KFServingで機械学習モデルをサービング
連載の8回目となる今回は、学習済みモデルのデプロイの手順とその運用で利用するKubeflowの機能やコンポーネントについて解説します。
2022年4月27日 6:00
はじめに
ここまで、機械学習モデルの開発におけるパイプラインを中心に、データ取り込みから学習済みモデルを出力するまでのステップとパイプラインを構築する手順を解説してきました。そして、前回はパイプラインをKubeflow Pipelinesにデプロイし実行する手順やパイプラインでモデルを作成する際に役に立つ機能を解説しました。これでモデル作成の各ステップを自動化し反復的にモデルを作成する仕組みを構築できるようになりました。
しかしながら、作成したモデルは実用化されて初めてその効果を発揮します。実用化するには学習済みモデルを商用システムへ導入(デプロイ)し、ユーザーや他システムから使えるようにする必要があります。また、安定して使えるようにその運用監視についても考慮が必要になるでしょう。今回は、機械学習モデルの運用について焦点を当て、モデルをデプロイする方法や運用監視で使う周辺コンポーネントの利用方法について解説していきます。
機械学習モデルの運用
まず、本連載の第1回で解説した機械学習のワークフローにおける機械学習モデルの運用の位置づけと構成するステップを振り返ってみます。
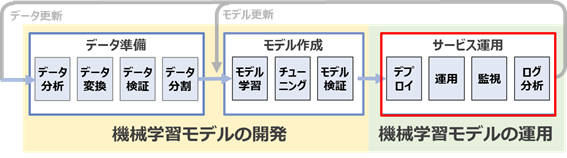
図1-1:機械学習ワークフローとステップ
図1-1に示すとおり、機械学習モデルの運用は機械学習モデルの開発の後続のプロセスとして位置付けられ、モデルのデプロイのステップから始まります。モデルをデプロイする一般的な方法は、予測結果を返却するインターフェース(REST API等)を実装し、推論サービスとしてユーザーに公開する形が多いでしょう。その場合、運用側の主なタスクとしては、推論サービスの構築やモデルのデプロイ、モデルのバージョン切り替え、稼働状態の監視、リクエストとレスポンス(推論結果)のログ監視などが挙げられます。これらのタスクは機械学習モデルの開発に求められる専門領域とは少し外れています。今日の分業制の考え方の下では、これらはシステム開発者や運用者のタスクと考えるのは自然なことだと言えるでしょう。そのため、機械学習モデルの開発者が作成したモデルの運用はシステム開発者や運用者が引き継いで進めなくてはならず、その役割間のコミュニケーションや分断コストが発生します。具体的には次のような課題が挙げられます。
- モデルと推論サービスの密結合:機械学習モデルは、推論サービス側のアプリケーションの要件と互換性がない言語やフレームワークを使って作成することがあります。モデルを作成する際、そのタスクに合ったフレームワークを選択することや精度を優先することが多いためです。その場合、推論サービス側で同じ言語やフレームワークを使った再実装が必要になったり、インターフェースの仕様調整が必要になったりすることがあります。
- デプロイプロセスの制約:機械学習モデルの開発者は、新しく作成したモデルと運用中のモデルを比較しデプロイの影響を評価したいと考えるケースがあります。これは手元で実施したモデルの検証結果には問題がなくても、商用環境で問題が見つかることが少なくないからです。異なるバージョンのモデルを共存させるには、エンドポイントの分岐や構造的に同じに保つために運用側で必要以上の労力を要することがあります。
- デプロイまでの所要時間:精度が高いモデルを作成したとしてもすぐにデプロイしないと陳腐化してしまいます。それは推論時の入力データが時間の経過に伴って変化すると、モデルの予測精度が低下する可能性があるからです。そのため、モデルの開発者は速やかにデプロイすることを望みますが、上記で挙げた点や、毎回手動でデプロイを行っている場合、多くの時間を要してしまいます。ようやくデプロイできたとしても、そのモデルが役に立たなくなっている可能性があります。
- 推論サービスの継続的な監視:推論サービスの監視には、一般的なシステムの監視に加え「モデルが問題なく動いているか」を監視する必要があります。代表的なものとしては、モデルの精度に関する指標の監視となりますが、他にもさまざまな指標があります。これらの指標はモデル開発者がログを分析して確立することが多いですが、その元となるログの収集などはシステム運用者が対応します。そのため新たな推論サービスが増えるたびに、その都度ログ収集の設定や監視の仕組みを構築するのに大きなコストがかかってしまいます。
上記のような機械学習モデルの開発と運用におけるギャップを埋めるコンポーネントとしてKFServingがあります。
KFServingとは
