機械学習モデルの継続的な改善に向けて
連載の最終回となる今回は、機械学習モデルの開発と運用におけるパイプライン全体を協調動作させモデルを継続的に改善する仕組みについて解説します。
2022年6月13日 6:00
はじめに
本連載も今回で最終回となります。ここまで、8回にわたって機械学習モデルの開発と運用におけるパイプラインを構築してきました。今回は、本番環境にデプロイしたモデルの予測性能の監視と、モデルを継続的に改善するためのサイクルを自動化する方法について解説します。
監視とフィードバックループ
機械学習モデルは一度作成したものを永遠に使い続けられるわけではありません。これは本連載の第1回でも言及していた点ですが、入力データは変化するものなので、時間が経つにつれて予測精度が悪くなる可能性があるためです。この問題に対処するには、本番環境にデプロイしたモデルの監視と継続的な更新が必要です。
モデルの監視
本番環境にデプロイしたモデルは主に次の2つについて監視を行います。
- リソースレベルの監視:モデル(推論サービス)のCPUやメモリの使用量、ネットワークレイテンシ、ディスク使用量などで問題が発生していないかを監視します
- モデルの予測性能の監視:モデルを作成した時点での精度を保っているか、入力データに対して予測結果を期待どおりに返却できているかどうかなどを監視します
前者は一般的なシステム監視と同様ですが、後者は機械学習モデルならではの監視となり、さまざまな要素を含んでいます。ここでは、後者であるモデルの予測性能監視について解説していきます。
モデルの予測性能を監視する方法
本番環境にデプロイしたモデルの予測性能を監視する方法として主に次の2つがあります。
- モデルの評価指標の監視
- モデルに入力されるデータの監視
それぞれの方法について詳細に確認していきます。
モデルの評価指標の監視
実績データを使って算出したモデルの評価指標を監視する方法です。実績データとは、例えばクレジットカードの不正取引検知の場合なら、あるトランザクションが実際に不正だったかどうかといったものであり、またWebマーケティングの場合であれば、実際にダイレクトメールを開封したかどうかなどの実績を含んだデータです。その実績データを使って、主に次の2つの評価指標を算出し監視します。
- モデルの精度: ROC、AUC、ログ損失などの指標を使って、モデルの予測結果と実績データを使って作成した正解ラベル付きのデータを比較する方法です。これはモデルの評価時にも利用した指標です
- ビジネス上の指標: 前述のWebマーケティングを例にとると、開封率やCVR(コンバージョン率)などが挙げられます
前者はドメインに依存しないことが利点として挙げられ、精度の低下とモデルの予測性能の低下は統計的にも有意です。一方、後者は機械学習モデルを導入する目的となるビジネス課題に対する効果を測定する指標となるため、理にかなっています。どちらの指標を用いたとしてもモデルの予測性能の監視に適しています。しかしながら、これらの方法には次のような課題があります。
- 実績データを取得できるまでの時間: 実績データは常にすぐ取得できるとは限りません。ユースケースによっては正解ラベル付きのデータやビジネス上の指標を入手するのに数カ月以上かかる可能性があります。予測性能が低下するスピードが速い場合、実績データを待っている間に、モデルが使い物にならなくなり、結果としてビジネスに大きな損失を与えてしまう可能性があります
この課題の解決策の1つとして、モデルに入力されるデータを監視する方法があります。
モデルに入力されるデータの監視
モデルに入力されるデータの変化は予測性能に大きな影響を与えます。モデルの学習時に利用したデータと予測時の入力データが異なる値を取るときに予測が外れる可能性が高くなるためです。この事象はデータドリフトと呼ばれ、原因としては次のようなことが挙げられます。
