Kubeflowとは
連載第1回目となる今回は、Kubeflowの登場した背景とその概要について解説します。
2021年9月24日 6:00
はじめに
ディープラーニングの登場がブレークスルーとなり、第3次AIブームが始まり、機械学習やディープラーニングを用いた開発が盛んに行われるようになりました。
昨今では、多くの企業が機械学習やディープラーニングを活用したAIのビジネスへの利活用に取り組んでおり、すでにいくつかの成功事例も出てきています。その一方で、PoC(概念実証)から先に進めず、頓挫するプロジェクトが増えている実情もあります。その理由の一つとして、PoCから実運用へ進むためには、機械学習モデルの開発と運用も含めた全体のプロセスの整備や運用システムの構築が必要となり、その実現が困難であるといったケースがあります。
本連載では、そのような課題の解決策となる、機械学習プラットフォームの一つとして注目を集めているKubeflowについて、実際に構築しながら、解説していきます。
第1回目となる今回は、Kubeflow登場の背景と概要について、解説していきます。
機械学習モデルの運用における課題
機械学習モデルの開発では主に、データの前処理から機械学習モデルの作成、評価までが範囲となり、PoCでは、この段階でプロトタイプシステムを作り、検証を進めていくことが多いでしょう。その後、十分な成果を得られ、いざ実用化を進めるとなると、作成した機械学習モデルの商用システムへの導入が必要です。
この作業は、機械学習モデル開発者が作成したモデルをシステム運用者が引き継いで進めなくてはならず、その役割間のコミュニケーションや作業の分断コストにより時間がかかることが課題となります。また、モデルは一度作成したものを永遠に使い続けられるわけではありません。社会情勢や市場・環境の変化に伴い、予測対象となるデータの傾向が変わると、モデルがその変化に追随できずに予測精度が悪くなる状況が起こり得ます。
従って、商用システムに導入したモデルの精度を監視する仕組みや、継続的にデータを取り込み、再学習して作成した新たなモデルを再び商用システムへ導入するための作業が必要となります。つまり、機械学習モデルの開発から運用へとつながる後続のプロセスの構築が必要となり、その全体を管理するのは非常に複雑な作業となります。
以下の図は、「Hidden Technical Debt in Machine Learning Systems」という論文で論述された、機械学習システムに必要な要素です。図の中の小さな黒いボックスで描かれたところにML Codeが見えますが、機械学習を取り巻く要素の中で、モデルを作成する部分はごく一部で、その周辺は膨大で複雑であることが明らかになっています。
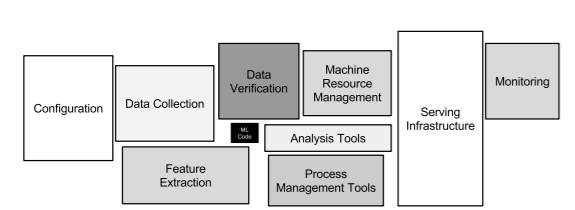
図1:機械学習システムに必要な要素
出典『Hidden Technical Debt in Machine Learning Systems』(D. Sculley、Gary Holt、Daniel Golovin、Eugene Davydov、Todd Phillips、Dietmar Ebner、Vinay Chaudhary、Michael Young、Jean-Francois Crespo、Dan Dennison、2015)、Figure 1より
では、このような課題を解決して、機械学習モデルの開発と運用を円滑に進めるにはどうしたらよいでしょうか。
