環境はもちろんのこと、今回説明するAWSやその他の主要パブリッククラウド(Google Cloud Platform、Microsoft Azure)が提供するマネージド型のKubernetes環境や、その他クラウドサービスプロバイダーが提供する環境にも対応しています。詳しくは、Kubeflowインストールガイドを参照してください。
本稿では、EKSクラスタの構築とKubeflowのデプロイを行い、次のような構成を目指して構築を進めます。
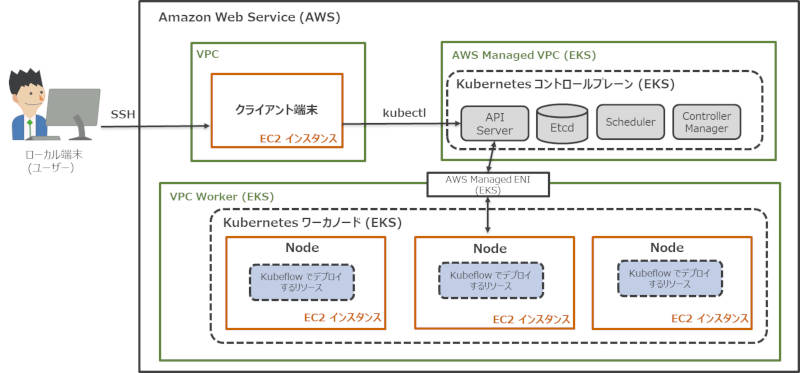
図2:本稿で構築するシステムの全体構成
構築の流れは次のとおりです。
- クライアント端末のセットアップ
- EKSクラスタの構築
- Kubeflowのデプロイ4 .Kubeflow UIへのアクセス
EKSクラスタの構築は、eksctlというコマンドラインツールを使って構築します。図2内で末尾に「(EKS)」と記載されているAWSリソースはNodeのEC2インスタンスも含め、eksctlで自動的に作成することができます。構築したEKSクラスタ上にKubeflowをデプロイすると、Kubeflowのリソースはワーカーノードにデプロイされます。最後にKubeflow UIへのアクセスするところまでの流れで構築を進めます。
前提条件
・クライアント端末
以降の構築手順はローカル端末からクライアント端末にSSHで接続して実施することを想定しています。以下のインスタンスタイプ、OSのEC2インスタンスをあらかじめ用意してください。なお、本稿ではクライアント端末として利用するEC2インスタンスの作成手順については割愛しています。
| インスタンスタイプ | t2.micro |
|---|
| OS | Amazon Linux 2 |
|---|
・IAMユーザーとアクセスキー
構築で利用するIAMユーザーには、EKSクラスタを構築するためのポリシーが付与されている必要があります。最低限必要なポリシーは、eksctlの公式ドキュメントを参照してください。
また、アクセスキーおよびシークレットアクセスキーは、アクセスキーの管理を参照し、あらかじめ用意してください。
・各種バージョン
クライアント端末に導入するツールのバージョン
| kubectl | 1.18.9 |
|---|
| eksctl | 0.69.0 |
|---|
構築するKubernetes、Kubeflowのバージョン
| Kubernetes(AWS EKS) | 1.18 |
|---|
| Kubeflow | 1.2.0 |
|---|
1:クライアント端末のセットアップ
1-1:kubectlのインストール
・kubectlをダウンロード
・実行権限を付与
・コマンドにPATHを通すため、/usr/local/binに移動
1 | sudo mv ./kubectl /usr/local/bin |
・kubectlのインストールが成功したことを確認
コマンドを実行し、以下のように結果が表示されることを確認
1 | kubectl version --short --client |
2 | Client Version: v1.18.9-eks-d1db3c |
1-2:eksctlのインストール
・eksctlをダウンロード
・コマンドにPATHを通すため、/usr/local/binに移動
1 | sudo mv /tmp/eksctl /usr/local/bin |
・eksctlのインストールが成功したことを確認
コマンドを実行し、以下のように結果が表示されることを確認
1-3:awscliの初期設定
・あらかじめ用意した「アクセスキー」、「シークレットアクセスキー」と「リージョン」、「出力フォーマット」を設定
2 | AWS Access Key ID [None]: <アクセスキー> |
3 | AWS Secret Access Key [None]: <シークレットアクセスキー> |
4 | Default region name [None]: ap-northeast-1 |
5 | Default output format [None]: json |
今回は東京リージョン(ap-northeast-1)を選択していますが、その他多くのリージョンに対応しています。詳しくはAWSグローバルインフラストラクチャのリージョン表を参照してください。
なお、以降の手順でリージョンを指定する際には、ここで設定したリージョンを用いてください。
2:EKSクラスタの構築
2-1:環境変数の設定
1 | export AWS_CLUSTER_NAME=kubeflow-example |
2 | export AWS_REGION=ap-northeast-1 |
