TFXを使った機械学習パイプラインの構築(デプロイ編)
連載の7回目となる今回は、実装編で構築した機械学習パイプラインをKubeflow Pipelinesにデプロイし実行します。
2022年3月30日 10:44
はじめに
前回までの実装編では、機械学習パイプラインを構築するために必要なTFXコンポーネントについて、実装を進めながら解説してきました。今回はデプロイ編として、前半でこれまで実装してきたすべてのコンポーネントをまとめて、Kubeflow Pipelinesにデプロイし実行する手順を解説します。そして後半では、機械学習パイプラインの運用で役に立つKubeflow Pipelinesの機能を具体的なユースケースに沿って紹介します。
Kubeflow Pipelinesを使ったTFXパイプラインのオーケストレーション
Kubeflow Pipelinesは、エンドツーエンドな機械学習パイプラインのデプロイと運用管理に焦点をあてたワークフローツールです。Kubeflowの標準コンポーネントの一つとして含まれているため、個別に導入せず利用できます。Kubeflow Pipelinesを使うと、一貫したWeb UI(Pipelines UI)で機械学習パイプラインの運用管理が行えます。また、Kubernetesクラスタ上で機械学習タスクを実行でき、スケーラブルなパイプラインを構築できます。また、TFXとの親和性が高いことも特徴の一つとして挙げられます。
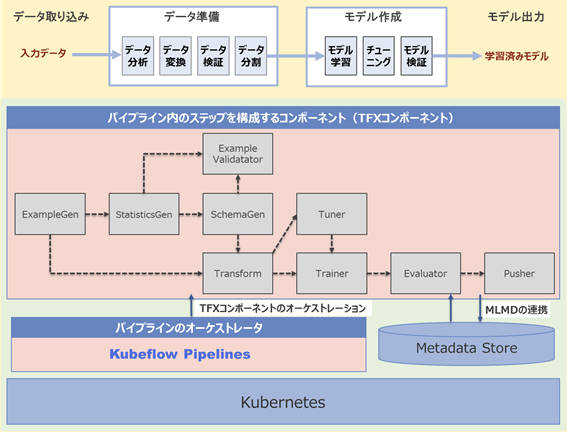
図1:Kubeflow Pipelinesのアーキテクチャ概要
図1はTFXコンポーネントを使って構築したパイプライン(TFXパイプライン)をKubeflow Pipelinesにデプロイした際のアーキテクチャの概要を示しています。これまで実装してきたパイプライン内のステップを構成するTFXコンポーネントは、Kubeflow Pipelinesによってオーケストレーションされます。また、TFXコンポーネントの入出力に関するメタデータを管理する仕組みであるMLMD(Machine Learning Metadata)と連携できるバックエンドデータベースなどもKubeflow Pipelinesの一式としてインストールされるため、各コンポーネントは中央管理されたMetadata Storeを利用することができます。他にも、TFXコンポーネントの出力結果(Artifact)やMetadata Storeに格納されたデータを使った次の機能を提供しています。
- Artifact Visualization:TFDV、TFMA、TensorBoardでの可視化機能
- Metadata UI:MLMDと連携し各コンポーネントの生成物に関する系統来歴を確認できる機能
後述の「機械学習パイプラインの運用で役に立つKubeflow Pipelinesの機能」では、具体的なユースケースに沿って、これらの機能を紹介します。では、実際にKubeflow PipelinesにTFXパイプラインをデプロイし実行してみましょう。
TFXパイプラインのデプロイ
ここでは、Kubeflow PipelinesにTFXパイプラインをデプロイする手順を解説します。
デプロイの手順
デプロイの手順は大きく2つに分けて解説します。
- TFXパイプラインをエクスポート:これまで実装してきたTFXコンポーネントをまとめ、Kubeflow Pipelinesにデプロイできる形式にエクスポートします。この手順では、前回利用したノートブックサーバーおよびPython3ノートブック(.ipynb)を引き続き利用します
- Kubeflow Pipelinesにデプロイ:Pipelines UIを使って、前の手順でエクスポートしたファイルをアップロードしデプロイします
TFXパイプラインをエクスポート
Kubeflow PipelinesにTFXパイプラインをデプロイするには、これまでインタラクティブパイプラインで実装してきたTFXコンポーネントをまとめて、Kubeflow Pipelinesにデプロイできる形式に変換してエクスポートする必要があります。
- Python3ノートブックを開く
前回までの実装編で利用したPython3ノートブック(.ipynb)を開きます。以降、記載しているコード例はコードブロックごとにノートブックの末尾のセルに追記し、実行しながら進めていきます。
- 依存パッケージのインストール
TFXパイプラインをエクスポートするために必要な依存ライブラリをインストールします。
!pip install --upgrade pip --user
!pip install kfp==1.7.2 --user
- TFXパイプラインの生成物を格納するバケットを作成
TFXパイプラインの各コンポーネントが出力する生成物の格納先となるMinIOにバケットを作成します。
# MinIOにKubeflow Pipelinesバケットを作成する
pipeline_bucket_name = 'mlpipeline'