KFServingは、Kubernetes上に機械学習モデルの推論サービスを構築するためのコンポーネントです。Kubeflowの一式として標準で導入されるため、個別でインストールせずに利用できます(※執筆時点でKFServingはKServeという名前に変わり、Kubeflowの一部としてだけでなく、推論サービスを構築するための独立したプラットフォームとして利用が可能になっています)。KFServingを利用する利点としては次が挙げられます。
機械学習フレームワークに非依存で拡張性と汎用性の高い推論サービスを構築できる
KFServingは主要な機械学習フレームワークに対応したモデルサーバーを搭載しているため、推論サービスを構築する際にその言語やフレームワークを意識する必要はありません。主に対応している機械学習フレームワークは次のとおりです。
さらに、推論リクエストに対する変換処理や後処理など推論時における典型的なワークフローが標準化されており、必要に応じて個別に処理を追加できます。これにより拡張性と汎用性の高い推論サービスが構築可能になっています。
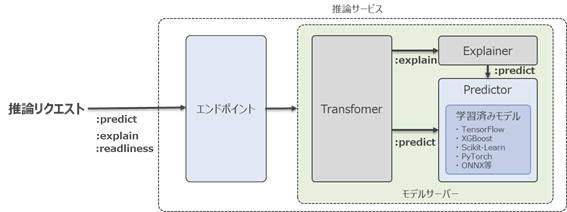
図2-1:推論サービスの処理フローとモデルサーバーのコンポーネント
図2-1に示すモデルサーバーのコンポーネントは次のとおりです。
- Transformer:推論リクエストに対する前処理、予測結果に対する後処理などを行うデータ変換処理を行います。本稿では詳しく解説しませんが、処理を追加する際はTransformerのコードテンプレート(基底クラス)を元に処理を記述します。詳細はKFServingのドキュメントを参照してください。
- Predictor:学習済みのモデルを読み込み、推論処理を行います。モデルサーバーの必須コンポーネントとなっています。
- Explainer:モデルの推論結果に対して、その推論結果に「なぜその推論結果になったのか」といった説明を付与します。詳しくは次回紹介する予定です。
なお、これらのモデルサーバーのコンポーネントをコンテナイメージとしてパッケージングしデプロイします。また、推論サービスのインターフェースは統一された仕様で公開できるため、例えばデプロイするモデルの機械学習フレームワークが複数種類あったとしても同じ形式で推論リクエストを送ることができます。
| API | メソッド | Path | 説明 |
|---|---|---|---|
| Readiness | GET | /v1/models/ | モデルサーバーの状態を返却する |
| Predict | POST | /v1/models/:predict | 推論結果を返却する |
| Explain | POST | /v1/models/:explain | 推論結果とその推論結果に対する説明を付与して返却する |
シンプルなデプロイプロセスで安全にモデルをデプロイできる
KFServingを使って機械学習モデルをデプロイするには、InferenceServiceというカスタムリソースをKubernetes上に作成する必要がありますが、この一つの作業だけで、推論サーバーのインターフェースやモデルサーバー、またモデルサーバーに接続するための通信制御の設定など自動的に構成できます。InferenceServiceを作成すると、主に次のようなリソースが自動的に作成されます。
- Revision:デプロイするモデルサーバーのコンテナイメージや環境変数などの設定情報のスナップショットとなっていて、その履歴を保持します。
- Configuration:Revisionを作成するためのテンプレートとなっていて、これを元にRevisionが作成されます。DefaultとCanaryの二つのConfigurationが作成されます。
- Route:推論リクエストをどのRevisionに転送するか設定します。例えば、90%をDefaultのRevision Nに10%をCanaryのRevision 1になどの設定ができます。
それぞれのリソースの関係を示したものが図2-2です。
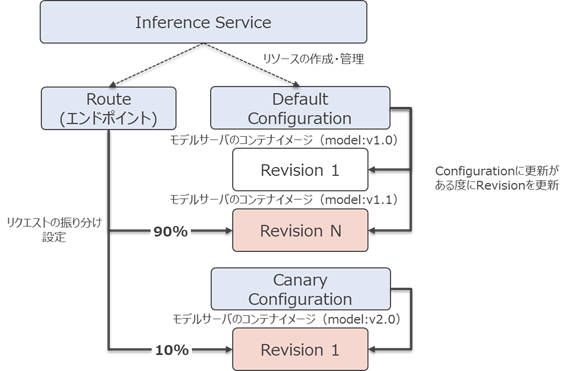
図2-2: Inference Serviceで作成されるリソース
これらのリソースにより、新旧バージョンのモデルを共存させ新しいバージョンのモデルへのリクエストの振り分けを段階的に増やしていく「カナリアリリース」というデプロイ方法を実現できます。これは前述した「新しく作成したモデルと運用中のモデルを比較しデプロイの影響を評価したい」といったユースケースに対応でき、新しいバージョンのモデルに問題が見つかればすぐに切り戻しできます。