- 学習データセットのサンプリングの問題:学習時のデータが母集団を表していない偏ったサンプリングだったために、本番環境における入力データと分布が異なっている場合などを指します。例えば、顔認識のモデルで主に若い人の顔で学習したものの、実際の入力データは年配の方が多い場合などです
- データの生成過程が非定常:入力データの分布が学習時から本番運用時で変化した場合などを指します。非定常環境の影響の例としては、強い季節性があるデータにおいて、夏季のデータを使って学習したために、冬季の入力データに対しては予測が当たらなくなるといったものや、個人的嗜好やトレンドが変わり予測が当たらなくなるといったものが挙げられます
モデルに入力されるデータを監視し、データドリフトを検知する方法は複数ありますが、TFDVを例にとると次の2つがあります。
- チェビシェフ距離:カテゴリ値特徴量の分布の差異を検知
- ジェンセン・シャノン・ダイバージェンス:連続値特徴量の分布の差異を検知
ここでは、モデルの予測性能を監視する方法を2つ挙げましたが、「モデルの評価指標の監視」はその課題を考えると、「モデルに入力されるデータの監視」がより実用的なアプローチに思えるかもしれません。しかしながら、「モデルに入力されるデータの監視」によってデータドリフトを検知したとしても、それは予測性能低下の可能性を示すものにすぎません。たとえ実績データを入手するのに時間がかかるとしても、理想的にはどちらの監視方法も採用し、モデルの開発プロセスにフィードバックすることが重要です。
フィードバックループの構築
モデルを継続的に改善するにはフィードバックループの構築が必要です。つまり、本番環境にデプロイしたモデルの監視から得られた情報を、モデルの開発プロセスに戻し、その情報をもとにモデルを改善する必要があります。
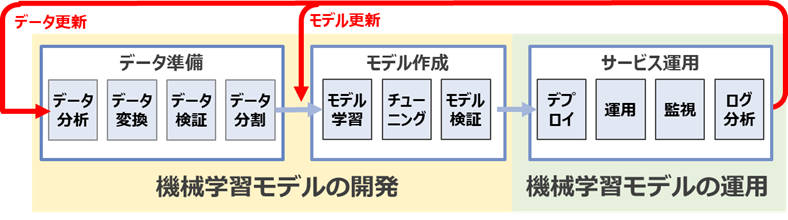
図1-1:フィードバックループ
フィードバックする情報はサービス運用の監視とログ分析のステップから生成されます。前述した内容をまとめると次のとおりになります。
フィードバックする情報と主な指標値
| フィードバックする情報 | 入力 | 主な指標値 |
|---|---|---|
| モデルの精度 | 推論ログ、実績データ | ROC、AUC、ログ損失など |
| ビジネス上の指標 | 実績データ | (例:Webマーケティングの場合)開封率、CVRなど |
| 入力データの変化 | 推論ログ、学習時のデータ | 特徴量ごとの分布の差異(チェビシェフ距離、ジェンセン・シャノン・ダイバージェンスなど) |
サービス運用でのこれらの情報をふまえ、モデルを改善します。モデルを改善する方法は主に次の3つがあります。
- 新しいデータセットを取り込み同じモデルを再トレーニングする:新しい学習データ(実績データ)もしくは既存の学習データの再サンプリングを行い、本番環境にデプロイしているモデル(元のモデル)と同じモデル(アルゴリズム・ハイパーパラメータなど)で再学習する
- 新しい特徴量を加えて再トレーニングする:元のモデルの学習時のデータセットを使って、新しい特徴量を追加もしくは選択をしてモデルを再学習する
- 別のアルゴリズムのモデルを作成する:元のモデルの学習時のデータセットを使って、元のモデルとは別のアルゴリズムで再学習する
モデルの再学習が完了したら、元のモデルとの精度比較を行い更新するか否かを決定します。いずれの方法も新しい学習データが揃うのを待たずともモデルを再学習して改善できるアプローチになっています。フィードバックされた情報を元に、再サンプリングするか、大きく変化している特徴量を特定しその影響を軽減させるために、特徴量の選択・再設計することで、モデルを改善できる可能性があります。
フィードバックループを構築するとモデルを継続的に改善するサイクルが完成します。そのサイクルを効率よく回すための実装例を次に解説します。
- この記事のキーワード
この記事をシェアしてください
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