try:
pipeline_bucket = s3_resource.Bucket(pipeline_bucket_name)
pipeline_bucket.create()
print("Create S3 bucket:", pipeline_bucket_name)
except:
print("Existing S3 bucket:", pipeline_bucket_name)
- Kubeflow Pipelines の設定
Kubeflow Pipelinesを使ってTFXパイプラインを実行するための環境設定を行います。まずは、Metadata Storeの接続情報を定義します。
from tfx.orchestration.kubeflow import kubeflow_dag_runner
metadata_config = kubeflow_dag_runner.get_default_kubeflow_metadata_config()
metadata_config.mysql_db_service_host.value = 'mysql.kubeflow'
metadata_config.mysql_db_service_port.value = "3306"
metadata_config.mysql_db_name.value = "metadb"
metadata_config.mysql_db_user.value = "root"
metadata_config.mysql_db_password.value = ""
metadata_config.grpc_config.grpc_service_host.value = 'metadata-grpc-service.kubeflow.svc.cluster.local'
metadata_config.grpc_config.grpc_service_port.value = '8080'
次に、TransformerやTrainerコンポーネントのモジュールファイルなどMinIOにアップロードしてある各種ファイルにKubeflow Pipelinesからアクセスできるようにするため、MinIOの接続情報を環境変数として定義します。
def env_params(name='S3_ENDPOINT', value=''):
def _env_params(task):
from kubernetes import client as k8s_client
return(task.add_env_variable(k8s_client.V1EnvVar(name=name, value=value)))
return _env_params
operator_funcs = []
operator_funcs.append(env_params('AWS_ACCESS_KEY_ID', os.environ['AWS_ACCESS_KEY_ID']))
operator_funcs.append(env_params('AWS_SECRET_ACCESS_KEY', os.environ['AWS_SECRET_ACCESS_KEY']))
operator_funcs.append(env_params('AWS_REGION', os.environ["AWS_REGION"]))
operator_funcs.append(env_params('S3_ENDPOINT', os.environ["S3_ENDPOINT"]))
operator_funcs.append(env_params('S3_USE_HTTPS', '0'))
operator_funcs.append(env_params('S3_VERIFY_SSL', '0'))
次に、Kubeflow PipelinesでTFXコンポーネントを実行する際に使用するコンテナイメージを設定します。ここではAmazon ECR(Amazon Elastic Container Registry)に登録済みのカスタムコンテナイメージを使用します。※Amazon ECRの利用方法や、カスタムコンテナイメージの登録方法については本稿の最後に記載している「(補足)カスタムイメージの利用とKubeflowへの追加設定」を参照してください。そして、これまで定義してきた内容をKubeflowDagRunnerConfigに設定します。KubeflowDagRunnerConfigは、Kubeflow Pipelinesでの実行に必要な固有の構成情報パラメータを設定する際に使用します。
# boto3とkeras-tunerがインストールされたDockerImageを使用
tfx_image = '<AccountID>.dkr.ecr.ap-northeast-1.amazonaws.com/tfx-kubeflow-pipeline:1.0'