一見、複雑そうに見える構成ですが、実際にKFServingを使ってデプロイする際はInferenceServiceの定義のみ意識すればよく、デプロイプロセスはシンプルになります。また、パイプラインとしてデプロイプロセスを自動化することもできます。詳しくは次に解説します。
Kubeflow Pipelinesでデプロイプロセスを自動化できる
KFServingは、Kubeflowの一つのコンポーネントとしてKubeflow Pipelinesに統合されているため、デプロイプロセスを容易にパイプライン化し自動的に実行できるようになります。具体的には、Kubeflow PipelinesのライブラリにInferenceServiceのテンプレートが組み込まれているため、それを利用してモデルデプロイ用のパイプラインの定義ファイルを生成することができます。手順やコード例は後述します。
監視とログ出力も手間なく利用できる
KFServingには、推論サービスの性能監視やリクエスト・レスポンスなどのログを出力する仕組みが標準で備わっています。
・推論サービスの性能監視
PrometheusというOSSの監視ツールがKFServingのコンポーネントの一つとして標準で導入されていて連携できるようになっているため、容易に性能に関する指標(メトリクス)が取得できます。取得できる主なメトリクスは次のとおりです。
| メトリック名 | 説明 | 単位(メトリクスタイプ) |
|---|---|---|
| request_count | リクエスト数 | 回数(カウンター) |
| request_latencies | 応答時間 | ミリ秒(ヒストグラム) |
・ログ出力
Inference LoggerというKFServingが提供するログを出力するための仕組みを導入することで推論サーバーへのリクエストの内容やレスポンスの推論結果などのログを出力できます。内部的にはKFServingのベースとなっているKnativeのMessage Dumperというコンポーネントを使って実現しています。
また、GrafanaというOSSの可視化ツールを使うことで、メトリクスやログを可視化できます。可視化した結果をダッシュボードとして共有することも可能です。
他にもKFServingは自動スケールに対応しており、負荷状況に応じてモデルサーバーの並列度を上げて処理したり、一定期間リクエストが来ない場合には、リソースを使わない状態(ゼロスケール)にしたりすることで効率的にKubernetes上のリソースを活用することができます。
それでは、実際にKFServingを使って機械学習モデルをデプロイしてみましょう。
KFServingを使った機械学習モデルのデプロイ(ハンズオン)
KFServingを使った機械学習モデルのデプロイ手順を解説します。本稿では、機械学習モデルのデプロイプロセスをパイプライン化していきます。解説の流れは次のとおりです。
- 事前準備
パイプライン化にはKubeflow PipelinesのPythonライブラリを利用します。Jupyter notebookを使ってコードを実行しながらパイプラインの構築を進めていくため、その環境となるノートブックを作成します。 - Kubernetesクラスタに環境設定を追加する
モデルサーバーから学習済みの機械学習モデルをダウンロードできるようにするため、KubernetesクラスタにMinIOの接続情報等を設定します。なお、学習済みモデルはMinIOに格納されていることを前提としています(本稿では、前回の解説でMinIOにアップロードした学習済みモデルを利用します)。 - 機械学習モデルのデプロイを行うパイプラインを構築する
Kubeflow Pipelinesのライブラリを使って機械学習モデルのデプロイを行うパイプラインの定義ファイル(yamlファイル)を作成し、Kubeflow Pipelinesにデプロイします。 - パイプラインを実行し機械学習モデルをデプロイする
機械学習モデルのデプロイを行うパイプラインを実行し、推論サービスを構築します。 - 推論結果を取得する
推論サービスに対し推論リクエストを送り推論結果を取得します。
事前準備
まず、以下の手順で新しいノートブックを作成します。
- 「Kubeflow UI」にアクセス
- 「Notebook Servers」へ画面遷移し、Notebook Server一覧を表示
- 作成済みの「example-notebook」に接続
- Python 3 のノートブックを作成
以降、記載しているコード例はノートブックのセルに入力し実行していきます。
次に、ノートブック上でyamlファイルを作成するので、出力先のディレクトリを新規作成します。
