Kubeflowを構築する
連載の2回目となる今回は、Kubeflowの内部構造の概要と構築手順について解説します。
2021年10月27日 6:00
はじめに
前回は、Kubeflow登場の背景とその概要、機械学習パイプラインを作成するためのフレームワークであるTensorFlow Extended(TFX)の概要を解説しました。
今回は、最初にKubeflowを構築し利用する上で理解しておくべき内部構造の概要を解説し、次に構築手順と設定について、実際に構築を行いながら確認していきます。
Kubeflowのアーキテクチャ概要
Kubeflowの構築を始める前に、Kubeflowのアーキテクチャの概要を解説します。構築時において各コンポーネントの動作を細かく意識する必要はありませんが、設定変更やトラブルシューティングなどを行う上で役に立ちます。
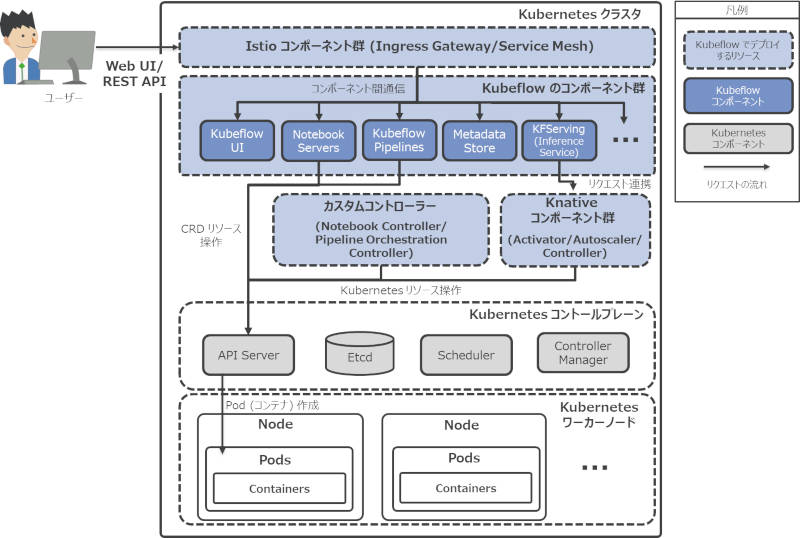
図1:Kubeflowのアーキテクチャ概要
図1はKubeflowおよびKubernetesの主なコンポーネントとリクエストフローの概要図です。図に示すように、Kubeflowの各コンポーネントはKubernetes上で連携し合うことで、機械学習プラットフォームとしての機能を実現しています。
注釈
図1では、Kubeflowのアーキテクチャの概要を説明するため、各コンポーネントを簡略化して図示しています。実際にKubeflowによってデプロイされるコンポーネントは、バックエンドコンポーネントや本連載では取り上げないJob管理コンポーネントなどを含め、他にも多く存在します。
また本稿では、KubernetesコンポーネントのリクエストフローやDeployment、Pod、Service、Custom Resource Definitions(以下、CRD)等のKubernetesリソースの説明は省略しています。必要に応じて、公式ドキュメント等を参照してください。
KubeflowにおけるIstioの役割
Istioはマイクロサービス間の相互の通信を管理し、サービスメッシュを実現するOSSプロダクトです。KubeflowにおけるIstioの主な役割は次の2つです。
・ゲートウェイ
Kubeflowへの入り口の役割はIstioのIngress Gatewayというコンポーネントが担います。Kubernetesクラスタ外からのリクエストを受け付け、それに応じたコンポーネントに連携します。ユーザーがKubeflow UI(WebUI)にアクセスする際や、機械学習モデルの推論インターフェース(REST API)から推論結果を取得する場合など、Kubeflowに対するリクエストはすべてIngress Gatewayを介し、各コンポーネントへ連携されます。
・コンポーネント間の通信管理
図1に示すとおり、Kubeflowのコンポーネント群はIstioが構築するサービスメッシュ内で相互に連携しています。Istioはコンポーネント間の通信を管理し、アクセス制御やルーティングを行います。また、Istioが果たす重要な役割の1つとして、サービスメッシュ内に作成された新たなエンドポイントを自動的に検出し管理できる点が挙げられます。例えば、ユーザーが新たに作成したノートブックサーバーに接続して利用することもIstioなしでは実現できません。
CRDとカスタムコントローラー
Kubeflowが機械学習プラットフォームとしての機能を実現するための重要な概念として、CRDとカスタムコントローラーがあります。Notebook ServersやKubeflow PipelineなどのKubeflowコンポーネントの裏側は、CRDとカスタムコントローラーが支えています。その例として、次のフローで説明します。
・ノートブックサーバー作成フロー
- Notebook Serversの管理画面よりノートブックサーバーを作成すると、そのバックエンドコンポーネントはAPI Serverを介して、Notebook CRDオブジェクトを作成します
- Notebook CRDオブジェクトが作成されると、必要なKubernetesリソース(Deployment、Serviceなど)はNotebook ControllerによりAPI Serverを介して作成され、Node上にノートブックサーバーのPodを起動します
・機械学習パイプライン実行フロー
- Kubeflow Pipelineの管理画面からパイプラインを実行すると、そのバックエンドコンポーネントはAPI Serverを介してパイプラインを実行するために必要なCRDオブジェクトを作成します
- CRDオブジェクトが作成されると、Pipeline Orchestration Controllerは定義されたパイプライン内の一連のステップを完了するためのPodを作成し、処理を実行します。※デフォルトではArgo Workflowsのワークフローエンジンが利用されます
KFServingとKnative
KFServingはKnativeというコンポーネントに基づき構築されています。KnativeはKubernetes上でのサーバーレスワークロードを管理するOSSのプロダクトです。なお、KnativeもIstioのサービスメッシュを利用します。KFServingでは、Knativeのコンポーネント群と連携することで、Inference ServiceというCRDオブジェクトを作成するだけで、機械学習モデルのサービングが行えます。なお、KFServingの詳しいアーキテクチャについては、本連載の機械学習モデルのサービングを紹介する回で解説する予定です。
ここまで、Kubeflowのアーキテクチャ概要について解説しました。これだけ多くのコンポーネントで構成されているKubeflowの構築はとても大変な作業になるのではという印象を持たれた方も多いかと思います。Kubeflowは以下に示す2つのデプロイ方法をサポートしておりますが、幸いなことにそのいずれ方法でも、容易に構築が可能となっています。
・パッケージ化されたディストリビューションを利用してデプロイする方法
パブリッククラウドのプラットフォームやサードパーティベンダにより開発されているパッケージ化されたディストリビューションで構築する方法です。セットアップスクリプトを実行することで自動的にKubeflowを構築できます
・Kubeflowのコンポーネントを個別にデプロイする方法
Notebook ServersやKubeflow PipelinesといったKubeflowのコンポーネントを個別に構築する方法です。定義済みマニフェスト(構成ファイル)を手動で適用することで構築できます。
本稿では、パッケージ化されたディストリビューションを利用してKubeflowを構築します。
この記事をシェアしてください
関連記事
バックナンバー
この記事の筆者


筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