機械学習モデルの開発と運用を円滑化する概念「MLOps」とは?
MLOpsは、ML(Machine Learning:機械学習)とDevOpsを組み合わせた造語です。DevOpsはソフトウェア開発における、開発(Dev)と運用(Ops)のワークフローの連携を効率化し、生産性を向上する概念で、そのDevOpsを機械学習プロジェクトに適用し、拡張したものが、MLOpsです。このMLOpsが機械学習モデルの開発と運用における課題の解決策となります。まず、前で述べた機械学習モデルの開発と運用に必要となる作業を踏まえて、ワークフローを整理してみましょう。
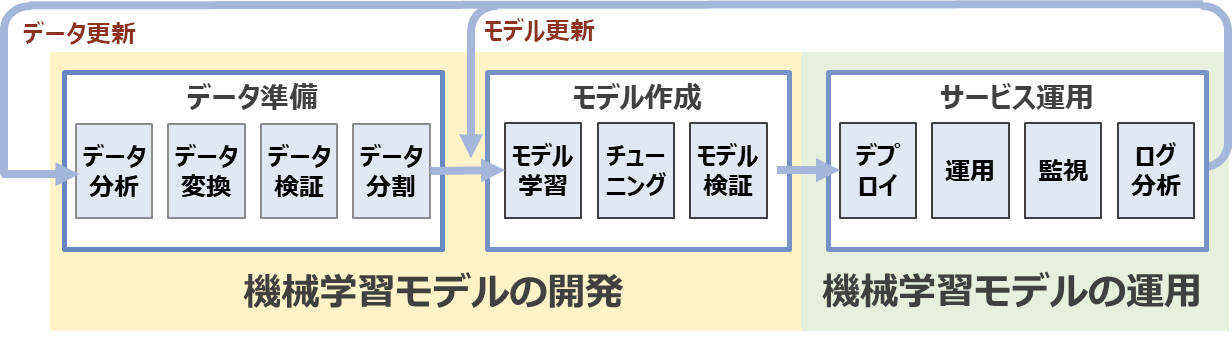
図2:機械学習モデルの開発と運用のワークフロー
図2が示す通り、全体のワークフローは、繰り返しのサイクルからなります。データ取得から始まり、データ準備、モデル作成を行い、商用システムへのデプロイ・運用へとつながり、モデルのパフォーマンスに関するフィードバックを受け取り、継続的にモデル再作成・改善を実施していきます。この一連のワークフローを回すには、機械学習モデルの開発と運用をつなぎ、効率よく円滑に進める仕組みが必要になります。
この課題は、ソフトウェア開発で直面する、開発(Dev)と運用(Ops)における分断とよく似ていて、その解決策としてすでに確立された手法としてDevOpsがあります。そのDevOpsを機械学習モデルの開発と運用に対して適用し拡張することで、全体のワークフローを効率化するMLOpsが誕生しました。
機械学習プラットフォームの必要性
機械学習モデルの開発と運用において、MLOpsの利点を享受するには、DevOpsの CI/CDというワークフローをオーケストレートし管理するコンセプトを導入します。しかしながら、CI/CDだけでは足りず、機械学習モデルの運用を行うシステムにおいては、主に以下の点を考慮する必要があります
- 再現性:機械学習には試行錯誤が必要となる性質があり、繰り返し問題に対して最適な方法を探索することが求められます。どの試行で精度が上がったのか、また精度が下がったのかを追跡して、コードの再利用性を高めながら再現性を維持する必要があります
- 継続的なモニタリング:商用システムへデプロイしたモデルは、環境の変化や時間の経過とともに精度が劣化することがあるため、継続的に監視する仕組みが必要になります
- スケーラビリティ:ほとんどの組織は、同時に複数の機械学習モデルを管理する必要があるでしょう。そのワークフローを回すためにスケーラブルな基盤が必要になります
MLOpsにおいては、自動化は必須ではありませんが、ワークフローの各ステップを機械学習パイプラインとして管理することで、繰り返しの実行を可能にし、実行時のパラメータや実行履歴などのメタデータを管理することで追跡や再現性を担保できます。これを踏まえてMLOpsを実現するシステムを考えると以下のようになります。
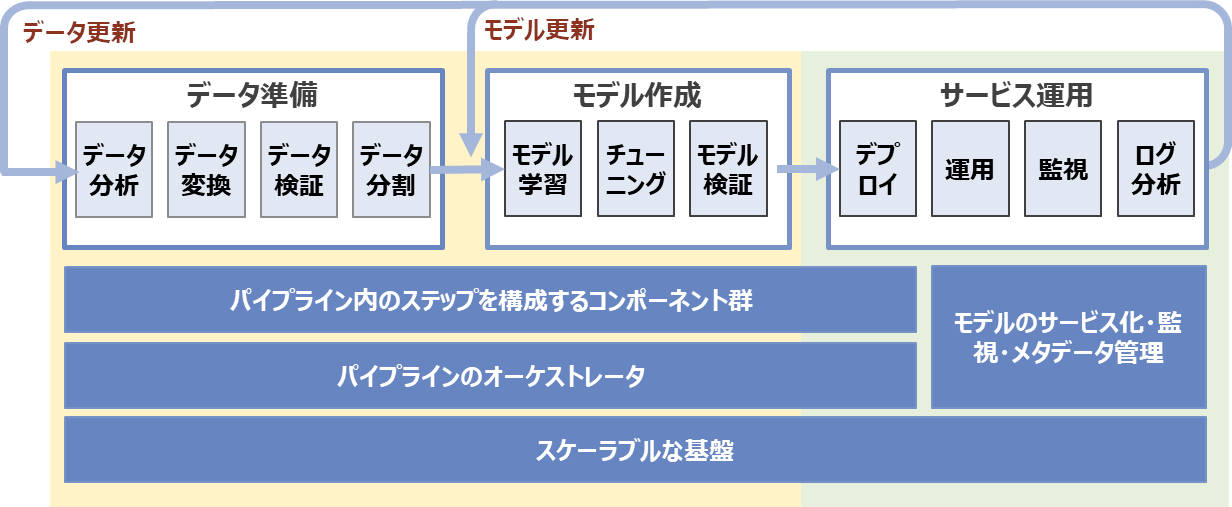
図3:機械学習モデルの開発と運用を行うシステムの全体像
これで機械学習モデルの開発と運用を行うためのシステムの全体像はつかめました。しかしながら、この基盤を一から作るのは大変です。そこで機械学習プラットフォームのKubeflowが登場します。
この記事をシェアしてください
関連記事
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