import os
yaml_dir = os.path.join(os.getcwd(), 'yaml')
os.makedirs(yaml_dir, exist_ok=True)
Kubernetesクラスタに環境設定を追加する
モデルが格納されているMinIOにアクセスするための認証情報を保持するSecretと、InferenceServiceとSecretを紐づけるためのServiceAccountを作成します。まず、出力するyamlファイルのパスを定義します。
minio_secret_yaml_file = os.path.join(yaml_dir, 'minio_secret.yaml')
minio_sa_yaml_file = os.path.join(yaml_dir, 'minio_service_account.yaml')
次に、MinIOの接続情報を保持するSecretを作成します。AWS_ACCESS_KEY_ID、AWS_SECRET_ACCESS_KEYはBase64でエンコードした文字列を指定します。
%%writefile {minio_secret_yaml_file}
apiVersion: v1
kind: Secret
metadata:
name: kubeflow-minio-secret
annotations:
serving.kubeflow.org/s3-endpoint: minio-service.kubeflow.svc.cluster.local:9000
serving.kubeflow.org/s3-usehttps: "0"
type: Opaque
data:
AWS_ACCESS_KEY_ID: bWluaW8=
AWS_SECRET_ACCESS_KEY: bWluaW8xMjM=
続いて、ServiceAccountを作成します。
%%writefile {minio_sa_yaml_file}
apiVersion: v1
kind: ServiceAccount
metadata:
name: kubeflow-minio-sa
secrets:
- name: kubeflow-minio-secret
作成したyamlファイルを使用して、リソースを適用します。
!kubectl apply -f {minio_secret_yaml_file}
!kubectl apply -f {minio_sa_yaml_file}
機械学習モデルのデプロイを行うパイプラインを構築する
デプロイプロセスのパイプライン化にはKubeflow PipelinesのPythonライブラリを利用します。このライブラリを使用することで、Python関数を実装するだけでパイプラインを構築することができます。
まず、Kubeflow Pipelines ライブラリであるkfpをインポートします。
import kfp.dsl as dsl
from kfp import compiler
from kfp import components
次に、KFServingコンポーネント定義を読み込みます。このコンポーネント定義に従ってPython関数を実装するだけで、デプロイプロセスのパイプラインの定義が生成できます。
url = 'https://raw.githubusercontent.com/kubeflow/pipelines/
65bed9b6d1d676ef2d541a970d3edc0aee12400d/ \
components/kubeflow/kfserving/component.yaml' \
kfserving_op = components.load_component_from_url(url)
続いて、InferenceServiceの定義をyaml形式の文字列で設定します。このとき、一部の設定値をパイプライン実行時のパラメータとするために「{}」(プレースホルダー)としておき、後続の処理で置換できるようにしておきます。
isvc_yaml = '''
apiVersion: serving.kubeflow.org/v1alpha2
kind: InferenceService
metadata:
annotations:
sidecar.istio.io/inject: "false"
prometheus.io/scrape: "true"
name: {}
spec:
default:
predictor:
minReplicas: 1
serviceAccountName: kubeflow-minio-sa
tensorflow:
runtimeVersion: 2.5.1
storageUri: {}