4 | export EC2_INSTANCE_TYPE=m5.xlarge |
AWS_CLUSTER_NAMEは構築するEKSクラスタ名を設定します。EKSクラスタ名は任意の名前で問題ありません。
AWS_REGIONはEKSクラスタを構築するAWSリージョンを設定します。前述のAWS認証情報の設定で選択したリージョンと同一リージョンを設定します。
K8S_VERSIONは構築するKubernetesのバージョンを設定します。
EC2_INSTANCE_TYPEにはワーカーノードのインスタンスタイプを設定します。今回はm5.xlargeを設定しますが、要件に合わせて設定してください。
2-2:eksctlで使用するクラスタ構成ファイルの作成
01 | cat << EOF > cluster.yaml |
03 | apiVersion: eksctl.io/v1alpha5 |
07 | name: ${AWS_CLUSTER_NAME} |
08 | version: "${K8S_VERSION}" |
16 | instanceType: ${EC2_INSTANCE_TYPE} |
「desiredCapacity」で指定する値が、Kubernetesワーカーノードのノード数です。ここでは、3台のワーカーノードで構成しますが、要件に合わせて設定してください。
「minSize」、「maxSize」はワーカーノードの最小ノード数と最大ノード数を指定します。ワーカーノード数はこの範囲内で変更が可能となります。
2-3:Kubernetesクラスタの作成
1 | eksctl create cluster -f cluster.yaml |
コマンドの実行完了に20分程度かかるので、プロンプトが戻ってくるまで待ちます。
2-4:Kubernetesクラスタの状態を確認
コマンドを実行し、以下のように結果が表示されることを確認
2 | NAME STATUS ROLES AGE VERSION |
3 | ip-192-168-20-217.ec2.internal Ready <none> 49m v1.18.20-eks-c9f1ce |
4 | ip-192-168-42-115.ec2.internal Ready <none> 50m v1.18.20-eks-c9f1ce |
5 | ip-192-168-46-182.ec2.internal Ready <none> 49m v1.18.20-eks-c9f1ce |
3:Kubeflowのデプロイ
3-1:kfctlのインストール
・Kubeflowリリースページからkfctl v1.2.0をダウンロード
・解凍し、実行権限を付与
1 | tar -xvf kfctl_v1.2.0.tar.gz |
・コマンドにPATHを通すため、/usr/local/bin に移動
1 | sudo mv ./kfctl /usr/local/bin |
3-2:kfctl構成ファイルのダウンロード
Kubeflowのマニフェストリポジトリより、Kubeflow v1.2.0の構成ファイルをダウンロードします。
2 | mkdir ${AWS_CLUSTER_NAME} && cd ${AWS_CLUSTER_NAME} |
3 | wget -O kfctl_k8s_istio.yaml $CONFIG_URI |
3-3:Kubeflowのデプロイ
1 | kfctl apply -V -f kfctl_k8s_istio.yaml |
コマンドの実行完了に10分程度かかるので、プロンプトが戻ってくるまで待ちます。
3-4:ログ抑止のための設定変更
Kubeflow v1.2.0では、「application-controller」のログが大量に蓄積されディスク容量を消費する事象が報告されています(参考:https://github.com/kubeflow/kubeflow/issues/5514#issuecomment-782227059)。
そこで、以下の設定を行い、ログの出力を抑止します。
01 | kubectl edit sts application-controller-stateful-set -n kubeflow |
16 | echo "logs are hidden because volume is too excessive" && |
17 | /root/manager 2> /dev/null |
3-5:mpi-operator Podのエラー解消
本連載では取り上げないコンポーネントのため影響はありませんが、「mpi-operator」Podが正常に起動しない事象が発生するため、修正を行います。