pipeline_config = kubeflow_dag_runner.KubeflowDagRunnerConfig(tfx_image = tfx_image,
pipeline_operator_funcs = operator_funcs,
kubeflow_metadata_config = metadata_config)
Kubeflow Pipelinesのランタイムパラメータを設定します。そのために、作成済みのTFXコンポーネントの実行時パラメータを書き換えます。今回は、次の設定をランタイムパラメータとして定義します。
- パイプラインの入力ファイルのパス
- モデルのアップロード先
これにより、パイプライン自体を再作成しなくともパイプライン実行時にパラメータを変更することで、異なる入力ファイルを使用してパイプラインを実行することや、モデルの出力先の変更ができるようになります。
import json
# RuntimeParameter としてパイプライン実行時のパラメータとする
# ExampleGenの入力ファイル
pipeline_example_gen_input = tfx.dsl.experimental.RuntimeParameter(
name='input_config', ptype=str, default=json.dumps(example_gen_input))
example_gen.exec_properties['input_config'] = pipeline_example_gen_input
# Pusherのモデルアップロード先
pipeline_push_destination = tfx.dsl.experimental.RuntimeParameter(
name='push_destination', ptype=str, default=json.dumps(param_push_destination))
pusher.exec_properties['push_destination'] = pipeline_push_destination
- TFXパイプラインのエクスポート
続いて、TFXパイプラインをエクスポートするために各コンポーネントをまとめていきます。
今回は、SchemaGenとTunerはすでに作成済みのファイルを使用するため、import_schemaとimport_tunerをそれぞれリストに定義します。
components = [
example_gen,
statistics_gen,
import_schema,
example_validator,
transform,
import_tuner,
trainer,
evaluator,
pusher,
]
次に、Kubeflow Pipelinesの定義を作成します。pipeline_rootにMinIOのバケットを指定することで、各コンポーネントの出力結果をMinIOにアップロードするようにします。
pipeline_name = 'tfx_census_income_pipeline'
pipeline = tfx.dsl.Pipeline(
pipeline_name = pipeline_name,
pipeline_root = '%s/pipelines/%s' % (bucket_name_s3_prefix, pipeline_name),
components = components,
enable_cache = True,
beam_pipeline_args = beam_pipeline_args)
ここまでノートブック上で実行すると、KubeflowDagRunnerを使用して、TFXパイプラインをエクスポートできます。併せて、出力ディレクトリが存在しない場合は事前に作成しておく必要があるので作成します。
package_dir = os.path.join(os.getcwd(), "package")
os.makedirs(package_dir, exist_ok=True)
package_file_name = '%s_pipeline.tar.gz' % pipeline_name
package_path = os.path.join(package_dir, package_file_name)
kubeflow_dag_runner.KubeflowDagRunner(output_dir=package_dir,
output_filename=package_file_name,
config=pipeline_config).run(pipeline)
- エクスポートしたファイルをダウンロード
出力されたファイルを選択して「Download」ボタンをクリックします。

図2-1:エクスポートしたファイルのダウンロード
Kubeflow Pipelinesにデプロイ
エクスポートしたパイプラインをKubeflow Pipelinesにデプロイします。