resources:
requests:
cpu: 0.1
memory: 1Gi
limits:
cpu: 1
memory: 1Gi
logger:
mode: all
url: http://message-dumper.anonymous.svc.cluster.local
'''
上記コード例でInferenceServiceに設定した内容は次のとおりです。
- default:Defaultの推論リクエストを受け付ける推論サービスの設定
- predictor:モデルサーバーの設定
- minReplicas:モデルサーバーのレプリカの最小数。この設定を0にすると、トラフィックがないときに自動的にゼロスケールとなります
- serviceAccountName:先ほど作成したServiceAccountを設定
- tensorflow:学習済みモデルの機械学習フレームワーク。本稿の例ではTensorFlowを使用したため、tensorflowを指定します
- runtimeVersion:学習済みモデルを作成した際の機械学習フレームワークのバージョン。ここでは TensorFlowのバージョン 2.5.1 を指定しています
- storageUri:学習済みのモデルが格納されているストレージのパス
- resources:モデルサーバーコンテナのリソース設定。
- logger:推論リクエストや推論結果のレスポンスのロギングをする Inference Loggerの設定。詳細は「推論サービスの監視とログ出力」で説明します
続いて、パイプラインで実行するステップをPythonの関数として定義します。この関数の引数としている変数がパイプラインパラメータとなります。また、パイプライン実行時のキャッシュ機能がデフォルトで有効になっていますが、キャッシュ機能を無効化するための設定もします。設定の内容についてはKubeflowのドキュメントを参照してください。
@dsl.pipeline(
name='census_income_kfserving',
description='A pipeline for KFServing.'
)
def kfserving_pipeline(model_name: str='census-income',
default_model_uri: str='s3://census-income/serving_model'):
kfserving_op(
action='apply',
model_name=model_name,
namespace='anonymous',
inferenceservice_yaml=isvc_yaml.format(model_name, default_model_uri)
).execution_options.caching_strategy.max_cache_staleness = "P0D"
パイプラインの定義をyamlファイルとして出力します。ここで出力したyamlファイルを使用して、Kubeflow Pipelines上にパイプラインを構築します。
kfserving_pipeline_yaml_file = os.path.join(yaml_dir, 'kfserving_pipeline.yaml')
kfp.compiler.Compiler().compile(kfserving_pipeline, kfserving_pipeline_yaml_file)
出力したyamlファイルをダウンロードします。出力されたファイルを選択して「Download」ボタンをクリックします。

図3-1:出力したパイプライン構築ファイルのダウンロード
ダウンロードしたファイルをKubeflow Pipelinesにアップロードし、パイプラインを作成します。前回解説した「Kubeflow Pipelinesにデプロイ」と同じ手順で実施します。

図3-2:パイプラインのグラフ表示
パイプラインの作成が完了すると、図3-2で示すように、InferenceServiceを作成するステップだけのパイプラインが作成されます。
続いて、パイプラインを実行していきます。パイプライン実行時の設定画面では、パイプライン名やパイプラインパラメータ(「Run parameters」)の設定ができます。「Run parameters」の各項目には次の設定を行います。
- model_name:任意の推論サービス名を設定
- default_model_uri:学習済みモデルが格納されているストレージのパス
必要な項目はすでに入力されているので、内容を確認したらページ下部の「Start」ボタンをクリックしパイプラインを実行します。