以下は、修正箇所の差分表示となっています(参考:https://github.com/kubeflow/manifests/pull/2019/files#diff-aa00c61222b1e4cc15752f50f7ede8a2b6970646d4603d56fd0de9dc857fee47)。
01 | kubectl edit -n kubeflow deployment/mpi-operator |
06 | + command: ["/opt/mpi-operator.v1"] |
11 | - --kubectl-delivery-image |
12 | - $(kubectl-delivery-image) |
13 | image: mpioperator/mpi-operator:latest |
14 | imagePullPolicy: Always |
16 | serviceAccountName: mpi-operator |
3-6. KubeflowのPodがすべて起動していることを確認
1 | kubectl -n kubeflow get pods |
すべてのPodが「Running」状態になっていることを確認します。
4:Kubeflow UIへのアクセス
4-1:kubectlのポートフォワーディングコマンドを実行
以下のコマンドでIstioのIngress Gatewayにポートフォワーディングします。
1 | kubectl port-forward -n istio-system svc/istio-ingressgateway 31380:80 |
ここでは、クライアント端末のlocalhost:31380への接続をKubernetes側のsvc/istio-ingressgateway:80に転送する設定を行います。
4-2:ローカル端末のポートフォワーディングを設定
ローカル端末からKubeflow UIへ接続するためには、ローカル端末側においてもポートフォワーディングの設定が必要です。
ローカル端末のSSHクライアントのポートフォワーディング設定で、ローカル端末のlocalhost:31380への接続をクライアント端末側のlocalhost:31380に転送する設定を行います。
例えばTeraTermにて設定する場合は以下のように設定します。

図3:ローカル端末(TeraTerm)でのポートフォワーディングの設定
4-3:Kubeflow UIへのアクセス
ブラウザを開き「http://localhost:31380」にアクセスします。以下のような画面が表示されればアクセス成功です。

図4:Kubeflow UIへのアクセス
次に、「Start Setup」をクリックします。
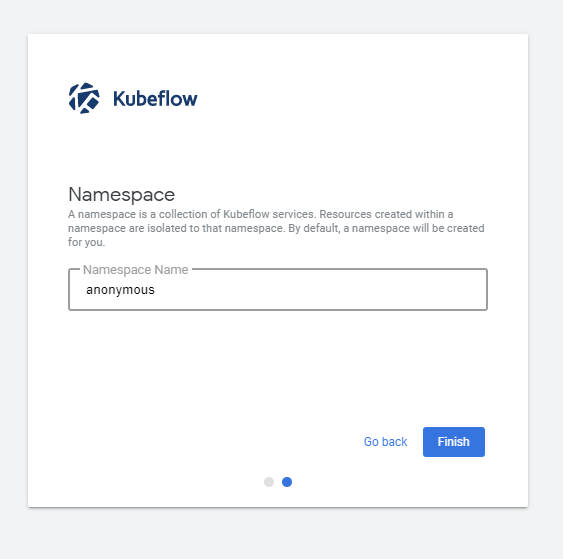
図5:Namespaceの設定
Namespaceの設定は、デフォルトの「anonymous」のままで「Finish」をクリックします。
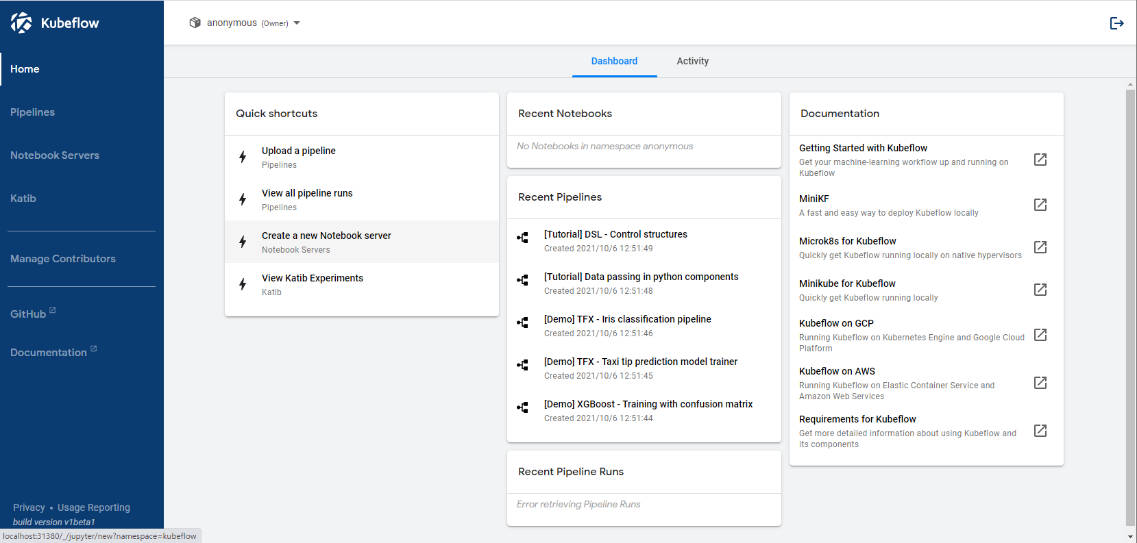
図6:環境構築完了
Kubeflow UIが表示されれば、構築完了です。
(Tips)EKSクラスタの運用について
・ワーカーノード数の変更
EKSクラスタ構築後にワーカーノードのリソース拡張や縮小が必要になった場合は、以下の手順でワーカーノード数の変更が可能です。
1 | eksctl scale nodegroup --name=kubeflow-mng --cluster=kubeflow-example -N <変更したいノード数> |
ノード数は最小サイズと最大サイズが設定されているので、その範囲内で選択して下さい。ノードの情報は以下のコマンドで確認可能です。
1 | eksctl get nodegroup --name=kubeflow-mng --cluster=kubeflow-example |
・EKSクラスタの削除
EKSやKubernetesワーカーノードして利用するEC2は有償サービスとなるため、利用しない場合は以下の手順でシャットダウンすることをお勧めします。
1 | eksctl delete cluster --name kubeflow-example |
おわりに
本稿では、Kubeflowの内部構造の概要とAmazon EKSを用いたKubernetesクラスタの構築からKubeflowのデプロイ、Kubeflow UIへのアクセス手順について解説しました。
次回は、Kubeflowのコンポーネントの一つであるNotebook Serversを利用して、ノートブックサーバーのセットアップからJupyter notebookを使ったデータ分析について解説していきます。