- Pipeline UI に画面遷移
はじめにWebブラウザを開いて、Kubeflow UIにアクセスします。
図2-2:Kubeflow UI
左ペインの「Pipelines」をクリックし、Pipelines UIを表示します。
図2-3:Pipelines UI
Pipelines UIの画面上部にある「+ Upload pipeline」ボタンをクリックし、パイプラインアップロード画面を開きます
- パイプラインをデプロイ
パイプラインアップロード画面では、前述でエクスポートしたファイルのアップロードとパイプラインのデプロイを行います。
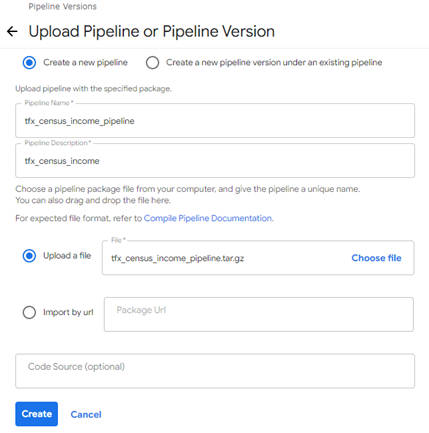
図2-4:パイプラインアップロード画面
デフォルトで「Create a new pipeline」が選択されているので、このまま新規パイプラインを作成します。ファイルをアップロードする際は、「Upload a file」を選択し、先ほどエクスポートしたファイルを選択します。
ファイルが読み込まれると自動的にPipeline Nameの項目が入力されます。Pipeline Descriptionも必須項目となっているので、任意の文字を入力します。入力が完了したらページ下部の「Create」ボタンをクリックします。
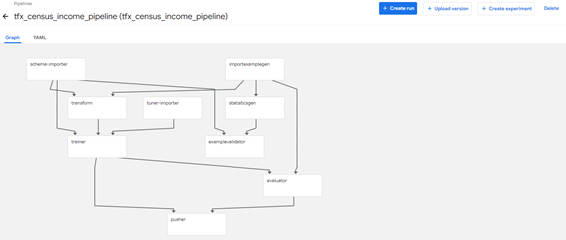
図2-5:パイプラインのグラフ表示
図2-5のように、パイプラインのグラフが表示されれば、デプロイは完了です。
パイプラインの実行
パイプラインのデプロイが完了したので、次は実行していきます。前述のパイプラインのグラフが表示された画面で次の手順を行います。
- Experimentの作成
Experimentはパイプラインの実行履歴を紐づけてグループ化するために利用します。初回実行時はExperimentが存在しないため、新規作成する必要があります。
「+ Create Experiment」ボタンをクリックします。

図2-6:パイプラインのグラフ表示画面(Create Experiment)
Experiment作成画面が表示されたら、Experiment nameに任意の名前を入力します。
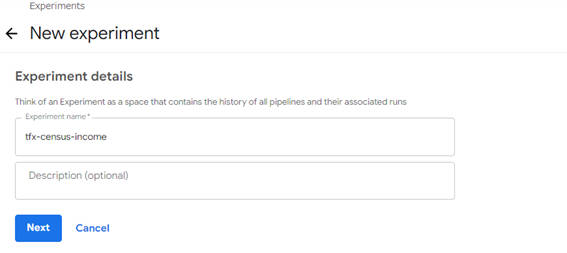
図2-7:Experiment 作成画面
Experiment nameを入力後、「Next」ボタンをクリックすると、次はパイプラインの設定と実行画面が表示されます。
- パイプラインの設定と実行
パイプラインの設定と実行画面では、パイプライン名やランタイムパラメータを設定し、パイプラインの実行を行います。
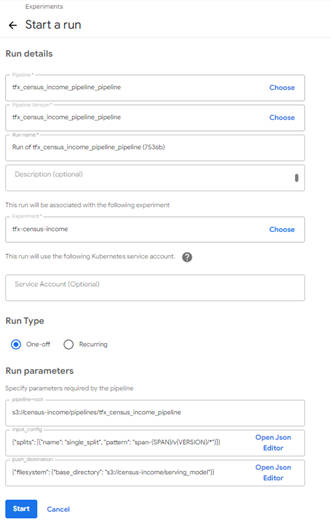
図2-8:パイプラインの設定と実行画面
設定が必要な項目に関しては、自動的に値が入力された状態で画面が表示され、基本的には自動入力された内容でそのまま実行できます。なお、同じパイプラインで異なる入力データを用いて実行したい場合は、ランタイムパラメータ(Run parameters)となっている「入力ファイルのパス」と「モデルのアップロード先」を変更することで、実現できます。内容を確認したらページ下部の「Start」ボタンをクリックしパイプラインを実行します。
- パイプラインの実行状況を確認
パイプラインを実行すると、Experiment一覧画面に自動的に遷移します。
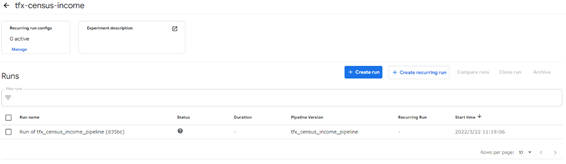
図2-9:Experiment一覧画面
Experiment一覧画面では、該当の「Run」を選択することで、パイプライン実行状況やコンポーネントごとの状態を確認できます。
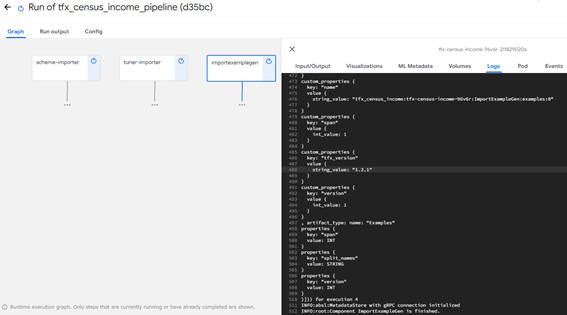
図2-10:コンポーネントごとの状態を確認する画面
コンポーネントごとの状態を確認する画面では、次の内容を確認できます。
- Input/Output:コンポーネントの入出力に関する情報
- Visualizations:コンポーネントの結果を可視化するためのビュー
- ML Metadata:MLMDの情報
- Volumes:アタッチされたボリュームの情報
- Logs:コンポーネントのログ
- Pod:Podリソースのマニフェスト
- Events: EventListリソースのマニフェスト
パイプラインのコンポーネントの実行がすべて完了すると、図2-11のような状態になります。
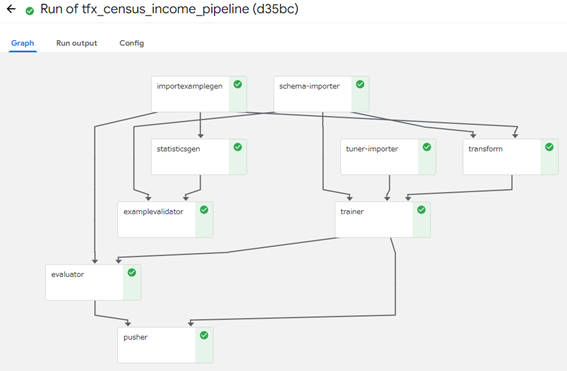
図2-11:パイプラインの実行結果画面(実行がすべて完了の状態)
ここまでKubeflow Pipelinesへのデプロイと実行について、基本的な手順を解説しました。
- この記事のキーワード
この記事をシェアしてください
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