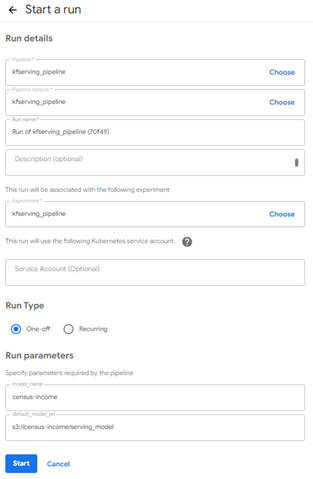
図3-3:パイプラインの設定と実行画面
・パイプラインの実行状況を確認
パイプラインを実行すると、Experiment一覧画面に自動的に遷移します。Experiment一覧画面では、該当の「Run name」をクリックすることで、パイプライン実行状況やコンポーネントごとの状態を確認できます。
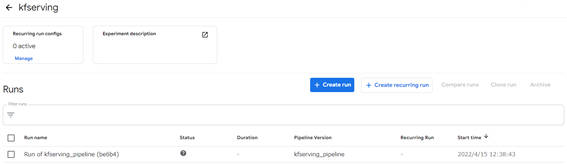
図3-4:Experiment 一覧画面
パイプライン実行中の画面です。Logsを開くとInferenceServiceの作成状況が表示されます。
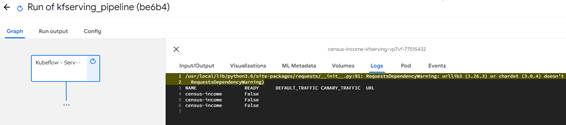
図3-5:パイプライン実行中の画面
Logsにて表示されるInferenceService作成状況にてREADYが「True」となり、パイプラインが正常終了したことを確認します。
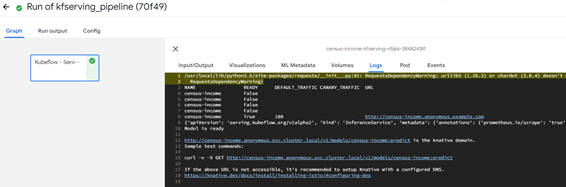
図3-6:パイプラインの実行結果画面
ここまで完了すると機械学習モデルがデプロイされ、推論サービスが利用できるようになります。
推論結果を取得する
先ほど構築した推論サービスに対して推論リクエストを送信することで、推論結果を取得します。先ほどまで使用していたノートブックから推論リクエストを送信してみます。
まず、リクエストを送信するために必要なライブラリをインポートします。
import tensorflow as tf
import base64
import json
import requests
次に、先ほど「Run parametes」で設定した推論サービス名と、リクエスト送信時に付与するヘッダーを定義します。
inferenceservice_name = "census-income"
headers = {"content-type": "application/json", "Host": "census-income.anonymous.example.com"}
リクエストにて送信するデータを作成します。ここでは疎通確認を兼ねたテストとして、モデル学習で利用したデータセット(TFRecordに変換済みのデータ)から最初のレコードを取得してリクエストを送信します。
リクエストのボディーに設定するデータはBase64でエンコードします。
tfrecord_data_root = os.path.join(os.getcwd(), 'tfrecord_data', 'span-1', 'v1')
tfrecord_filenames = [os.path.join(tfrecord_data_root, name)
for name in os.listdir(tfrecord_data_root)]
dataset = tf.data.TFRecordDataset(tfrecord_filenames)
examples = []
for tfrecord in dataset.take(1):
serialized_example = tfrecord.numpy()
example = tf.train.Example()
example.ParseFromString(serialized_example)
examples.append(base64.b64encode(example.SerializeToString()).decode('utf-8'))
instances = {"instances": [i for i in [{"b64": e} for e in examples]]}
data = json.dumps(instances)
リクエストを送信します。
response = requests.post(
"http://istio-ingressgateway.istio-system/v1/models/"
"%s:predict" % inferenceservice_name, data=data,
headers=headers)
返却されたデータを確認します。リクエストで送信したデータに対する推論結果が返ってくればInferenceServiceが正しく稼働して、推論サービスが利用できたことが確認できます。下記の結果では予測結果(predictions)として0.0470…(年収が5万ドル以上の確率は約4%)という結果が得られています。
response.json()

図3-7:サービング実行結果
この記事をシェアしてください
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
